一.Ceph 存储基础
1、单机存储设备
-
DAS(直接附加存储,是直接接到计算机的主板总线上去的存储)
IDE、SATA、SCSI、SAS、USB 接口的磁盘
所谓接口就是一种存储设备驱动下的磁盘设备,提供块级别的存储 -
NAS(网络附加存储,是通过网络附加到当前主机文件系统之上的存储)
-
NFS、CIFS、FTP
文件系统级别的存储,本身就是一个做好的文件系统,通过nfs接口在用户空间输出后,客户端基于内核模块与远程主机进行网络通信,把它转为好像本地文件系统一样来使用,这种存储服务是没办法对它再一次格式化创建文件系统块的 -
SAN(存储区域网络)
SCSI协议(只是用来传输数据的存取操作,物理层使用SCSI线缆来传输)、FCSAN(物理层使用光纤来传输)、iSCSI(物理层使用以太网来传输)
也是一种网络存储,但不同之处在于SAN提供给客户端主机使用的接口是块级别的存储
2、单机存储的问题
-
存储处理能力不足
传统的IDE的IO值是100次/秒,SATA固态磁盘500次/秒,固态硬盘达到2000-4000次/秒。即使磁盘的IO能力再大数十倍,也不够抗住网站访问高峰期数十万、数百万甚至上亿用户的同时访问,这同时还要受到主机网络IO能力的限制。 -
存储空间能力不足
单块磁盘的容量再大,也无法满足用户的正常访问所需的数据容量限制。 -
单点故障问题
单机存储数据存在单点故障问题
3、商业存储解决方案
EMC、NetAPP、IBM、DELL、华为、浪潮
4、分布式存储(软件定义的存储 SDS)
- Ceph、TFS、FastDFS、MooseFS(MFS)、HDFS、GlusterFS(GFS)
- 存储机制会把数据分散存储到多个节点上,具有高扩展性、高性能、高可用性等优点。
5、分布式存储的类型
-
块存储(例如硬盘,一般是一个存储被一个服务器挂载使用,适用于容器或虚拟机存储卷分配、日志存储、文件存储)
就是一个裸设备,用于提供没有被组织过的存储空间,底层以分块的方式来存储数据 -
文件存储(例如NFS,解决块存储无法共享问题,可以一个存储被多个服务器同时挂载,适用于目录结构的存储、日志存储)
是一种数据的组织存放接口,一般是建立在块级别的存储结构之上,以文件形式来存储数据,而文件的元数据和实际数据是分开存储的 -
对象存储(例如OSS,一个存储可以被多服务同时访问,具备块存储的高速读写能力,也具备文件存储共享的特性,适用图片存储、视频存储)
基于API接口提供的文件存储,每一个文件都是一个对象,且文件大小各不相同的,文件的元数据和实际数据是存放在一起的
二.Ceph 介绍
1.Ceph 的概念
- Ceph使用C++语言开发,是一个开放、自我修复和自我管理的开源分布式存储系统。具有高扩展性、高性能、高可靠性的优点
- Ceph目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack,Kubernetes都可与Ceph整合以支持虚拟机镜像的后端存储。粗略估计,我国70%—80%的云平台都将Ceph作为底层的存储平台,由此可见Ceph俨然成为了开源云平台的标配。目前国内使用Ceph搭建分布式存储系统较为成功的企业有华为、阿里、中兴、华三、浪潮、中国移动、网易、乐视、360、星辰天合存储、杉岩数据等。
2、Ceph 优势
- 高扩展性:去中心化,支持使用普通X86服务器,支持上千个存储节点的规模,支持TB到EB级的扩展
- 高可靠性:没有单点故障,多数据副本,自动管理,自动修复
- 高性能:摒弃了传统的集中式存储元数据寻址的方案,采用 CRUSH 算法,数据分布均衡,并行度高
- 功能强大:Ceph是个大一统的存储系统,集块存储接口(RBD)、文件存储接口(CephFS)、对象存储接口(RadosGW)于一身,因而适用于不同的应用场景
3、Ceph 架构
-
RADOS 基础存储系统(Reliab1e,Autonomic,Distributed object store,即可靠的、自动化的、分布式的对象存储)
RADOS是Ceph最底层的功能模块,是一个无限可扩容的对象存储服务,能将文件拆解成无数个对象(碎片)存放在硬盘中,大大提高了数据的稳定性。它主要由OSD和Monitor两个组件组成,OSD和Monitor都可以部署在多台服务器中,这就是ceph分布式的由来,高扩展性的由来。 -
LIBRADOS 基础库
Librados提供了与RADOS进行交互的方式,并向上层应用提供Ceph服务的API接口,因此上层的RBD、RGW和CephFS都是通过Librados访问的,目前提供PHP、Ruby、Java、Python、Go、C和C++支持,以便直接基于RADOS(而不是整个Ceph)进行客户端应用开发。
4、高层应用接口:包括了三个部分
1)对象存储接口 RGW(RADOS Gateway)
- 网关接口,基于Librados开发的对象存储系统,提供S3和Swift兼容的RESTful API接口。
2)块存储接口 RBD(Reliable Block Device)
- 基于Librados提供块设备接口,主要用于Host/VM。
3)文件存储接口 CephFS(Ceph File System)
- Ceph文件系统,提供了一个符合POSIX标准的文件系统,它使用Ceph存储集群在文件系统上存储用户数据。基于Librados提供的分布式文件系统接口
- 应用层:基于高层接口或者基础库Librados开发出来的各种APP,或者Host、VM等诸多客户端
5、Ceph 核心组件
- Ceph是一个对象式存储系统,它把每一个待管理的数据流(如文件等数据)切分为一到多个固定大小(默认4兆)的对象数据(Object),并以其为原子单元(原子是构成元素的最小单元)完成数据的读写。
1)OSD(Object Storage Daemon,守护进程 ceph-osd)
- 是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等。通常至少需要3个OSD来实现冗余和高可用性
2)PG(Placement Group 归置组)
- PG 是一个虚拟的概念而已,物理上不真实存在。它在数据寻址时类似于数据库中的索引:Ceph 先将每个对象数据通过HASH算法固定映射到一个 PG 中,然后将 PG 通过 CRUSH 算法映射到 OSD
3)Pool
- Pool 是存储对象的逻辑分区,它起到 namespace 的作用。每个 Pool 包含一定数量(可配置)的 PG。Pool 可以做故障隔离域,根据不同的用户场景统一进行隔离
6、Pool中数据保存方式支持两种类型
- 多副本(replicated):类似 raid1,一个对象数据默认保存 3 个副本,放在不同的 OSD
- 纠删码(Erasure Code):类似 raid5,对 CPU 消耗稍大,但是节约磁盘空间,对象数据保存只有 1 个副本。由于Ceph部分功能不支持纠删码池,此类型存储池使用不多
7、Pool、PG 和 OSD 的关系
- 一个Pool里有很多个PG;一个PG里包含一堆对象,一个对象只能属于一个PG;PG有主从之分,一个PG分布在不同的OSD上(针对多副本类型)
1)Monitor(守护进程 ceph-mon)
- 用来保存OSD的元数据。负责维护集群状态的映射视图(Cluster Map:OSD Map、Monitor Map、PG Map 和 CRUSH Map),维护展示集群状态的各种图表, 管理集群客户端认证与授权。一个Ceph集群通常至少需要 3 或 5 个(奇数个)Monitor 节点才能实现冗余和高可用性,它们通过 Paxos 协议实现节点间的同步数据。
2)Manager(守护进程 ceph-mgr)
- 负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率、当前性能指标和系统负载。为外部监视和管理系统提供额外的监视和接口,例如 zabbix、prometheus、 cephmetrics 等。一个 Ceph 集群通常至少需要 2 个 mgr 节点实现高可用性,基于 raft 协议实现节点间的信息同步。
3)MDS(Metadata Server,守护进程 ceph-mds)
- 是 CephFS 服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务;如果不使用 CephFS 可以不安装。
8、OSD 存储后端
- OSD 有两种方式管理它们存储的数据。在 Luminous 12.2.z 及以后的发行版中,默认(也是推荐的)后端是 BlueStore。在 Luminous 发布之前, 默认是 FileStore, 也是唯一的选项。
1)Filestore
- FileStore是在Ceph中存储对象的一个遗留方法。它依赖于一个标准文件系统(只能是XFS),并结合一个键/值数据库(传统上是LevelDB,现在BlueStore是RocksDB),用于保存和管理元数据。
FileStore经过了良好的测试,在生产中得到了广泛的应用。然而,由于它的总体设计和对传统文件系统的依赖,使得它在性能上存在许多不足。
2)Bluestore
- BlueStore是一个特殊用途的存储后端,专门为OSD工作负载管理磁盘上的数据而设计。BlueStore 的设计是基于十年来支持和管理 Filestore 的经验。BlueStore 相较于 Filestore,具有更好的读写性能和安全性。
9、BlueStore 的主要功能包括:
1)BlueStore直接管理存储设备,即直接使用原始块设备或分区管理磁盘上的数据。这样就避免了抽象层的介入(例如本地文件系统,如XFS),因为抽象层会限制性能或增加复杂性。
2)BlueStore使用RocksDB进行元数据管理。RocksDB的键/值数据库是嵌入式的,以便管理内部元数据,包括将对象名称映射到磁盘上的块位置。
3)写入BlueStore的所有数据和元数据都受一个或多个校验和的保护。未经验证,不会从磁盘读取或返回给用户任何数据或元数据。
4)支持内联压缩。数据在写入磁盘之前可以选择性地进行压缩。
5)支持多设备元数据分层。BlueStore允许将其内部日志(WAL预写日志)写入单独的高速设备(如SSD、NVMe或NVDIMM),以提高性能。如果有大量更快的可用存储,则可以将内部元数据存储在更快的设备上。
6)支持高效的写时复制。RBD和CephFS快照依赖于在BlueStore中有效实现的即写即复制克隆机制。这将为常规快照和擦除编码池(依赖克隆实现高效的两阶段提交)带来高效的I/O。
10、Ceph 数据的存储过程
1)客户端从 mon 获取最新的 Cluster Map
2)在 Ceph 中,一切皆对象。Ceph 存储的数据都会被切分成为一到多个固定大小的对象(Object)。Object size 大小可以由管理员调整,通常为 2M 或 4M。
11、每个对象都会有一个唯一的 OID
- ino :即是文件的 FileID,用于在全局唯一标识每一个文件
- ono :则是分片的编号
- 比如:一个文件 FileID 为 A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的 oid 则为 A0 与 A1
- OID 的好处是可以唯一标示每个不同的对象,并且存储了对象与文件的从属关系。由于 Ceph 的所有数据都虚拟成了整齐划一的对象,所以在读写时效率都会比较高
- 通过对 OID 使用 HASH 算法得到一个16进制的特征码,用特征码与 Pool 中的 PG 总数取余,得到的序号则是 PGID , Pool_ID + HASH(OID) % PG_NUM 得到 PGID
- PG 会根据设置的副本数量进行复制,通过对 PGID 使用 CRUSH 算法算出 PG 中目标主和次 OSD 的 ID,存储到不同的 OSD 节点上(其实是把 PG 中的所有对象存储到 OSD 上)。
即通过 CRUSH(PGID) 得到将 PG 中的数据存储到各个 OSD 组中
CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
12、Ceph 版本发行生命周期
-
Ceph从Nautilus版本(14.2.0)开始,每年都会有一个新的稳定版发行,预计是每年的3月份发布,每年的新版本都会起一个新的名称(例如,“Mimic”)和一个主版本号(例如,13代表Mimic,因为“M”是字母表的第13个字母)。
-
版本号的格式为 x.y.z,x 表示发布周期(例如,13 代表 Mimic,17 代表 Quincy),y 表示发布版本类型,即
● x.0.z :y等于 0,表示开发版本
● x.1.z :y等于 1,表示发布候选版本(用于测试集群)
● x.2.z :y等于 2,表示稳定/错误修复版本(针对用户)
13、Ceph 集群部署的方法
-
ceph-deploy :一个集群自动化部署工具,使用较久,成熟稳定,被很多自动化工具所集成,可用于生产部署。
-
cephadm :从 Octopus 和较新的版本版本后使用 cephadm 来部署 ceph 集群,使用容器和 systemd 安装和管理 Ceph 集群。目前不建议用于生产环境。
-
二进制:手动部署,一步步部署 Ceph 集群,支持较多定制化和了解部署细节,安装难度较大。
三、 基于 ceph-deploy 部署 Ceph 集群
1、Ceph 生产环境推荐
① 存储集群全采用万兆网络
② 集群网络(cluster-network,用于集群内部通讯)与公共网络(public-network,用于外部访问Ceph集群)分离
③ mon、mds 与 osd 分离部署在不同主机上(测试环境中可以让一台主机节点运行多个组件)
④ OSD 使用 SATA 亦可
⑤ 根据容量规划集群
⑥ 至强E5 2620 V3或以上 CPU,64GB或更高内存
⑦ 集群主机分散部署,避免机柜的电源或者网络故障
2、Ceph 环境规划
| 主机名 | Public网络 | Cluster网络 | 角色 |
|---|---|---|---|
| admin | 192.168.247.134 | / | admin(管理节点负责集群整体部署)、client |
| node01 | 192.168.247.131 | 192.168.100.131 | mon、mgr、osd(/dev/sdb、/dev/sdc、/dev/sdd) |
| node02 | 192.168.247.132 | 192.168.100.132 | mon、mgr、osd(/dev/sdb、/dev/sdc、/dev/sdd) |
| node03 | 192.168.247.133 | 192.168.100.133 | mon、osd(/dev/sdb、/dev/sdc、/dev/sdd) |
| client | 192.168.247.133 | / | client |
3、关闭 selinux 与防火墙
systemctl disable --now firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
4、根据规划设置主机名
hostnamectl set-hostname admin
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
hostnamectl set-hostname client
5、配置 hosts 解析
cat >> /etc/hosts << EOF
192.168.247.134 admin
192.168.247.131 node01
192.168.247.132 node02
192.168.247.133 node03
192.168.247.135 client
EOF
6、安装常用软件和依赖包
yum -y install epel-release
yum -y install yum-plugin-priorities yum-utils ntpdate python-setuptools python-pip gcc gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel zip unzip ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5-devel libidn libidn-devel openssl openssh openssl-devel nss_ldap openldap openldap-devel openldap-clients openldap-servers libxslt-devel libevent-devel ntp libtool-ltdl bison libtool vim-enhanced python wget lsof iptraf strace lrzsz kernel-devel kernel-headers pam-devel tcl tk cmake ncurses-devel bison setuptool popt-devel net-snmp screen perl-devel pcre-devel net-snmp screen tcpdump rsync sysstat man iptables sudo libconfig git bind-utils tmux elinks numactl iftop bwm-ng net-tools expect snappy leveldb gdisk python-argparse gperftools-libs conntrack ipset jq libseccomp socat chrony sshpass
7、在 admin 管理节点配置 ssh 免密登录所有节点
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
sshpass -p 'xw523716' ssh-copy-id -o StrictHostKeyChecking=no root@admin
sshpass -p 'xw523716' ssh-copy-id -o StrictHostKeyChecking=no root@node01
sshpass -p 'xw523716' ssh-copy-id -o StrictHostKeyChecking=no root@node02
sshpass -p 'xw523716' ssh-copy-id -o StrictHostKeyChecking=no root@node03
8、配置时间同步
systemctl enable --now chronyd
timedatectl set-ntp true #开启 NTP
timedatectl set-timezone Asia/Shanghai #设置时区
chronyc -a makestep #强制同步下系统时钟
timedatectl status #查看时间同步状态
chronyc sources -v #查看 ntp 源服务器信息
timedatectl set-local-rtc 0 #将当前的UTC时间写入硬件时钟
- 重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond
- 关闭无关服务
systemctl disable --now postfix
9、配置 Ceph yum源
wget https://download.ceph.com/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm --no-check-certificaterpm -ivh ceph-release-1-1.el7.noarch.rpm --force
10、执行完上面所有的操作之后重启所有主机(可选)
sync
reboot
11、在三个node节点上增加网卡并修改
四、部署 Ceph 集群
1、为所有节点都创建一个 Ceph 工作目录,后续的工作都在该目录下进行
mkdir -p /etc/ceph
2、安装 ceph-deploy 部署工具
cd /etc/ceph
yum install -y ceph-deploy
ceph-deploy --version
3、在管理节点为其它节点安装 Ceph 软件包
yum clean all
yum -y install epel-release
yum -y install yum-plugin-priorities
yum -y install ceph-release ceph ceph-radosgw
- 也可采用手动安装 Ceph 包方式,在其它节点上执行下面的命令将 Ceph 的安装包都部署上
sed -i 's#download.ceph.com#mirrors.tuna.tsinghua.edu.cn/ceph#' /etc/yum.repos.d/ceph.repo
yum install -y ceph-mon ceph-radosgw ceph-mds ceph-mgr ceph-osd ceph-common ceph
4、生成初始配置
cd /etc/ceph
ceph-deploy new --public-network 192.168.247.0/24 --cluster-network 192.168.100.0/24 node01 node02 node03
- 命令执行成功后会在 /etc/ceph 下生成配置文件
ls /etc/ceph
ceph.conf #ceph的配置文件
ceph-deploy-ceph.log #monitor的日志
ceph.mon.keyring #monitor的密钥环文件
5、在管理节点初始化 mon 节点
cd /etc/ceph
ceph-deploy mon create node01 node02 node03 #创建 mon 节点,由于 monitor 使用 Paxos 算法,其高可用集群节点数量要求为大于等于 3 的奇数台
ceph-deploy --overwrite-conf mon create-initial #配置初始化 mon 节点,并向所有节点同步配置 # --overwrite-conf 参数用于表示强制覆盖配置文件
ceph-deploy gatherkeys node01 #可选操作,向 node01 节点收集所有密钥
- 命令执行成功后会在 /etc/ceph 下生成配置文件
ls /etc/ceph
ceph.bootstrap-mds.keyring #引导启动 mds 的密钥文件
ceph.bootstrap-mgr.keyring #引导启动 mgr 的密钥文件
ceph.bootstrap-osd.keyring #引导启动 osd 的密钥文件
ceph.bootstrap-rgw.keyring #引导启动 rgw 的密钥文件
ceph.client.admin.keyring #ceph客户端和管理端通信的认证密钥,拥有ceph集群的所有权限
ceph.conf
ceph-deploy-ceph.log
ceph.mon.keyring
- 在 mon 节点上查看自动开启的 mon 进程
ps aux | grep ceph
root 1823 0.0 0.2 189264 9216 ? Ss 19:46 0:00 /usr/bin/python2.7 /usr/bin/ceph-crash
ceph 3228 0.0 0.8 501244 33420 ? Ssl 21:08 0:00 /usr/bin/ceph-mon -f --cluster ceph --id node03 --setuser ceph --setgroupceph
root 3578 0.0 0.0 112824 988 pts/1 R+ 21:24 0:00 grep --color=auto ceph
- 在管理节点查看 Ceph 集群状态
cd /etc/ceph
ceph -scluster:id: 7e9848bb-909c-43fa-b36c-5805ffbbeb39health: HEALTH_WARNmons are allowing insecure global_id reclaimservices:mon: 3 daemons, quorum node01,node02,node03mgr: no daemons activeosd: 0 osds: 0 up, 0 indata:pools: 0 pools, 0 pgsobjects: 0 objects, 0 Busage: 0 B used, 0 B / 0 B availpgs:
- 查看 mon 集群选举的情况
ceph quorum_status --format json-pretty | grep leader
"quorum_leader_name": "node01",
- 扩容 mon 节点
ceph-deploy mon add <节点名称>
6、部署能够管理 Ceph 集群的节点(可选)
- 可实现在各个节点执行 ceph 命令管理集群
cd /etc/ceph
ceph-deploy --overwrite-conf config push node01 node02 node03 #向所有 mon 节点同步配置,确保所有 mon 节点上的 ceph.conf 内容必须一致
ceph-deploy admin node01 node02 node03 #本质就是把 ceph.client.admin.keyring 集群认证文件拷贝到各个节点
- 在 mon 节点上查看
ls /etc/ceph
ceph.client.admin.keyring ceph.conf rbdmap tmpr8tzyc
cd /etc/ceph
ceph -s
7、部署 osd 存储节点
- 主机添加完硬盘后不要分区,直接使用
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 500M 0 part /boot
├─sda2 8:2 0 4G 0 part [SWAP]
└─sda3 8:3 0 55.5G 0 part /
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sdd 8:48 0 20G 0 disk
- 如果是利旧的硬盘,则需要先擦净(删除分区表)磁盘(可选,无数据的新硬盘可不做)
cd /etc/ceph
ceph-deploy disk zap node01 /dev/sdb
ceph-deploy disk zap node02 /dev/sdb
ceph-deploy disk zap node03 /dev/sdb
- 添加 osd 节点
ceph-deploy --overwrite-conf osd create node01 --data /dev/sdb
ceph-deploy --overwrite-conf osd create node02 --data /dev/sdb
ceph-deploy --overwrite-conf osd create node03 --data /dev/sdb
- 查看 ceph 集群状态
ceph -scluster:id: 7e9848bb-909c-43fa-b36c-5805ffbbeb39health: HEALTH_WARNno avtive mgrservices:mon: 3 daemons, quorum node01,node02,node03 (age 119m)mgr: no daemons activeosd: 3 osds: 3 up (since 35s), 3 in (since 35s)data:pools: 0 pools, 0 pgsobjects: 0 objects, 0 Busage: 3.0 GiB used, 57 GiB / 60 GiB availpgs:
ceph osd stat
ceph osd tree
rados df
ssh root@node01 systemctl status ceph-osd@0
ssh root@node02 systemctl status ceph-osd@1
ssh root@node03 systemctl status ceph-osd@2ceph osd status #查看 osd 状态,需部署 mgr 后才能执行
+----+--------+-------+-------+--------+---------+--------+---------+-----------+
| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |
+----+--------+-------+-------+--------+---------+--------+---------+-----------+
| 0 | node01 | 1025M | 18.9G | 0 | 0 | 0 | 0 | exists,up |
| 1 | node02 | 1025M | 18.9G | 0 | 0 | 0 | 0 | exists,up |
| 2 | node03 | 1025M | 18.9G | 0 | 0 | 0 | 0 | exists,up |
+----+--------+-------+-------+--------+---------+--------+---------+-----------+ceph osd df #查看 osd 容量,需部署 mgr 后才能执行
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS 0 hdd 0.01949 1.00000 20 GiB 1.0 GiB 1.8 MiB 0 B 1 GiB 19 GiB 5.01 1.00 0 up 1 hdd 0.01949 1.00000 20 GiB 1.0 GiB 1.8 MiB 0 B 1 GiB 19 GiB 5.01 1.00 0 up 2 hdd 0.01949 1.00000 20 GiB 1.0 GiB 1.8 MiB 0 B 1 GiB 19 GiB 5.01 1.00 0 up TOTAL 60 GiB 3.0 GiB 5.2 MiB 0 B 3 GiB 57 GiB 5.01
MIN/MAX VAR: 1.00/1.00 STDDEV: 0
- 扩容 osd 节点
cd /etc/ceph
ceph-deploy --overwrite-conf osd create node01 --data /dev/sdc
ceph-deploy --overwrite-conf osd create node02 --data /dev/sdc
ceph-deploy --overwrite-conf osd create node03 --data /dev/sdc
ceph-deploy --overwrite-conf osd create node01 --data /dev/sdd
ceph-deploy --overwrite-conf osd create node02 --data /dev/sdd
ceph-deploy --overwrite-conf osd create node03 --data /dev/sdd
8、部署 mgr 节点
- ceph-mgr守护进程以Active/Standby模式运行,可确保在Active节点或其ceph-mgr守护进程故障时,其中的一个Standby实例可以在不中断服务的情况下接管其任务。根据官方的架构原则,mgr至少要有两个节点来进行工作
cd /etc/ceph
ceph-deploy mgr create node01 node02ceph -scluster:id: 7e9848bb-909c-43fa-b36c-5805ffbbeb39health: HEALTH_WARNmons are allowing insecure global_id reclaimservices:mon: 3 daemons, quorum node01,node02,node03mgr: node01(active, since 10s), standbys: node02osd: 0 osds: 0 up, 0 in
-
解决 HEALTH_WARN 问题:mons are allowing insecure global_id reclaim问题:
-
禁用不安全模式:ceph config set mon auth_allow_insecure_global_id_reclaim false
-
扩容 mgr 节点
ceph-deploy mgr create <节点名称>
9、开启监控模块
- 在 ceph-mgr Active节点执行命令开启
ceph -s | grep mgr
yum install -y ceph-mgr-dashboard
cd /etc/ceph
ceph mgr module ls | grep dashboard
#开启 dashboard 模块
ceph mgr module enable dashboard --force
#禁用 dashboard 的 ssl 功能
ceph config set mgr mgr/dashboard/ssl false
#配置 dashboard 监听的地址和端口
ceph config set mgr mgr/dashboard/server_addr 0.0.0.0
ceph config set mgr mgr/dashboard/server_port 8000
#重启 dashboard
ceph mgr module disable dashboard
ceph mgr module enable dashboard --force
#确认访问 dashboard 的 url
ceph mgr services
#设置 dashboard 账户以及密码
echo "12345678" > dashboard_passwd.txt
ceph dashboard set-login-credentials admin -i dashboard_passwd.txt或
ceph dashboard ac-user-create admin administrator -i dashboard_passwd.txt
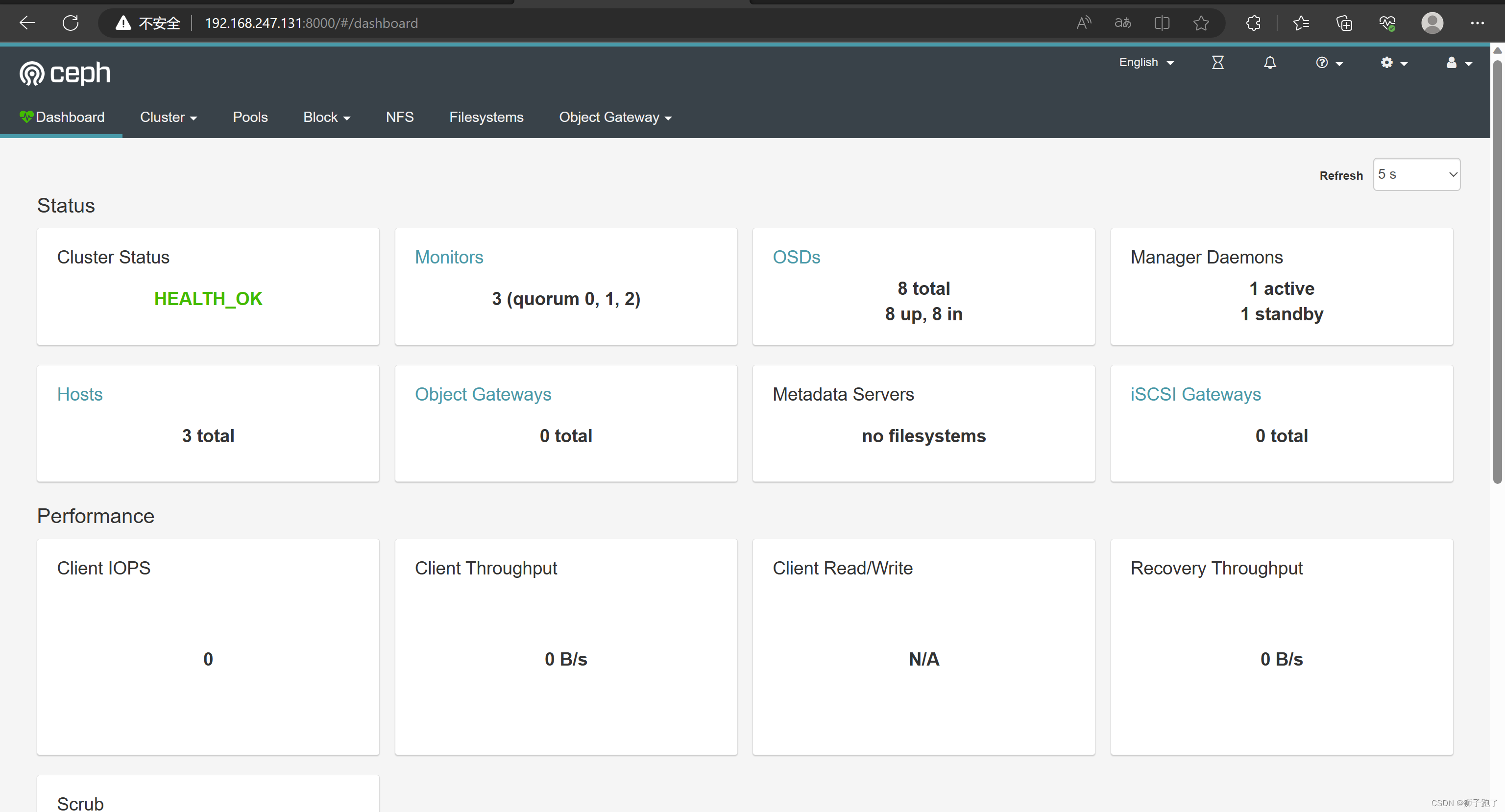
- 浏览器访问:http://192.168.247.131:8000 ,账号密码为 admin/12345678