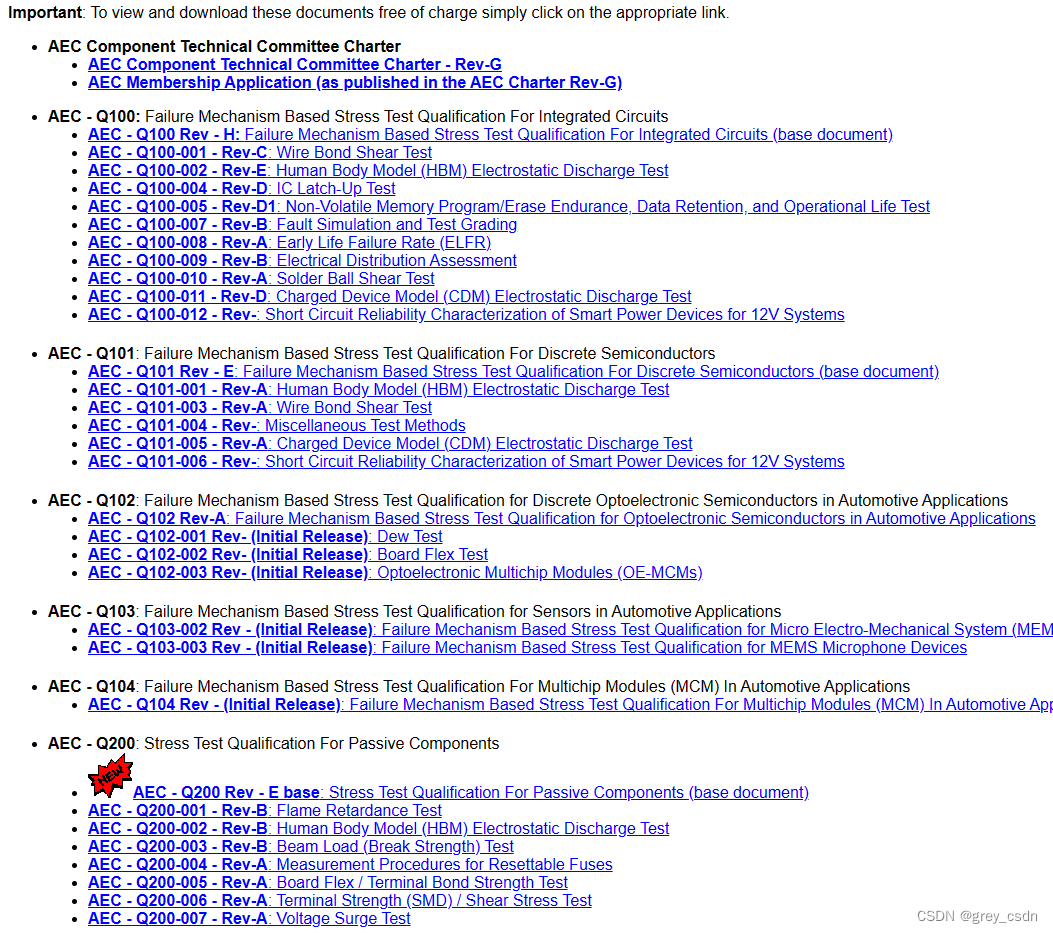
大家好,我是二狗。
![]()
英伟达和AMD这两家芯片巨头掐起来啦!

事情的起因是,两周前AMD董事会主席兼CEO苏姿丰在一场活动中发布了用于生成式AI和数据中心的新一代Intinct MI300X GPU芯片加速卡。

单单发布显卡没啥问题,但是AMD声称MI300X芯片在推断 Meta 的 Llama 2700 亿参数模型时,能够实现比 H100 低 40% 的延迟。
这意味着AMD的MI300X芯片性能更优呗!
英伟达下场指责AMD
那英伟达作为GPU显卡的行业老大哥,听到之后哪能愿意啊。
所以,就在上周,英伟达特意发布一篇官方博客来证明 H100 具有顶级的推理性能。
英伟达博客表示:
一流的AI性能需要高效的并行计算架构、高效的工具堆栈和深度优化的算法。英伟达发布了开源 NVIDIA TensorRT-LLM,其中包括针对 NVIDIA H100 Tensor Core GPU 核心的 NVIDIA Hopper 架构的最新内核优化。这些优化使 Llama 2 70B 等模型能够在 H100 GPU 上使用加速 FP8 运算执行,同时保持推理精度。
而AMD在发布会上提到MI300X 芯片相比H100 GPU 更好的推理性能,但是AMD的测试没有使用优化软件,如果基准测试正确,H100 的推理速度将会快 2 倍。
简单来讲,英伟达的想表达意思就是,AMD 在基准测试时没有利用优化软件或 H100 对 FP8 数据类型的支持,而是在 FP16 上使用 vLLM 进行测试。一般来说,精度较低的数据类型会牺牲精度来换取性能。换句话说,英伟达表示 AMD 故意阻碍了H100的性能发挥。
英伟达在博客上还po出了具有8个 H100 GPU 的单台 NVIDIA DGX H100 服务器在 Llama 2 70B 型号上的实际测试性能。测试包括一次处理一个推理请求的“Batch-1”的结果,以及使用固定响应时间处理的结果。
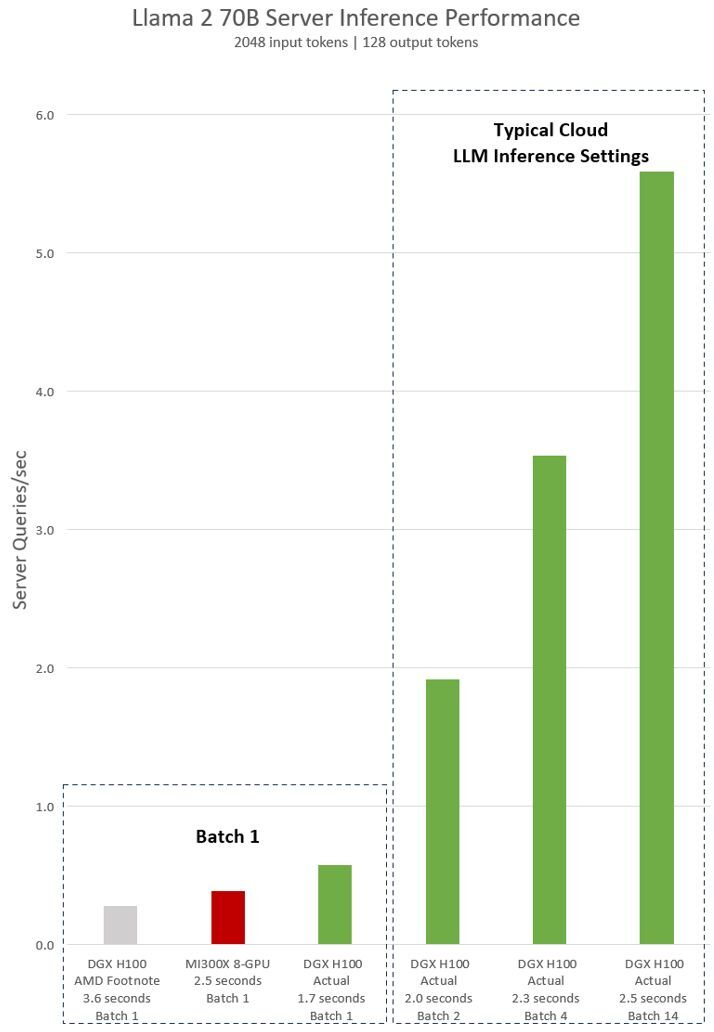
英伟达声称,当使用其闭源 TensorRT LLM 框架和 FP8 进行基准测试时,H100的性能实际上是 MI300X 的两倍。
英伟达还认为,AMD 通过使用 把batch size 设置为1 来呈现性能的最佳情况,换句话说,只通过一次处理一个推理请求。英伟达认为这是不符合实际的,因为大多数云提供商都会用延迟来换取更大的batch size。
据英伟达称,使用英伟达的优化软件堆栈,具有 8 个加速器的 DGX H100 节点能够处理 14 个batch size,而具有 8 个 AMD MI300X 的类似节点则可以处理一个batch size。
AMD摆数据强势回击英伟达
在英伟达的上述博客发布一天之内,AMD也发布了博客进行回应,AMD声称自家的显卡确实具备行业领先的性能,而英伟达的基准测试并不是做的同类比较。
AMD指责英伟达进行的测试基准是不合理的:
-
英伟达在 H100 上使用 TensorRT-LLM 进行测试,而不是 AMD 基准测试中使用的 vLLM;
-
英伟达用 H100 上的 FP8 数据类型的性能和AMD MI300X GPU 上的 FP16 数据类型进行了比较;
-
英伟达将AMD发布的性能数据从相对延迟数反转为绝对吞吐量;
AMD表示:
我们正处于产品升级阶段,我们不断寻找新的途径来利用 ROCM 软件和 AMD Instinct MI300 加速器释放性能。
我们发布会上提供的数据是在 11 月份测试记录的。自从11月份以来,我们已经取得了很大进展,并且很高兴分享我们突显这些成果的最新结果。
下图是AMD使用最新的MI300X运行Llama 70B的性能数据进行对比,蓝色是MI300X显卡的性能,灰色是H100显卡的性能。
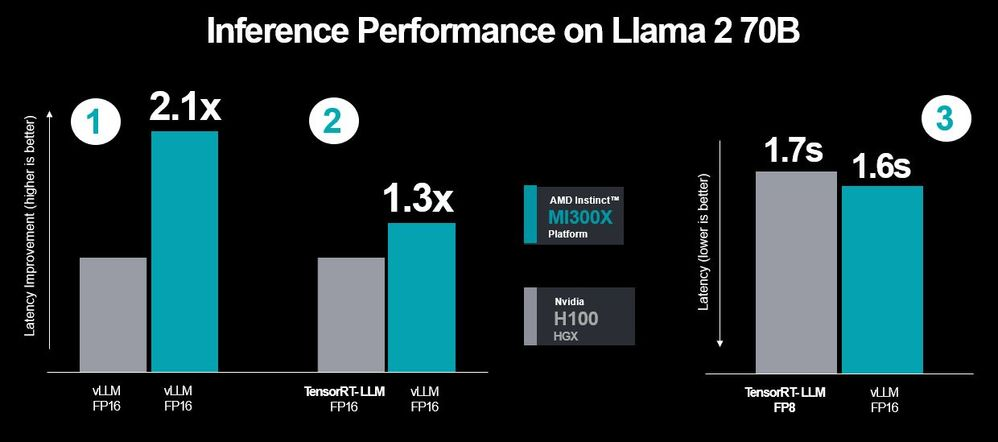
很容易看出,在AMD的测试之下,无论是性能还是延迟,MI300X都要优于H100。
AMD则接着表示:“结果再次表明,即使使用 FP8 和 TensorRT-LLM,使用 FP16 的 MI300X 也可与 Nvidia 推荐的最佳性能设置的 H100 相媲美。”
显卡竞争的关键-软件栈优化
英伟达事后没有针对AMD的最新博客做出声明,但是英伟达和 AMD 的基准测试争论凸显了软件库和框架在提升AI性能方面所发挥的作用。
英伟达的主要论点之一是,AMD 通过使用 vLLM 而不是 TensorRT-LLM软件来测试,所以才导致 H100性能处于劣势。
英伟达于9月份宣布并于10月底发布 TensorRT-LLM,TensorRT-LLM组合了包括深度学习编译器、优化内核、预处理和后处理步骤以及多GPU和多节点通信原语等功能。
英伟达声称,使用优化后的软件在运行 60 亿个参数的 GPT-J 模型时,能够有效地将 H100 的推理性能提高一倍,而H100 在 Llama 2 70B 中的性能也提升了 77%。
AMD 在本月早些时候推出 ROCm 6 框架时也做出了类似的声明。AMD 声称,由于对 vLLM、HIP Graph 和 Flash Attention 的优化,其最新的 AI 框架能够将 LLM 性能提高 1.3 倍到 2.6 倍。且与在 ROCm 5 上运行的 MI250X 相比,在 ROCm 6新软件框架上运行的 MI300X 速度快了 8 倍。
AMD凭借“内存”取胜?
AI推理工作负载非常复杂,性能取决于FLOPS、精度、内存容量、内存带宽、互连带宽和模型大小等多种因素。
AMD本次最大的优势不是浮点性能,而是内存—— MI300X 的高带宽内存 (HBM) 速度提高了55%,速度为 5.2TB/秒,容量为 192GB,是 H100 的 80GB 的两倍多。 这对于AI推理非常重要,因为模型的大小与运行它所需的内存量成正比。在 FP16 中,每个参数有 16 位或 2 个字节。因此,对于 Llama 70B,需要大约 140GB+ 的 KV 缓存空间,这有助于加速推理工作负载,但需要额外的内存。
AMD 的 MI300X 平台可支持具有多达 8 个加速器的系统,HBM 总量为 1.5TB,而英伟达的 HGX 平台最高才 640 GB。 正如 SemiAnalysis 在其 MI300X 发布报道中指出的那样,在 FP16 上,具有 1760 亿参数的Bloom 模型需要 352GB 内存,从而为 AMD 留下更多内存以适应更大的batch size大小。
英伟达彻底慌了
英伟达一般是不会和AMD掐架的,但这次可能是真的慌了。
因为在AMD的发布会当天,Meta和微软表示,他们将购买使用AMD最新的AI芯片 Instinct MI300X,这意味着在英伟达显卡缺货的情况下,AMD应成为最优先的替代品。
下图是研究公司 Omidia 最近的一份报告,显示了英伟达2023年Q3季度Top12的H100显卡购买客户:
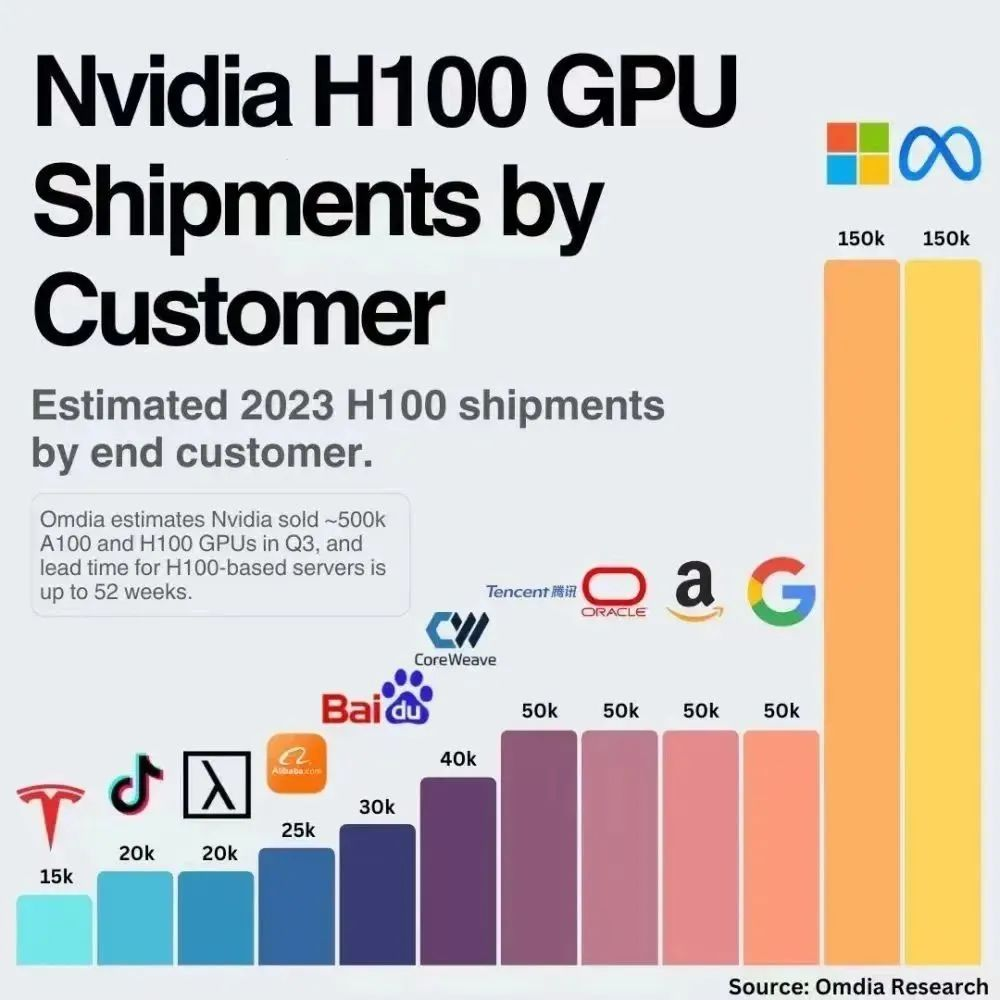
而这些大客户都有可能面临流失的风险。
夕小瑶科技说前不久刚写了一篇文章「英伟达危机大爆发!一夜之间,四面楚歌 」,深度分析了英伟达现在面临的对手和危机(感兴趣的朋友可以移步查看)。
1、AMD正面挑战英伟达显卡霸主地位;
2、微软自研AI芯片,软件硬件两手抓;
3、谷歌坚持自用TPU,打造下一代最强TPU;
4、美国政府对英伟达的限令,禁售中国大陆,将失去百度阿里抖音客户;
5、OpenAI等创业公司正在研发自己的AI芯片。
行业会等待英伟达吗?英伟达的“显卡蛋糕”将被分食多少?

答案或许不乐观,但是英伟达依旧可能是Top赢家。