Nginx-02
- (五)、Nginx负载均衡
- 1.负载均衡概述
- 2.负载均衡的原理及处理流程
- (1).负载均衡的作用
- 3.负载均衡常用的处理方式
- (1).用户手动选择
- (2).DNS轮询方式
- (3).四/七层负载均衡
- (4).Nginx七层负载均衡指令 ⭐
- (5).Nginx七层负载均衡的实现流程 ⭐
- 4.负载均衡状态
- (1).down (停用)
- (2).backup (哨兵服务器)
- (3).max_conns
- (4).max_fails和fail_timeout
- 5.负载均衡策略
- (1).轮询
- (2).weight (轮询)
- (3).ip_hash (哈希主机定位)
- (4).least_conn (最少连接)
- (5).url_hash (哈希路径定位)
- (6).fair (智能)
- 6.负载均衡案例_七层
- (1).对所有请求实现一般轮询规则的负载均衡
- (2).对所有请求实现加权轮询规则的负载均衡
- (3).对特定资源实现负载均衡
- (4).对不同域名实现负载均衡
- (5).实现带有URL重写的负载均衡
- 7.负载均衡_四层
- (1).添加stream模块的支持
- (2).Nginx四层负载均衡的指令
- (3).四层负载均衡的案例_需求分析
- (六)、Nginx缓存集成
- 1.缓存的概念
- 2.Nginx的web缓存服务
- 3.Nginx缓存设置的相关指令
- (1).proxy_cache_path
- (2).proxy_cache
- (3).proxy_cache_key
- (4).proxy_cache_valid
- (5).proxy_cache_min_uses
- (6).proxy_cache_methods
- 4. Nginx缓存设置案例
- (1).需求分析
- (2).步骤实现
- (3).完整配置
- 5.Nginx缓存的清除
- (1).方式一: 删除对应的缓存目录
- (2).方式二: 使用第三方扩展模块
- 6.Nginx设置资源不缓存
- (1). `$cookie_nocache`、`$arg_nocache`、`$arg_comment`
- (2).示列
- (七)、Nginx实现服务器端集群搭建
- 1.Nginx与Tomcat部署
- (1).环境准备(Tomcat)
- (2).环境准备(Nginx)
- 2.Nginx实现动静分离
- (1).需求分析
- (2).动静分离实现步骤
- 3.Nginx实现Tomcat集群搭建
- (1).环境准备:
- (2).配置信息
- (3).测试tomcat集群
- 4.Nginx高可用解决方案
- (1).Keepalived
- (2).VRRP介绍
- (3).环境搭建 ⭐
- (4).下载 Keepalived
- (5).Keepalived配置文件介绍
- (6).keppalived 自定义配置 ⭐⭐
- (7).自定义配置后访问测试 ⭐⭐⭐
- (8).keepalived之自动切换脚本
- 5.Nginx制作下载站点
- (1).autoindex:启用或禁用目录列表输出
- (2).autoindex_exact_size:对应HTLM格式,指定是否在目录列表展示文件的详细大小
- (3).autoindex_format:设置目录列表的格式
- (4).autoindex_localtime:对应HTML格式,是否在目录列表上显示时间。
- (4).测试
- 6.Nginx的用户认证模块
- (1).auth_basic:使用“ HTTP基本认证”协议启用用户名和密码的验证
- (2).auth_basic_user_file:指定用户名和密码所在文件
- (八)、Lua
- 1.基本介绍
- (1).Lua的基本概念
- (2).Lua的特性
- (3).应用场景
- 2.Lua的安装与编译
- (1).找到Lua官网
- (2).进行编译与安装
- 3.Lua的语法
- (1).Lua的两种交互方式
- (2).Lua的注释
- (3).标识符
- (4).关键字
- (5).运算符
- (6).全局变量&局部变量
- 4.Lua数据类型
- (1).nil (空值)
- (2).boolean (布尔)
- (3).number (数值)
- (4).string (字符串)
- (5).table (表)
- (6).function (函数)
- (7).thread (线程)
- (8).userdata (用户数据)
- 5.Lua控制结构
- (1).if then elseif else
- (2).while循环 (先判断在执行)
- (3).repeat循环 (先执行在判断条件)
- (4).for循环
- (九)、ngx_lua模块概念
- 1.ngx_lua模块环境准备
- (1).方式一:lua-nginx-module
- (2).方式二: OpenRestry (推荐⭐)
- 2.ngx_lua的使用
- (1).init_by_lua*
- (2).init_worker_by_lua*
- (3).set_by_lua*
- (4).rewrite_by_lua*
- (5).access_by_lua*
- (6).content_by_lua*
- (7).header_filter_by_lua*
- (8).body_filter_by_lua*
- (9).log_by_lua*
- (10).balancer_by_lua*
- (11).ssl_certificate_by_*
(五)、Nginx负载均衡
1.负载均衡概述
早期的网站流量和业务功能都比较简单,单台服务器足以满足基本的需求,但是随着互联网的发展,业务流量越来越大并且业务逻辑也跟着越来越复杂,单台服务器的性能及单点故障问题就凸显出来了,因此需要多台服务器进行性能的水平扩展及避免单点故障出现。那么如何将不同用户的请求流量分发到不同的服务器上呢?
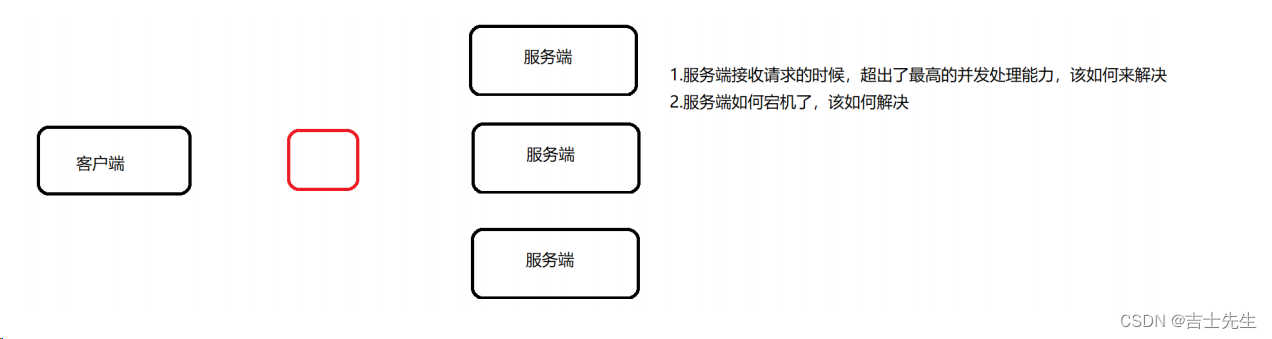
2.负载均衡的原理及处理流程
系统的扩展可以分为纵向扩展和横向扩展。
- 纵向扩展是从单机的角度出发,通过
增加系统的硬件处理能力来提升服务器的处理能力。 - 横向扩展是通过
添加机器来满足大型网站服务的处理能力。

这里面涉及到两个重要的角色分别是"应用集群"和"负载均衡器"。
- 应用集群:将
同一应用部署到多台机器上,组成处理集群,接收负载均衡设备分发的请求,进行处理并返回响应的数据。 - 负载均衡器: 将用户访问的请求
根据对应的负载均衡算法,分发到集群中的一台服务器进行处理。
(1).负载均衡的作用
- 解决服务器的高并发压力,提高应用程序的处理性能。
- 提供故障转移,实现高可用。
- 通过添加或减少服务器数量,增强网站的可扩展性。
- 在负载均衡器上进行过滤,可以提高系统的安全性。
3.负载均衡常用的处理方式
(1).用户手动选择
这种方式比较原始,只要实现的方式就是在网站主页上面提供不同线路、不同服务器链接方式,让用户来选择自己访问的具体服务器,来实现负载均衡。
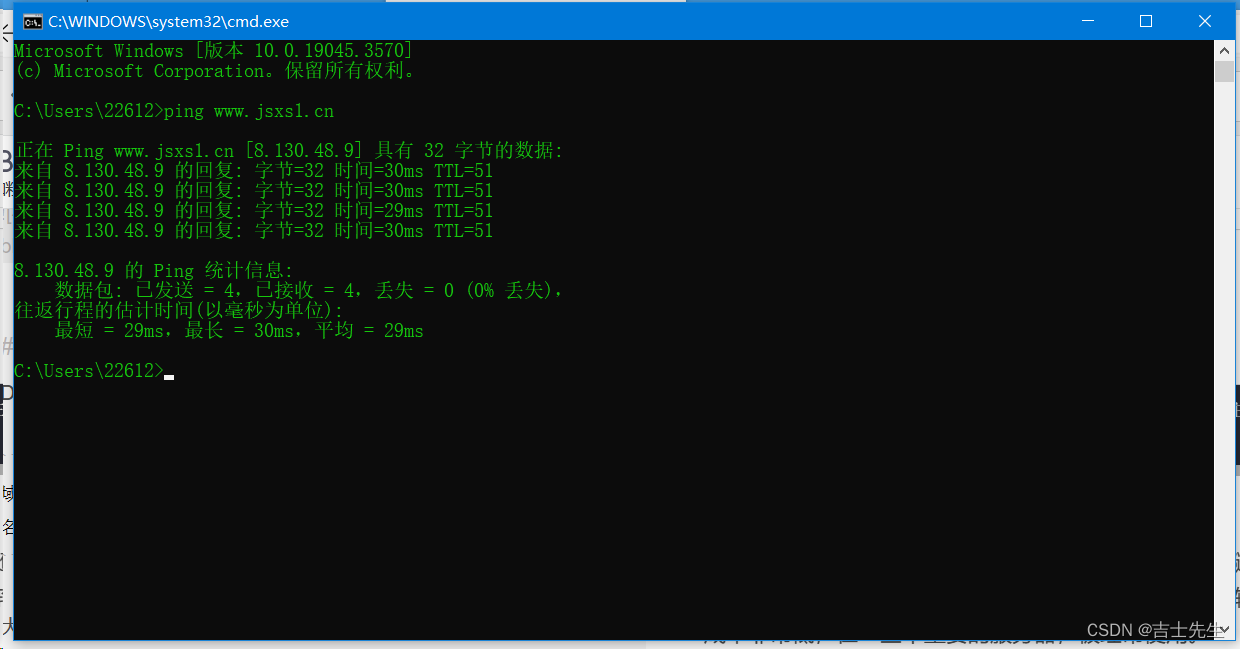
(2).DNS轮询方式
DNS
域名系统(服务)协议(DNS)是一种分布式网络目录服务,主要用于域
名与 IP 地址的相互转换。
大多域名注册商都支持对同一个主机名添加多条A记录 (也就是说一个域名可以绑定多个IP主机地址),这就是DNS轮询,DNS服务器将解析请求按照A记录的顺序,随机分配到不同的IP上,这样就能完成简单的负载均衡。DNS轮询的成本非常低,在一些不重要的服务器,被经常使用。
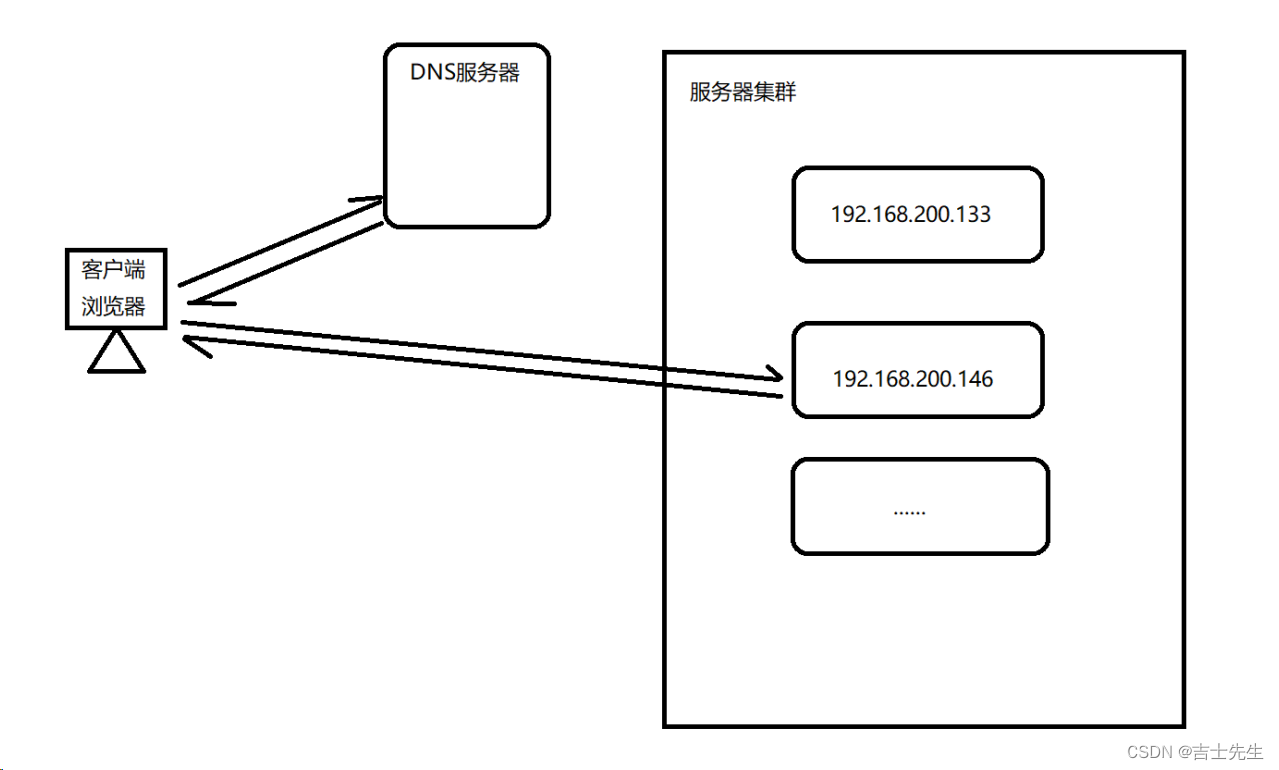
我们发现使用DNS来实现轮询,不需要投入过多的成本,虽然DNS轮询成本低廉,但是DNS负载均衡存在明显的缺点。
- 可靠性低
假设一个域名DNS轮询多台服务器,如果其中的一台服务器发生故障,那么所有的访问该服务器的请求将不会有所回应,即使你将该服务器的IP从DNS中去掉,但是由于各大宽带接入商将众多的DNS存放在缓存中,以节省访问时间,导致DNS不会实时更新。所以DNS轮流上一定程度上解决了负载均衡问题,但是却存在可靠性不高的缺点。
- 负载均衡不均衡
DNS负载均衡采用的是简单的轮询负载算法,不能区分服务器的差异,不能反映服务器的当前运行状态,不能做到为性能好的服务器多分配请求,另外本地计算机也会缓存已经解析的域名到IP地址的映射,这也会导致使用该DNS服务器的用户在一定时间内访问的是同一台Web服务器,从而引发Web服务器减的负载不均衡。
负载不均衡则会导致某几台服务器负荷很低,而另外几台服务器负荷确很高,处理请求的速度慢,配置高的服务器分配到的请求少,而配置低的服务器分配到的请求多。
(3).四/七层负载均衡
介绍四/七层负载均衡之前,我们先了解一个概念,OSI(open system interconnection),叫开放式系统互联模型,这个是由国际标准化组织ISO指定的一个不基于具体机型、操作系统或公司的网络体系结构。该模型将网络通信的工作分为七层。
两台电脑想要交互,需要先从应用层搭到物理层执行一遍,然后接收方再从物理层到应用层再执行一遍。
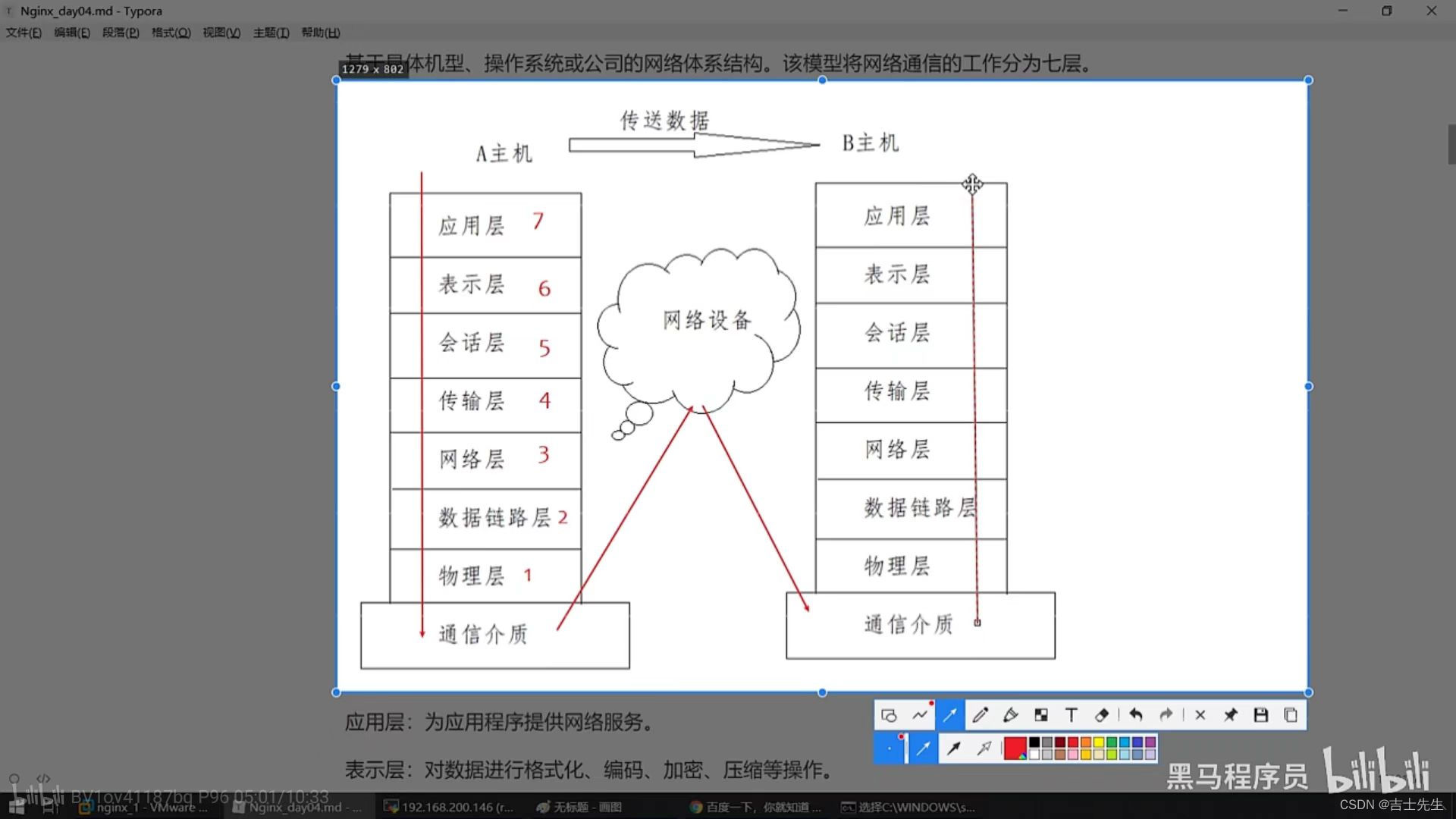
- 应用层:为应用程序提供网络服务。 (QQ)
- 表示层:对数据进行格式化、编码、加密、压缩等操作。
- 会话层:建立、维护、管理会话连接。
- 传输层:建立、维护、管理端到端的连接,常见的有TCP/UDP。
- 网络层:IP寻址和路由选择。
- 数据链路层:控制网络层与物理层之间的通信。(光纤)
- 物理层:比特流传输。(信息)
所谓四层负载均衡指的是OSI七层模型中的传输层,主要是基于IP+PORT 的负载均衡。
实现四层负载均衡的方式:
硬件:F5 BIG-IP、Radware等
软件:LVS、Nginx、Hayproxy等
所谓的七层负载均衡指的是在应用层,主要是基于虚拟的URL或主机IP的负载均衡
实现七层负载均衡的方式:
软件:Nginx、Hayproxy等
四层和七层负载均衡的区别
四层负载均衡数据包是在底层就进行了分发,而七层负载均衡数据包则在
最顶端进行分发,所以四层负载均衡的效率比七层负载均衡的要高。
四层负载均衡不识别域名,而七层负载均衡识别域名。
处理四层和七层负载以为其实还有二层、三层负载均衡,二层是在 数据链路层基于mac地址 来实现负载均衡,三层是在网络层一般采用 虚拟IP地址 的方式实现负载均衡。
实际环境采用的模式
四层负载(LVS)+七层负载(Nginx)
(4).Nginx七层负载均衡指令 ⭐
Nginx要实现七层负载均衡需要用到 proxy_pass 代理模块配置。Nginx默认安装支持这个模块,我们不需要再做任何处理。Nginx的负载均衡是在Nginx的反向代理基础上把用户的请求根据指定的算法分发到一组【upstream虚拟服务池】。
- upstream指令
该指令是用来定义一组服务器,它们可以是监听不同端口的服务器,并且也可以是同时监听 TCP和Unix socke t的服务器。服务器可以指定不同的权重,默认为1。

- server指令
该指令用来指定后端服务器的名称和一些参数,可以使用域名、IP、端口或者unix socket

(5).Nginx七层负载均衡的实现流程 ⭐
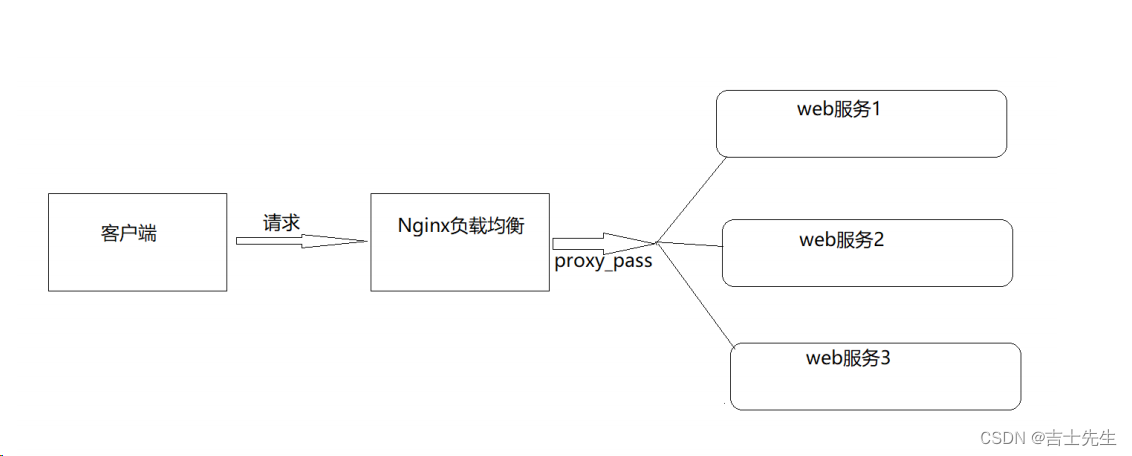
服务端配置:
server {listen 8081;server_name localhost;default_type text/html;location / {return 200 '<h1>8.130.48.9:8081</h1>';}}server {listen 8082;server_name localhost;default_type text/html;location / {return 200 '<h1>8.130.48.9:8082</h1>';}}server {listen 8083;server_name localhost;default_type text/html;location / {return 200 '<h1>8.130.48.9:8083</h1>';}}负载均衡服务端(代理服务端)
# 这里是配置我们的服务组⭐
upstream backend{server 8.130.48.9:8081;server 8.130.48.9:8082;server 8.130.48.9:8083;
}
# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}

测试: http://8.130.48.9:8084/
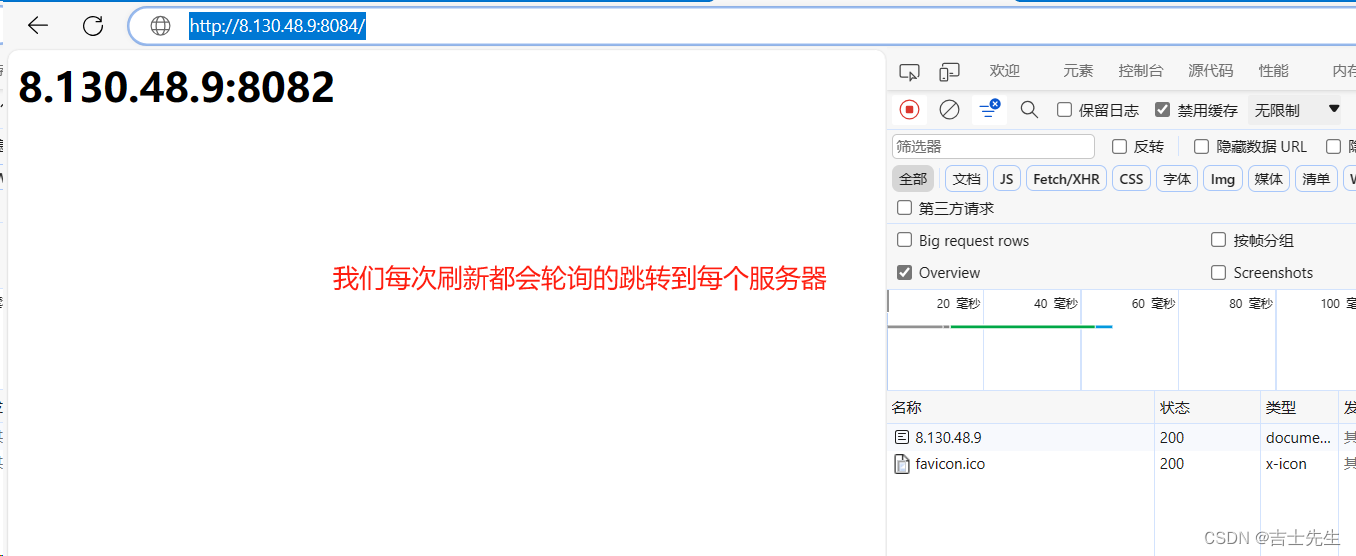
4.负载均衡状态
代理服务器在负责均衡调度中的状态有以下几个:

(1).down (停用)
down:将该服务器标记为永久不可用,那么该代理服务器将不参与负载均衡。
# 在我们的服务组中设置状态
upstream backend{server 192.168.200.146:9001 down;server 192.168.200.146:9002server 192.168.200.146:9003;
}
server {listen 8083;server_name localhost;location /{proxy_pass http://backend;}
}
该状态一般会对需要停机维护的服务器进行设置
(2).backup (哨兵服务器)
将该服务器标记为备份服务器,当主服务器不可用时,将用来传递请求。
# 在我们的服务组中设置状态
upstream backend{server 192.168.200.146:9001 down;server 192.168.200.146:9002 backup;server 192.168.200.146:9003;
}
server {listen 8083;server_name localhost;location /{proxy_pass http://backend;}
}
此时需要将9093端口的访问禁止掉来模拟下唯一能对外提供访问的服务宕机以后,backup的备份服务器9002就要开始对外提供服务,如果主服务器9003没有宕机的话,那么备份服务(9002)是不参与服务提供的,如果主服务器一段时间后又恢复了,那么备份服务器(9002)会将权力还给主服务器(9003),假如说此时为了测试验证,我们需要使用防火墙来进行拦截。
介绍一个工具firewall-cmd ,该工具是Linux提供的专门用来操作
firewall的。
查询防火墙中指定的端口是否开放
firewall-cmd --query-port=9001/tcp
如何开放一个指定的端口
firewall-cmd --permanent --add-port=9002/tcp
批量添加开发端口
firewall-cmd --permanent --add-port=9001-9003/tcp
如何移除一个指定的端口
firewall-cmd --permanent --remove-port=9003/tcp
重新加载
firewall-cmd --reload
其中
- –permanent表示设置为持久
- –add-port表示添加指定端口
- –remove-port表示移除指定端口
(3).max_conns
用来设置代理服务器同时活动链接的最大数量,默认为0,表示不限制,使用该配置可以根据后端服务器处理请求的并发量来进行设置,防止后端服务器被压垮。
(4).max_fails和fail_timeout
- max_fails=number:设置允许请求代理服务器失败的次数,默认为1。
- fail_timeout=time:设置经过max_fails失败后,服务暂停的时间,默认是10秒。
upstream backend{server 192.168.200.133:9001 down;server 192.168.200.133:9002 backup;server 192.168.200.133:9003 max_fails=3 fail_timeout=15;
}
server {listen 8083;server_name localhost;location /{proxy_pass http://backend;}
}
如果说9003服务器出现三次问题宕机了,那么先暂停15秒这个主服务器的服务,把提供服务的权利让给其他服务器,如果说在15秒内这个服务器能启动了,那么这个主服务器仍然不能提供服务,直到15秒时间过了,才能恢复服务。假如说我们超过了15秒问题依然没解决,那么9003服务器再停机15秒。
5.负载均衡策略
介绍完Nginx负载均衡的相关指令后,我们已经能实现将用户的请求分发到不同的服务器上,那么除了采用默认的分配方式以外,我们还能采用什么样的负载算法?
Nginx的upstream支持如下六种方式的分配算法,分别是:
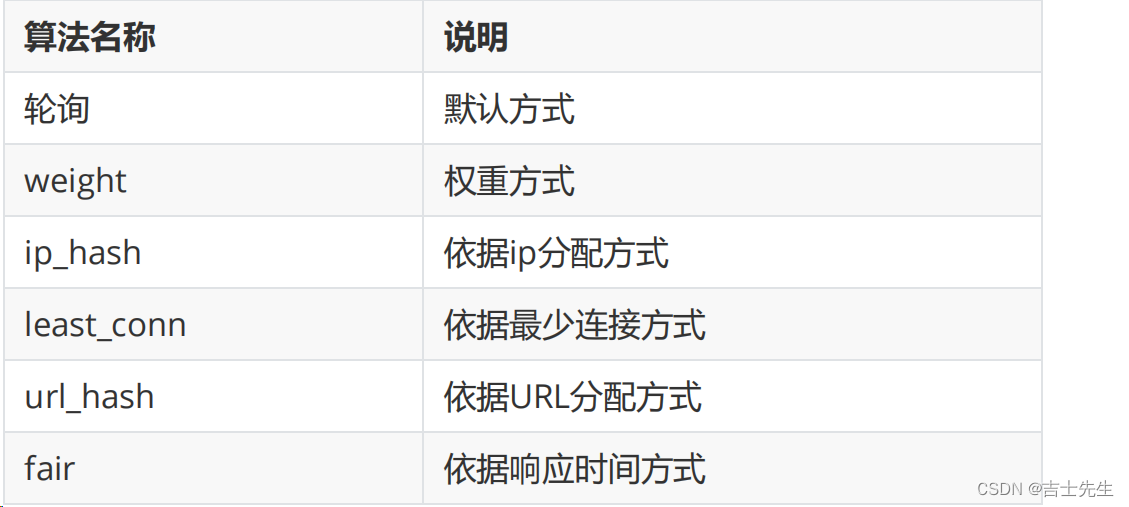
(1).轮询
是upstream模块负载均衡默认的策略。每个请求会按时间顺序逐个分配到不同的后端服务器。轮询不需要额外的配置。
# 这里是配置我们的服务组⭐
upstream backend{server 8.130.48.9:8081;server 8.130.48.9:8082;server 8.130.48.9:8083;
}
# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}
(2).weight (轮询)
用来设置服务器的权重,默认为1,权重数据越大,被分配到请求的几率越大;该权重值,主要是针对实际工作环境中不同的后端服务器硬件配置进行调整的,所有此策略比较适合服务器的硬件配置差别比较大的情况。
# 这里是配置我们的服务组⭐
upstream backend{server 8.130.48.9:8081 weight=10;server 8.130.48.9:8082 weight=5;server 8.130.48.9:8083 weight=3;
}
# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}
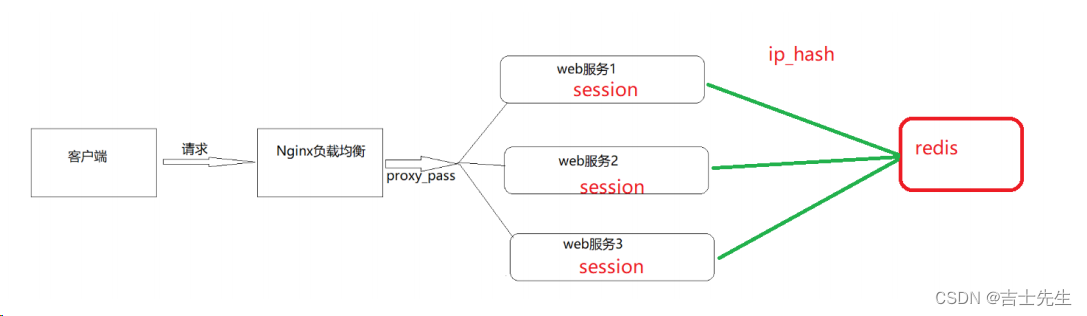
(3).ip_hash (哈希主机定位)
当对后端的多台动态应用服务器做负载均衡时,ip_hash指令能够将某个客户端IP的请求通过哈希算法定位到同一台后端服务器上。这样,当来自某一个IP的用户在后端Web服务器A上登录后,在访问该站点的其他URL,能保证其访问的还是后端web服务器A。
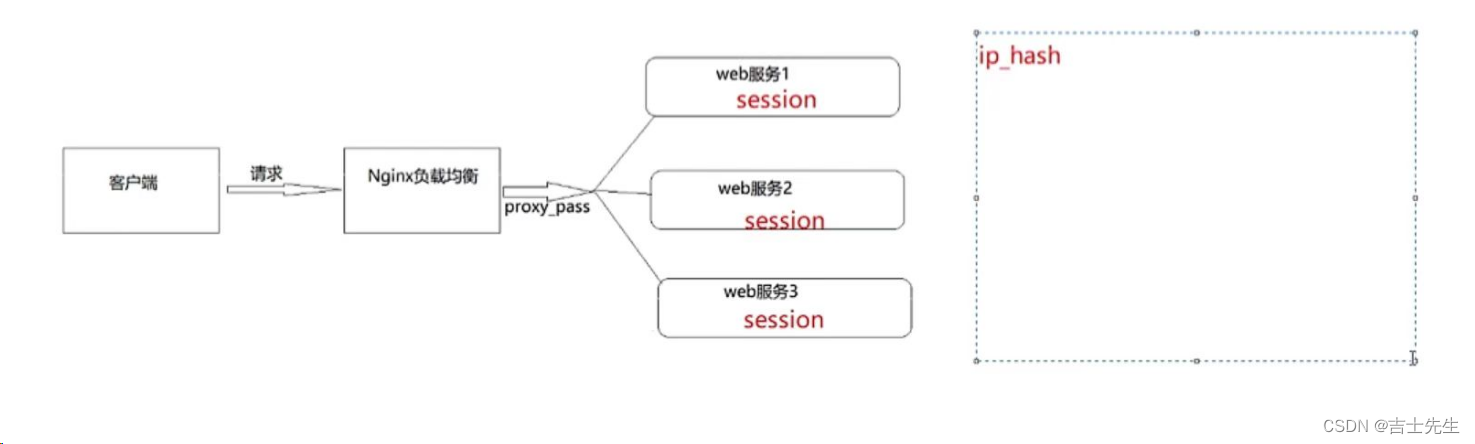
# 这里是配置我们的服务组⭐
upstream backend{ip_hash;server 8.130.48.9:8081;server 8.130.48.9:8082;server 8.130.48.9:8083;
}
# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}
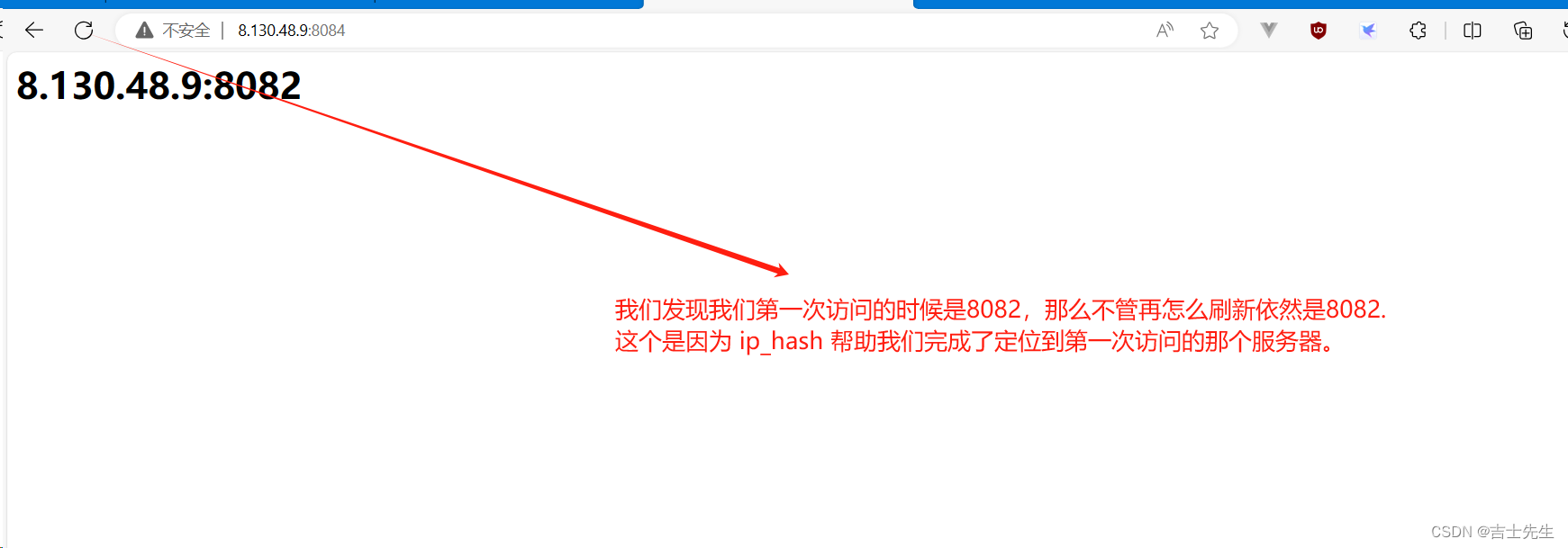
需要额外多说一点的是使用 ip_hash 指令无法保证后端服务器的负载均衡,可能导致有些后端服务器接收到的请求多,有些后端服务器接收的请求少,而且设置后端服务器权重等方法将不起作用。
正解: 使用我们的Redis缓存的操作。
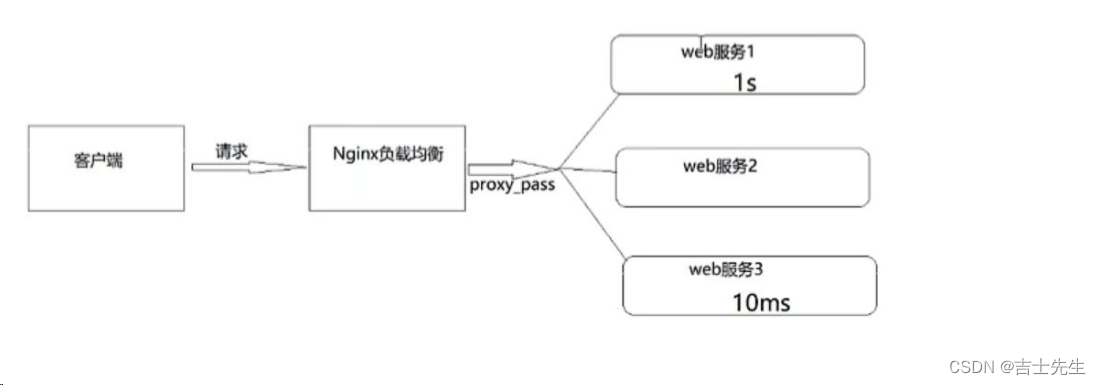
(4).least_conn (最少连接)
最少连接,把请求转发给连接数较少的后端服务器。轮询算法是把请求平均的转发给各个后端,使它们的负载大致相同;但是,有些请求占用的时间很长,会导致其所在的后端负载较高。如果继续采用轮询算法的话,那么服务器也会进行崩溃的,这种情况下,least_conn这种方式就可以达到更好的负载均衡效果。
此负载均衡策略适合请求处理时间长短不一造成服务器过载的情况。
# 这里是配置我们的服务组⭐
upstream backend{least_conn;server 8.130.48.9:8081;server 8.130.48.9:8082;server 8.130.48.9:8083;
}
# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}
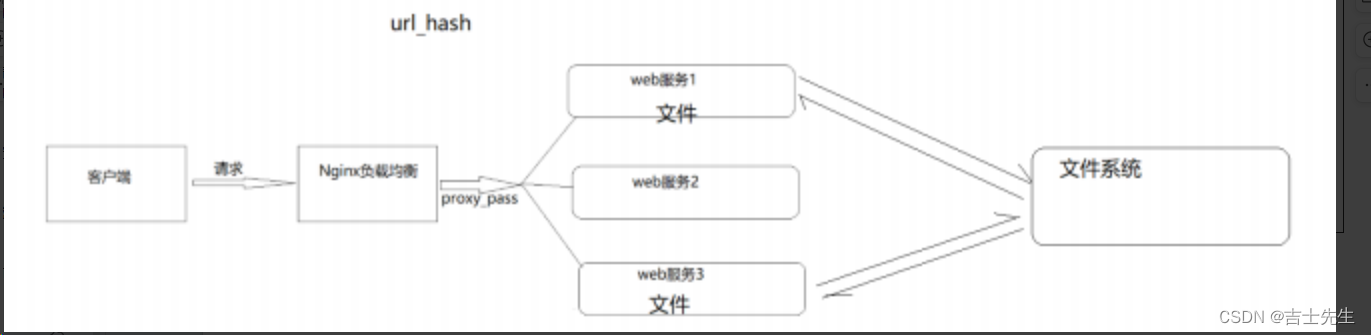
(5).url_hash (哈希路径定位)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,要配合缓存命中来使用。同一个资源多次请求,可能会到达不同的服务器上,导致不必要的多次下载,缓存命中率不高,以及一些资源时间的浪费。而使用url_hash,可以使得同一个url(也就是同一个资源请求)会到达同一台服务器,一旦缓存住了资源,再此收到请求,就可以从缓存中读取。
# 这里是配置我们的服务组⭐
upstream backend{hash &request_uri;server 8.130.48.9:8081;server 8.130.48.9:8082;server 8.130.48.9:8083;
}
# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}
(6).fair (智能)
fair采用的不是内建负载均衡使用的轮换的均衡算法,而是可以根据页面大小、加载时间长短智能的进行负载均衡。那么如何使用第三方模块的fair负载均衡策略。
# 这里是配置我们的服务组⭐
upstream backend{fair;server 8.130.48.9:8081;server 8.130.48.9:8082;server 8.130.48.9:8083;
}
# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}
但是如何直接使用会报错,因为fair属于第三方模块实现的负载均衡。需要添加 nginx-upstream-fair ,如何添加对应的模块:
- 安装支持
下载地址为: https://github.com/gnosek/nginx-upstream-fair
# 1.创建目录
cd /root
mkdir model
cd model
# 2.解压压缩包 (zip压缩包)
unzip nginx-upstream-fair-master.zip
# 3.名字有点长,改个短点的名字
mv nginx-upstream-fair-master fair

fari所在的文件位置: /root/model/fair
# 4.进入我们的nginx目录下
cd /root/nginx/core/nginx-1.16.1/
# 5.查看我们以前的配置
[root@Jsxs nginx-1.16.1]# nginx -V
nginx version: nginx/1.16.1
built by gcc 10.2.1 20200825 (Alibaba 10.2.1-3.5 2.32) (GCC)
built with OpenSSL 1.1.1k FIPS 25 Mar 2021
TLS SNI support enabled
configure arguments: --prefix=/usr/local/nginx --sbin-path=/usr/local/nginx/sbin/nginx --modules-path=/usr/local/nginx/modules --conf-path=/usr/local/nginx/conf/nginx.conf --error-log-path=/usr/local/nginx/logs/error.log --http-log-path=/usr/local/nginx/logs/access.log --pid-path=/usr/local/nginx/logs/nginx.pid --lock-path=/usr/local/nginx/logs/nginx.lock --with-http_gzip_static_module --with-http_ssl_module
# 6.然后执行重新安装 :新增-> --add-module=/root/model/fair
./configure --prefix=/usr/local/nginx --sbin-path=/usr/local/nginx/sbin/nginx --modules-path=/usr/local/nginx/modules --conf-path=/usr/local/nginx/conf/nginx.conf --error-log-path=/usr/local/nginx/logs/error.log --http-log-path=/usr/local/nginx/logs/access.log --pid-path=/usr/local/nginx/logs/nginx.pid --lock-path=/usr/local/nginx/logs/nginx.lock --with-http_gzip_static_module --with-http_ssl_module --add-module=/root/model/fair
# 7.进行编译:
make
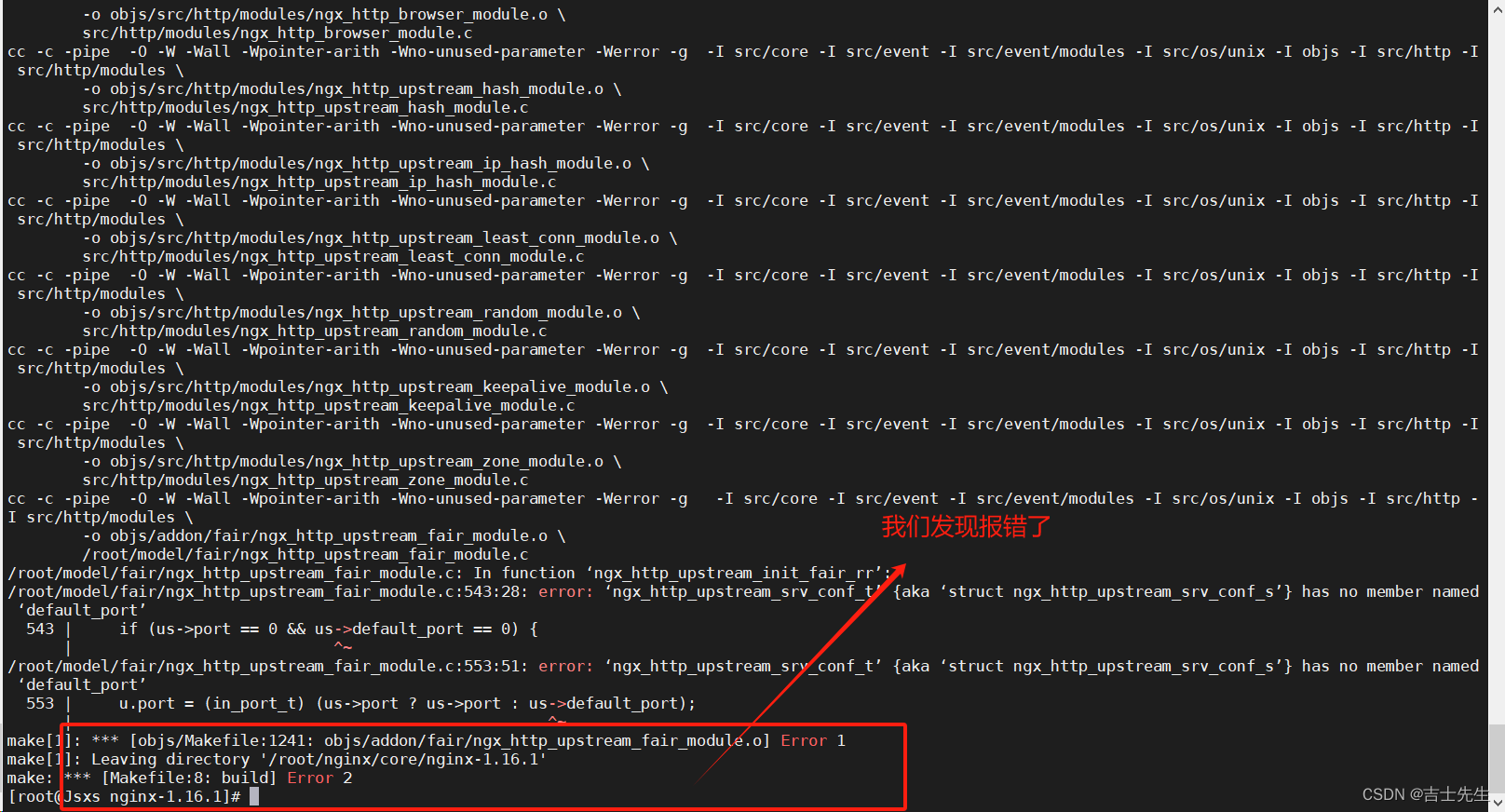
- 解决报错问题
在Nginx的源码中 src/http/ngx_http_upstream.h,找到ngx_http_upstream_srv_conf_s,在模块中添加添加 default_port属性。
in_port_t default_port
# 1.重写指定文件
vim /root/nginx/core/nginx-1.16.1/src/http/ngx_http_upstream.h
# 2.查找 ngx_http_upstream_srv_conf_s
/ngx_http_upstream_srv_conf_s
# 3.然后回车按 n 找到一个结构体
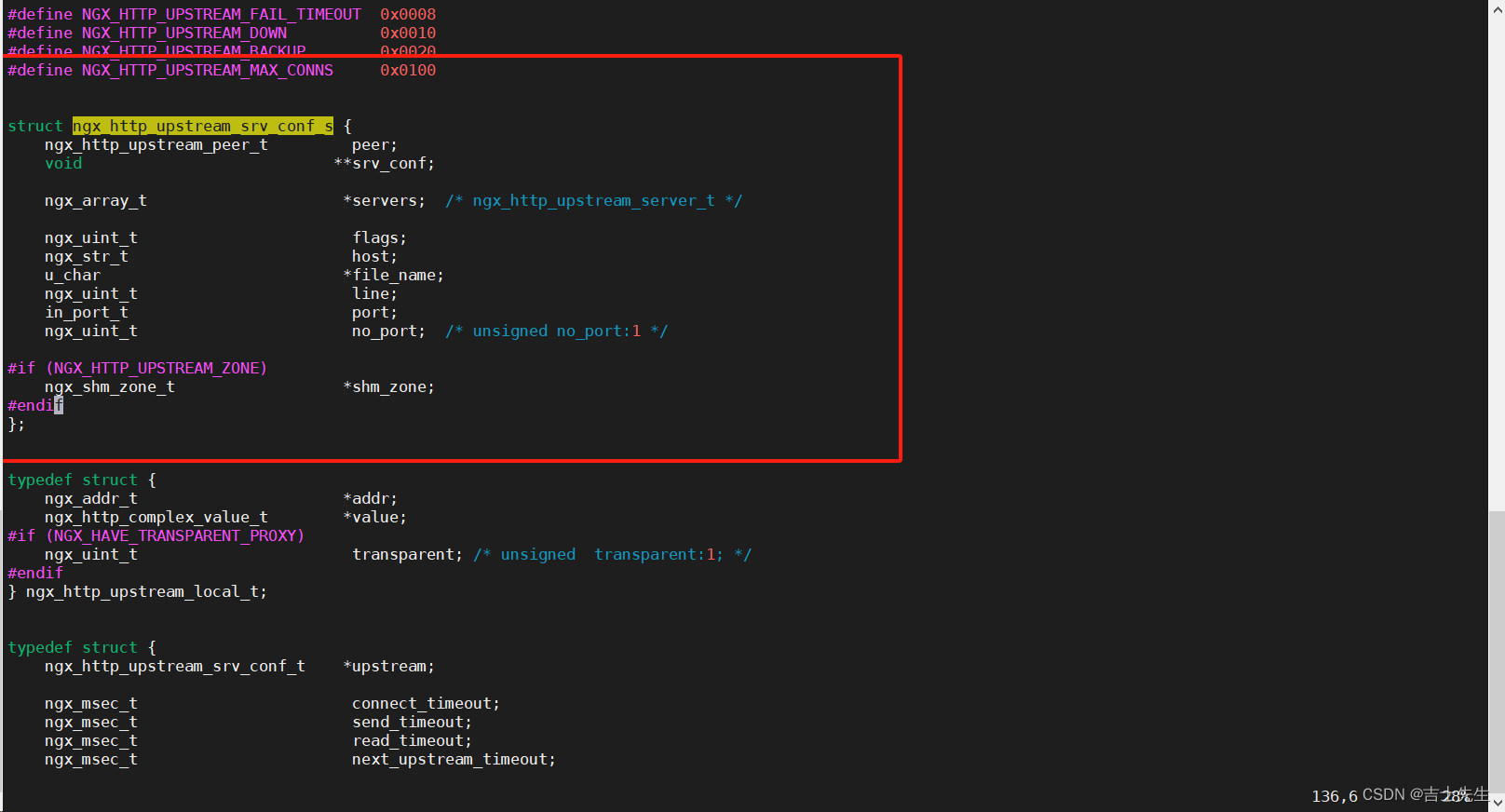
#4. 添加属性
in_port_t default_port;

# 5.回退到根目录
cd /root/nginx/core/nginx-1.16.1
# 6.重新执行编译
make
# 7.将旧的nginx进行备份
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginxold;
# 8.make成功后会生成一个objs目录,里面放有新的nginx运行文件
cd /root/nginx/core/nginx-1.16.1/objs
cp nginx /usr/local/nginx/sbin
# 9.回退到根目录
cd /root/nginx/core/nginx-1.16.1
# 10.进行平滑升级
make upgrade
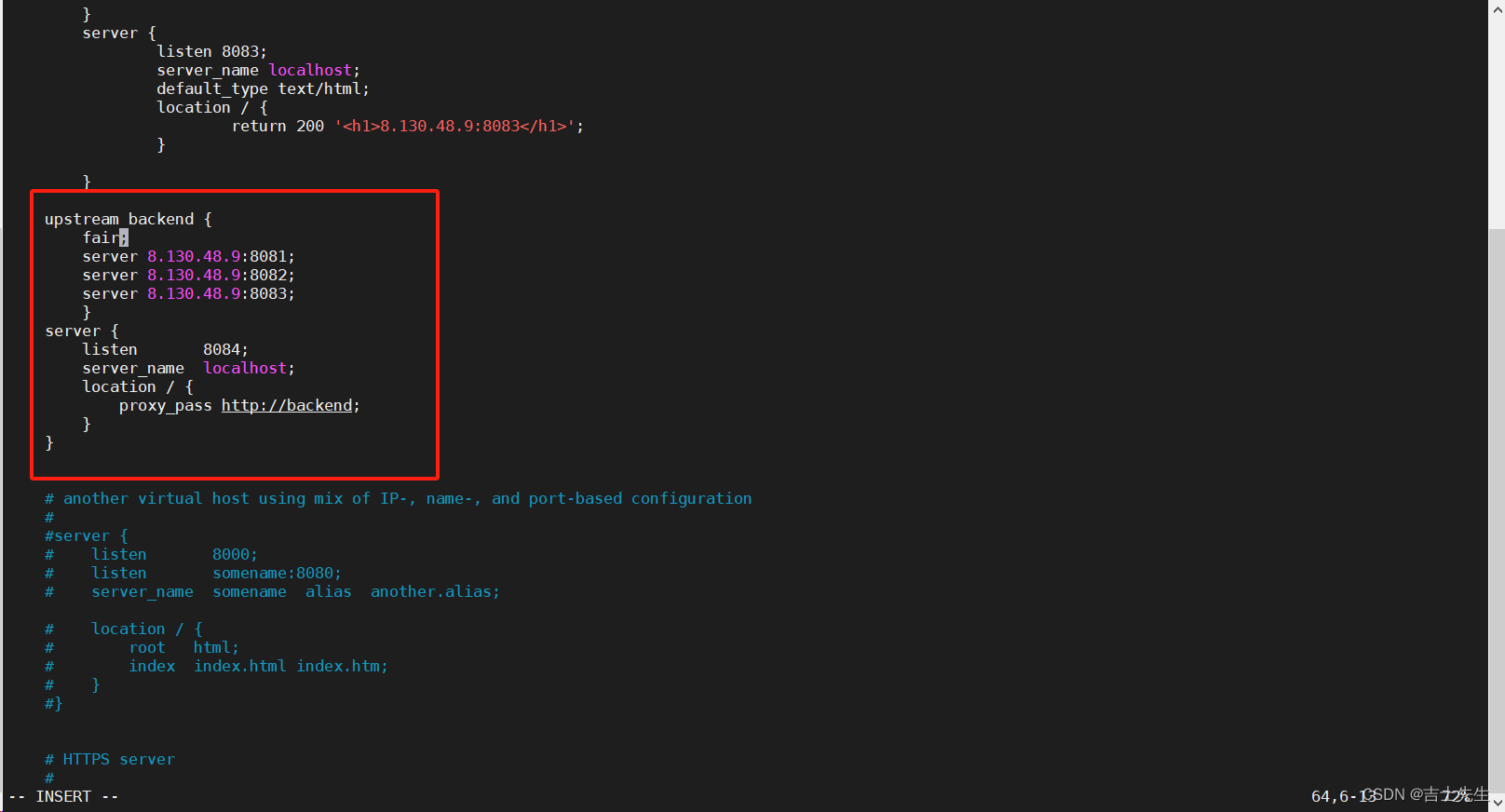
测试: http://8.130.48.9:8084/
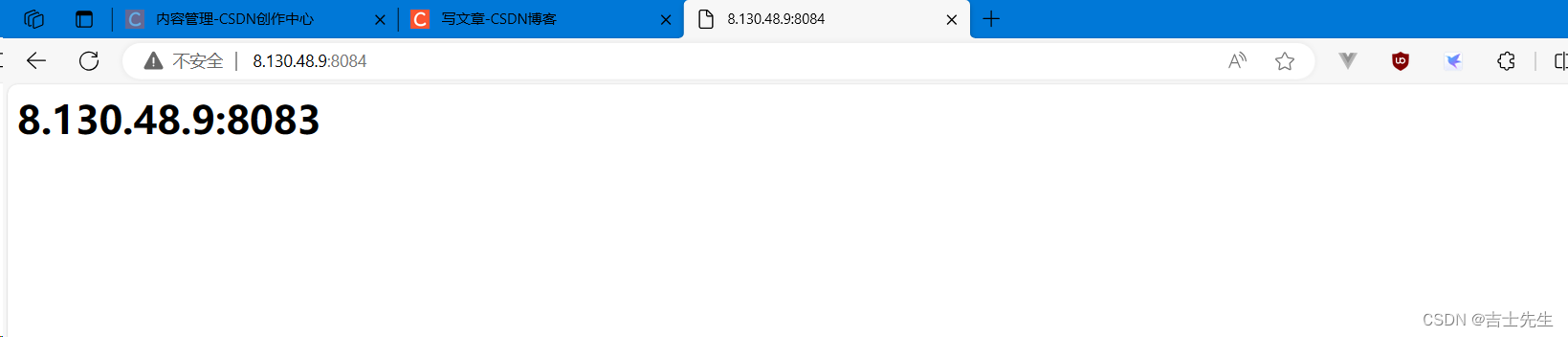
上面介绍了Nginx常用的负载均衡的策略,有人说是5种,是把轮询和加权轮询归为一种,也有人说是6种。那么在咱们以后的开发中到底使用哪种,这个需要根据实际项目的应用场景来决定的。
6.负载均衡案例_七层
(1).对所有请求实现一般轮询规则的负载均衡
# 这里是配置我们的服务组⭐
upstream backend{server 8.130.48.9:8081;server 8.130.48.9:8082;server 8.130.48.9:8083;
}
# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}
(2).对所有请求实现加权轮询规则的负载均衡
# 这里是配置我们的服务组⭐
upstream backend{server 8.130.48.9:8081 weight=10;server 8.130.48.9:8082 weight=5;server 8.130.48.9:8083 weight=3;
}# 服务组名称为 backend⭐
server {listen 80;server_name localhost;location /{proxy_pass http://backend;}
}
(3).对特定资源实现负载均衡
upstream videobackend{server 192.168.200.146:9001;server 192.168.200.146:9002;
}
upstream filebackend{server 192.168.200.146:9003;server 192.168.200.146:9004;
}
server {listen 8084;server_name localhost;location /video/ {proxy_pass http://videobackend;}location /file/ {proxy_pass http://filebackend;}
}
(4).对不同域名实现负载均衡
upstream itcastbackend{server 192.168.200.146:9001;server 192.168.200.146:9002;
}
upstream itheimabackend{server 192.168.200.146:9003;server 192.168.200.146:9004;
}server {listen 8085;server_name www.itcast.cn;location / {proxy_pass http://itcastbackend;}}
server {listen 8086;server_name www.itheima.cn;location / {proxy_pass http://itheimabackend;}
}
(5).实现带有URL重写的负载均衡
upstream backend{server 192.168.200.146:9001;server 192.168.200.146:9002;server 192.168.200.146:9003;
}server {listen 80;server_name localhost;location /file/ {rewrite ^(/file/.*) /server/$1 last;}location / {proxy_pass http://backend;}
}
7.负载均衡_四层
Nginx在1.9之后,增加了一个stream模块,用来实现四层协议的转发、代理、负载均衡等。stream模块的用法跟http的用法类似,允许我们配置一组TCP或者UDP等协议的监听,然后通过proxy_pass来转发我们的请求,通过upstream添加多个后端服务,实现负载均衡。
四层协议负载均衡的实现,一般都会用到 LVS、HAProxy、F5等,要么很贵要么配置很麻烦,而Nginx的配置相对来说更简单,更能快速完成工作。
(1).添加stream模块的支持
Nginx默认是没有编译这个模块的,需要使用到stream模块,那么需要在编译的时候加上 --with-stream。
完成添加 --with-stream 的实现步骤:
# 1.执行配置 : 这里多添加了--with-stream
./configure --prefix=/usr/local/nginx --sbin-path=/usr/local/nginx/sbin/nginx --modules-path=/usr/local/nginx/modules --conf-path=/usr/local/nginx/conf/nginx.conf --error-log-path=/usr/local/nginx/logs/error.log --http-log-path=/usr/local/nginx/logs/access.log --pid-path=/usr/local/nginx/logs/nginx.pid --lock-path=/usr/local/nginx/logs/nginx.lock --with-http_gzip_static_module --with-http_ssl_module --add-module=/root/model/fair --with-stream
# 2.执行编译
make...
...
...
(2).Nginx四层负载均衡的指令
- stream指令
该指令提供在其中指定流服务器指令的配置文件上下文。和http指令同级。
- upstream指令
该指令和http的upstream指令是类似的。
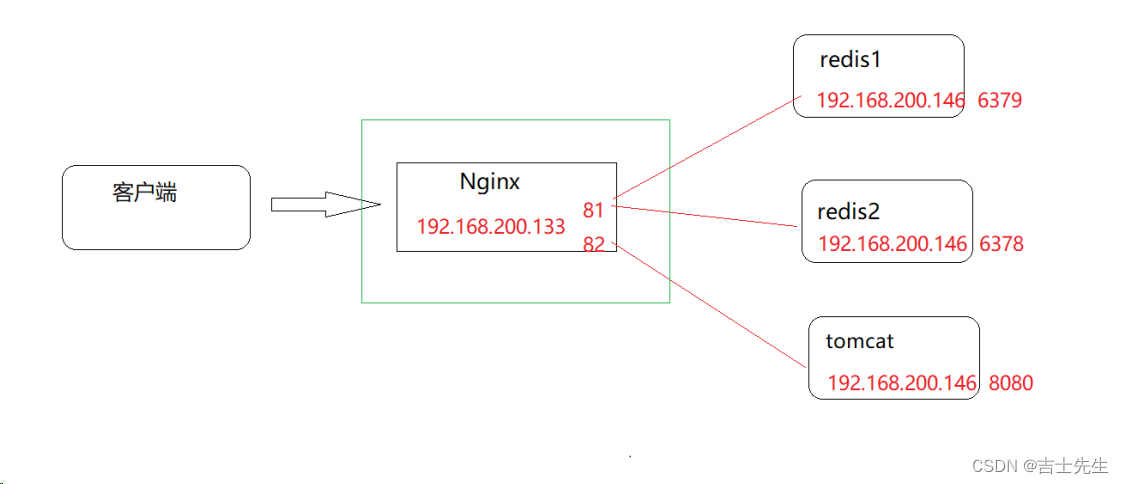
(3).四层负载均衡的案例_需求分析
(六)、Nginx缓存集成
1.缓存的概念
缓存就是数据交换的缓冲区(称作:Cache), 当用户要获取数据的时候,会先从缓存中去查询获取数据,如果缓存中有就会直接返回给用户,如果缓存中没有,则会发请求从服务器重新查询数据,将数据返回给用户的同时将数据放入缓存,下次用户就会直接从缓存中获取数据。
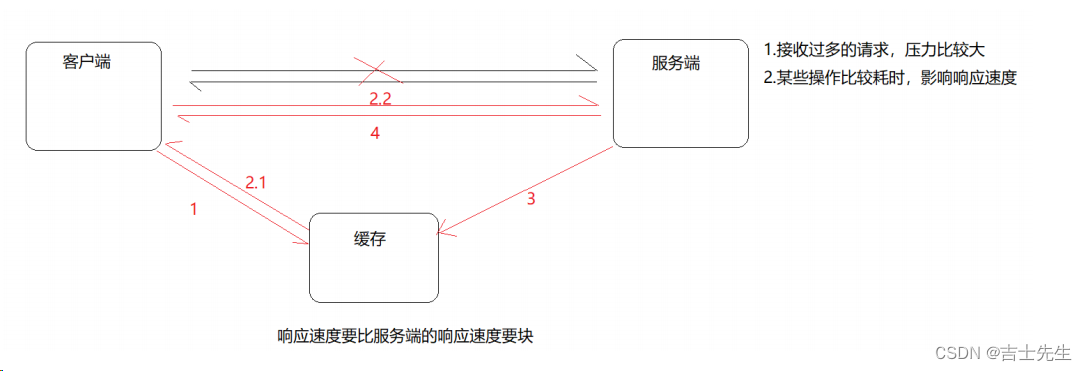
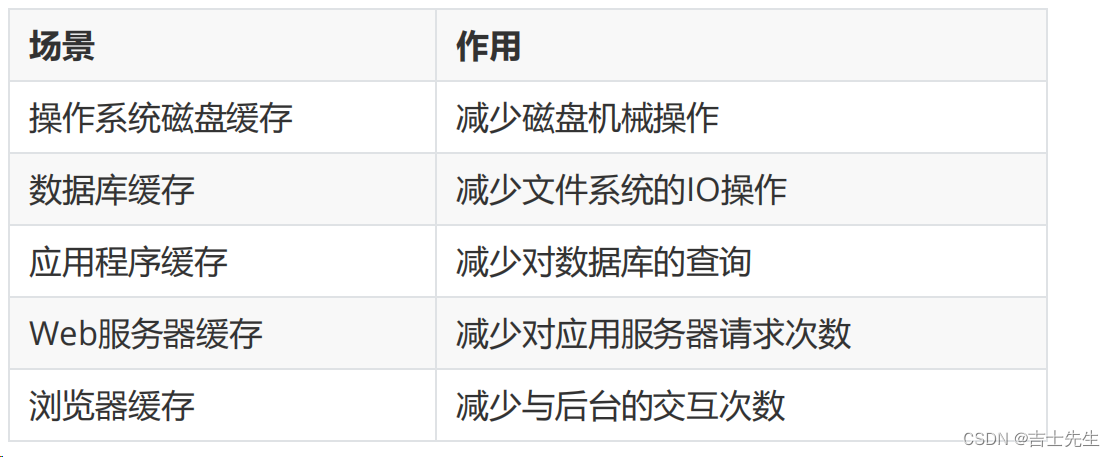
缓存其实在很多场景中都有用到,比如:
- 缓存的优点
- 减少数据传输,节省网络流量,加快响应速度,提升用户体验;
- 减轻服务器压力;
- 提供服务端的高可用性;
- 缓存的缺点
- 数据的同步不一致。
- 增加成本。
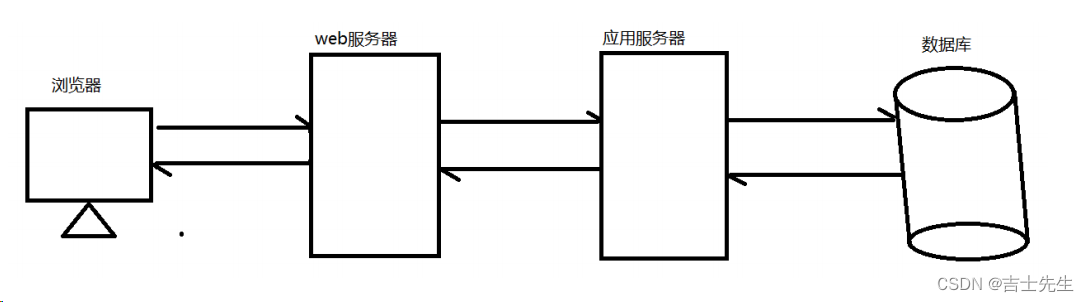
Nginx作为web服务器,Nginx作为Web缓存服务器,它介于客户端和应用服务器之间,当用户通过浏览器访问一个URL时,web缓存服务器会去应用服务器获取要展示给用户的内容,将内容缓存到自己的服务器上,当下一次请求到来时,如果访问的是同一个URL,web缓存服务器就会直接将之前缓存的内容返回给客户端,而不是向应用服务器再次发送请求。web缓存降低了应用服务器、数据库的负载,减少了网络延迟,提高了用户访问的响应速度,增强了用户的体验。
2.Nginx的web缓存服务
Nginx是从0.7.48版开始提供缓存功能。Nginx是基于Proxy Store来实现的,1.其原理是把URL及相关组合当做Key,2.在使用MD5算法对Key进行哈希,3.得到硬盘上对应的哈希目录路径,4.从而将缓存内容保存在该目录中。它可以支持任意URL连接,同时也支持404/301/302这样的非200状态码。Nginx即可以支持对指定URL或者状态码设置过期时间,也可以使用purge命令来手动清除指定URL的缓存。
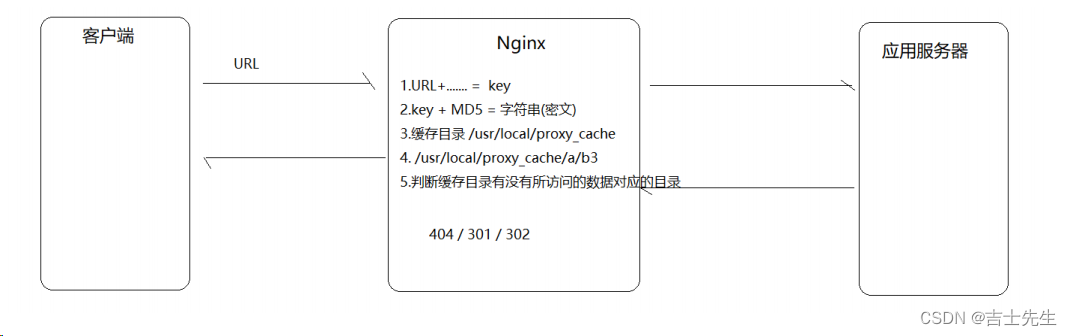
判断缓存目录中是否存在,假如不存在的话那么就转向访问应用服务器,应用服务器在返回之前,先保留一份数据给我们的Nginx缓存。
3.Nginx缓存设置的相关指令
Nginx的web缓存服务主要是使用ngx_http_proxy_module模块相关指令集来完成,接下来我们把常用的指令来进行介绍下。
(1).proxy_cache_path
该指定用于设置缓存文件的存放路径

- path:缓存路径地址,如:
/usr/local/proxy_cache
- levels: 指定该缓存空间对应的目录,最多可以设置3层,每层取值为1|2如 :
levels=1:2 缓存空间有两层目录,第一次是1个字母,第二次是2个字母举例说明:
itheima[key]通过MD5加密以后的值为 43c8233266edce38c2c9af0694e2107d
levels=1:2 最终的存储路径为 /usr/local/proxy_cache/d/07
levels=2:1:2 最终的存储路径为 /usr/local/proxy_cache/7d/0/21
levels=2:2:2 最终的存储路径为 ??/usr/local/proxy_cache/7d/10/e2
- keys_zone:用来为这个缓存区设置名称和指定大小,如:
keys_zone=itcast:200m 缓存区的名称是itcast,大小为200M,1M大概能存储8000个keys
- inactive:指定缓存的数据多次时间未被访问就将被删除,如:
inactive=1d 缓存数据在1天内没有被访问就会被删除
- max_size:设置最大缓存空间,如果缓存空间存满,默认会覆盖缓存时间最长的资源,如:
max_size=20g
完整配置示列: ⭐
proxy_cache_path /usr/local/proxy_cache levels=2:1 keys_zone=itcast:200m inactive=1d max_size=20g;
(2).proxy_cache
该指令用来开启或关闭代理缓存,如果是开启则自定使用哪个缓存区来进行缓存。
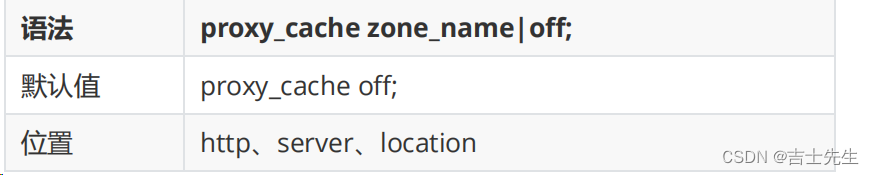
zone_name:指定使用缓存区的名称
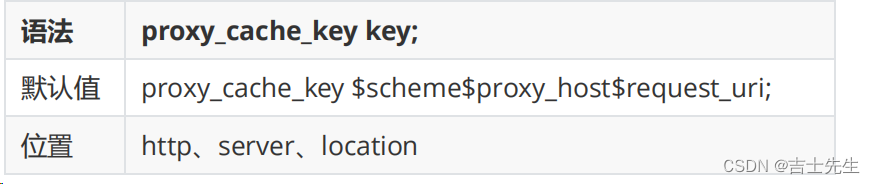
(3).proxy_cache_key
该指令用来设置web缓存的key值,Nginx会根据key值MD5哈希存缓存。
(4).proxy_cache_valid
该指令用来对不同返回状态码的URL设置不同的缓存时间

如:
proxy_cache_valid 200 302 10m;
proxy_cache_valid 404 1m;
为200和302的响应URL设置10分钟缓存,为404的响应URL设置1分钟缓存
proxy_cache_valid any 1m;
对所有响应状态码的URL都设置1分钟缓存
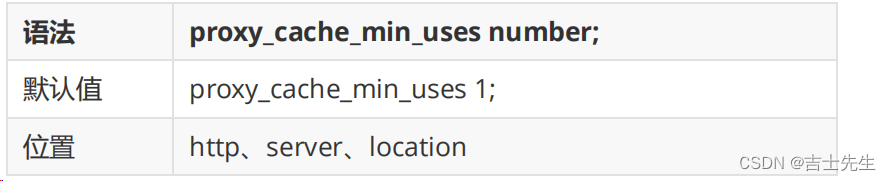
(5).proxy_cache_min_uses
该指令用来设置资源被访问多少次后被缓存
(6).proxy_cache_methods
该指令用户设置缓存哪些HTTP方法

默认缓存HTTP的GET和HEAD方法,不缓存POST方法。
4. Nginx缓存设置案例
(1).需求分析

(2).步骤实现
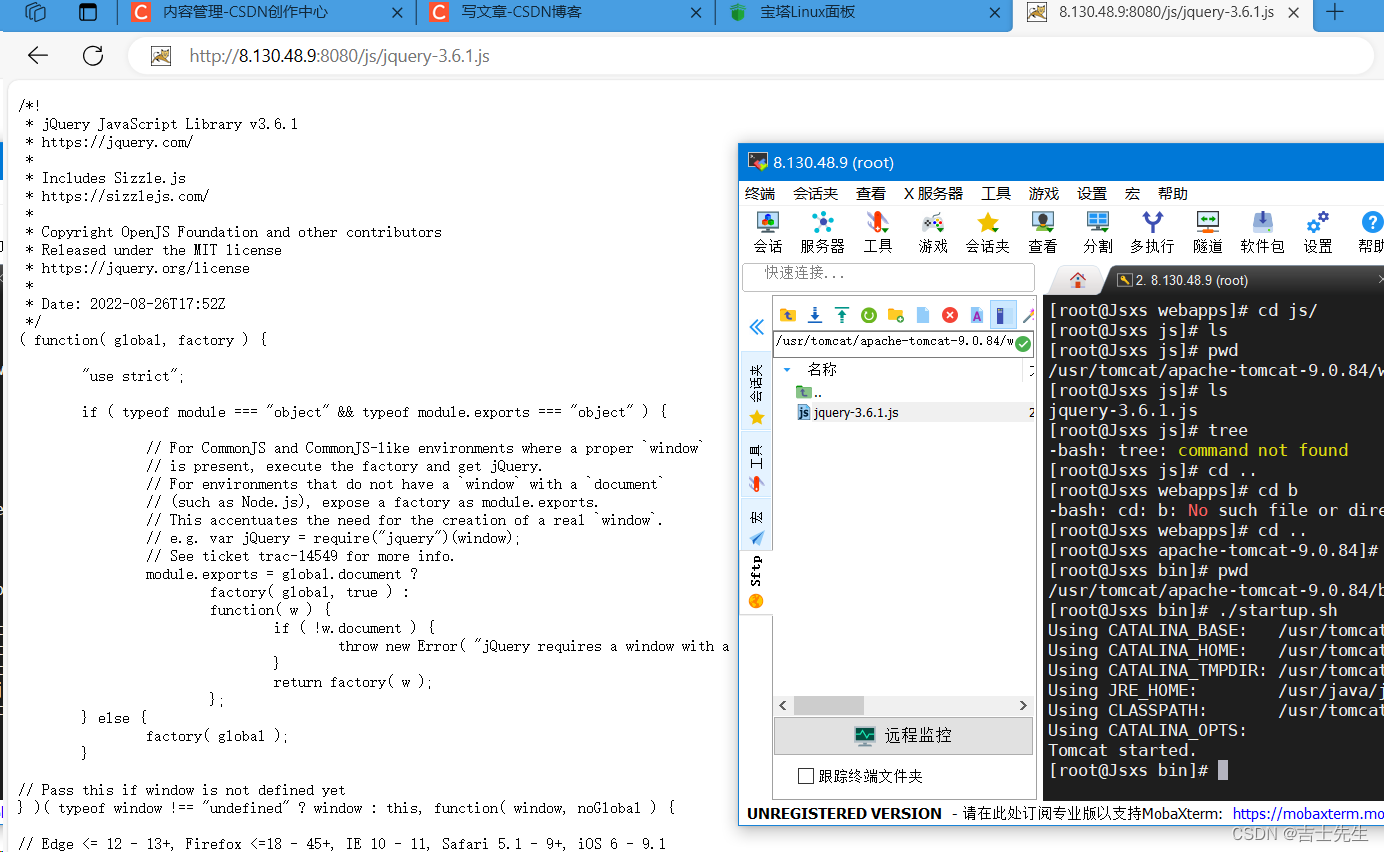
第一步: 环境准备
- 应用服务器的环境准备 (8080端口) ⭐
- 在8.130.48.9 服务器上的tomcat的webapps下面添加一个js目录,并在js目录中添加一个jquery.js文件
- 启动 tomcat
- 访问测试
# 进入我们的tomcat目录
cd /usr/tomcat/apache-tomcat-9.0.84/webapps
# 创建js文件夹,并且在js文件中写入我们的jquery.js
mkdir js
# 进入我们的bin目录
cd /usr/tomcat/apache-tomcat-9.0.84/bin
# 重新启动我们的项目
./startup.sh
http://8.130.48.9:8080/js/jquery-3.6.1.js
- Nginx的环境准备 (8081端口) ⭐
proxy_cache_path /usr/local/proxy_cache levels=2:1 keys_zone=itcast:200m inactive=1d max_size=20g;upstream backend {server 8.130.48.9:8080;}server {listen 8081;server_name localhost;location / {proxy_pass http://backend/js/;}}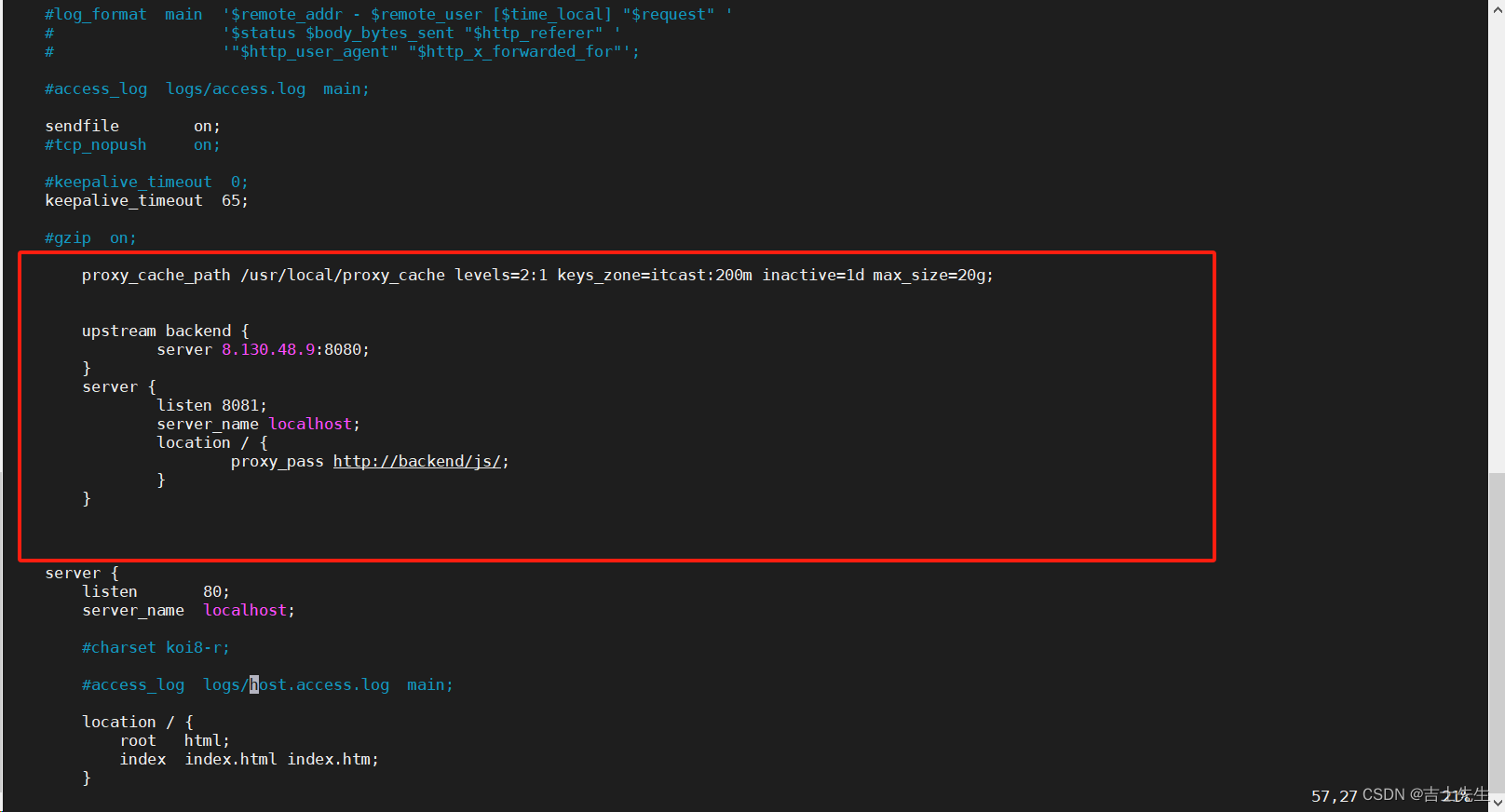
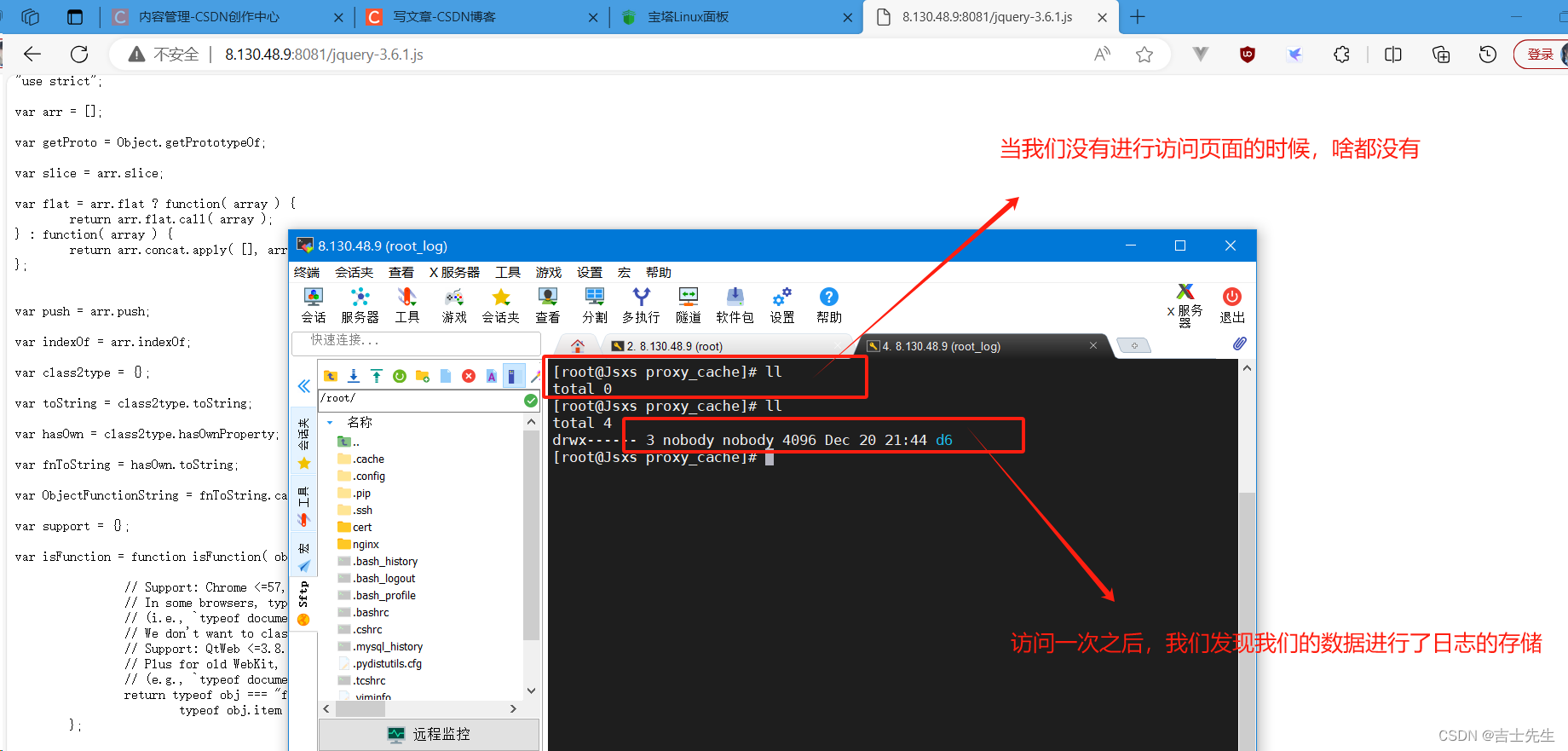
http://8.130.48.9:8081/jquery-3.6.1.js
- 完成Nginx缓存配置 ⭐
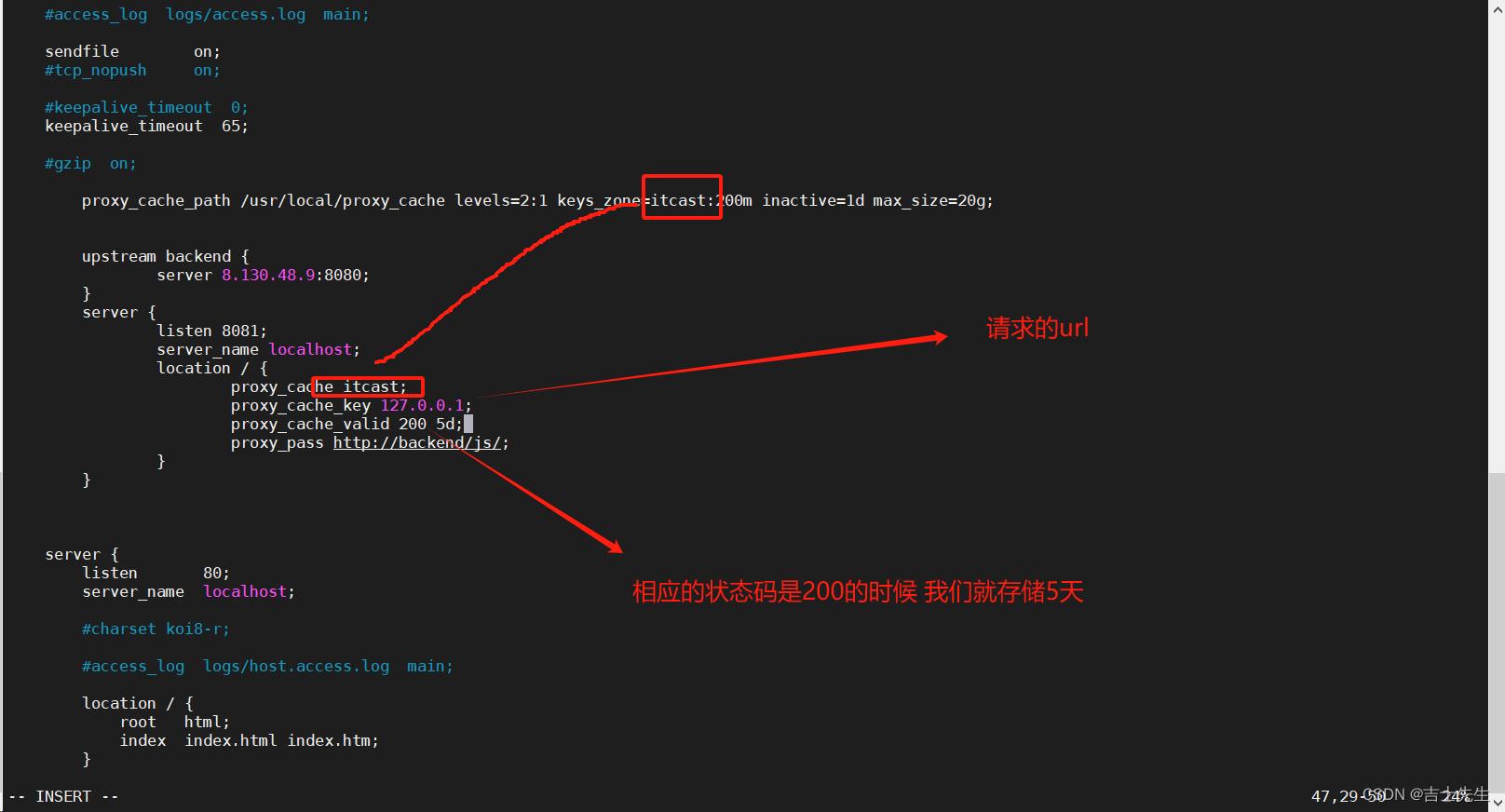
proxy_cache_path /usr/local/proxy_cache levels=2:1 keys_zone=itcast:200m inactive=1d max_size=20g;upstream backend {server 8.130.48.9:8080;}server {listen 8081;server_name localhost;location / {# 对应缓存文件夹的名字proxy_cache itcast;# 访问的路径 proxy_cache_key 127.0.0.1;# 当状态码为200的时候 缓存5天 proxy_cache_valid 200 5d;proxy_pass http://backend/js/;}}
http://8.130.48.9:8081/jquery-3.6.1.js
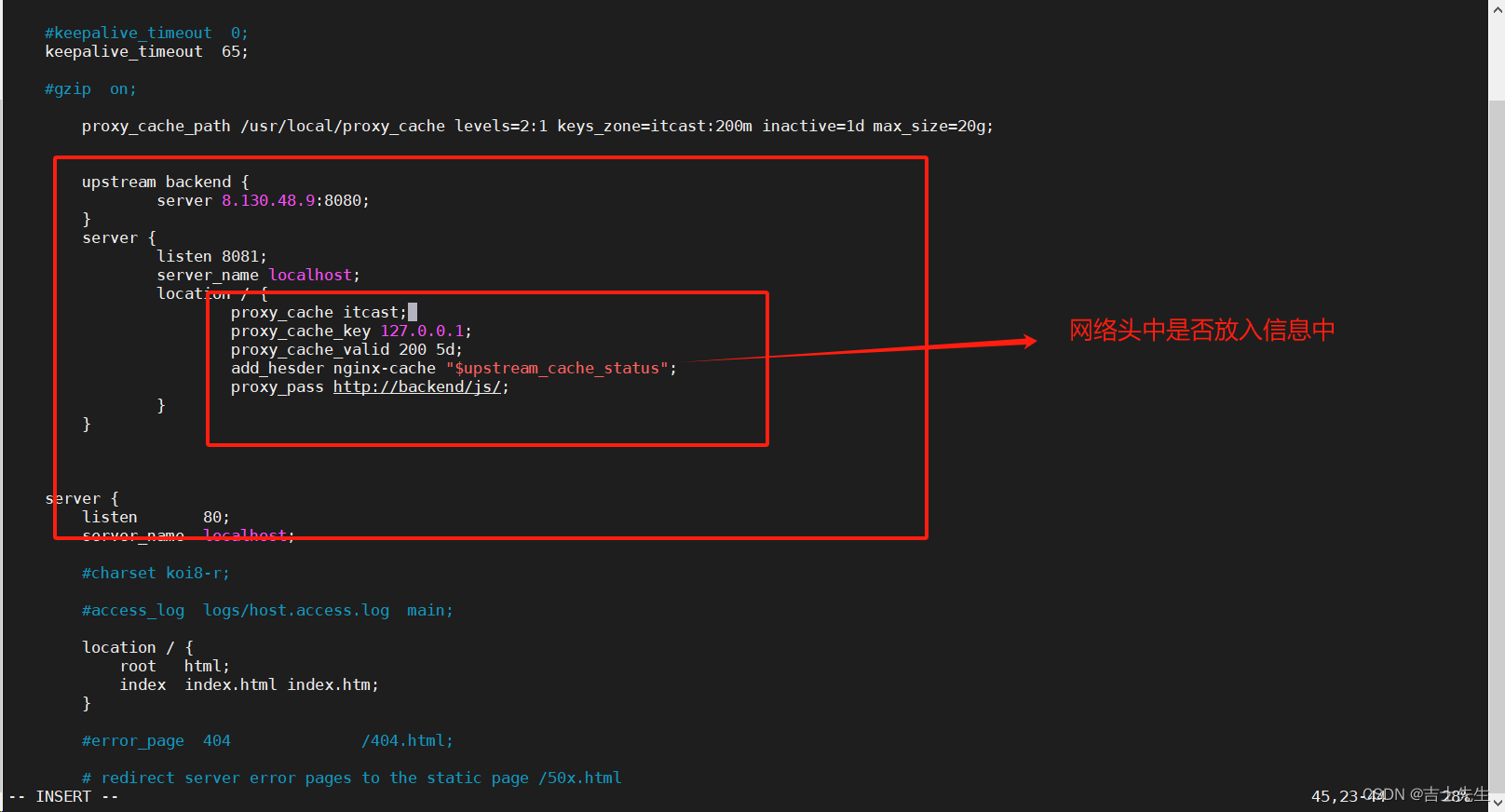
- 在消息头显示是否使用了缓存
proxy_cache_path /usr/local/proxy_cache levels=2:1 keys_zone=itcast:200m inactive=1d max_size=20g;upstream backend {server 8.130.48.9:8080;}server {listen 8081;server_name localhost;location / {proxy_cache itcast;proxy_cache_key 127.0.0.1;proxy_cache_valid 200 5d;add_header nginx-cache "$upstream_cache_status";proxy_pass http://backend/js/;}}
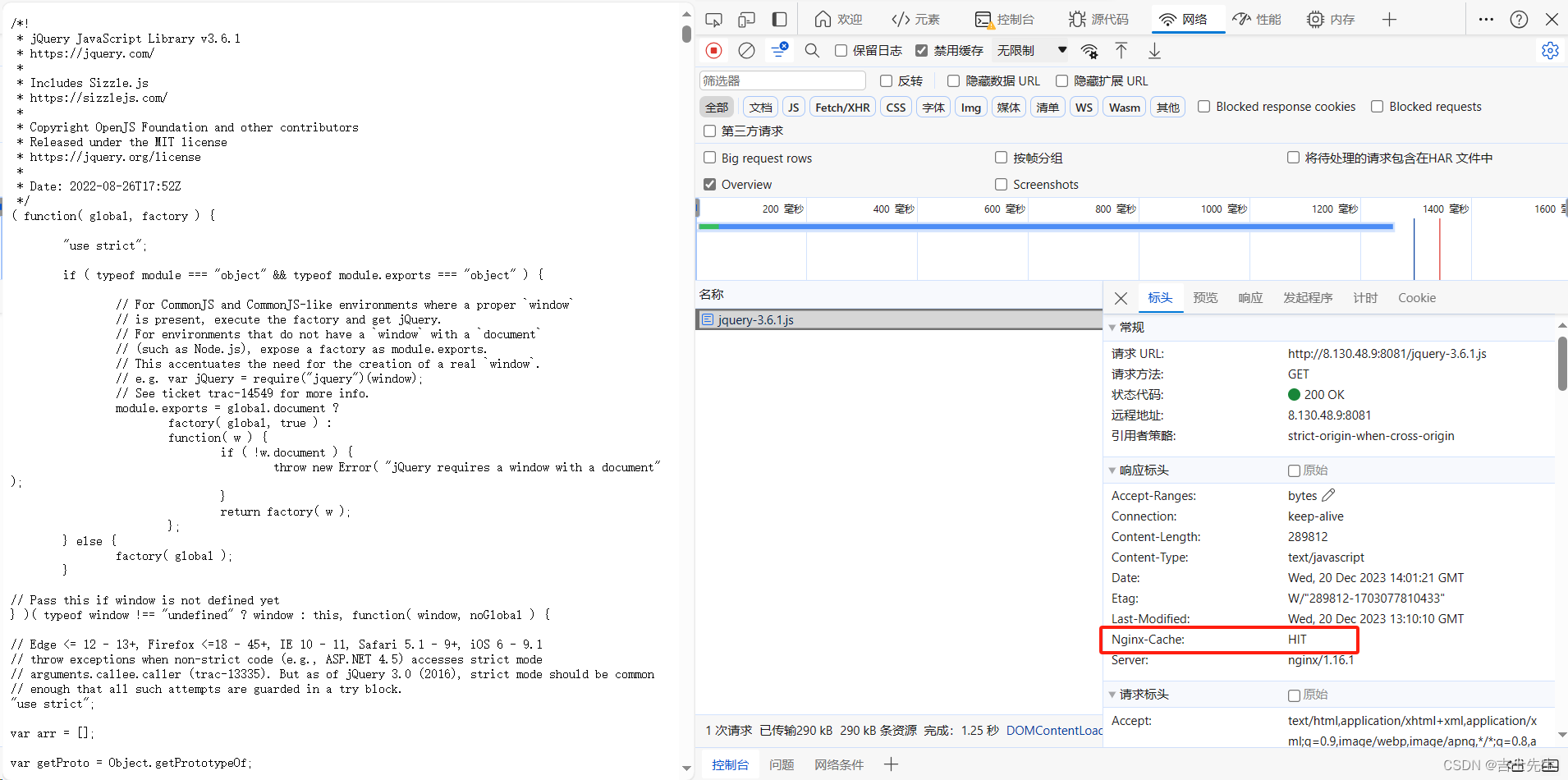
(3).完整配置
http{proxy_cache_path /usr/local/proxy_cachelevels=2:1 keys_zone=itcast:200m inactive=1dmax_size=20g;upstream backend{server 192.168.200.146:8080;}
server {listen 8080;server_name localhost;location / {# 缓存的文件夹proxy_cache itcast;# 访问的网址proxy_cache_key $scheme$proxy_host$request_uri;# 被访问5次的时候,才会缓存proxy_cache_min_uses 5;# 当状态码为200的时候 缓存5天proxy_cache_valid 200 5d;# 当状态码为 404的时候 缓存30秒proxy_cache_valid 404 30s;# 当状态码为任何一个的时候 缓存1分proxy_cache_valid any 1m;# 是否在头部显示添add_header nginx-cache "$upstream_cache_status";# 代理proxy_pass http://backend/js/;}}
}
5.Nginx缓存的清除
(1).方式一: 删除对应的缓存目录
适用于删除整个web服务器的全部缓存资源,而不适用于单行缓存的删除。
rm -rf /usr/local/proxy_cache/......
(2).方式二: 使用第三方扩展模块
ngx_cache_purge
- 下载
ngx_cache_purge模块对应的资源包,并上传到服务器上。
# 进入这个文件夹
cd /root/nginx/module/
# 上传下面的文件
ngx_cache_purge-2.3.tar.gz
- 对资源文件进行解压缩
#解压这个文件
tar -zxf ngx_cache_purge-2.3.tar.gz
- 修改文件夹名称,方便后期配置
# 修改我们的文件信息
mv ngx_cache_purge-2.3 purge
- 查询Nginx的配置参数
# 查看我们的配置信息
nginx -V
- 进入Nginx的安装目录,使用./configure进行参数配置
cd /root/nginx/core/nginx-1.16.1
# 在编译的时候在原有的基础上加上我们的这个新插件
./configure --prefix=/usr/local/nginx --sbin-path=/usr/local/nginx/sbin/nginx --modules-path=/usr/local/nginx/modules --conf-path=/usr/local/nginx/conf/nginx.conf --error-log-path=/usr/local/nginx/logs/error.log --http-log-path=/usr/local/nginx/logs/access.log --pid-path=/usr/local/nginx/logs/nginx.pid --lock-path=/usr/local/nginx/logs/nginx.lock --with-http_gzip_static_module --with-http_ssl_module --add-module=/root/nginx/module/purge
- 使用make进行编译
make
- 将nginx安装目录的nginx二级制可执行文件备份
cd /usr/local/nginx/sbin
# 进行备份的操作
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginxold
- 将编译后的objs中的nginx拷贝到nginx的sbin目录下
cd /root/nginx/core/nginx-1.16.1/objscp objs/nginx /usr/local/nginx/sbin
- 使用make进行升级
cd /root/nginx/core/nginx-1.16.1make upgrade
- 在nginx配置文件中进行如下配置
# 进入我们的配置文件
cd /usr/local/nginx/conf
# 进行修改我们的配置文件
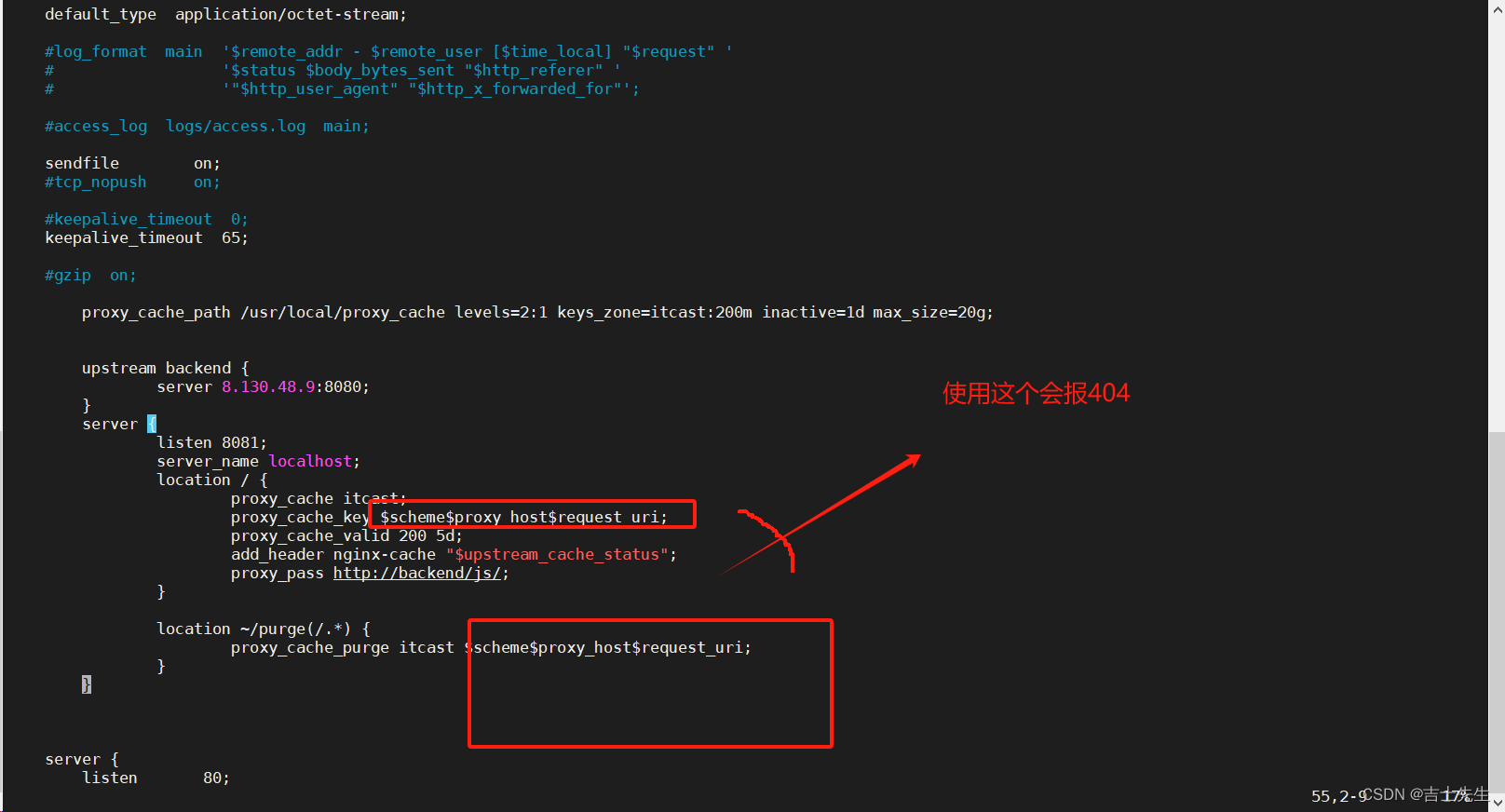
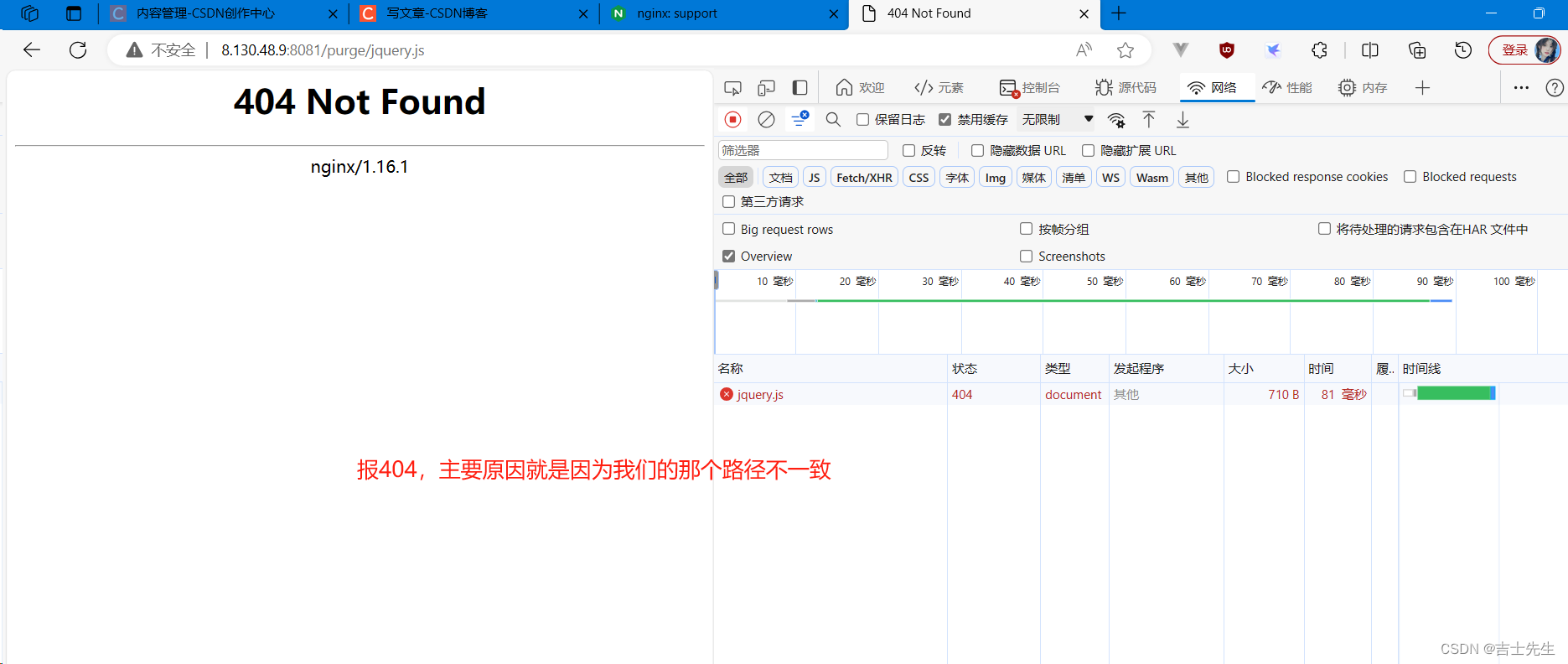
vim nginx.conf# 配置如下的信息proxy_cache_path /usr/local/proxy_cache levels=2:1 keys_zone=itcast:200m inactive=1d max_size=20g;upstream backend {server 8.130.48.9:8080;}server {listen 8081;server_name localhost;location / {proxy_cache itcast;proxy_cache_key $scheme$proxy_host$request_uri;proxy_cache_valid 200 5d;add_header nginx-cache "$upstream_cache_status";proxy_pass http://backend/js/;}location ~/purge(/.*) {proxy_cache_purge itcast $scheme$proxy_host$request_uri;}}
nginx -t
nginx -s reload

6.Nginx设置资源不缓存
前面咱们已经完成了Nginx作为web缓存服务器的使用。但是我们得思考一个问题就是不是所有的数据都适合进行缓存。比如说对于一些经常发生变化的数据。如果进行缓存的话,就很容易出现用户访问到的数据不是服务器真实的数据。所以对于这些资源我们在缓存的过程中就需要进行过滤,不进行缓存。
Nginx也提供了这块的功能设置,需要使用到如下两个指令
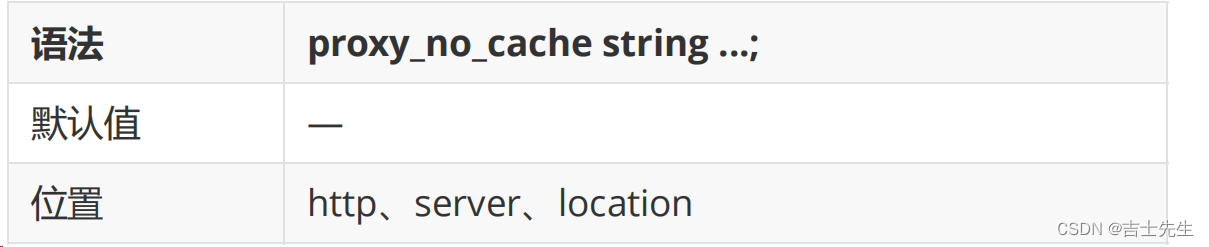
proxy_no_cache
该指令是用来定义不将数据进行缓存的条件。
配置实例
proxy_no_cache $cookie_nocache $arg_nocache $arg_comment;
proxy_cache_bypass
该指令是用来设置不从缓存中获取数据的条件。

配置实例
proxy_cache_bypass $cookie_nocache $arg_nocache $arg_comment;
上述两个指令都有一个指定的条件,这个条件可以是多个,并且多个条件中至少有一个不为空且不等于"0",则条件满足成立。上面给的配置实例是从官方网站获取的,里面使用到了三个变量,分别是$cookie_nocache、$arg_nocache、$arg_comment
(1). $cookie_nocache、$arg_nocache、$arg_comment
这三个参数分别代表的含义是:
$cookie_nocache
指的是当前请求的cookie中键的名称为nocache对应的值
$arg_nocache和$arg_comment
指的是当前请求的参数中属性名为nocache和comment对应的属性值
案例演示下:
未添加消息头的时候
log_format params $cookie_nocache | $arg_nocache | $arg_comment;server{listen 8081;server_name localhost;location /{access_log logs/access_params.log params;root html;index index.html;}
}
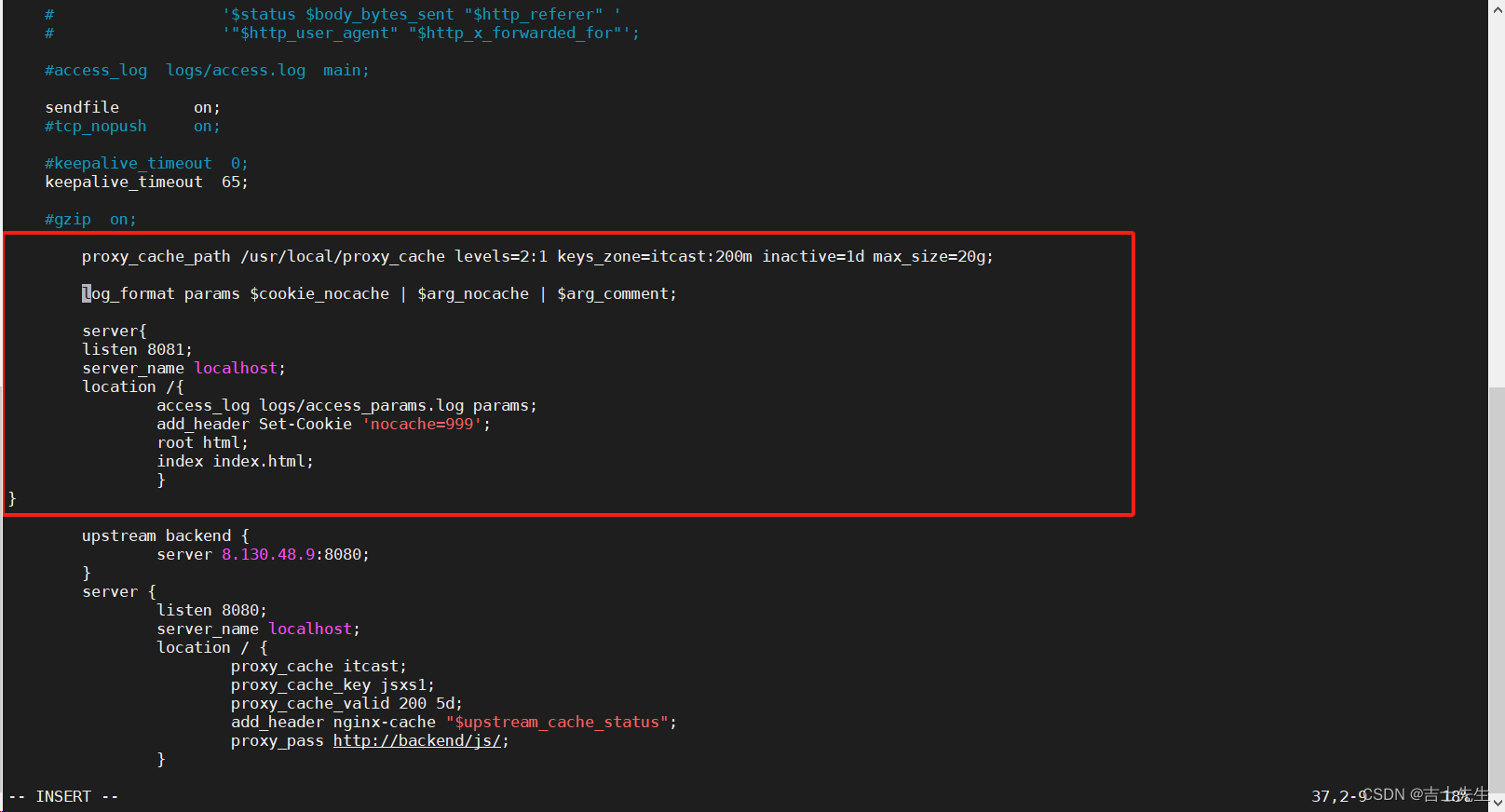
http://8.130.48.9:8081/

添加消息头的时候
log_format params $cookie_nocache | $arg_nocache | $arg_comment;server{listen 8081;server_name localhost;location /{access_log logs/access_params.log params;add_header Set-Cookie 'nocache=999';root html;index index.html;}
}

三个参数联合使用
http://8.130.48.9:8081/?nocache=999&comment=777
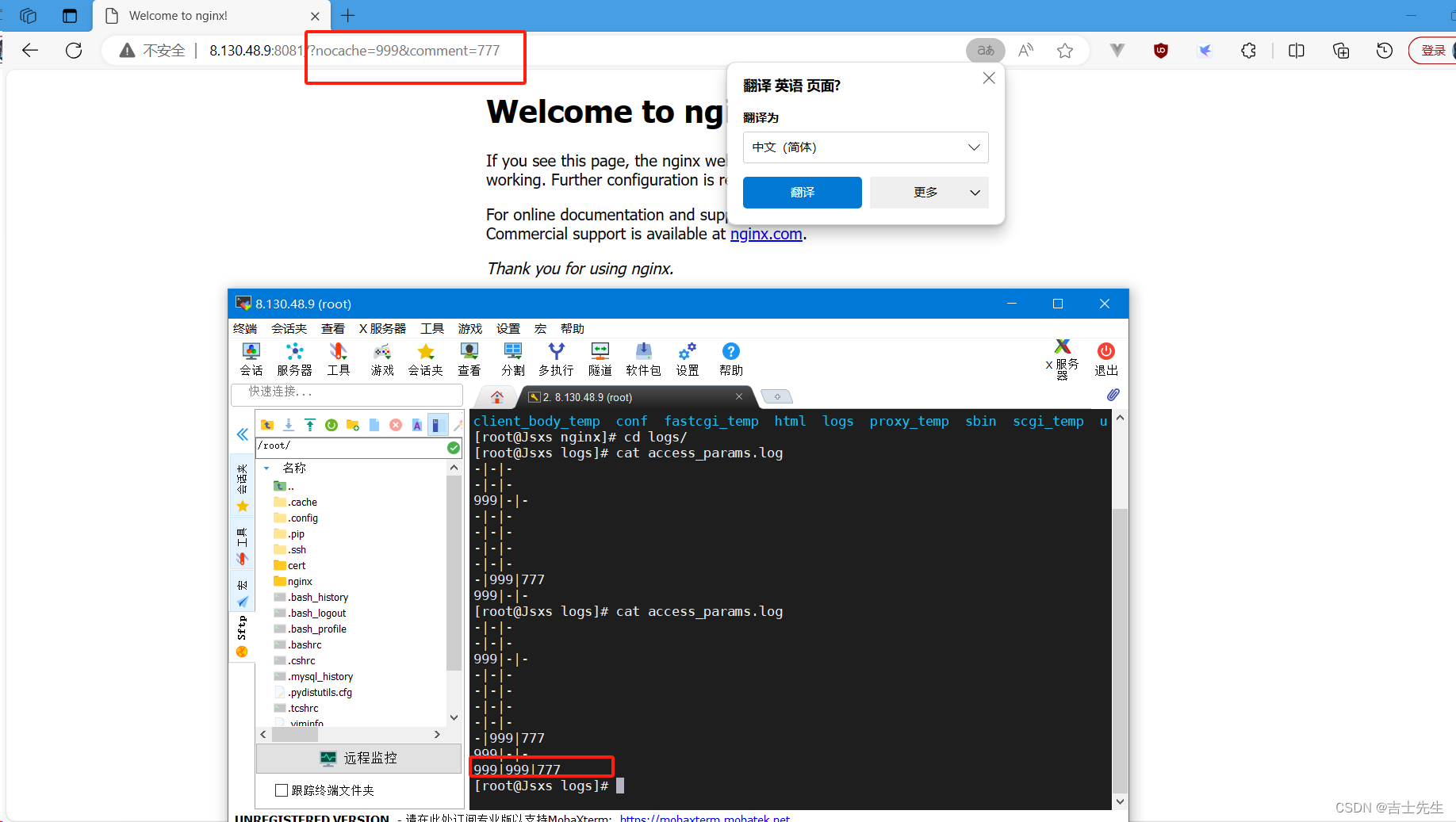
(2).示列
- 第一种: 仅使用三个参数
proxy_cache_path /usr/local/proxy_cache levels=2:1 keys_zone=itcast:200m inactive=1d max_size=20g;log_format params $cookie_nocache | $arg_nocache | $arg_comment;server {listen 8081;server_name localhost;location / {access_log logs/access_params.log params;# 配置过滤缓存的操作 ⭐proxy_no_cache $cookie_nocache $arg_nocache $arg_comment;proxy_cache_bypass $cookie_nocache $arg_nocache $arg_comment;add_header Set-Cookie 'nocache=999';root html;index index.html;}}
http://8.130.48.9:8081/?nocache=1&comment=2
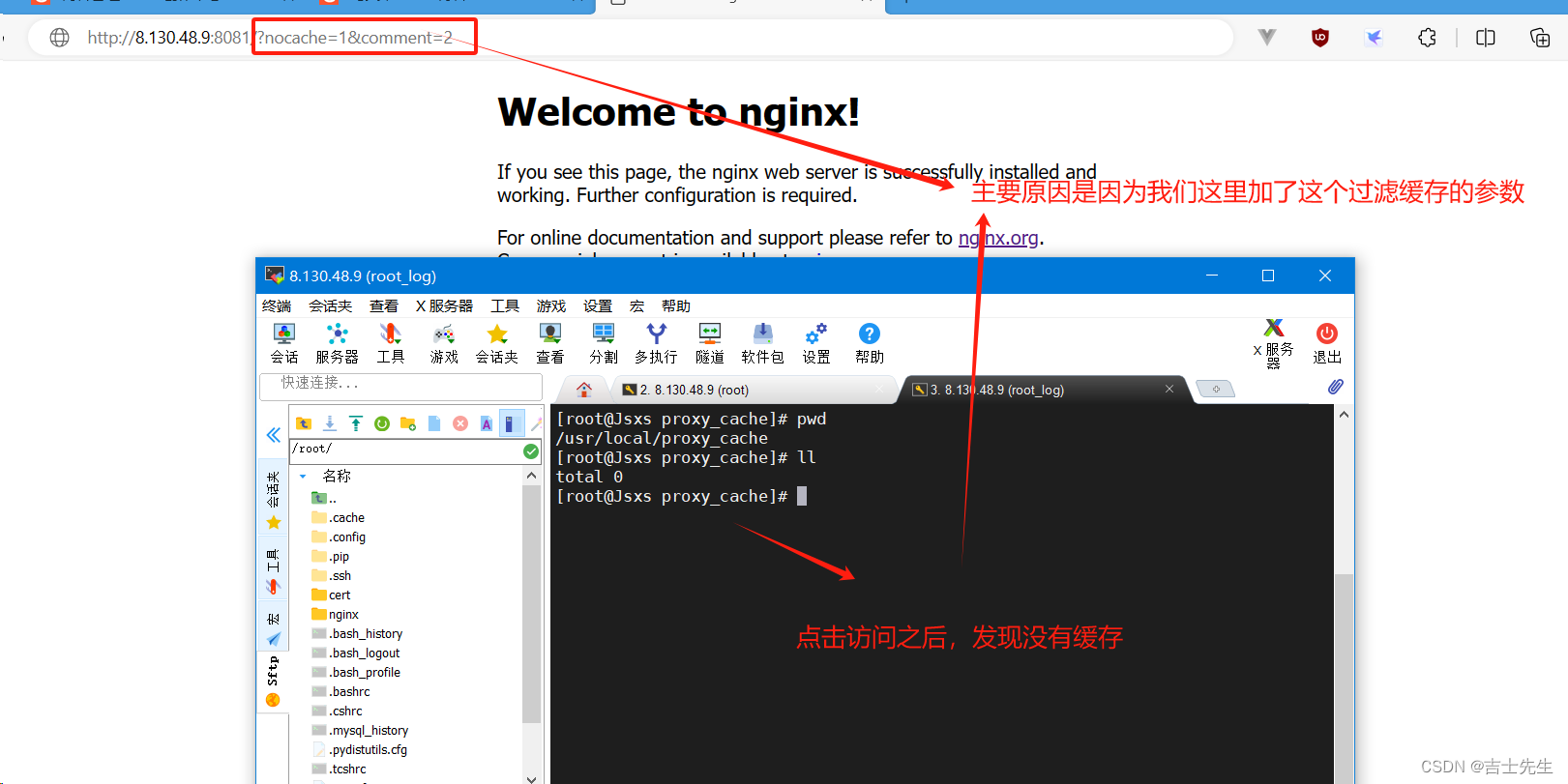
- 第二种方式: if判断且使用自定义
proxy_cache_path /usr/local/proxy_cache levels=2:1 keys_zone=itcast:200m inactive=1d max_size=20g;log_format params $cookie_nocache | $arg_nocache | $arg_comment;server {listen 8081;server_name localhost;location / {# 假如我们请求的url里面以.js结尾就进入方法⭐if ($request_uri ~ /.*\.js$) {# 假如参数值 mynocache 为1的话,就过滤不缓存set $mynocache 1;}access_log logs/access_params.log params;# 在原初的三个参数中,我们添加上第四个参数 ⭐proxy_no_cache $cookie_nocache $arg_nocache $arg_comment $mynocache;# 需要在这里多添加一行 ⭐⭐proxy_cache_bypass $cookie_nocache $arg_nocache $arg_comment $mynocache;add_header Set-Cookie 'nocache=999';root html;index index.html;}}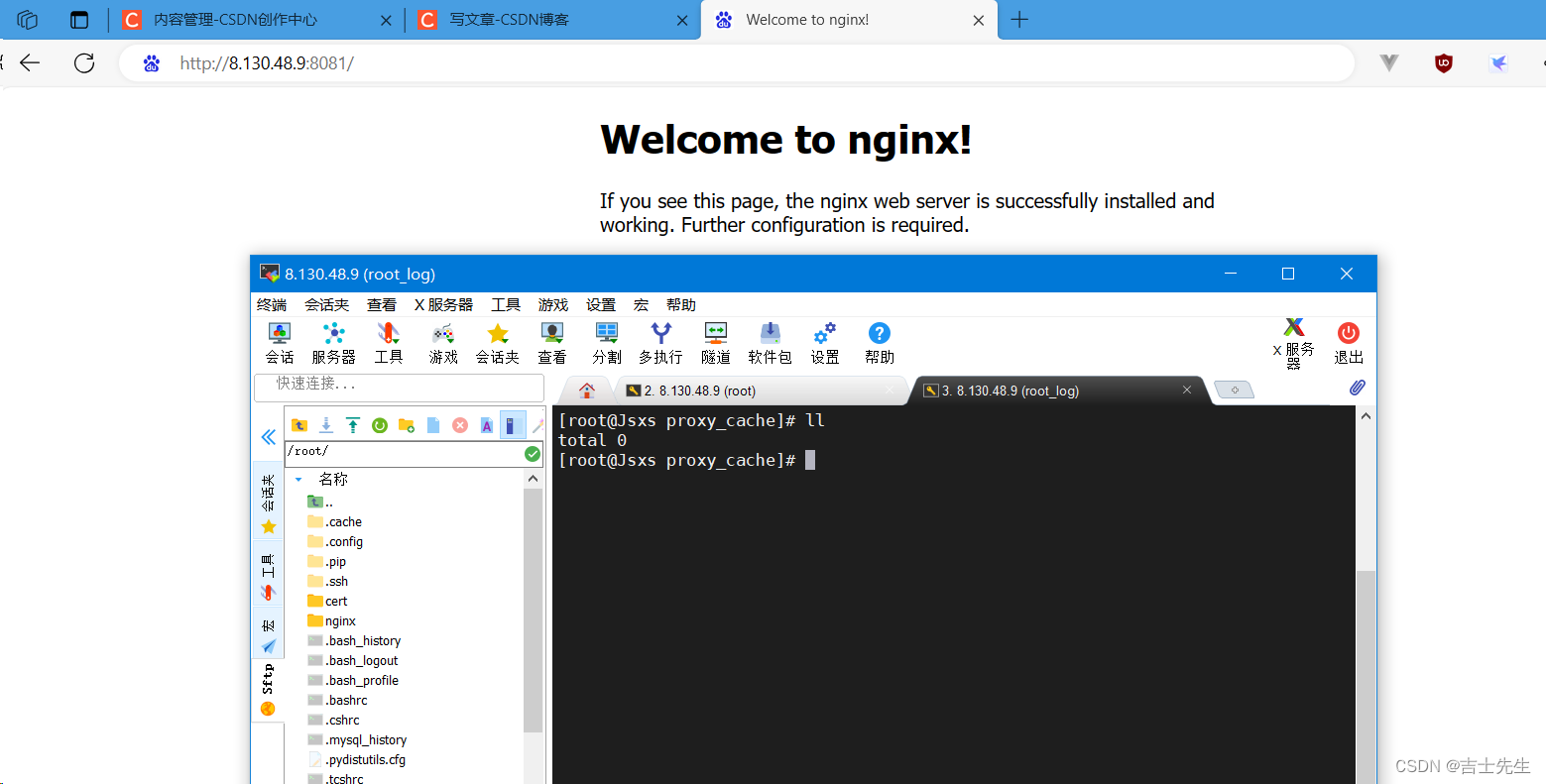
(七)、Nginx实现服务器端集群搭建
1.Nginx与Tomcat部署
前面课程已经将Nginx的大部分内容进行了讲解,我们都知道了Nginx在高并发场景和处理静态资源是非常高性能的,但是在实际项目中除了静态资源还有就是后台业务代码模块,一般后台业务都会被部署在Tomcat,weblogic或者是websphere等web服务器上。那么如何使用Nginx接收用户的请求并把请求转发到后台web服务器?

步骤分析:
1. 准备Tomcat环境,并在Tomcat上部署一个web项目
2. 准备Nginx环境,使用Nginx接收请求,并把请求分发到Tomat上
(1).环境准备(Tomcat)
浏览器访问:
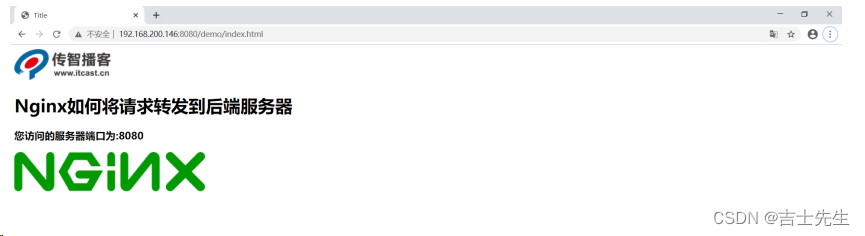
获取动态资源的链接地址:
http://192.168.200.146:8080/demo/getAddress
本次课程将采用Tomcat作为后台web服务器
(1)在Centos上准备一个Tomcat
1.Tomcat官网地址:https://tomcat.apache.org/
2.下载tomcat,本次课程使用的是apache-tomcat-8.5.59.tar.gz
3.将tomcat进行解压缩
mkdir web_tomcat
tar -zxf apache-tomcat-8.5.59.tar.gz -C /web_tomcat
(2)准备一个web项目,将其打包为war
1.将资料中的demo.war上传到tomcat8目录下的webapps包下
2.将tomcat进行启动,进入tomcat8的bin目录下./startup.sh
(3)启动tomcat进行访问测试。
静态资源: http://192.168.200.146:8080/demo/index.html
动态资源: http://192.168.200.146:8080/demo/getAddress
(2).环境准备(Nginx)
(1)使用Nginx的反向代理,将请求转给Tomcat进行处理。
upstream webservice {
server 192.168.200.146:8080;
}
server{listen 80;server_name localhost;location /demo {proxy_pass http://webservice;}
}
(2)启动访问测试
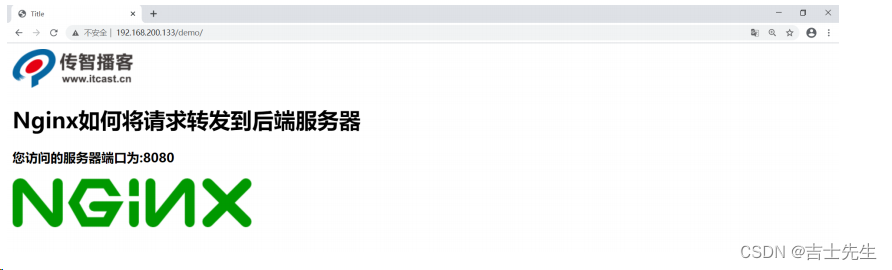
学习到这,可能大家会有一个困惑,明明直接通过tomcat就能访问,为什么还需要多加一个nginx,这样不是反而是系统的复杂度变高了么? 那接下来我们从两个方便给大家分析下这个问题.
- 第一个使用Nginx实现动静分离
- 第二个使用Nginx搭建Tomcat的集群
2.Nginx实现动静分离
什么是动静分离?
- 动: 后台应用程序的业务处理
- 静: 网站的静态资源(html,javaScript,css,images等文件)
- 分离: 将两者进行分开部署访问,提供用户进行访问。举例说明就是以后所有和静态资源相关的内容都交给Nginx来部署访问,非静态内容则交个类似于Tomcat的服务器来部署访问。
为什么要动静分离?
前面我们介绍过Nginx在处理静态资源的时候,效率是非常高的,而且Nginx的并发访问量也是名列前茅,而Tomcat则相对比较弱一些,所以把静态资源交个Nginx后,可以减轻Tomcat服务器的访问压力并提高静态资源的访问速度。
动静分离以后,降低了动态资源和静态资源的耦合度。如动态资源宕机了也不影响静态资源的展示。
如何实现动静分离?
实现动静分离的方式很多,比如静态资源可以部署到CDN、Nginx等服务器上,动态资源可以部署到Tomcat,weblogic或者websphere上。本次课程只要使用Nginx+Tomcat来实现动静分离。
(1).需求分析
动静分离的主要优点是为了: 假如服务器发生了宕机,因为前端页面部署在Nginx中,所以前端页面不会受服务器宕机的影响,依旧会展示给前端。

(2).动静分离实现步骤
1.将demo.war项目中的静态资源都删除掉,重新打包生成一个war包,在资料中有提供。
2.将war包部署到tomcat中,把之前部署的内容删除掉
进入到tomcat的webapps目录下,将之前的内容删除掉
将新的war包复制到webapps下
将tomcat启动
3.在Nginx所在服务器创建如下目录,并将对应的静态资源放入指定的位置

其中index.html页面的内容如下:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title><script src="js/jquery.min.js"></script><script>$(function(){$.get('http://192.168.200.133/demo/getAddress',function(data){$("#msg").html(data);});});</script>
</head>
<body><img src="images/logo.png"/><h1>Nginx如何将请求转发到后端服务器</h1><h3 id="msg"></h3><img src="images/mv.png"/>
</body>
</html>
4.配置Nginx的静态资源与动态资源的访问
upstream webservice{server 192.168.200.146:8080;
}
server {listen 80;server_name localhost;#动态资源location /demo {proxy_pass http://webservice;}#静态资源: 如果是.png .jpg .gif .js 都要进入我们的web目录下查找location ~/.*\.(png|jpg|gif|js){root html/web;gzip on;}location / {root html/web;index index.html index.htm;}
}
- 启动测试,访问
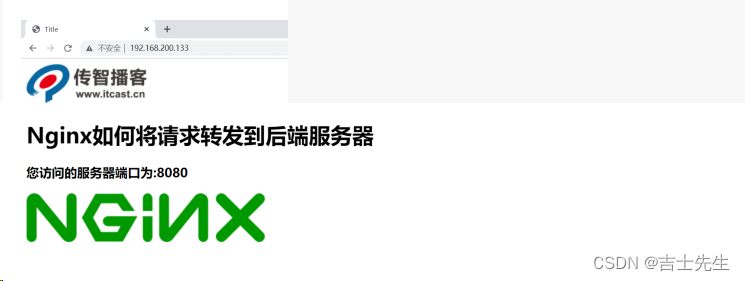
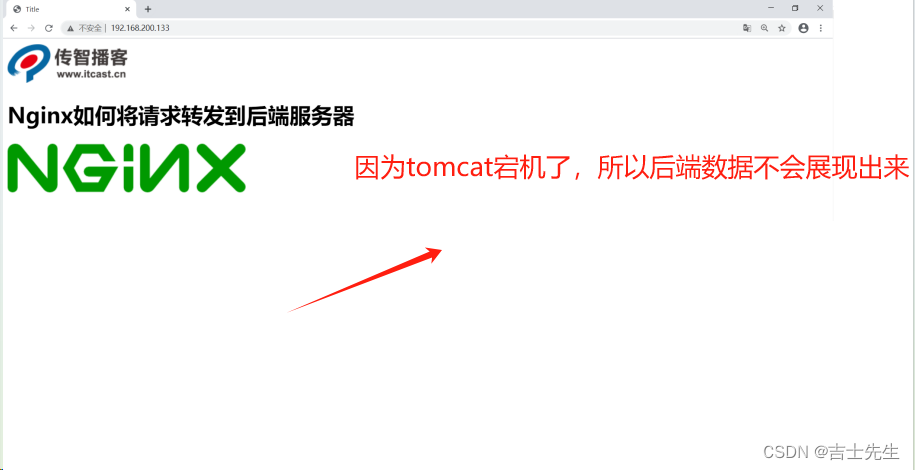
假如某个时间点,由于某个原因导致Tomcat后的服务器宕机了,我们再次访问Nginx,会得到如下效果,用户还是能看到页面,只是缺失了访问次数的统计,这就是前后端耦合度降低的效果,并且整个请求只和后的服务器交互了一次,js和images都直接从Nginx返回,提供了效率,降低了后的服务器的压力。
3.Nginx实现Tomcat集群搭建
在使用Nginx和Tomcat部署项目的时候,我们使用的是一台Nginx服务器和一台Tomcat服务器,效果图如下:
单点故障: 假如只部署一台的tomcat服务器发生了故障,那么就称作单点故障

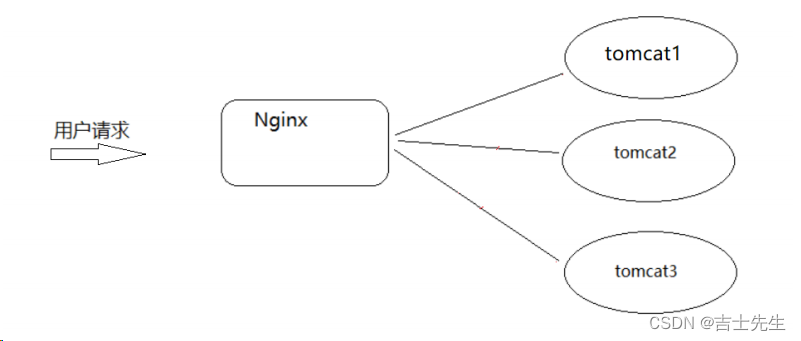
那么问题来了,如果Tomcat的真的宕机了,整个系统就会不完整,所以如何解决上述问题,一台服务器容易宕机,那就多搭建几台Tomcat服务器,这样的话就提升了后的服务器的可用性。这也就是我们常说的集群,搭建Tomcat的集群需要用到了Nginx的反向代理和赋值均衡的知识,具体如何来实现?我们先来分析下原理
(1).环境准备:
(1)准备3台tomcat,使用端口进行区分[实际环境应该是三台服务器],修改server.ml,将端口修改分别修改为8080,8180,8280
# 1.拉取我们最新版的tomcat
docker pull tomcat
# 2.创建宿主机的数据卷
cd /
mkdir category
mkdir -p docker_tomcat/tomcat01
mkdir -p docker_tomcat/tomcat02
cd /root/category/docker_tomcat/tomcat02
# 3.在tomcat02这个文件夹中执行挂载语句
docker run -p 8083:8080 --name tomcat01 \
-v $PWD/webapps:/usr/local/tomcat/webapps \
-d tomcat
# 4.进入tomcat01也进行挂载数据卷
cd /root/category/docker_tomcat/tomcat01docker run -p 8082:8080 --name tomcat02 \
-v $PWD/webapps:/usr/local/tomcat/webapps \
-d tomcat# 5.在宿主机上的数据卷中进行编写数据
cd /usr/tomcat/apache-tomcat-9.0.84cp -r webapps /root/category/docker_tomcat/tomcat02
cp -r webapps /root/category/docker_tomcat/tomcat01
(2)启动tomcat并访问测试
(2).配置信息
upstream webservice{server 127.0.0.1:8080;server 127.0.0.1:8082;server 127.0.0.1:8083;}server {listen 80;server_name localhost;location / {root html;proxy_pass http://webservice;index index.html index.htm;}}

(3).测试tomcat集群
我们每次访问的时候,3个tomcat会根据轮询的方式进行访问
http://8.130.48.9/
好了,完成了上述环境的部署,我们已经解决了Tomcat的高可用性,一台服务器宕机,还有其他两条对外提供服务,同时也可以实现后台服务器的不间断更新。但是新问题出现了,上述环境中,如果是Nginx宕机了呢,那么整套系统都将服务对外提供服务了,这个如何解决?
4.Nginx高可用解决方案
针对于上面提到的问题,我们来分析下要想解决上述问题,需要面临哪些问题?
需要两台以上的Nginx服务器对外提供服务,这样的话就可以解决其中一台宕机了,另外一台还能对外提供服务,但是如果是两台Nginx服务器的话,会有两个IP地址,用户该访问哪台服务器,用户怎么知道哪台是好的,哪台是宕机了的?
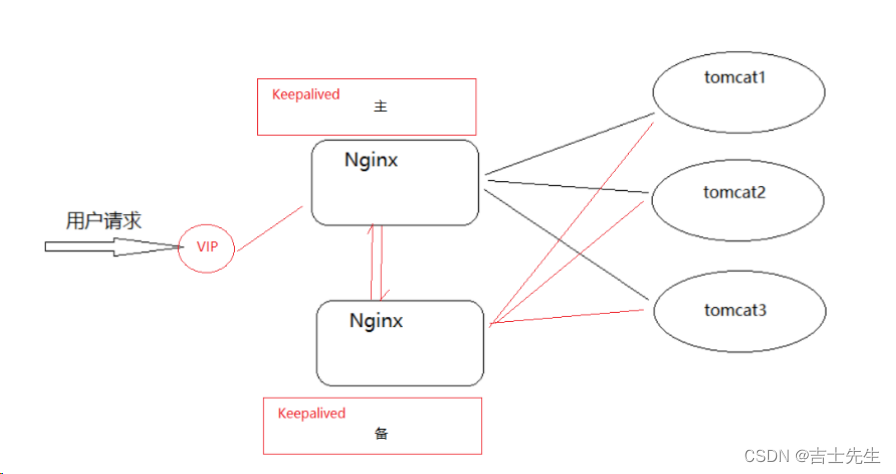
(1).Keepalived
使用Keepalived来解决,Keepalived 软件由 C 编写的,最初是专为 LVS负载均衡软件设计的,Keepalived 软件主要是通过 VRRP 协议实现高可用功能。
(2).VRRP介绍
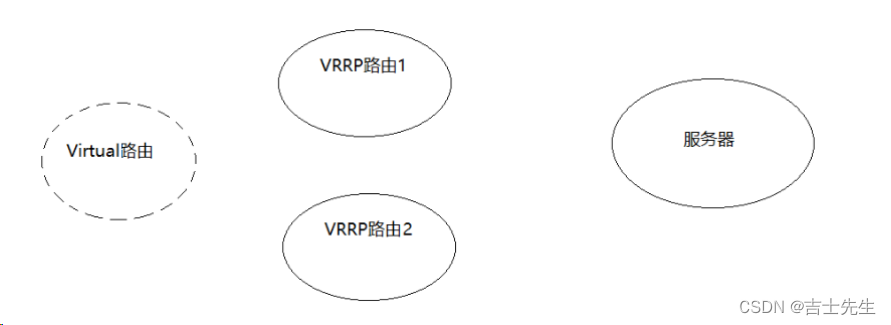
VRRP(Virtual Route Redundancy Protocol)协议,翻译过来为虚拟路由冗余协议。VRRP协议将两台或多台路由器设备虚拟成一个设备,对外提供虚拟路由器IP,而在路由器组内部,如果实际拥有这个对外IP的路由器如果工作正常的话就是MASTER,MASTER实现针对虚拟路由器IP的各种网络功能。其他设备不拥有该虚拟IP,状态为BACKUP,处了接收MASTER的VRRP状态通告信息以外,不执行对外的网络功能。当主机失效时,BACKUP将接管原先MASTER的网络功能。
从上面的介绍信息获取到的内容就是VRRP是一种协议,那这个协议是用来干什么的?
- 选择协议
VRRP可以把一个虚拟路由器的责任动态分配到局域网上的 VRRP 路由器中的一台。其中的虚拟路由即Virtual路由是由VRRP路由群组创建的一个不真实存在的路由,这个虚拟路由也是有对应的IP地址。而且VRRP路由1和VRRP路由2之间会有竞争选择,通过选择会产生一个Master路由和一个Backup路由。
- 路由容错协议
Master路由和Backup路由之间会有一个心跳检测,Master会定时告知Backup自己的状态,如果在指定的时间内,Backup没有接收到这个通知内容,Backup就会替代Master成为新的Master。Master路由有一个特权就是虚拟路由和后端服务器都是通过Master进行数据传递交互的,而备份节点则会直接丢弃这些请求和数据,不做处理,只是去监听Master的状态
用了Keepalived后,解决方案如下:
(3).环境搭建 ⭐
- 环境准备
# 1.新建我们的数据卷文件位置
cd /root/category/docker_nginx/nginx01
# 2.挂载配置文件
mkdir conf
# 3.进行挂载并启动
docker run -p 8084:80 --name nginx01 \
-v $PWD/conf:/usr/local/nginx/conf \
-d nginx:1.16.1
# 4.进行挂载文件夹的同步
cp -r conf /root/category/docker_nginx/nginx01
http://8.130.48.9:8084/
并此时此刻启动我们两个容器!!!!
(4).下载 Keepalived
https://www.keepalived.org/

下载 2.0.20版本的即可,并上传到我们的虚拟机(宿主机要下载、容器也要进行下载)中
#步骤1:从官方网站下载keepalived,官网地址:
https://keepalived.org/
#步骤2:将下载的资源上传到服务器 ->
keepalived-2.0.20.tar.gz
#步骤3:创建keepalived目录,方便管理资源 ->
cd ~
mkdir keepalived
cd keepalived
#步骤4:将压缩文件进行解压缩,解压缩到指定的目录 ->
tar -zxf keepalived-2.0.20.tar.gz
# 步骤5:对keepalived进行配置,编译和安装
cd /root/keepalived/keepalived-2.0.20
# 步骤六: 进行配置
./configure --sysconf=/etc --prefix=/usr/local
# 步骤七: 进行编译和安装
make && make install
安装完成后,有两个文件需要我们认识下,一个是
/etc/keepalived/keepalived.conf (keepalived的系统配置文件,我们主要操作的就是该文件),一个是/usr/local/sbin目录下的keepalived ,是系统配置脚本,用来启动和关闭keepalived
(5).Keepalived配置文件介绍
打开keepalived.conf配置文件这里面会分三部,第一部分是global全局配置、第二部分是vrrp相关配置、第三部分是LVS相关配置。 本次课程主要是使用keepalived实现高可用部署,没有用到LVS,所以我们重点关注的是前两部分.
# 1.global全局部分:⭐
global_defs {# 2.通知邮件,当keepalived发送切换时需要发email给具体的邮箱地址notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}# 3.设置发件人的邮箱信息notification_email_from Alexandre.Cassen@firewall.loc# 4.指定smpt服务地址smtp_server 192.168.200.1# 5.指定smpt服务连接超时时间smtp_connect_timeout 30# 6.运行keepalived服务器的一个标识,可以用作发送邮件的主题信息router_id LVS_DEVEL#默认是不跳过检查。检查收到的VRRP通告中的所有地址可能会比较耗时,设置此命令的意思是,如果通告与接收的上一个通告来自相同的master路由器,则不执行检查(跳过检查)vrrp_skip_check_adv_addr#严格遵守VRRP协议。vrrp_strict#在一个接口发送的两个免费ARP之间的延迟。可以精确到毫秒级。默认是0vrrp_garp_interval 0#在一个网卡上每组na消息之间的延迟时间,默认为0vrrp_gna_interval 0
}# 2.VRRP部分,该部分可以包含以下四个子模块
#1. vrrp_script 2. vrrp_sync_group 3.garp_group 4. vrrp_instance#设置keepalived实例的相关信息,VI_1为VRRP实例名称 ⭐⭐
vrrp_instance VI_1 {#有两个值可选MASTER主 BACKUP备state MASTER#vrrp实例绑定的接口,用于发送VRRP包[当前服务器使用的网卡名称]interface eth0#指定VRRP实例ID,范围是0-255virtual_router_id 51#指定优先级,优先级高的将成为priority 100#指定发送VRRP通告的间隔,单位是秒advert_int 1#vrrp之间通信的认证信息authentication {#指定认证方式。PASS简单密码认证(推荐)auth_type PASS#指定认证使用的密码,最多8位auth_pass 1111}virtual_ipaddress {#虚拟IP地址设置虚拟IP地址,供用户访问使用,可设置多个,一行一个192.168.200.16192.168.200.17192.168.200.18}
}
# ⭐⭐⭐
virtual_server 192.168.200.100 443 {delay_loop 6lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPreal_server 192.168.201.100 443 {weight 1SSL_GET {url {path /digest ff20ad2481f97b1754ef3e12ecd3a9cc}url {path /mrtg/digest 9b3a0c85a887a256d6939da88aabd8cd}connect_timeout 3retry 3delay_before_retry 3}}
}
# ⭐⭐⭐⭐
virtual_server 10.10.10.2 1358 {delay_loop 6lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPsorry_server 192.168.200.200 1358real_server 192.168.200.2 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3retry 3delay_before_retry 3}}real_server 192.168.200.3 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334c}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334c}connect_timeout 3retry 3delay_before_retry 3}}
}
# ⭐⭐⭐⭐⭐
virtual_server 10.10.10.3 1358 {delay_loop 3lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPreal_server 192.168.200.4 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3retry 3delay_before_retry 3}}real_server 192.168.200.5 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3retry 3delay_before_retry 3}}
}
(6).keppalived 自定义配置 ⭐⭐
- 服务器1
192.168.200.133
global_defs {notification_email {tom@itcast.cnjerry@itcast.cn}notification_email_from zhaomin@itcast.cnsmtp_server 192.168.200.1smtp_connect_timeout 30router_id keepalived1vrrp_skip_check_adv_addrvrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0}vrrp_instance VI_1 {# ⭐这里配置成主机state MASTER# 实列设置成 ens33interface ens33# 路由id 设置成 51,从机也要设置成51virtual_router_id 51# 因为是主机我们要设置成 100,优先级比较高 priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {# 虚拟IP地址192.168.200.222}
}
- 服务器2
192.168.200.122
! Configuration File for keepalivedglobal_defs {notification_email {tom@itcast.cnjerry@itcast.cn}notification_email_from zhaomin@itcast.cnsmtp_server 192.168.200.1smtp_connect_timeout 30router_id keepalived2vrrp_skip_check_adv_addrvrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0}vrrp_instance VI_1 {# ⭐ 这里配置成从机state BACKUP# 和主机保持一致interface ens33# 和主机保持一致virtual_router_id 51# 因为是从机,优先级我们设置成90priority 90advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {# 虚拟ip地址和主机一样192.168.200.222}}
(7).自定义配置后访问测试 ⭐⭐⭐
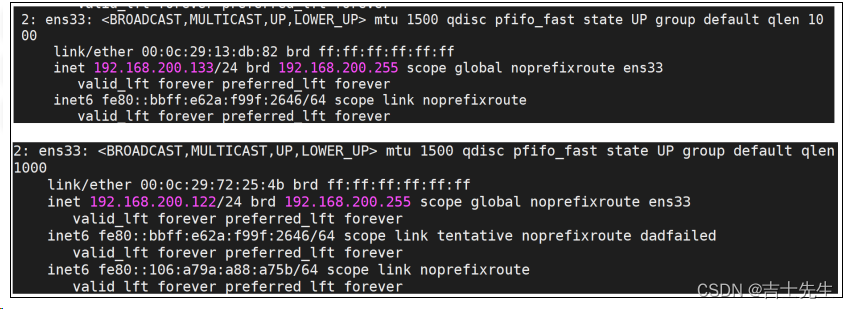
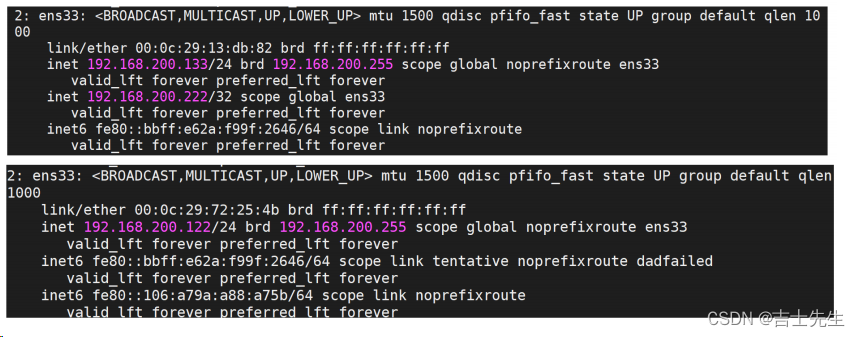
- 启动keepalived之前,咱们先使用命令 ip a ,查看
192.168.200.133和192.168.200.122这两台服务器的IP情况。
2. 分别启动两台服务器的keepalived
cd /usr/local/sbin
./keepalived
再次通过 ip a 查看ip
我们发现我们的虚拟IP绑定到了 192.168.200.133上
3. 当把192.168.200.133服务器上的keepalived关闭后,再次查看ip
133手动关闭之后,我们发现的虚拟IP绑定到了 192.168.200.122上
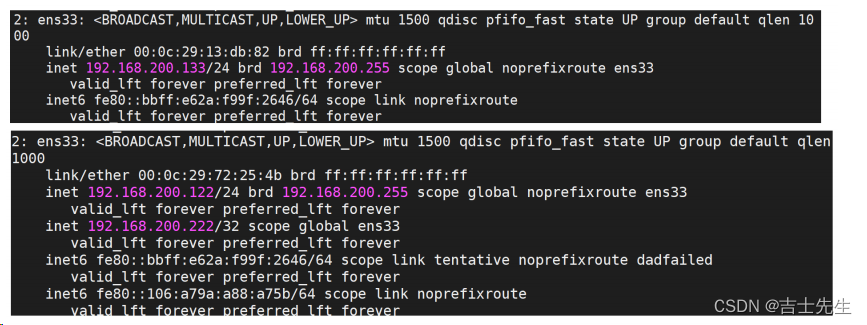
通过上述的测试,我们会发现,虚拟IP(VIP)会在MASTER节点上,当MASTER节点上的keepalived出问题以后,因为BACKUP无法收到MASTER发出的VRRP状态通过信息,就会直接升为MASTER。VIP也会"漂移"到新的MASTER。
上面测试和Nginx有什么关系?
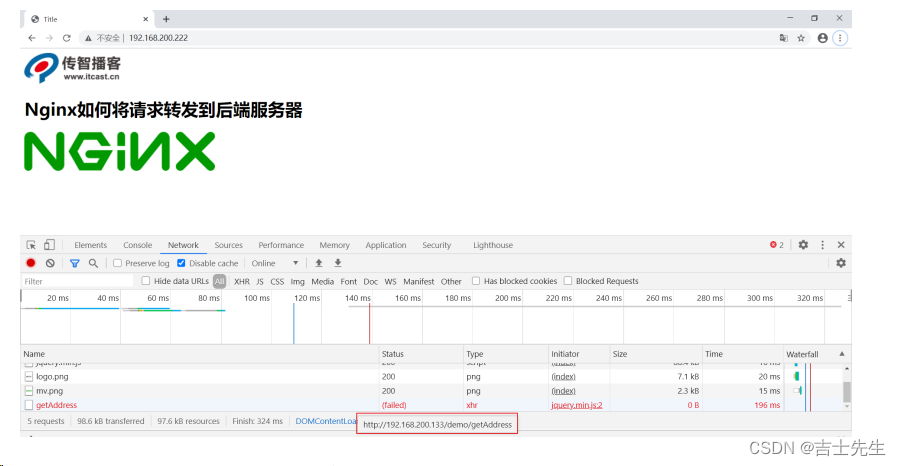
我们把192.168.200.133服务器的keepalived再次启动下,由于它的优先级高于服务器192.168.200.122的,所有它会再次成为MASTER,VIP也会"漂移"过去,然后我们再次通过浏览器访问:
http://192.168.200.222/
如果把192.168.200.133服务器的keepalived关闭掉,再次访问相同的地址
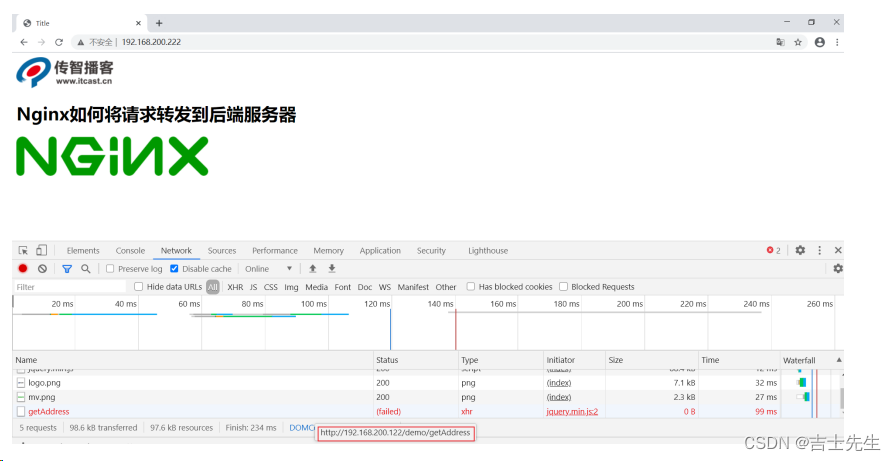
效果实现了以后, 我们会发现要想让vip进行切换,就必须要把服务器上的keepalived进行关闭,而什么时候关闭keepalived呢?应该是在keepalived所在服务器的nginx出现问题后,把keepalived关闭掉,就可以让VIP执行另外一台服务器,但是现在这所有的操作都是通过手动来完成的,我们如何能让系统自动判断当前服务器的nginx是否正确启动,如果没有,要能让VIP自动进行"漂移",这个问题该如何解决?
(8).keepalived之自动切换脚本
keepalived只能做到对网络故障和keepalived本身的监控,即当出现网络故障或者keepalived本身出现问题时,进行切换。但是这些还不够,我们还需要监控keepalived所在服务器上的其他业务,比如Nginx,如果Nginx出现异常了,仅仅keepalived保持正常,是无法完成系统的正常工作的,因此需要根据业务进程的运行状态决定是否需要进行主备切换,这个时候,我们可以通过编写脚本对业务进程进行检测监控。
实现步骤:
- 在keepalived配置文件中添加对应的配置像
vrrp_script 脚本名称
{script "脚本位置"#执行时间间隔interval 3#动态调整vrrp_instance的优先级weight -20
}
- 编写脚本
ck_nginx.sh
#!/bin/bashnum=`ps -C nginx --no-header | wc -l`if [ $num -eq 0 ];then/usr/local/nginx/sbin/nginxsleep 2if [ `ps -C nginx --no-header | wc -l` -eq 0 ]; thenkillall keepalivedfifi
Linux ps命令用于显示当前进程 (process) 的状态。
-C(command) : 指定命令的所有进程
–no-header 排除标题
- 为脚本文件设置权限
chmod 755 ck_nginx.sh
- 将脚本添加到
# 添加我们的脚本
vrrp_script ck_nginx {#执行脚本的位置script "/etc/keepalived/ck_nginx.sh" #执行脚本的周期,秒为单位interval 2 #权重的计算方式weight -20 }
vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 10priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.200.111}track_script {ck_nginx}
}
- 如果效果没有出来,可以使用
tail -f /var/log/messages查看日志信息,找对应的错误信息。 - 测试
问题思考:
通常如果master服务死掉后backup会变成master,但是当master服务又好了的时候 master此时会抢占VIP,这样就会发生两次切换对业务繁忙的网站来说是不好的。所以我们要在配置文件加入 nopreempt 非抢占,但是这个参数只能用于 state 为backup,故我们在用的时候最好 master 和backup的state都设置成backup 让其通过priority(优先级)来竞争。
5.Nginx制作下载站点
首先我们先要清楚什么是下载站点?
我们先来看一个网站http://nginx.org/download/这个我们刚开始学习Nginx的时候给大家看过这样的网站,该网站主要就是用来提供用户来下载相关资源的网站,就叫做下载网站。
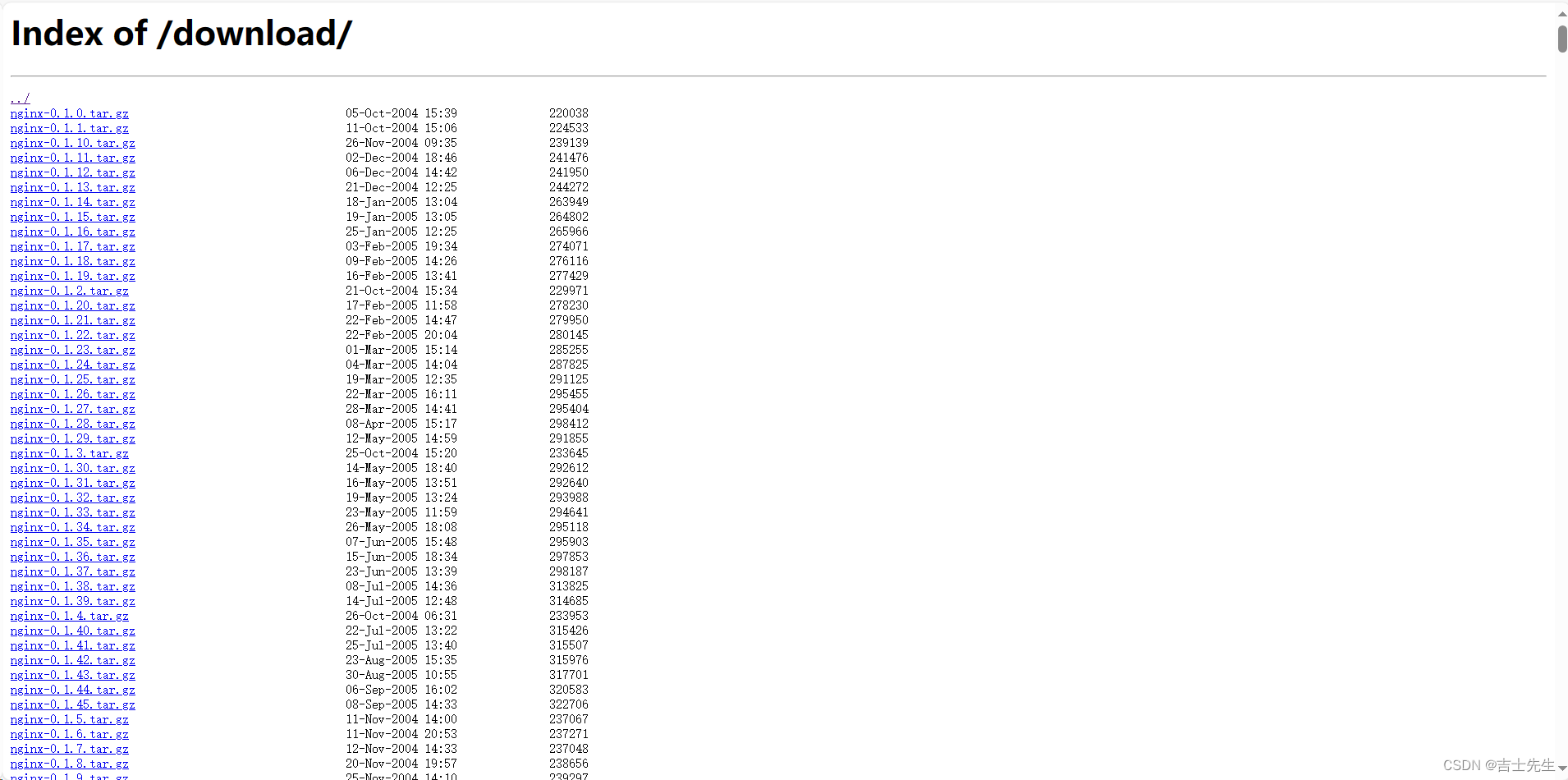
如何制作一个下载站点:
nginx使用的是模块 ngx_http_autoindex_module 来实现的,该模块处理以斜杠(“/”)结尾的请求,并生成目录列表。
nginx编译的时候会自动加载该模块,但是该模块默认是关闭的,我们需要使用下来指令来完成对应的配置。
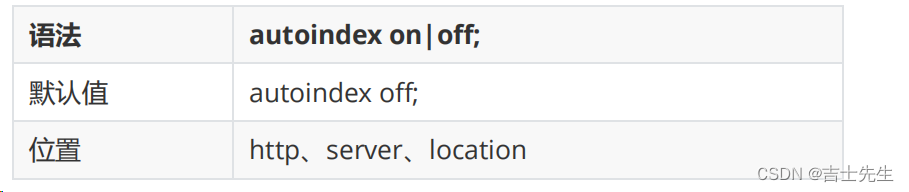
(1).autoindex:启用或禁用目录列表输出
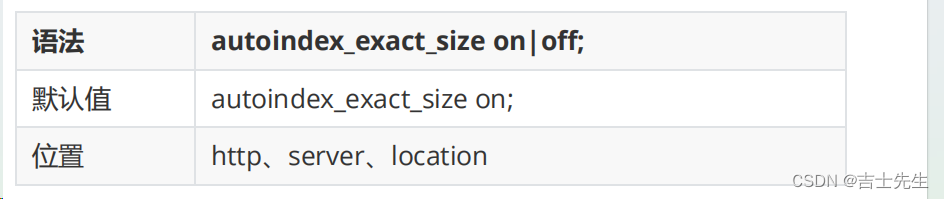
(2).autoindex_exact_size:对应HTLM格式,指定是否在目录列表展示文件的详细大小
默认为on,显示出文件的确切大小,单位是bytes。 改为off后,显示出文件的大概大小,单位是kB或者MB或者GB
(3).autoindex_format:设置目录列表的格式

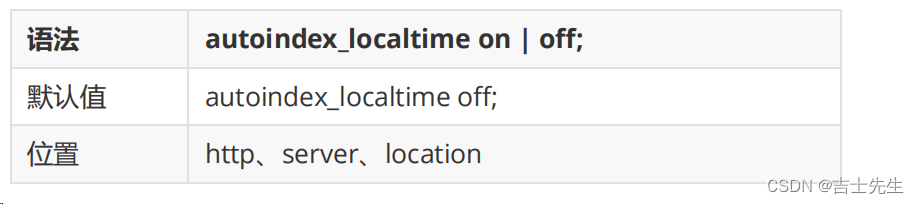
(4).autoindex_localtime:对应HTML格式,是否在目录列表上显示时间。
默认为off,显示的文件时间为GMT时间。 改为on后,显示的文件时间为文件的服务器时间
(4).测试
# 在local文件中创建 download文件夹
cd /usr/local
mkdir download
# 进入download文件夹,并且将我们要下载的文件放在这里
cp -r /root/nginx/core/nginx-1.16.1.tar.gz /usr/local/download在 nginx.conf 配置文件中写下面的数据:
server {listen 80;server_name localhost;location / {root html;index index.html index.htm;}location /download{# 下载文件所在的目录root /usr/local;# 开启站点大小autoindex on;# 开启大小设置autoindex_exact_size on;# 使用html页面autoindex_format html;# 本地时间autoindex_localtime on;
}
自动生成如下目录:
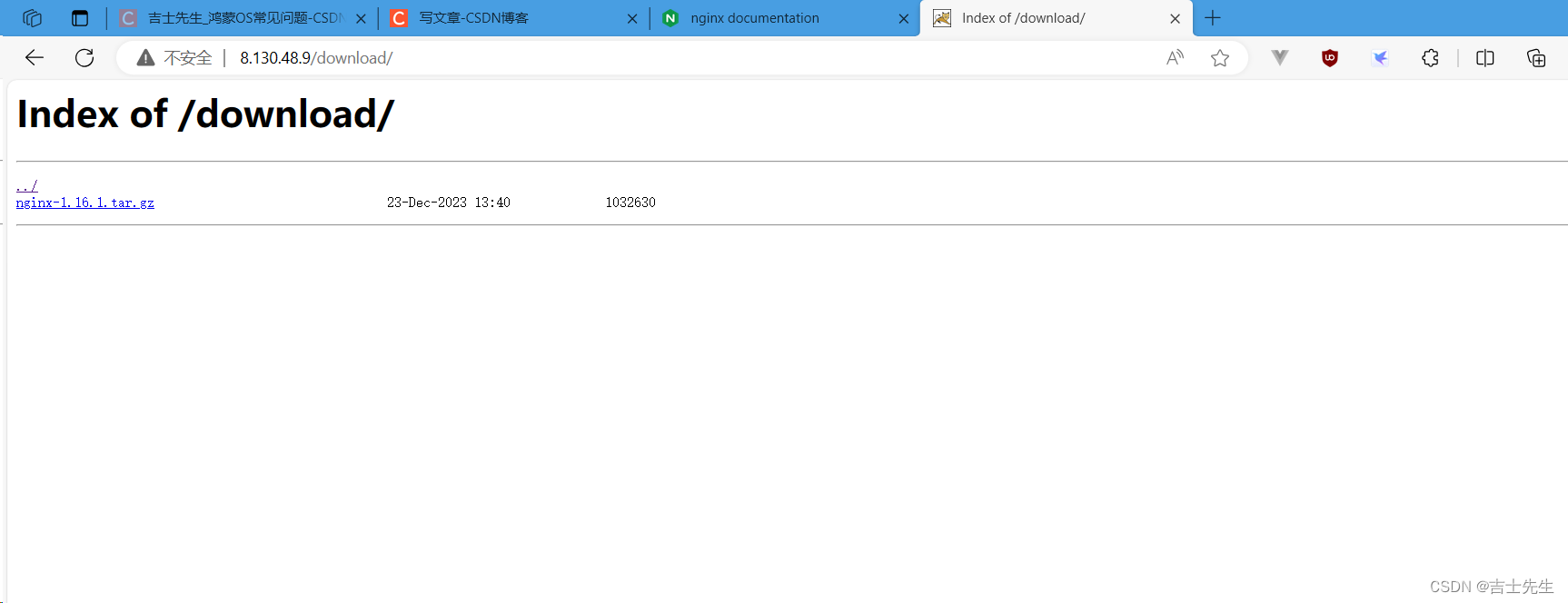
6.Nginx的用户认证模块
对应系统资源的访问,我们往往需要限制谁能访问,谁不能访问。这块就是我们通常所说的认证部分,认证需要做的就是根据用户输入的用户名和密码来判定用户是否为合法用户,如果是则放行访问,如果不是则拒绝访问。
Nginx对应用户认证这块是通过 ngx_http_auth_basic_module 模块来实现的,它允许通过使用"HTTP基本身份验证"协议验证用户名和密码来限制对资源的访问。默认情况下nginx是已经安装了该模块,如果不需要则使用 --without-http_auth_basic_module。
该模块的指令比较简单
(1).auth_basic:使用“ HTTP基本认证”协议启用用户名和密码的验证

开启后,服务端会返回401,指定的字符串会返回到客户端,给用户以提示信息,但是不同的浏览器对内容的展示不一致。
(2).auth_basic_user_file:指定用户名和密码所在文件
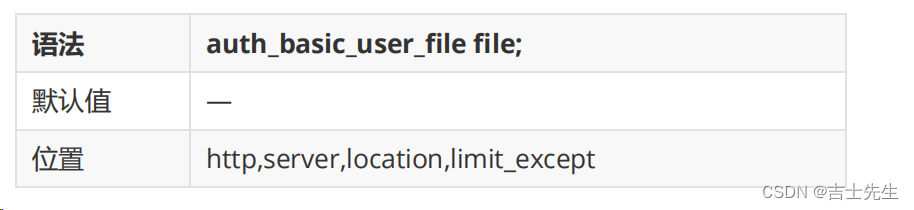
指定文件路径,该文件中的用户名和密码的设置,密码需要进行加密。
可以采用工具自动生成.
实现步骤:
1.nginx.conf添加如下内容
server {listen 80;server_name localhost;#charset koi8-r;#access_log logs/host.access.log main;location / {root html;index index.html index.htm;}location /download{root /usr/local;# 开启站点大小autoindex on;# 开启大小设置autoindex_exact_size on;# 使用html页面autoindex_format html;# 本地时间autoindex_localtime on;# 弹出两个输入框auth_basic 'please input your auth';# 用户名和密码的所在文件auth_basic_user_file htpasswd;
}
2.我们需要使用htpasswd工具生成
yum install -y httpd-tools
//创建一个新文件记录用户名和密码
htpasswd -c /usr/local/nginx/conf/htpasswd 用户名
//在指定文件新增一个用户名和密码
htpasswd -b /usr/local/nginx/conf/htpasswd 用户名 密码
//从指定文件删除一个用户信息
htpasswd -D /usr/local/nginx/conf/htpasswd 用户名
//验证用户名和密码是否正确
htpasswd -v /usr/local/nginx/conf/htpasswd 用户名
我们执行之后我们就会发现我们的conf之中就会有一个 htpaswd

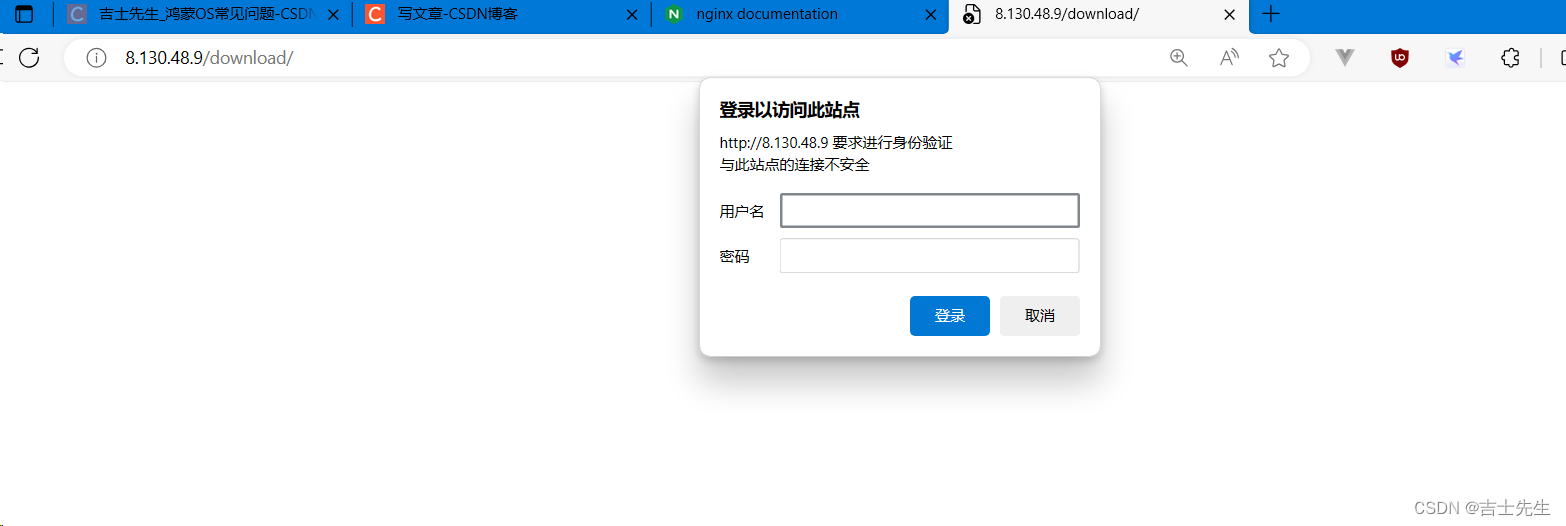
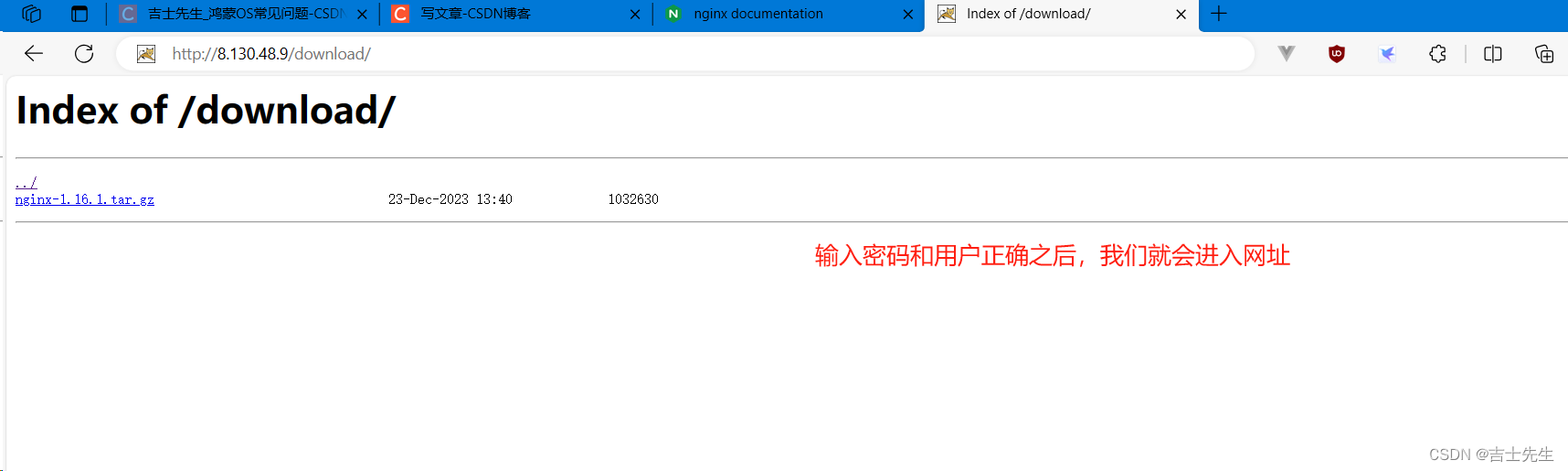
假如我们访问这个下载网址,必须先要我们进行认证:
http://8.130.48.9/download/
(八)、Lua
1.基本介绍
(1).Lua的基本概念
Lua是一种轻量、小巧的脚本语言,用标准C语言编写并以源代码形式开发。设计的目的是为了嵌入到其他应用程序中,从而为应用程序提供灵活的扩展和定制功能。
(2).Lua的特性
跟其他语言进行比较,Lua有其自身的特点:
- 轻量级
Lua用标准C语言编写并以源代码形式开发,编译后仅仅一百余千字节,可
以很方便的嵌入到其他程序中。
- 可扩展
Lua提供非常丰富易于使用的扩展接口和机制,由宿主语言(通常是C或
C++)提供功能,Lua可以使用它们,就像内置的功能一样。
- 支持面向过程编程和函数式编程
(3).应用场景
Lua在不同的系统中得到大量应用,场景的应用场景如下:
游戏开发、独立应用脚本、web应用脚本、扩展和数据库插件、系统安全上。
2.Lua的安装与编译
(1).找到Lua官网
在linux上安装Lua非常简单,只需要下载源码包并在终端解压、编译即可使用。
Lua的官网地址为: https://www.lua.org

(2).进行编译与安装
下载
点击download可以找到对应版本的下载地址,我们本次课程采用的是lua-5.3.5,其对应的资源链接地址为 https://www.lua.org/ftp/lua-5.4.1.tar.gz
也可以使用wget命令直接下载:
wget https://www.lua.org/ftp/lua-5.4.1.tar.gz
编译安装
# 创建文件夹并解压
mkdir lua
tar -zxf lua-5.4.1.tar.gz
cd /root/lua/lua-5.4.1
# 编译
make linux test
make install
如果在执行make linux test失败,报如下错误:

说明当前系统缺少libreadline-dev依赖包,需要通过命令来进行安装
yum install -y readline-devel
验证是否安装成功
lua -v
3.Lua的语法
Lua和C/C++语法非常相似,整体上比较清晰,简洁。条件语句、循环语句、函数调用都与C/C++基本一致。如果对C/C++不太熟悉的同学来说,也没关系,因为天下语言是一家,基本上理解起来都不会太困难。我们一点点来讲。
(1).Lua的两种交互方式
大家需要知道的是,Lua有两种交互方式,分别是:交互式和脚本式,这两者的区别,下面我们分别来讲解下:
- 交互式
交互式是指可以在命令行输入程序,然后回车就可以看到运行的效果。
- Lua交互式编程模式可以通过命令lua -i 或lua来启用:
# 输入这个命令,我们进入lua命令行工具
lua -i
# 执行命令后回车
print("hello world");
- 在命令行中key输入如下命令,并按回车,会有输出在控制台:
// 执行命令后回车
print("hello world");

- 脚本式
脚本式是将代码保存到一个以lua为扩展名的文件中并执行的方式。
- 方式一: 使用lua进行编译解析
我们需要一个文件名为 hello.lua , 在文件中添加要执行的代码,然后通过命令 lua hello.lua 来执行,会在控制台输出对应的结果。
// 创建一个文件夹管理我们的lua程序
mkdir lua_data
cd /root/lua/lua_data
// 编写我们的hello.lua文件
vim hello.lua
print("hello lua!!!");
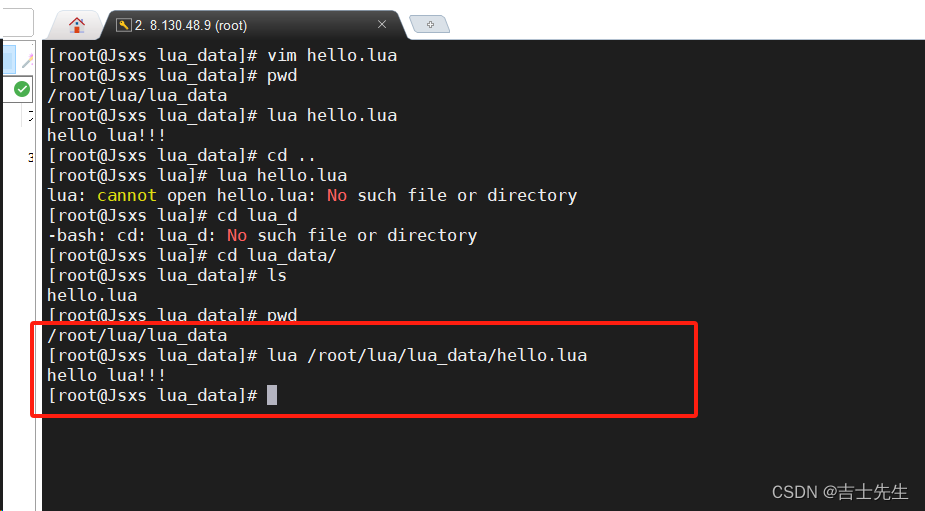
// 运行我们的hello.lua
lua /root/lua/lua_data/hello.lua
在解析编译的过程中
- 方式二: 内嵌lua进行解析编译
#! /usr/local/bin/lua
print("hello lua!!!");
第一行用来指定Lua解释器所在位置为 /usr/local/bin/lua,加上 #号标记解释器会忽略它。一般情况下#!就是用来指定用哪个程序来运行本文件。但是hello.lua并不是一个可执行文件,需要通过chmod来设置可执行权限,最简单的方式为:
chmod 755 hello.lua
然后执行该文件
./hello.lua
补充一点,如果想在交互式中运行脚本式的 hello.lua 中的内容,我们可以使用一个dofile函数,如:
dofile("/root/lua/lua_data/hello.lua")
注意:在Lua语言中,连续语句之间的分隔符并不是必须的,也就是说后面不需要加分号,当然加上也不会报错,
在Lua语言中,表达式之间的换行也起不到任何作用。如以下四个写法,其实都是等效的
#写法一
a=1
b=a+2
#写法二
a=1;
b=a+2;
#写法三
a=1; b=a+2;
#写法四
a=1 b=a+2
不建议使用第四种方式,可读性太差。
(2).Lua的注释
关于Lua的注释要分两种,第一种是单行注释,第二种是多行注释。
单行注释的语法为:
--注释内容
多行注释的语法为:
--[[注释内容注释内容
--]]
如果想取消多行注释,只需要在第一个–之前在加一个-即可,如:
---[[注释内容注释内容
--]]
(3).标识符
换句话说标识符就是我们的变量名,Lua定义变量名以一个字母 A 到 Z或 a 到 z 或 下划线 _ 开头后加上0个或多个字母,下划线,数字(0到9)。这块建议大家最好不要使用下划线加大写字母的标识符,因为Lua的保留字也是这样定义的,容易发生冲突。注意Lua是区分大小写字母的。
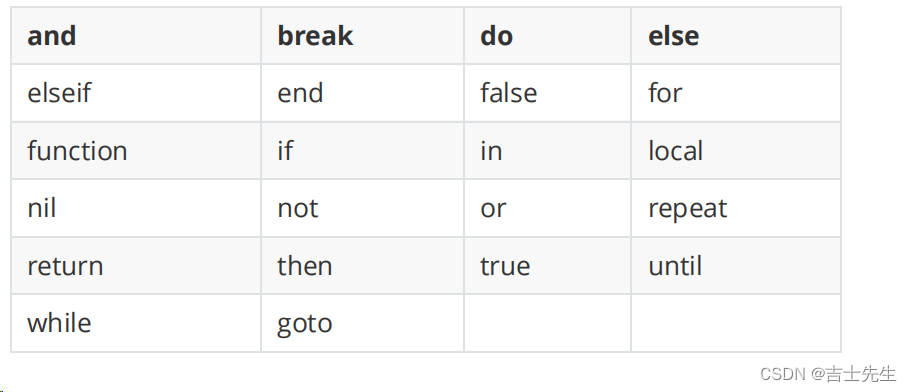
(4).关键字
下列是Lua的关键字,大家在定义常量、变量或其他用户自定义标识符都要避免使用以下这些关键字:
一般约定,以下划线开头连接一串大写字母的名字(比如 _VERSION)被保留用于 Lua 内部全局变量。这个也是上面我们不建议这么定义标识符的原因。
(5).运算符
Lua中支持的运算符有算术运算符、关系运算符、逻辑运算符、其他运算符。
算术运算符:
+ 加法
- 减法
* 乘法
/ 除法
% 取余
^ 乘幂
- 负号
例如:
10+20 -->30
20-10 -->10
10*20 -->200
20/10 -->2
3%2 -->1
10^2 -->100
-10 -->-10
关系运算符
== 等于
~= 不等于
> 大于
< 小于
>= 大于等于
<= 小于等于
例如:
10==10 -->true
10~=10 -->false
20>10 -->true
20<10 -->false
20>=10 -->true
20<=10 -->false
逻辑运算符
and 逻辑与 A and B &&
or 逻辑或 A or B ||
not 逻辑非 取反,如果为true,则返回false !
逻辑运算符可以作为if的判断条件,返回的结果如下:
A = true
B = true
A and B -->true
A or B -->true
not A -->falseA = true
B = false
A and B -->false
A or B -->true
not A -->falseA = false
B = true
A and B -->false
A or B -->true
not A -->true
其他运算符
.. 连接两个字符串
# 一元预算法,返回字符串或表的长度
例如:
"HELLO ".."WORLD" -->HELLO WORLD
#"HELLO" -->5
(6).全局变量&局部变量
在Lua语言中,全局变量无须声明即可使用。在默认情况下,变量总是认为是全局的,如果未提前赋值,默认为nil:
# 我们设置全局变量,我们发现我们的全局变量能够打印
> b=10
> print(b)
10
要想声明一个局部变量,需要使用local来声明
# 设置局部变量的话,我们发现我们打印不出来
> local a = 100
> print(a)
nil
# 假如说我们的命令在同一个命令行的话,那么局部变量就能使用
> local c=100; print(c)
100结论: 如果是全局变量,那么我们每一个命令行都能访问,如果说是局部变量的话,那么我们只能访问这一行的数据。
4.Lua数据类型
Lua有8个数据类型
nil(空,无效值)
boolean(布尔,true/false)
number(数值)
string(字符串)
function(函数)
table(表)
thread(线程)
userdata(用户数据)
可以使用 type 函数测试给定变量或者的类型:
print(type(nil)) -->nil
print(type(true)) --> boolean
print(type(1.1*1.1)) --> number
print(type("Hello world")) --> string
print(type(io.stdin)) -->userdata
print(type(print)) --> function
print(type(type)) -->function
print(type{}) -->table
print(type(type(X))) --> string
(1).nil (空值)
nil是一种只有一个nil值的类型,它的作用可以用来与其他所有值进行区分,也可以当想要移除一个变量时,只需要将该变量名赋值为nil,垃圾回收就会会释放该变量所占用的内存。
(2).boolean (布尔)
boolean类型具有两个值,true和false。boolean类型一般被用来做条件判断的真与假。在Lua语言中,只会将false和nil视为假,其他的都视为真,特别是在条件检测中0和空字符串都会认为是真,这个和我们熟悉的大多数语言不太一样。
(3).number (数值)
在Lua5.3版本开始,Lua语言为数值格式提供了两种选择: integer(整型)和float(双精度浮点型) [和其他语言不太一样,float不代表单精度类型]。
数值常量的表示方式:
>4 -->4
>0.4 -->0.4
>4.75e-3 -->0.00475
>4.75e3 -->4750
不管是整型还是双精度浮点型,使用type()函数来取其类型,都会返回的是number
>type(3) -->number
>type(3.3) -->number
所以它们之间是可以相互转换的,同时,具有相同算术值的整型值和浮点型值在Lua语言中是相等的
(4).string (字符串)
Lua语言中的字符串即可以表示单个字符,也可以表示一整本书籍。在Lua语言中,操作100K或者1M个字母组成的字符串的程序很常见。
可以使用
单引号或双引号来声明字符串
>a = "hello"
>b = 'world'
>print(a) -->hello
>print(b) -->world
如果声明的字符串比较长或者有多行,则可以使用如下方式进行声明
html = [[
<html>
<head>
<title>Lua-string</title>
</head>
<body>
<a href="http://www.lua.org">Lua</a>
</body>
</html>
]]
(5).table (表)
table是Lua语言中最主要和强大的数据结构。使用表, Lua 语言可以以一种简单、统一且高效的方式表示数组、集合、记录和其他很多数据结构。 Lua语言中的表本质上是一种辅助数组。这种数组比Java中的数组更加灵活,可以使用数值做索引,也可以使用字符串或其他任意类型的值作索引(除nil外)。
创建表的最简单方式:
> a = {}
创建数组:
我们都知道数组就是相同数据类型的元素按照一定顺序排列的集合,那么使用table如何创建一个数组呢?
>arr = {"TOM","JERRY","ROSE"}
要想获取数组中的值,我们可以通过如下内容来获取:
在Lua语言中我们的数组下标是从1开始的,不是0
print(arr[0]) nil
print(arr[1]) TOM
print(arr[2]) JERRY
print(arr[3]) ROSE
从上面的结果可以看出来,数组的下标默认是从1开始的。所以上述创建数组,也可以通过如下方式来创建
>arr = {}
>arr[1] = "TOM"
>arr[2] = "JERRY"
>arr[3] = "ROSE"
上面我们说过了,表的索引即可以是数字,也可以是字符串等其他的内容,所以我们也可以将索引更改为字符串来创建
>arr = {}
>arr["X"] = 10
>arr["Y"] = 20
>arr["Z"] = 30
当然,如果想要获取这些数组中的值,可以使用下面的方式
// 错误的获取方式,我们发现获取为空
>print(arr[1])
> nil
//方式一
>print(arr["X"])
>print(arr["Y"])
>print(arr["Z"])
//方式二
>print(arr.X)
>print(arr.Y)
>print(arr.Z)
当前table的灵活不进于此,还有更灵活的声明方式
>arr = {"TOM",X=10,"JERRY",Y=20,"ROSE",Z=30}
如何获取上面的值?
TOM : arr[1]
10 : arr["X"] | arr.X
JERRY: arr[2]
20 : arr["Y"] | arr.Y
ROESE : arr[3]
(6).function (函数)
在 Lua语言中,函数( Function )是对语句和表达式进行抽象的主要方式。
定义函数的语法为:
function functionName(params)end
函数被调用的时候,传入的参数个数与定义函数时使用的参数个数不一致的时候,Lua 语言会通过 抛弃多余参数和将不足的参数设为 nil 的方式来调整参数的个数。
function f(a,b)print(a,b)
endf() --> nil nilf(2) --> 2 nilf(2,6) --> 2 6f(2.6.8) --> 2 6 (8被丢弃)
可变长参数函数
function add(...)a,b,c=...print(a)print(b)print(c)
endadd(1,2,3) --> 1 2 3
函数返回值可以有多个,这点和Java不太一样
function f(a,b)return a,b
endx,y=f(11,22) --> x=11,y=22
(7).thread (线程)
thread翻译过来是线程的意思,在Lua中,thread用来表示执行的独立线路,用来执行协同程序。
(8).userdata (用户数据)
userdata是一种用户自定义数据,用于表示一种由应用程序或C/C++语言库所创建的类型。
5.Lua控制结构
Lua 语言提供了一组精简且常用的控制结构,包括用于条件执行的证 以及用于循环的 while、 repeat 和 for。 所有的控制结构语法上都有一个显式的终结符: end 用于终结 if、 for 及 while 结构, until 用于终结repeat 结构。
(1).if then elseif else
if语句先测试其条件,并根据条件是否满足执行相应的 then 部分或 else部分。 else 部分 是可选的。
function testif(a)if a>0 thenprint("a是正数")end
endfunction testif(a)if a>0 then print("a是正数")elseprint("a是负数")end
end
如果要编写嵌套的 if 语句,可以使用 elseif。 它类似于在 else 后面紧跟一个if。根据传入的年龄返回不同的结果,如
age<=18 青少年,
age>18 , age <=45 青年
age>45 , age<=60 中年人
age>60 老年人function show(age)if age<=18 thenreturn "青少年"elseif age>18 and age<=45 thenreturn "青年"elseif age>45 and age<=60 thenreturn "中年人"elseif age>60 thenreturn "老年人"end
end
(2).while循环 (先判断在执行)
顾名思义,当条件为真时 while 循环会重复执行其循环体。 Lua 语言先测试 while 语句 的条件,若条件为假则循环结束;否则, Lua 会执行循环体并不断地重复这个过程。
语法:
while 条件 do循环体
end
例子:实现数组的循环
function testWhile()local i = 1while i<=10 doprint(i)i=i+1end
end
(3).repeat循环 (先执行在判断条件)
顾名思义, repeat-until语句会重复执行其循环体直到条件为真时结束。 由于条件测试在循环体之后执行,所以循环体至少会执行一次。
语法
repeat循环体until 条件
function testRepeat()local i = 10repeatprint(i)i=i-1until i < 1
end
(4).for循环
数值型for循环
语法
for param=exp1,exp2,exp3 do循环体
end
param 的值从exp1变化到 exp2之前的每次循环会执行循环体,并在每次循环结束后将步长(step)exp3增加到param上。exp3可选,如果不设置默认为1
for i = 1,100,10 doprint(i)
end
泛型for循环
泛型for循环通过一个迭代器函数来遍历所有值,类似于java中的foreach语句。
语法
for i,v in ipairs(x) do循环体
end
i是数组索引值,v是对应索引的数组元素值,ipairs是Lua提供的一个迭代器函数,用来迭代数组,x是要遍历的数组。
例如:
arr = {"TOME","JERRY","ROWS","LUCY"}for i,v in ipairs(arr) doprint(i,v)end
上述实例输出的结果为
1 TOM
2 JERRY
3 ROWS
4 LUCY
但是如果将arr的值进行修改为
arr = {"TOME","JERRY","ROWS",x="JACK","LUCY"}
同样的代码在执行的时候,就只能看到和之前一样的结果,而其中的x为JACK就无法遍历出来,缺失了数据,如果解决呢?
我们可以将迭代器函数变成pairs,如
for i,v in pairs(arr) doprint(i,v)
end
上述实例就输出的结果为
1 TOM
2 JERRY
3 ROWS
4 LUCY
x JACK
(九)、ngx_lua模块概念
淘宝开发的 ngx_lua模块 通过将 lua解释器集成进Nginx ,可以采用 lua脚本 实现业务逻辑,由于lua的紧凑、快速以及内建协程,所以在保证高并发服务能力的同时极大地降低了业务逻辑实现成本。
1.ngx_lua模块环境准备
(1).方式一:lua-nginx-module
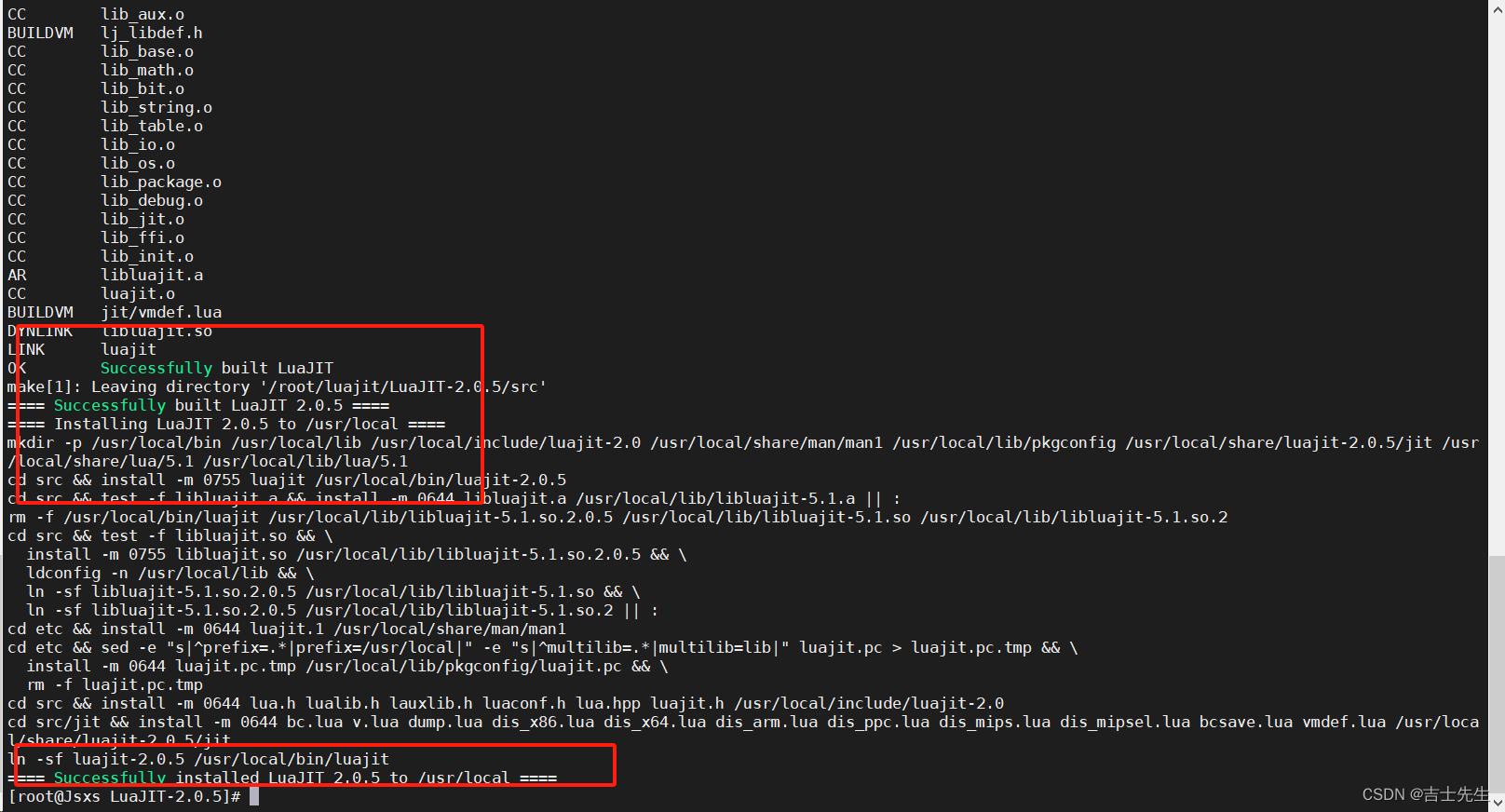
- LuaJIT是采用C语言编写的Lua代表的解释器。
官网地址为: http://luajit.org/
在官网上找到对应的下载地址: http://luajit.org/download/LuaJIT-2.0.5.tar.gz
在centos上使用wget来下载:
wget http://luajit.org/download/LuaJIT-2.0.5.tar.gz
将下载的资源进行解压:
tar -zxf LuaJIT-2.0.5.tar.gz
进入解压的目录:
cd LuaJIT-2.0.5
执行编译和安装:
make && make install
- 下载lua-nginx-module
下载地址: https://github.com/openresty/lua-nginx-module/archive/v0.10.16rc4.tar.gz
在centos上使用wget来下载:
wget https://github.com/openresty/luanginxmodule/archive/v0.10.16rc4.tar.gz
将下载的资源进行解压:
tar -zxf lua-nginx-module-0.10.16rc4.tar.gz
更改目录名:
mv lua-nginx-module-0.10.16rc4 lua-nginx-module
导入环境变量,告诉Nginx去哪里找luajit
export LUAJIT_LIB=/usr/local/lib
export LUAJIT_INC=/usr/local/include/luajit-2.0
进入Nginx的目录执行如下命令:
./configure --prefix=/usr/local/nginx --addmodule=../lua-nginx-module
进行编译与安装
make && make install
注意事项:
(1)如果启动Nginx出现如下错误:

解决方案:
设置软链接,使用如下命令
ln -s /usr/local/lib/libluajit-5.1.so.2 /lib64/libluajit-5.1.so.2
(2)如果启动Nginx出现以下错误信息
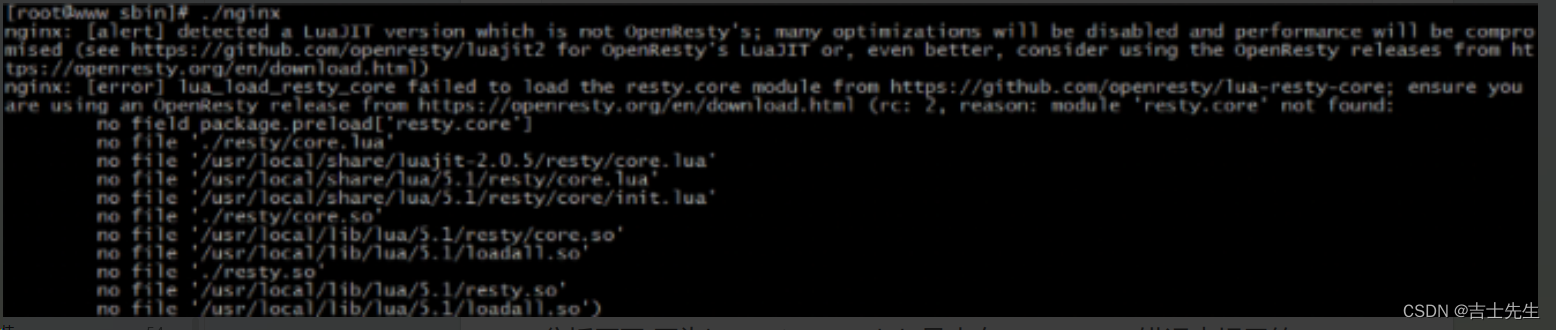
分析原因:因为lua-nginx-module是来自openrestry,错误中提示的
resty.core是openrestry的核心模块,对其下的很多函数进行了优化等工作。以前的版本默认不会把该模块编译进去,所以需要使用的话,我们得手动安装,或者禁用就可以。但是最新的lua-nginx-module模块已经强制性安装了该模块,所以此处因为缺少resty模块导致的报错信息。
解决方案有两个: 一种是下载对应的模块,另一种则是禁用掉restry模块,禁用的方式为:
http{lua_load_resty_core off;
}
- 测试
在nginx.conf下配置如下内容:
location /lua{default_type 'text/html';content_by_lua 'ngx.say("<h1>HELLO,LUA</h1>")';
}
配置成功后,启动nginx,通过浏览器进行访问,如果获取到如下结果,则证明安装成功。

(2).方式二: OpenRestry (推荐⭐)
概述
前面我们提到过,OpenResty是由淘宝工程师开发的,所以其官方网站(http://openresty.org/)我们读起来是非常的方便。OpenResty是一个基于Nginx与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。所以本身OpenResty内部就已经集成了Nginx和Lua,所以我们使用起来会更加方便。
安装
# 因为openresty内置了nginx所以,我们先把宿主机的nginx关闭
nginx -s stop
#(1) 下载OpenResty:
https://openresty.org/download/openresty-1.15.8.2.tar.gz
#(2)使用wget下载:
mkdir openresty
cd openresty
wget https://openresty.org/download/openresty-1.15.8.2.tar.gz
#(3)解压缩:tar -zxf openresty-1.15.8.2.tar.gz
#(4)进入OpenResty目录:
cd openresty-1.15.8.2
#(5) 执行命令:
./configure
#(6) 执行命令:
make && make install
#(7)进入OpenResty的目录,找到nginx:
cd /usr/local/openresty/nginx/conf
#(8)在conf目录下的nginx.conf添加如下内容
location /lua{default_type 'text/html';content_by_lua 'ngx.say("<h1>HELLO,OpenRestry</h1>")';
}
#(9)在sbin目录下启动nginx
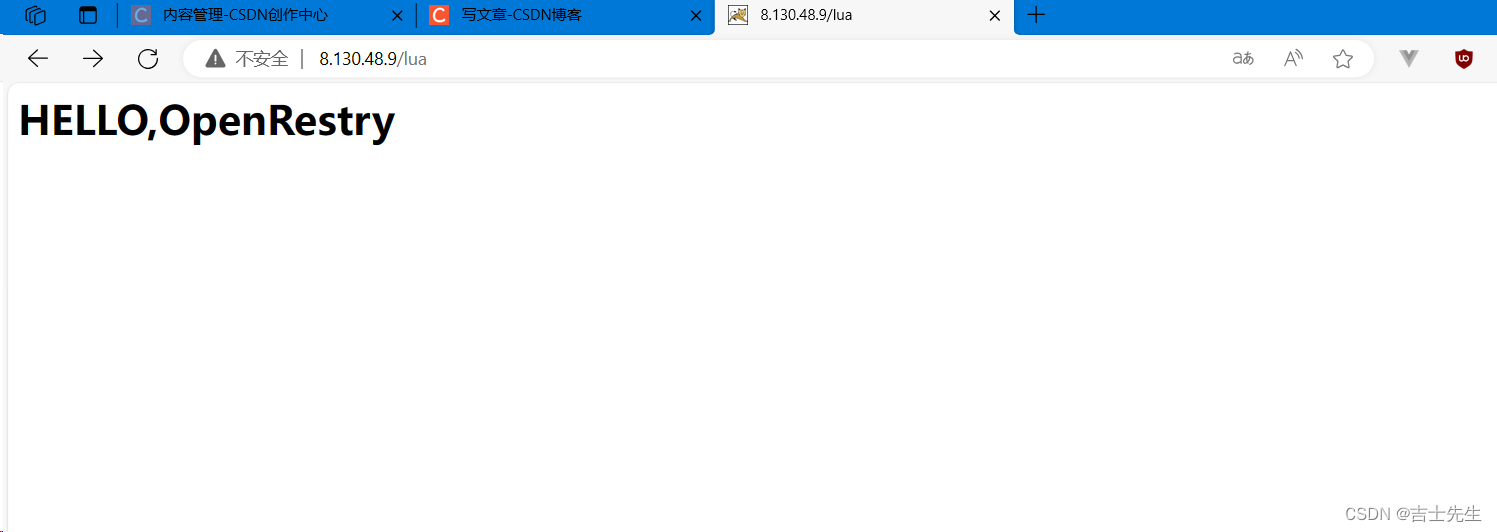
./nginx
#(10)通过浏览器访问测试
http://8.130.48.9/lua
2.ngx_lua的使用
使用Lua编写Nginx脚本的基本构建块是指令。指令用于指定何时运行用户Lua代码以及如何使用结果。下图显示了执行指令的顺序。
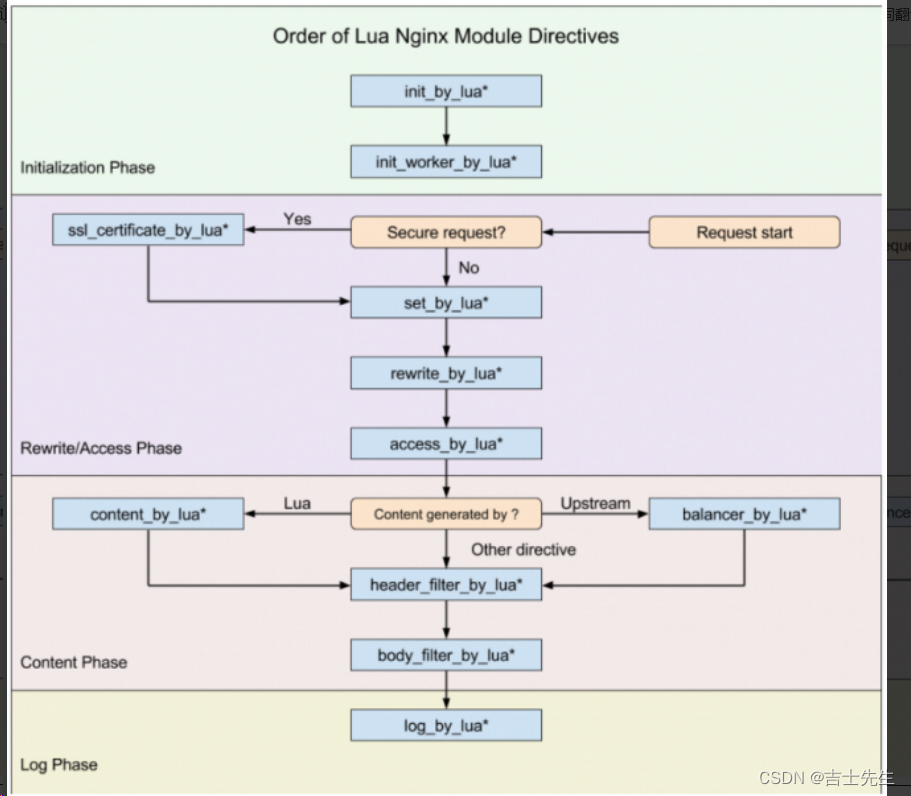
先来解释下*的作用
*: 无 , 即 xxx_by_lua ,指令后面跟的是 lua指令
*:_file,即 xxx_by_lua_file 指令后面跟的是 lua文件
*:_block,即 xxx_by_lua_block 在0.9.17版后替换init_by_lua_file
(1).init_by_lua*
该指令在每次Nginx重新加载配置时执行,可以用来完成一些耗时模块的加载,或者初始化一些全局配置。
(2).init_worker_by_lua*
该指令用于启动一些定时任务,如心跳检查、定时拉取服务器配置等。
(3).set_by_lua*
该指令只要用来做变量赋值,这个指令一次只能返回一个值,并将结果赋值给Nginx中指定的变量。
(4).rewrite_by_lua*
该指令用于执行内部URL重写或者外部重定向,典型的如伪静态化URL重写,本阶段在rewrite处理阶段的最后默认执行。
(5).access_by_lua*
该指令用于访问控制。例如,如果只允许内网IP访问。
(6).content_by_lua*
该指令是应用最多的指令,大部分任务是在这个阶段完成的,其他的过程往往为这个阶段准备数据,正式处理基本都在本阶段。
(7).header_filter_by_lua*
该指令用于设置应答消息的头部信息。
(8).body_filter_by_lua*
该指令是对响应数据进行过滤,如截断、替换。
(9).log_by_lua*
该指令用于在log请求处理阶段,用Lua代码处理日志,但并不替换原有log处理。
(10).balancer_by_lua*
该指令主要的作用是用来实现上游服务器的负载均衡器算法
(11).ssl_certificate_by_*
该指令作用在Nginx和下游服务开始一个SSL握手操作时将允许本配置项的Lua代码。