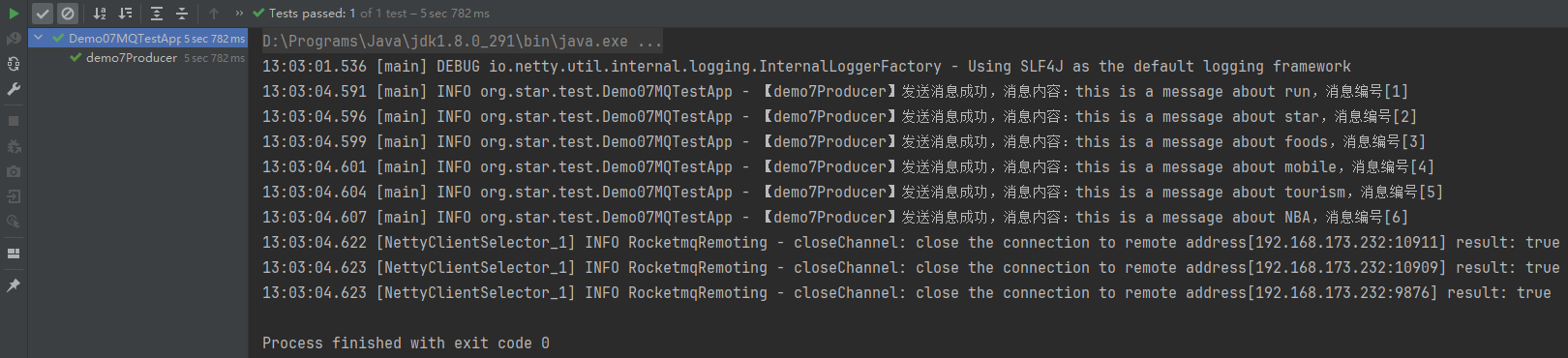
官网的都是手动训练,我做了一个自动化训练,执行一下,然后全部就能训练完。
说明:

audio是存放原始音频的位置,auto_train_main是核心自动化代码。
auto_train_main代码:
# -*- coding: utf-8 -*-
import string
import random
import requests
import pymysql
import sys
import os
import shutil
import subprocessimport paramiko
#-1代表错误,0代表警告提示,1代表执行成功
from run import slicer_fn
from run_auto_label import training_model
from basemodel_weitiao import weitiaodef con_mysql():conn = pymysql.connect(host="xxx",user="xxx",password="xxx",port=xx,db="xx",charset="utf8")return conn# 查询,是否有正在执行的任务
def get_task(conn, user_id, audio_url):cursor = conn.cursor()# 是否有空的机器可以训练,以后改队列sql = "SELECT * FROM kantts_auto_train_task where status=1"cursor.execute(sql)results = cursor.fetchall() # 获取所有查询结果if len(results) != 0:print("warn:【0.获取task警告】:目前机器正在被人训练...请稍后在来")error_msg = "warn:【0.获取task警告】:目前机器正在被人训练...请稍后在来"return {"code": 0, "error_msg": error_msg}# 这个用户是否已经训练完成sql = "SELECT * FROM kantts_auto_train_task where user_id=%s"cursor.execute(sql, [user_id])results = cursor.fetchall() # 获取所有查询结果if len(results) != 0:task_info = results[0]code =task_info[3]if code == 2:error_msg = "warn:【0.获取task警告】:用户已经训练过模型了"return {"code": 0, "error_msg": error_msg}#更新数据库,继续开始return update_task(conn,user_id,audio_url,1,"")# 没有数据,则插入任务sql = "INSERT INTO " \"kantts_auto_train_task(user_id,audio_url,status) " \"VALUES(%s,%s,%s)"cursor.execute(sql, [user_id, audio_url, 1])conn.commit()return {"code": 1, "error_msg": ""}def update_task(conn , user_id , audio_url ,status ,error_msg):cursor = conn.cursor()sql = "update kantts_auto_train_task set " \"user_id = %s ,audio_url = %s, status =%s , error_msg=%s where user_id = %s"cursor.execute(sql, [user_id, audio_url, status, error_msg, user_id])conn.commit()return {"code": 1, "error_msg": ""}#警告不更新状态,只更新提示
def update_task_warn(conn , user_id ,error_msg):cursor = conn.cursor()sql = "update kantts_auto_train_task set " \"user_id = %s , error_msg=%s where user_id = %s"cursor.execute(sql, [user_id, error_msg, user_id])conn.commit()return {"code": 1, "error_msg": ""}
# 获取训练的音频数据
#删除目录所有内容
def deletePathFile(path):for filename in os.listdir(path):file_path = os.path.join(path, filename)try:if os.path.isfile(file_path) or os.path.islink(file_path):os.unlink(file_path)elif os.path.isdir(file_path):shutil.rmtree(file_path)except Exception as e:print('Failed to delete %s. Reason: %s' % (file_path, e))print('Successfully deleted all content from directory %s' % path)def downloadAudio(audio_url):if audio_url.endswith(".wav"):audio_name = 'audio/source_audio.wav'response = requests.get(audio_url, stream=True)with open(audio_name, 'wb') as f:for chunk in response.iter_content(chunk_size=1024):if chunk:f.write(chunk)return {"code": 1, "error_msg": ""}else:error_msg="error:【1.获取音频错误】:音频必须为wav"print(error_msg)return {"code": -1, "error_msg": error_msg}def random_string(length):letters = string.ascii_letters + string.digitsreturn ''.join(random.choice(letters) for _ in range(length))def checkRs(conn,task,user_id,audio_url):if task["code"] == -1:# 写入数据库,然后停止update_task(conn,user_id,audio_url,-1,task["error_msg"])sys.exit()if task["code"] == 0:# 写入数据库,然后停止update_task_warn(conn,user_id,task["error_msg"])sys.exit()
#音频切片
def create_split_mkdir(user_id):# 判断目录是否存在,不存在则创建test_path = '/kan_tts/tmp/test_wavs/' + user_idif os.path.exists(test_path):# 删除目录及其内容shutil.rmtree(test_path)os.mkdir(test_path)else:os.mkdir(test_path)return test_path
#同步模型到合成的机器
def scp_file_path(local_path,remote_path):remote_path = "mqq@192.168.51.39:"+remote_pathp = subprocess.Popen(["scp","-r", local_path, remote_path])sts = os.waitpid(p.pid, 0)
if __name__ == '__main__':user_id = "xxx"audio_url = "https://xxx.wav"conn = con_mysql()print("接收到的参数是{\"user_id\":%s,\"audio_url\":%s}" % (user_id,audio_url))#检测机器是否被占用task = get_task(conn, user_id, audio_url)checkRs(conn,task,user_id,audio_url)print("开始执行任务.."+user_id)#删除目录中的其他音频deletePathFile("audio")#获取音频print("====1.开始获取音频")task = downloadAudio(audio_url)checkRs(conn, task, user_id, audio_url)print("====1.音频处理完成")#切分音频print("====2.开始切分音频")test_path = create_split_mkdir(user_id)try:#指定待切分的目录slicer_fn("audio",test_path)except Exception as e:task["code"]=-1task["error_msg"]="error:【2.音频切分错误】,请检查你的音频提交音否正常"print("error:【2.音频切分错误】,请检查你的音频提交音否正常")checkRs(conn, task, user_id, audio_url)print(e)sys.exit(0)print("====2.完成切分音频")print("====3.开始进行标注")try:training_model(user_id)except Exception as e:task["code"]=-1task["error_msg"]="error:【3.数据标注错误】,请检查你的切分音频路径"print("error:【3.数据标注错误】,请检查你的切分音频路径")checkRs(conn, task, user_id, audio_url)print(e)sys.exit(0)print("====3.标注完成")print("====4.开始微调训练4000步,预计30分钟")try:dataset_id = "/kan_tts/tmp/output_dir/"+user_idpretrain_work_dir = "/kan_tts/tmp/pretrain_work_dir/"+user_idweitiao(dataset_id, pretrain_work_dir)except Exception as e:task["code"]=-1task["error_msg"]="error:【4.微调训练错误】,请检查是否音频质量"print("error:【4.微调训练错误】,请检查是否音频质量")checkRs(conn, task, user_id, audio_url)print(e)sys.exit(0)print("====4,完成微调")print("====5,开始往机器同步")try:local_path = "/kan_tts/tmp/pretrain_work_dir/"+user_idremote_path = "/pzk/ttsGuaZai/tmp/pretrain_work_dir"task = scp_file_path(local_path,remote_path)# if task["code"] == -1:# print(task["error_msg"])# checkRs(conn, task, user_id, audio_url)# sys.exit(0)except Exception as e:task["code"] = -1task["error_msg"] = "error:【5.同步到合成机器错误】,请检查远程目录以及本地目录的predict_dir是否存在此用户模型"print("error:【5.同步到合成机器错误】,请检查远程目录以及本地目录的predict_dir是否存在此用户模型")print("检查是否开启ssh免密https://blog.csdn.net/u010044182/article/details/128664248")checkRs(conn, task, user_id, audio_url)print(e)sys.exit(0)# print("====5,同步结束")print("====6,配置数据库-至正式服")#配置音频数据库#配置当前的正式服的训练信息print("====6,配置数据库完成")其他的代码就是model_scope官网的代码,切分代码请看我历史博客,里面有。