前言
Pandas是贯穿数据分析的主要工具之一,它经常和其他数值计算工具一起使用(例如:Numpy、SciPy和matplotlib)。尽管pandas采用了很多NumPy的代码风格,但二者最大的区别是:pandas主要用于处理表格型或异质型数据;而NumPy更适合处理同质性数据
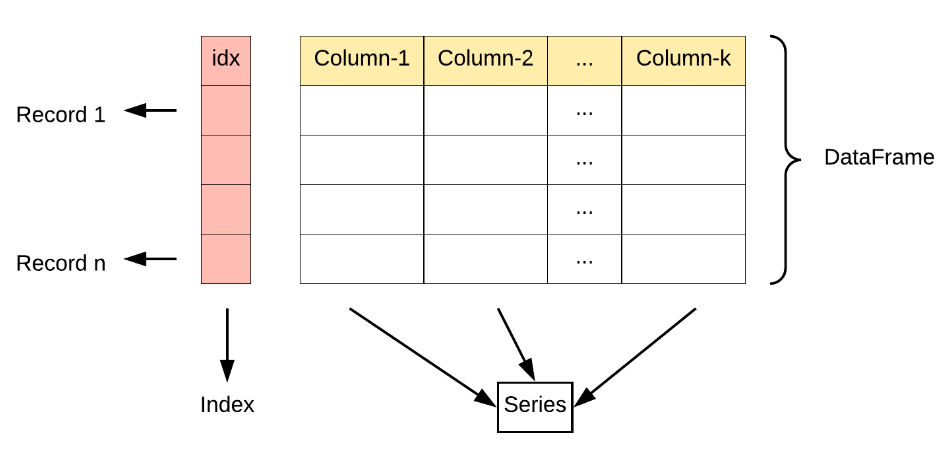
Pandas 主要引入了两种新的数据结构:DataFrame 和 Series。
- pandas和numpy的区别
pandas给出了索引,通过索引对数据进行操作,对索引的操作 就是对 数据本身的操作
1.Series
1.1 Series简介
Series 是 Pandas 中的一种基本数据结构,类似于一维数组或列表,可以保存任何数据类型。
- 特点:
1)它的每一个值都具有一个标签(可以是整数、字符串、日期等类型),用于索引;若未指定显示索引,会自动创建一个默认的整数索引
2)Series 可以容纳不同数据类型的元素,包括整数、浮点数、字符串等
1.2 Series的创建
- 法一:直接创建
pandas.Series( data, index, dtype, name)
参数说明:
data:一组数据(ndarray 类型)
index:数据索引标签
dtype:数据类型
name:设置名称
也可以直接通过两个列表来创建series 数据 = pd.Series(列表2,index=列表1)
data = pd.Series(["勒布朗","Lakers",23,"2020-10-12"],index=["姓名","球队","号码","夺冠时间"],name="个人信息")- 法二:通过字典创建Series
先使用 key/value 对象创建一个字典,然后利用 pd.Series(字典) 转化为Series
import pandas as pd
dir = {1: "JJ", 2: "GEM", 3: "Jay"} #创建字典
myvar = pd.Series(dir) #字典中的key就相当于index
print(myvar)1.3 Series的索引
与numpy的索引功能非常类似,但series不但可以索引编号,也可以索引名称 ;而且series的基于标签索引切片是包含尾部的(基于整数索引不含尾部)
我们可以直接利用标签来进行索引,但注意,若要同时索引多个目标,需要在索引列表中再输入一个列表
import pandas as pd
dir = {"man": "JJ", "woman": "GEM", "boy": "Jay"}
myvar = pd.Series(dir)
a = myvar["man"] #索引单个目标
b = myvar[["man","woman"]] #索引多个目标
c = myvar[0:2] #也可利用编号切片(注意:series名称索引切片是包含尾部的)
1.4 属性、方法和基本运算
| 方法 | 说明 |
|---|---|
| S.index | 获取所有索引信息 |
| S.values | 获取所有值 数组 |
| S.describe() | 获取描述统计信息 (如:个数、去除重复后个数、首部) |
| S.idxmax() S.idxmin() | 最大、最小值的索引 |
| S.isnull() S.notnull() | 查看数据是否(不)缺失 (返回布尔) |
Series 也可以直接进行运算,例如:
# 算术运算
result = series * 2 # 所有元素乘以2# 过滤
filtered_series = series[series > 2] # 选择大于2的元素# 数学函数
import numpy as np
result = np.sqrt(series) # 对每个元素取平方根2.Dataframe
2.1 Dataframe简介
DataFrame 是一个表格型的数据结构。 它含有一组有序的列,每列可以是不同的值类型。可以被看做由多个 Series 组成的字典(共同用一个索引)。
- 特点
1)既有行索引也有列索引,即行和列都有自己的名称
2)不同的列可以包含不同的数据类型,例如整数、浮点数、字符串等
2.2 Dataframe的创建
一般来说是利用 包含等长度列表或numpy数组 的 字典来形容dataframe,缺少的元素会自动以NaN补齐
语法: pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
data:一组数据(ndarray、series, list, dict 等类型)
index:索引值,或者可以称为行标签
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n)
dtype:数据类型
# 利用含有列表的字典创建
import pandas as pd
data1 = {"城市":["北京","上海","深圳","广州"],"同比":[120.7,127.3,119.4,140.9],"环比":[101.5,101.2,101.3,120.0],"定基":[121.4,127.8,120.0,145.5]}d = pd.DataFrame(data1,index=[1,2,3,4],columns=["城市","同比","环比","定基"])
print(d)# 利用含有数组的字典构建
data2 = {"team":pd.Series(["lakers","suns","kings"],index=["a","b","c"]),"player":pd.Series(["lbj","kd","fox","sga"],index=["a","b","c","d"])}
e = pd.DataFrame(data2)
print(e)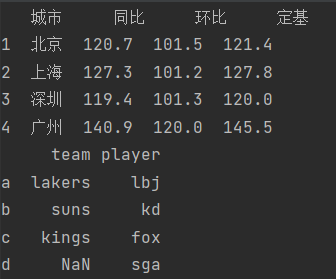
2.3 Dataframe的索引
- 索引列 : df [ 列索引名 ] 若要索引多列则需要输入多重 [[ ]]
- 索引行 : df.loc [ 行索引名 ] 索引多行同上
- 索引单个数据:df [ 列索引名 ][ 行索引名 ]
- 我们也可以利用条件语句 df [ 条件 ] 过滤行 和 列
import pandas as pd
data1 = {"城市":["北京","上海","深圳","广州"],"同比":[120.7,127.3,119.4,140.9],"环比":[101.5,101.2,101.3,120.0],"定基":[121.4,127.8,120.0,145.5]}d = pd.DataFrame(data1,index=[1,2,3,4])print(d["城市"]) #获取单列
print(d[["城市","定基"]]) #获取多列print(d.loc[2]) #获取单行 ([]内输入索引名称)
print(d.loc[[2,3]]) #获取多列 ([]内输入索引名称)print(d["城市"][2]) #获取单个数据print(d[d["定基"] > 120]) #过滤数据- 行索引:loc 和 iloc
我们已知, 基于标签索引和基于整数编号索引,在是否保留尾部上不一致,容易产生歧义;故设计了两种运算符来对应他们,即:loc(保留尾部) 和 iloc(不保留尾部)
2.4 属性、方法和基本运算
| 方法 | 说明 |
|---|---|
| df.columns | 获取列索引 |
| df.shape | 获取形状(行 列数) |
| df.index | 获取行索引 |
| df.describe() | 获取描述统计信息 |
| df [ xxx ] = [ xxx, xxx, xxx ] | 添加新列 |
2.5 对索引的操作
在Dataframe中通过 df.index 或 df.columns 可以获得0轴和1轴上的索引,返回的索引类型都是Index类型(类似一个固定大小的集合,但可含重复标签),而Index对象是一个不可修改的对象(无法通过 index [ 1 ] = xxx 修改)
前面提到过pandas中,对索引的操作 == 对数据的操作,因此我们有以下常用的索引操作
| 方法 | 说明 |
| . delete(loc) | 删除loc处位置的元素 |
| . insert ( loc,e ) | 在loc位置新增一个元素 |
| . append ( index ) | 将另一个index对象放在原来的index对象后面,产生新的index对象 |
import pandas as pd
data1 = {"城市":["北京","上海","深圳","广州"],"同比":[120.7,127.3,119.4,140.9],"环比":[101.5,101.2,101.3,120.0],"定基":[121.4,127.8,120.0,145.5]}
d = pd.DataFrame(data1,index=["c1","c2","c3","c4"])n1 = d.columns.delete(2) #删除第三列
n2 = d.index.insert(4,"c5") #新增一行
newd = d.reindex(index=n2,columns=n1) #重组
newd.loc["c5"]= ["成都",105,110]
print(newd)3.基本操作
3.1 重建索引
- 作用:重排series或dataframe的索引
- 语法 :
df.reindex(index = , columns= ,method = ,fill _value=)
index:新的行自定义索引
columns:新的列自定义索引
method:填充方法,ffill为向前填充 ; bfill为向后填充
fill _value:填充缺失位置的值
import pandas as pd
data1 = {"城市":["北京","上海","深圳","广州"],"同比":[120.7,127.3,119.4,140.9],"环比":[101.5,101.2,101.3,120.0],"定基":[121.4,127.8,120.0,145.5]}
d = pd.DataFrame(data1,index=["c1","c2","c3","c4"])newd = d.reindex(index=["c4","c3","c2","c1","c0"],columns=["定基","环比","同比","城市"],fill_value=0) #重组print(newd)
3.2 在轴上删除条目(索引)
- 作用:删除指定的行 / 列条目(直接修改原数组)
- 语法:
df.drop(“xxx” , axis = 0 / 1)
axis:指定删除的轴 默认为0轴 即删除行
3.3 算数和数据对齐
在pandas中,在两个不同的索引化对象之间进行算数操作时,会返回两者的并集,在没有交叠的位置上,返回的值为NaN,我们可以通过设置fill_value参数来填充缺失值
import pandas as pd
a = pd.DataFrame(np.arange(9).reshape(3,3),columns=["a","b","c"],index=["A","B","C"])
b = pd.DataFrame(np.arange(9).reshape(3,3),columns=["a","b","d"],index=["A","B","D"])print(a.mul(b,fill_value=0))# 乘法是对应位置元素相乘3.4 将某个函数应用到每行或每列的数组上
- 语法:
df.apply( f , axis= )
f : 自己定义的要应用到每一行(列)函数
axis:要应用的轴
import pandas as pd
a = pd.DataFrame(np.arange(9).reshape(3,3),columns=["a","b","c"],index=["A","B","C"])def f(x):return x.max()- x.min() #计算每行最大值和最小值的差print(a.apply(f))3.5 排序
| 方法 | 说明 |
|---|---|
| df.sort_index([ index = ,columns = , axis = ,ascending = ]) | 按 行/列 进行字典型排序 ascending:排序方式(默认True 升序) |
| df.sort_values([ by= ]) | 根据series的值进行排序 by:根据一列或多列(传入列表)作为排序键 |
| df.rank([ ascending= , method = ]) | 排名 method:排名方法 默认分配平均排名 |