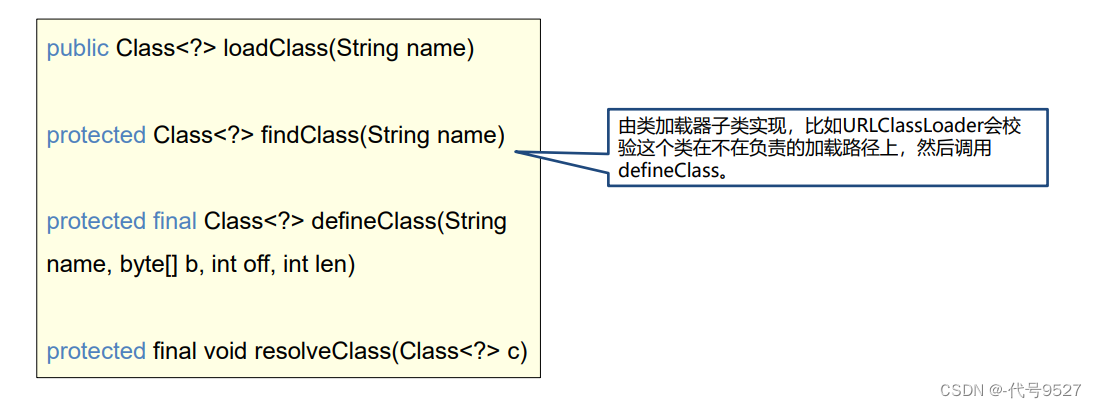
1.处理缺失值
1.1 数据删除函数
作用:删除Dataframe某行或某列的数据
语法:df.drop( labels = [ ] )
drop函数的几个参数:
labels =:接收一个列表,内含删除行 / 列的索引编号或索引名
axis =:删除的轴向 0代表删除行;1代表删除列
inplace =:是否改变原数组 默认False 即生成一个新数组
1.2 缺失值的查看
| 方法 | 描述 |
|---|---|
| df.isnull() | 返回一个布尔数组,是缺失值就显示True |
| df.notnull() | 返回一个布尔数组,是缺失值就显示False |
1.3 过滤缺失值
作用:删除缺失值所在的行 / 列
语法:df.dropna( axis=0, how='any', thresh=None, subset=None, inplace=False )
dropna函数的几个参数:
axis =:0代表删除包含缺失值的行;1代表删除包含缺失值的列
how=:“any”代表删除有缺失值的行 / 列 ; “all”代表删除所有值均缺失的行 / 列
thresh=:行 / 列中若达不到thresh个非缺失值,就删除
subset=:输入一个含索引名称的list,代表对这些列的空值进行删除
1.4 填充缺失值
作用:将缺失值补全为指定的值
语法:df.fillna(value, method=None, axis=None, inplace=False, limit=None)
fillna函数的几个参数:
value:填充的值,也可输入一个字典(用于为不同的列设置不同的填充值)
method:填充方法 “ffill”用前面的值填充 “bfill”用后面的值填充
axis:修改填充的轴
limt:最大填充数
2. 数据转换方法
2.1 删除和提取重复值
2.1.1 查看元素个数
- 语法:df [ 列名 ] . value_counts()
- 与count()函数的区别:前者是返回各个元素的个数,后者时返回该列中所有元素的总数
2.1.2 删除重复值
- 语法: df.drop_duplicates(subset=None, keep='first', inplace=False)
参数说明
subset:输入一个list,用来要操作的列,默认是所有列
keep:指定处理重复值的方法
“first” 指保留第一次出现的值 “last” 指保留最后一次出现的值
“False” 不保留重复值,全部删除
2.1.3 提取重复值
- 语法:df [ df.duplicated(subset=None, keep='first') ]
- 原理:相当于运用了索引切片的操作,中括号内的函数用来判断是否为重复值
2.2 数据替换
2.2.1 元素替换
- 语法:df.replace(被替换的元素,替换元素)
- 注意: 1)如果要一次替换多个不同的值,可以利用列表或者字典
- 2)如果想仅对某列替换,先利用df [ ] 切片即可
2.2.2 字符串替换
- 语法:df.str.replace(被替换的字符串,替换字符串)
- 区别:它是对字符串进行按元素替代的,可以对字符串切片后进行替换操作
例如:“山东省” 一> “山西省”,该方法就可直接替换“东” 一>“西”,这对于操作长数据非常方便
2.3 离散化和分箱
连续值经常需要离散化,或者分离成“箱子”进行处理。即:分组
2.3.1 指定分界点分箱
- 语法:pd.cut (x, bins, right=True, labels=None, precision=3, include_lowest=False)
参数说明:
x: 待切割的一维数组或列表对象
bins: 切割箱 若输入一个整数,则定义了x宽度范围内的等宽面元数量;
若输入一个序列,则代表分界点
right: 是否为左开右闭区间
labels: 自定义箱子名称 传入数组或列表(与箱子等长)
precision: 箱子精度 保留几位小数
include_lowest:第一个区间的左端点是否包含
2.3.2 等宽(频)分箱
- 作用:保证每个箱子的样本数一样
- 语法:pandas.qcut ( x, q, labels=None, precision=3 )
参数说明:
q:整数(分成几份) 或 分位数(0~1)组成的数组(分割点)
2.3.3 补充说明
1)以上两个函数会返回一个Categorical对象,会显示每个元素对应的箱名
2)对于返回的Categorical对象,可以结合数学统计函数去做数据统计
import pandas as pd
year = [1992,1985,1937,2005,2015,1999] #数据
box = [1930,1960,1990,2020] #箱子
box_name=["初期","中期","后期"] #定义箱子名result1 = pd.cut(year,box,labels=box_name) #按指定的箱分割,并指定箱名
print(result1)
print("-"*30)
print(result1.describe()) #做数据统计
print("-"*30)result2 = pd.qcut(year,3) #分成三段
print(result2)
2.4 其他数据转化操作
| 操作 | 方法 | 参数 |
|---|---|---|
| 实现one hot encode | get_dummies(data) | columns:需要转换的列 prefix:转换后列名的前缀 |
| 随机抽取子集 | df.sample(n=) | replace:取出后是否放回(默认不放回) n:抽取的样本数(列数目) |
| 重命名轴索引 | df.rename(index= , columns=) | 可以输入字典{ 旧索引名:新索引名 } |
- one hot encode(独热编码): 将离散型特征的每一种取值都看成一种状态

3.字符串操作
3.1 字符串常用方法


import pandas as pd
str = "a / b/ wow"
new = str.split("/")
print(new) # 按符号拆分字符串 ['a ', ' b', ' wow']piece = [x.strip() for x in new]
print(piece) # 与strip搭配使用 ,去除空格 ['a', 'b', 'wow']jia = "--".join(piece)
print(jia) # 将字符串用符号拼接起来 a--b--wowprint(jia.index("-")) # 返回“-”第一次出现的位置 13.2 正则表达式
正则表达式是一组由字母和符号组成的特殊文本,用于在文本中灵活的查找我们想要的格式的字符串,例如在一封邮件中提取所有的电话,在一篇文章中提取所有的地址
3.2.1 正则表达式的常用函数
要使用正则表达式函数,首先要导入re模块:import re
| 函数 | 描述 |
|---|---|
| re.compile() | 编译正则表达式,用其他函数再调用正则表达式,就不用重复编译了,提高效率 |
| re.spilt(“分隔符”,data) | 通过指定的分隔符将字符串拆分 |
| re.findall(正则表达式,data) | 匹配出字符串中所有符合正则表达式的值,并且以列表的形式返回 |
| re.sub(old,new) | 替换字符串 比replace好处:可以在 "[ ]" 内输入多个符号,同时被取代 |
| re.search(正则表达式,data) | 返回文本中第一个匹配项 |
| re.match(正则表达式,data) | 仅从字符串起始位置开始匹配,若满足要求则返回 |
3.2.2 正则表达式基础语法


- 贪婪与非贪婪
1)贪婪:'[a-zA-Z]{3,5}' 一> 要求找连续的3~5个字母
先找三个连续的字母,最多找到5个连续的字母后停止;在3个以后且5个以内发
现了不是字母的也停止。然后接着找下一个
2)非贪婪: '[a-zA-Z]{3}' 一> 找连续的3个字母,找到3个就停止,接着下一个
# 提取字符串a中所有的数字
import re
a = '孙悟空7猪八戒6沙和尚3唐僧6白龙马'
r = re.findall('[0-9]',a)
print(r) # 返回结果:['7', '6', '3', '6']# 找到字符串中间字母不是d或e的单词
a = 'xyz,xcz,xfz,xdz,xaz,xez'
r = re.findall('x[^de]z',a)
print(r) # 返回:['xyz', 'xcz', 'xfz', 'xaz'] # 提取特殊字符、空格、\n、\t等
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\W',a)
print(r)