0 引言
LoRA(Low-Rank Adaptation)出自2021年的论文“LoRA: Low-Rank Adaptation of Large Language Models” LoRA技术冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵),即在模型的Linear层的旁边增加一个“旁支”A和B。其中,A将数据从d维降到r维,这个r是LoRA的秩,是一个重要的超参数;B将数据从r维升到d维,B部分的参数初始为0。模型训练结束后,需要将A+B部分的参数与原大模型的参数合并在一起使用。

论文地址:https://arxiv.org/pdf/2106.09685.pdf
github链接:https://github.com/microsoft/LoRA
1 大模型微调的困境
随着模型规模的不断扩大,模型会"涌现"出各种能力。特别是对大语言模型(LLM)来说,随着规模的扩大其在zero-shot、常识推理等能力上会有大幅度的提高。相比于规模较小的模型,大模型的微调成本和部署成本都非常高。例如,GPT-3 175B模型微调需要1.2TB的显存。此外,若针对不同下游任务微调多个模型,那么就需要为每个下游任务保存一份模型权重,成本非常高。在某些场景下,甚至可能需要针对不同的用户微调不同的模型,那么模型微调和部署的成本将不可接受。因此,如何降低大模型微调和部署成本,将是大模型商用的重要一环。
2 LoRA之前的方法
在LoRA方法提出之前,也有很多方法尝试解决大模型微调困境的方法。其中有两个主要的方向:(1) 添加adapter层;(2) 由于某种形式的输入层激活,但是这两种方法都有局限性。
2.1 Adapter层会引入推理时延
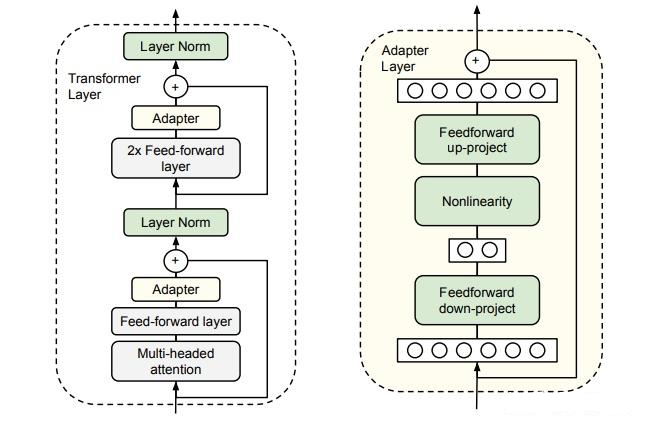
简单来说,adapter就是固定原有的参数,并添加一些额外参数用于微调。上图中会在原始的transformer block中添加2个adapter,一个在多头注意力后面,另一个这是FFN后面。
显然,adapter会在模型中添加额外的层,这些层会导致大模型在推理时需要更多的GPU通信,而且也会约束模型并行。这些问题都将导致模型推理变慢。
2.2 prefix-tuning难以优化

论文地址:https://aclanthology.org/2021.acl-long.353.pdf
prefix-tuning方法是受语言模型in-context learning能力的启发,只要有合适的上下文则语言模型可以很好的解决自然语言任务。但是,针对特定的任务找到离散token的前缀需要花费很长时间,prefix-tuning提出使用连续的virtual token embedding来替换离散token。
具体来说,对于transformer中的每一层,都在句子表征前面插入可训练的virtual token embedding。对于自回归模型(GPT系列),在句子前添加连续前缀,即。对于Encoder-Decoder模型(T5),则在Ecoder和Decoder前都添加连续前缀
。添加前缀的过程如上图所示。虽然,prefix-tuning并没有添加太多的额外参数。但是,prefix-tuning难以优化,且会减少下游任务的序列长度。
3 LoRA解析
3.1 重参数与本征维度
- 重参数
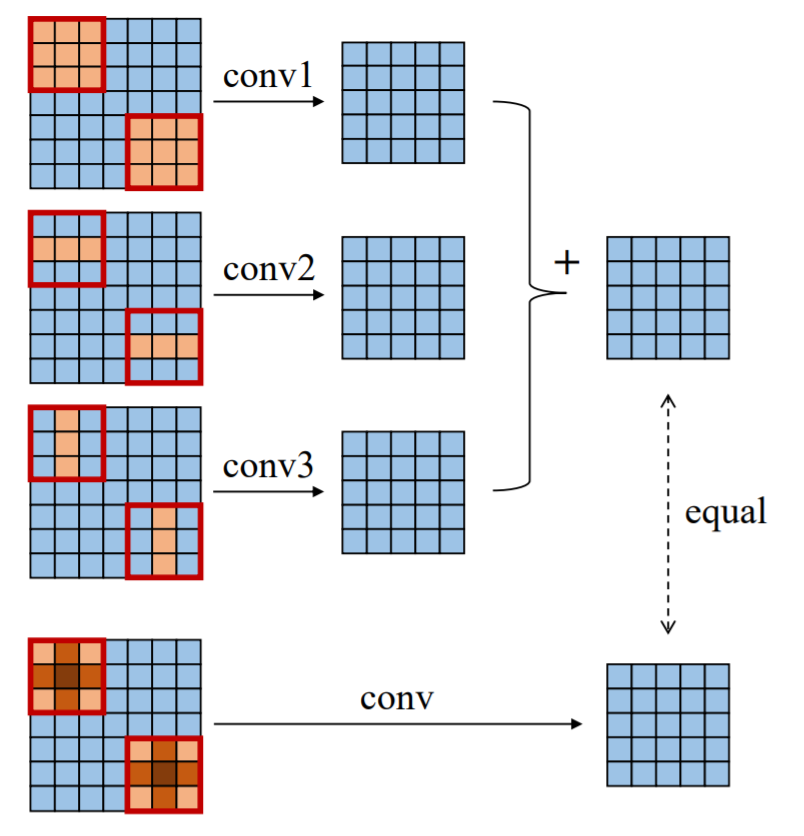
也就是结构重参数化,首先构造原始网络结构(一般使用带有预训练权重网络),将其权重参数等价转换为另一组参数(推理),从而将这一系列结构等价转换为另一系列结构。举个简单的例子,用卷积的方式去理解:
- 本征维度
通常是指一个数据集的有效维度数量,即可以用最少的维度来表达数据集的大部分信息。确定一个数据集的本征维度一般使用主成成分分析(PCA),独立成分分析(ICA),多维缩放(MDS)等。此处补充一些问题:
预训练的好坏与本征维度的关系:预训练模型的表征能力越强(训练得越好),本征维度越小。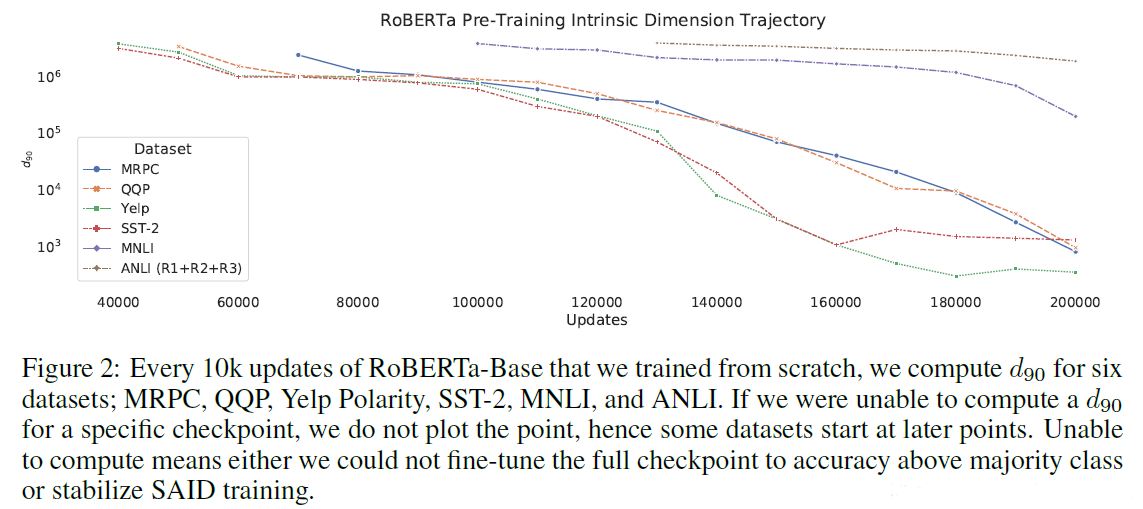
预训练模型参数与本征维度的关系:模型越大本征维度越小,即越强的模型本征维度越低。
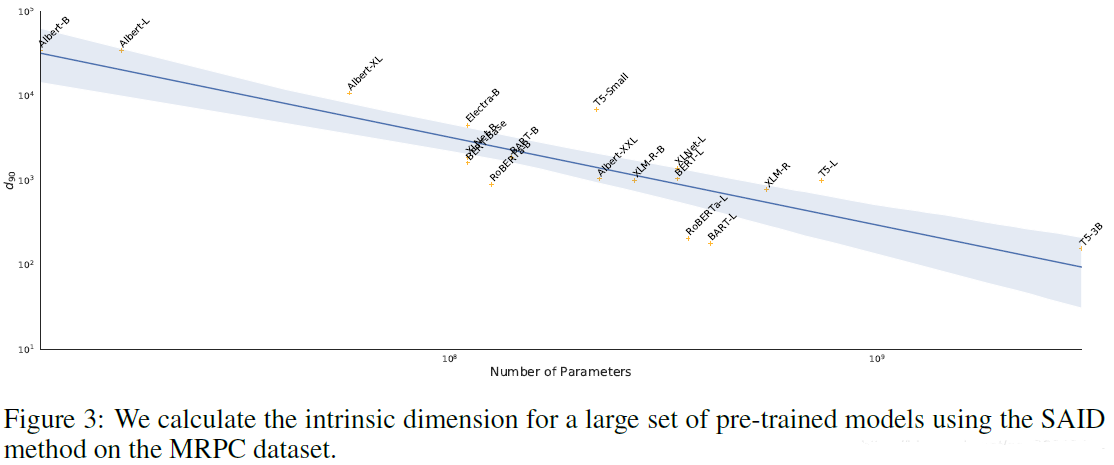
本征维度与泛化能力的关系:本征维度低的模型,训练出来的模型准确率是更高的。也就是说本征维度越低,泛化性能越好。
3.2 LoRA原理
首先给出微调的定义,即在尽量不改变推理速度的前提下,使用少量数据就能使预训练大模型达到原始推理精度的90%以上,来实现各种下游任务的应用。也就是说,在进行大量推理阶段时,网络结构是不允许被修改的,这就是重参数的重要性。
神经网络包含许多密集的层,这些层执行矩阵乘法。这些层中的权重矩阵通常具有全秩。当适应特定的任务时,预训练的语言模型往往具有较低的“instrisic dimension”,尽管随机投影到较小的子空间,但仍然可以有效地学习。
LoRA的实现原理在于,冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量。直白的来说,实际上是增加了右侧的“旁支”,也就是先用一个Linear层A,将数据从 d维降到r,再用第二个Linear层B,将数据从r变回d维。最后再将左右两部分的结果相加融合,得到输出的hidden_state。
如上图所示,左边是预训练模型的权重,输入输出维度都是d,在训练期间被冻结,不接受梯度更新。右边部分对A使用随机的高斯初始化,B在训练开始时为零,r是秩,会对△Wx做缩放 α/r。
LoRA的公式:
![]()
BA则是低秩分解,对应的图解:

- Lora 性质 1:全面微调的推广
通过将 LoRA 秩 r 设置为预训练的权重矩阵的秩,大致恢复了完整微调的表达性。换句话说,当增加可训练参数的数量时,训练LoRA大致收敛于训练原始模型。
- Lora 性质 2:没有额外的推断延迟
在生产中部署时,可以显式地计算和存储 W = W 0 + B A W = W_0 + BA W=W0+BA,并像往常一样执行推理,也就是将 LoRA 权重和原始模型权重合并,不增加任何的推断耗时 W 0 W_0 W0 和 B A BA BA 都是 R d × k R^{d×k} Rd×k。当需要切换到另一个下游任务时,可以通过减去 BA 然后添加不同的 B ′ A ′ B'A' B′A′ 来恢复 W 0 W_0 W0,这是一个内存开销很小的快速操作。
3.3 LoRA的优势
-
一个预先训练好的模型可以被共享,并用于为不同的任务建立许多小的LoRA模块。可以冻结共享模型,并通过替换图中的矩阵A和B来有效地切换任务,大大降低了存储需求和任务切换的难度。
-
在使用自适应优化器时,LoRA使训练更加有效,并将硬件进入门槛降低了3倍,因为我们不需要计算梯度或维护大多数参数的优化器状态。相反,我们只优化注入的、小得多的低秩矩阵。
-
简单的线性设计允许在部署时将可训练矩阵与冻结权重合并,与完全微调的模型相比,在结构上没有引入推理延迟。
-
LoRA与许多先前的方法是正交的,可以与许多方法结合,如前缀调整。
4 LoRA的使用
HuggingFace的PEFT(Parameter-Efficient Fine-Tuning)中提供了模型微调加速的方法,参数高效微调(PEFT)方法能够使预先训练好的语言模型(PLMs)有效地适应各种下游应用,而不需要对模型的所有参数进行微调。
对大规模的PLM进行微调往往成本过高,在这方面,PEFT方法只对少数(额外的)模型参数进行微调,基本思想在于仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本,这也克服了灾难性遗忘的问题,这是在 LLM 的全参数微调期间观察到的一种现象PEFT 方法也显示出在低数据状态下比微调更好,可以更好地泛化到域外场景。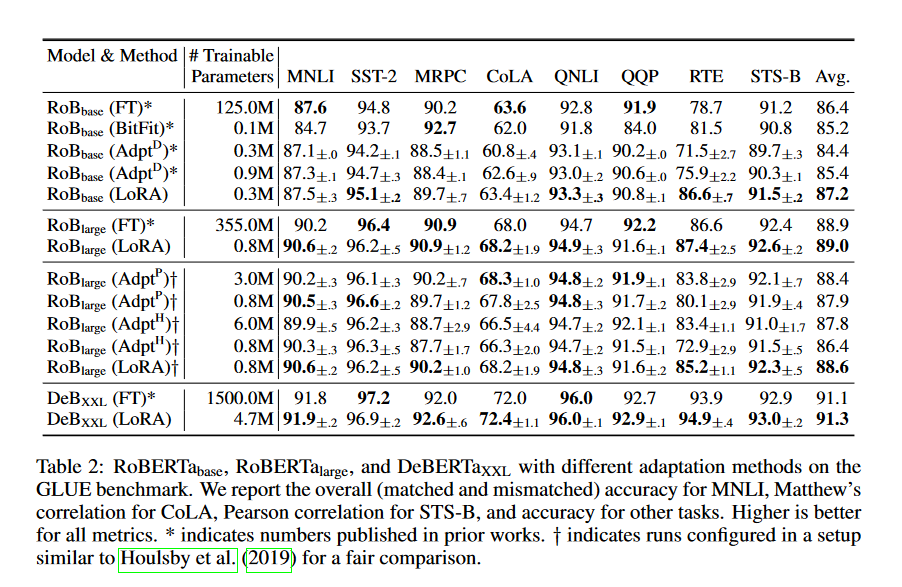
## 1、引入组件并设置参数
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, LoraConfig, TaskType
import torch
from datasets import load_dataset
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm## 2、搭建模型peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)## 3、加载数据
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]classes = dataset["train"].features["label"].names
dataset = dataset.map(lambda x: {"text_label": [classes[label] for label in x["label"]]},batched=True,num_proc=1,
)## 4、训练数据预处理
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)def preprocess_function(examples):inputs = examples[text_column]targets = examples[label_column]model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")labels = labels["input_ids"]labels[labels == tokenizer.pad_token_id] = -100model_inputs["labels"] = labelsreturn model_inputsprocessed_datasets = dataset.map(preprocess_function,batched=True,num_proc=1,remove_columns=dataset["train"].column_names,load_from_cache_file=False,desc="Running tokenizer on dataset",
)train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)## 5、设定优化器和正则项
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0,num_training_steps=(len(train_dataloader) * num_epochs),
)## 6、训练与评估model = model.to(device)for epoch in range(num_epochs):model.train()total_loss = 0for step, batch in enumerate(tqdm(train_dataloader)):batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.losstotal_loss += loss.detach().float()loss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()model.eval()eval_loss = 0eval_preds = []for step, batch in enumerate(tqdm(eval_dataloader)):batch = {k: v.to(device) for k, v in batch.items()}with torch.no_grad():outputs = model(**batch)loss = outputs.losseval_loss += loss.detach().float()eval_preds.extend(tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True))eval_epoch_loss = eval_loss / len(eval_dataloader)eval_ppl = torch.exp(eval_epoch_loss)train_epoch_loss = total_loss / len(train_dataloader)train_ppl = torch.exp(train_epoch_loss)print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")## 7、模型保存
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)## 8、模型推理预测from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)model = PeftModel.from_pretrained(model, peft_model_id)
model.eval()inputs = tokenizer(dataset["validation"][text_column][i], return_tensors="pt")
print(dataset["validation"][text_column][i])
print(inputs)
with torch.no_grad():outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)print(outputs)print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))5 LoRA的应用场景
在Transformer架构里Lora经常应用在self-attention模块和MLP模块中。在 Stable Diffusion模型里,Lora被用在condition和图像表示建立关联的Cross-Attention层。