安装DeepSpeed与集成
pip install deepspeedDeepSpeed与HuggingFace Transformers直接集成。使用者可以通过在模型训练命令中加入简单的 --deepspeed 标志和配置文件,来轻松加速模型训练。
编写DeepSpeed模型
DeepSpeed模型训练的核心是什么?它如何处理模型的初始化以及训练优化器、数据加载器和学习率调度器?对于分布式环境的设置,需要注意哪些细节?
DeepSpeed模型训练的核心在于DeepSpeed引擎,它能够包装任意类型为torch.nn.module的模型,并提供了一组最小的API用于训练和模型检查点。
在模型初始化方面,使用 `deepspeed.initialize()` 方法可以实现DeepSpeed引擎的初始化。此方法涵盖了训练优化器、数据加载器和学习率调度器的设置。具体来说:
模型初始化:
- 使用 `deepspeed.initialize()` 方法可以初始化DeepSpeed引擎。它接受参数并自动处理分布式数据并行或混合精度训练所需的所有设置。该方法包装模型并配置训练优化器、数据加载器和学习率调度器。

- 训练优化器、数据加载器和学习率调度器:
- DeepSpeed能够构建和管理训练优化器、数据加载器和学习率调度器,根据传递给 `deepspeed.initialize()` 方法和DeepSpeed配置文件中的参数进行设置。
- 深度学习引擎会根据传递给它的参数以及配置文件,自动执行学习率调度器中的学习率更新。 - 分布式环境的设置注意事项:
- 在分布式环境中,使用 `deepspeed.init_distributed()` 方法替换了通常的 `torch.distributed.init_process_group()` 方法来初始化分布式设置。如果已经有分布式环境设置,可以在 `deepspeed.initialize()` 之前调用,DeepSpeed在初始化时会自动处理分布式环境设置。
- 默认情况下,DeepSpeed使用NCCL后端进行分布式训练,但也可以覆盖默认设置。
需要注意的是,DeepSpeed引擎的关键在于简化了模型训练的流程,尤其是在分布式环境下。它通过`deepspeed.initialize()`方法集成了模型初始化、优化器设置、数据加载器和学习率调度器配置等步骤,使得用户能够更轻松地完成模型训练并且支持分布式环境下的加速训练。
训练过程
DeepSpeed引擎的训练过程包括哪些关键步骤?在训练过程中,DeepSpeed是如何处理分布式数据并行训练、混合精度等方面的细节?
DeepSpeed引擎的训练过程包括以下关键步骤:
- 初始化引擎:
使用 deepspeed.initialize 方法对引擎进行初始化。该方法包含参数设置、模型初始化和引擎构建,通过传递参数来指定分布式数据并行或混合精度训练等设置。 - 数据加载和分布式训练:
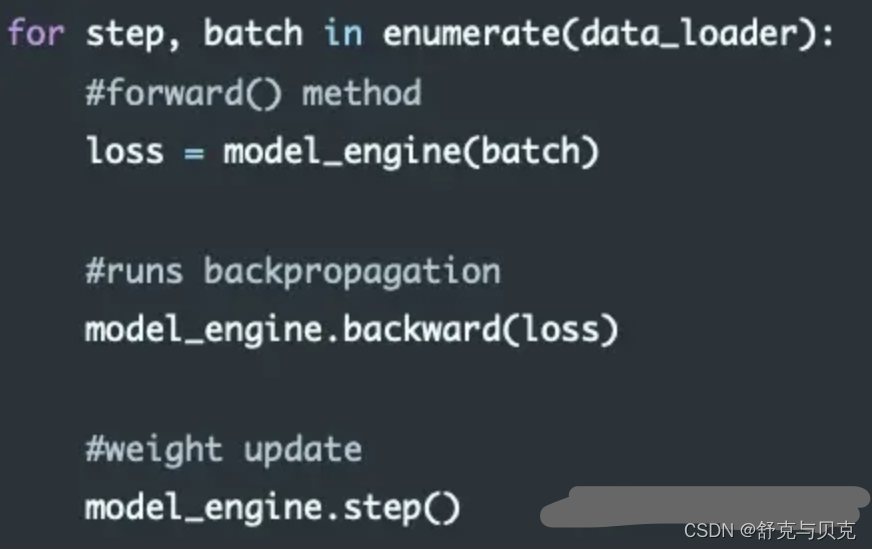
- 引擎利用数据加载器(data_loader)迭代训练数据。
- 在使用 model_engine(batch) 进行前向传播(forward)计算损失值时,DeepSpeed自动进行分布式数据并行训练,保证梯度在训练批次上进行平均。
3. 梯度反向传播和优化:
- 使用 model_engine.backward(loss) 进行梯度反向传播(backward),计算存储梯度。
- 接着使用 model_engine.step() 来执行权重更新,即优化器的步进操作。
在训练过程中,DeepSpeed处理以下方面的细节:
- 分布式数据并行训练:DeepSpeed引擎自动在多个设备或多个节点上执行数据并行训练,确保模型在各个设备上同步更新,实现分布式训练。
- 混合精度训练:在使用 FP16 或混合精度训练时,DeepSpeed会自动处理精度损失(precision loss)问题。它会自动调整损失值的缩放比例,以避免梯度计算过程中的精度损失。
- 学习率调度:当使用DeepSpeed的学习率调度器时,在训练过程中,DeepSpeed会在每个训练步骤中自动调用调度器的 step() 方法。这确保了学习率按照指定的调度规则进行更新。
模型检查占checkpoint
DeepSpeed如何处理模型的保存和加载?有哪些注意事项需要考虑?它是如何自动保存和恢复模型状态的?用户可以保存哪些额外数据?
DeepSpeed处理模型的保存和加载主要通过save_checkpoint和load_checkpoint两个API来完成。以下是一步一步的解释:

模型保存:
使用model_engine.save_checkpoint函数进行模型保存。此函数需要指定以下两个参数:
- ckpt_dir:指定模型检查点保存的目录。
- ckpt_id:作为检查点在目录中唯一标识的标识符。在示例代码中,使用了loss值作为检查点标识符。
保存额外数据:用户可以传递client_sd字典参数来保存特定于模型训练的额外数据。例如,在示例中将step值存储在client_sd中。
模型加载:
使用model_engine.load_checkpoint函数进行模型加载。此函数需要指定以下两个参数:
- load_dir:指定加载模型检查点的目录。
- ckpt_id:指定要加载的检查点标识符。
加载额外数据:load_checkpoint函数还返回两个值,通常被分配给_和client_sd。client_sd是存储在检查点中的客户端状态字典,其中包含了保存的额外数据。
- 自动保存和恢复模型状态:DeepSpeed通过save_checkpoint和load_checkpoint实现模型状态的自动保存和恢复。这些函数会隐藏模型、优化器和学习率调度器状态的细节,从而简化用户的操作。
注意事项:需要确保所有进程都调用save_checkpoint函数,而不仅仅是进程0的调用。这是因为每个进程都需要保存其主要权重以及调度器和优化器的状态。 - 额外保存的数据:用户可以通过client_sd参数保存任何与特定模型训练相关的数据。在示例中,将step值存储在client_sd字典中。这可以是任何用户认为对模型训练重要的信息。
DeepSpeed配置
使用配置JSON文件来启用、禁用或配置DeepSpeed的功能时,需要注意哪些核心参数?如何使用配置文件来定义训练批次大小、梯度累积步数、优化器类型和参数、FP16以及零优化等?
当使用配置JSON文件来启用、禁用或配置DeepSpeed功能时,需要注意一些核心参数。以下是关于定义训练批次大小、梯度累积步数、优化器类型和参数、FP16以及零优化等内容的指导:
- 训练批次大小 (train_batch_size):在配置文件中,可以通过指定一个整数值来设置训练批次的大小。这个值代表每个训练步骤中用于训练的样本数。
- 梯度累积步数 (gradient_accumulation_steps):通过设置这个参数,可以定义梯度累积的步数。这意味着在执行优化器步骤之前,模型将进行多少次前向传播和反向传播。这对于处理大批量训练数据而内存有限的情况很有用。
- 优化器类型和参数 (optimizer):在配置文件中,可以指定优化器的类型(如"Adam")并定义相应的参数,比如学习率 (lr)。这样可以配置模型训练中所使用的优化器及其超参数。
- FP16(半精度浮点数) (fp16):可以通过设置这个参数来启用或禁用FP16混合精度训练。将其设置为true表示启用FP16,以减少模型训练时的内存占用。
- 零优化 (zero_optimization):这个参数用于启用或禁用零优化技术,即在模型训练中将零梯度忽略以减少计算。将其设置为true表示启用零优化。
例如,在JSON配置文件中设置这些参数的示例:
{"train_batch_size": 16,"gradient_accumulation_steps": 4,"optimizer": {"type": "Adam","params": {"lr": 0.0004,"weight_decay": 0.01}},"fp16": {"enabled": true},"zero_optimization": true
}以上是配置JSON文件以定义训练批次大小、梯度累积步数、优化器类型和参数、FP16以及零优化的示例。根据实际需求,可以调整这些参数的值和设置,以便更好地配置DeepSpeed训练过程中的相关功能。
启动DeepSpeed训练
在启动分布式训练时,对于资源配置(多节点)和资源配置(单节点),有哪些不同的设置步骤?如何通过DeepSpeed的启动脚本来控制使用的节点和GPU数量?
在启动分布式训练时,资源配置(多节点)和资源配置(单节点)有一些不同的设置步骤。通过DeepSpeed的启动脚本来控制使用的节点和GPU数量涉及以下步骤:
单机单卡多卡
在单节点运行时,DeepSpeed无需使用主机文件。它将根据本地机器上的GPU数量自动发现可用的插槽数量。
仅在单节点运行DeepSpeed时,需要注意以下几点不同的配置和使用情况:
- 不需要指定hostfile:
在单节点运行时,不需要使用hostfile来指定计算资源。DeepSpeed会自动检测本地机器上的GPU数量,并使用这些GPU进行训练。 - --include和--exclude参数的使用:
虽然在单节点情况下不需要hostfile,但仍可以使用--include和--exclude参数来指定使用的GPU资源。此时应将主机名指定为'localhost',例如:deepspeed --include localhost:1 ...
CUDA_VISIBLE_DEVICES与DeepSpeed的异同
异同点:
- CUDA_VISIBLE_DEVICES是环境变量,用于指定哪些GPU设备可以被程序看到和使用。它可以限制程序在单节点内使用的GPU设备。
- DeepSpeed提供了--include和--exclude参数,用于在启动时指定要使用的GPU资源,类似于CUDA_VISIBLE_DEVICES的功能,但更加灵活且可以在命令行中指定不同的节点和GPU。
相同点:
- 两者都可以用于限制DeepSpeed或其他深度学习框架在单节点上使用的GPU设备。
在单节点情况下,DeepSpeed的配置更多地集中在指定的节点内,因此不需要显式指定hostfile,而可以通过命令行参数更灵活地控制使用的GPU资源。相比之下,CUDA_VISIBLE_DEVICES是一个环境变量,需要在运行程序之前设置,控制整个进程可见的GPU设备。
deepspeed train.py --deepspeed_config xxx.json
多机多卡
准备主机文件(hostfile): 创建一个主机文件(hostfile),其中列出了可访问且支持无密码SSH访问的机器名称或SSH别名,以及每台机器上可用于训练的GPU数量。
例如:

启动多节点训练作业: 使用DeepSpeed启动脚本和相应的命令行选项,在命令行中指定hostfile,DeepSpeed将根据hostfile配置在所有可用节点和GPU上启动训练作业。
示例命令:
deepspeed --hostfile=myhostfile <client_entry.py> <client args> --deepspeed_config ds_config.json控制节点和GPU数量: 可以通过DeepSpeed启动脚本的命令行选项来控制分布式训练作业使用的节点和GPU数量。
使用 --num_nodes 和 --num_gpus 参数限制训练作业使用的节点数和GPU数。例如,--num_nodes=2 限制使用两个节点进行训练。
使用 --include 和 --exclude 参数选择性地包含或排除特定资源。例如,--exclude="worker-2:0@worker-3:0,1" 表示排除worker-2上的GPU 0和worker-3上的GPU 0和1。
在这些设置步骤中,DeepSpeed的启动脚本提供了多种命令行选项,使用户能够根据需求有效地控制分布式训练作业在多节点或单节点上使用的节点和GPU数量。
关于NCCL(NVIDIA Collective Communications Library)参数的使用说明
在多节点环境中,DeepSpeed是如何处理用户定义的环境变量传播的?与MPI相关的配置,如何结合DeepSpeed启动多节点训练作业?
环境变量传播方式:
DeepSpeed默认情况下会传播设置的NCCL和PYTHON相关环境变量。
这些变量包括NCCL_IB_DISABLE和NCCL_SOCKET_IFNAME等。
| 参数 | 意义 | 说明 |
|---|---|---|
| NCCL_IB_DISABLE | 禁用IB网卡传输端口 | IB (InfiniBand)是一种用于高性能计算的计算机网络通信标准。 |
| NCCL_SHM_DISABLE | 禁用共享内存传输 | 共享内存(SHM)传输支持运行在相同处理单元/机器中的实体之间的快速通信,这依赖于主机操作系统提供的共享内存机制 |
| NCCL_P2P_DISABLE | 禁用GPU之间信息的传输 | P2P使用CUDA和NVLink直接实现GPU之间的传输与访问 |
关于如何查看GPU是否支持 NVLINK
使用命令
nvidia-smi topo -p2p n具体操作步骤:
若用户需要传播其他环境变量,可以在名为.deepspeed_env的点文件中指定,该文件包含以新行分隔的VAR=VAL条目。这些环境变量定义可以放置在执行命令的当前路径下或用户的主目录(~/)中。若用户想要使用不同的文件名或自定义路径和文件名,可以通过环境变量DS_ENV_FILE来指定。
用户可以在自己的主目录中创建名为.deepspeed_env的文件,并在其中添加需要传播的特定环境变量定义,例如:
NCCL_IB_DISABLE=1
NCCL_SOCKET_IFNAME=eth0DeepSpeed启动器会在执行时检查当前路径和用户主目录中是否存在这个文件,然后根据其中的定义传播这些环境变量到每个节点的每个进程。
至于与MPI相关的配置,DeepSpeed提供了兼容MPI的能力,并且可以通过MPI来启动多节点训练作业。但需要注意的是,DeepSpeed仍然会使用torch分布式的NCCL后端,而不是MPI后端。
在使用MPI来启动多节点训练作业时,用户只需要安装mpi4py Python包。DeepSpeed会利用mpi4py发现MPI环境,并将必要的状态(例如,world size、rank等)传递给torch分布式后端。
在需要使用模型并行、管道并行或在调用deepspeed.initialize(...)之前需要torch分布式调用的情况下,用户可以使用以下DeepSpeed的API调用代替初始的torch.distributed.init_process_group(...):
deepspeed.init_distributed()
这样,用户就能够结合MPI和DeepSpeed,在多节点环境下启动训练作业。
deepspeed-train入门教程 - 知乎 (zhihu.com)
关于Deepspeed的一些总结与心得 - 知乎 (zhihu.com)