这是Python特征工程系列原创文章,我的第186篇原创文章。
一、问题
应用背景介绍:
如果有一个包含数十个甚至数百个特征的数据集,每个特征都可能对你的机器学习模型的性能有所贡献。但是并不是所有的特征都是一样的。有些可能是冗余的或不相关的,这会增加建模的复杂性并可能导致过拟合。特征重要性分析可以识别并关注最具信息量的特征,从而带来以下几个优势:
-
-
改进模型性能
-
能减少过度拟合
-
更快训练和推理
-
增强可解释性
-
前期相关回顾:
【Python特征工程系列】利用梯度提升(GradientBoosting)模型分析特征重要性(源码)
【Python特征工程系列】8步教你用决策树模型分析特征重要性(源码)
【Python特征工程系列】利用随机森林模型分析特征重要性(源码)
本期相关知识:
XGBoost(eXtreme Gradient Boosting)极致梯度提升,是一种基于GBDT的算法或者说工程实现。XGBoost通过集成多个决策树模型来进行预测,并通过梯度提升算法不断优化模型的性能。XGBoost的基本思想和GBDT相同,但是做了一些优化,比如二阶导数使损失函数更精准;正则项避免树过拟合;Block存储可以并行计算等。XGBoost可以计算每个特征的重要性得分,帮助我们理解哪些特征对模型预测的贡献最大。
二、实现过程
导入第三方库
import pandas as pd
from sklearn.model_selection import train_test_split
import xgboost as xgb
import matplotlib.pyplot as plt
import seaborn as sns2.1 准备数据
data = pd.read_csv(r'dataset.csv')
df = pd.DataFrame(data)
2.2 目标变量和特征变量
target = 'target'
features = df.columns.drop(target)特征变量如下:

2.3 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)X_train如下:
2.4 训练模型
model = xgb.XGBRegressor(n_estimators=100, max_depth=10)
model.fit(X_train, y_train)2.5 提取特征重要性
feature_importance = model.feature_importances_
feature_names = featuresfeature_importance如下:

2.6 创建特征重要性的dataframe
importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importance})importance_df如下:
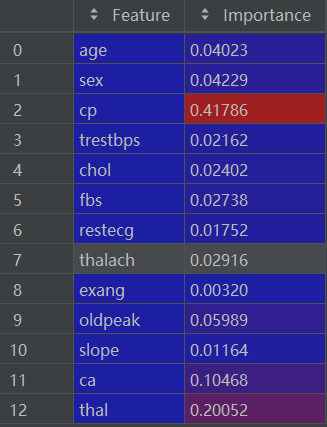
2.7 对特征重要性进行排序
importance_df = importance_df.sort_values(by='Importance', ascending=False)排序后的 importance_df如下:
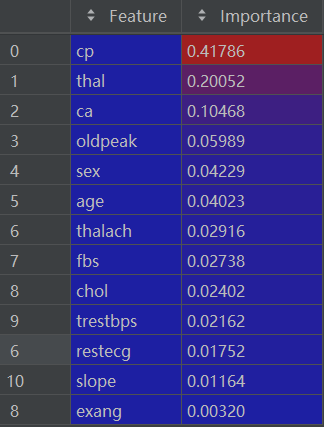
2.8 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show()可视化结果如下:
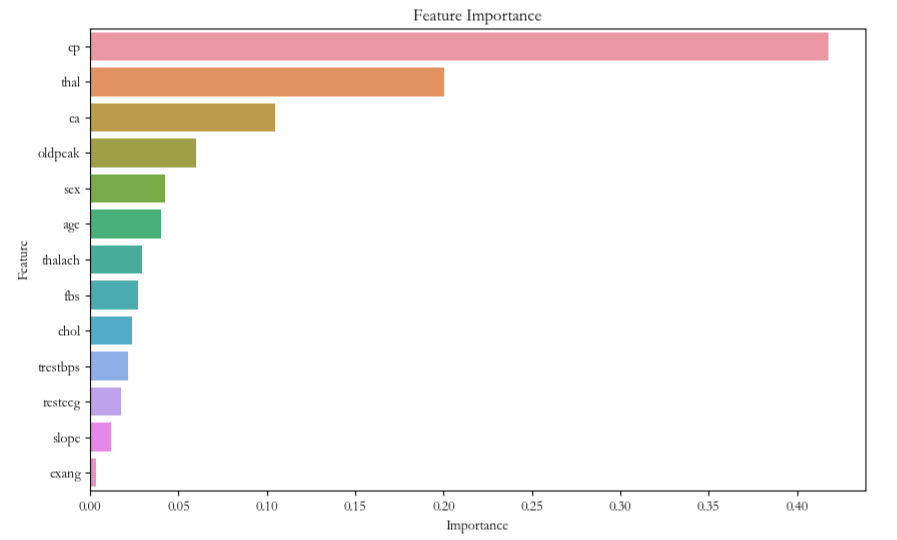
本期内容就到这里,我们下期再见!需要数据集和源码的小伙伴可以关注底部公众号添加作者微信!
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。