大家好,我是豆小匠。
关于数据库,大学的时候只知道MySQL,学习深入点也就是用到了Redis、MongoDB等非关系型数据库。
然而,工作中用到的数据库实在太多,每种数据库都有自身的优势和局限性。所以在这里梳理下日常常用数据库和适用场景,走起!
1. 常用数据库
1.1. 关系型数据库
关系型数据库通常是业务型项目的主力数据库,原因以下:
- 方便业务建模,表的关系和业务之间的关联是类似的。
- 数据一致性,关系型数据库一般支持ACID特性,可用于核心业务场景的数据持久化。
关系型数据库的基本单位是表,表与表之间通过键关联,比如学生表和班级表,可以通过班级ID,把学生和班级关联起来。
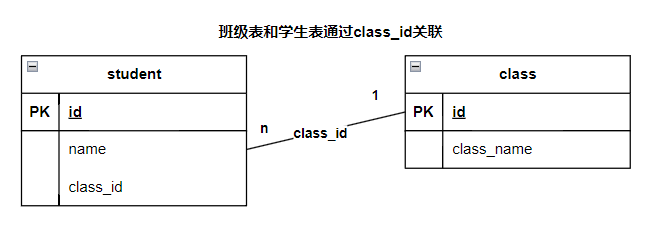
关系型数据库的经典代表:MySQL、Orcle、PostgreSQL、SQLite等。
1.2. 非关系型数据库
非关系型数据库其实只是一个比较笼统的叫法,实际分类下有非常多,这里只介绍键值对、文档、列式存储、图形结构等几种。
1.2.1. KV数据库
KV数据库以键值对的形式存储数据,常见底层数据结构实现是哈希表,读数据复杂度是O(1)。
| key | value |
|---|---|
| bean | good |
| milk | bad |
key-value存储的数据通常单个key-value就是一个条独立的数据,很方便水平扩展,可以根据key散列到不同的分片,且读的性能极好,因此常用于做缓存。
经典的代表有Redis、Memcached和LevelDB等。
1.2.2. 文档型数据库
文档型数据库的数据以文档的形式存储数据,每个文档类似一个JSON对象。
相比于KV存储,文档型数据库同样对水平扩展友好,且具有更好的查询性能,支持复杂查询,而KV存储几乎只通过key来读取数据。
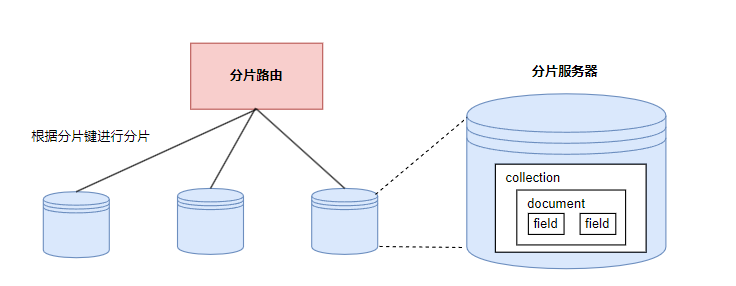
经典的文档型数据库有MongoDB,CouchDB和Elasticsearch等。
1.2.3. 列式存储数据库
经典的列式存储数据库有HBase、Druid、ClickHouse等,不同列式数据库的底层实现差别挺大的,它们的共同点是按列存储。
比如说MySQL存一个学生信息,有学号和姓名等,这两个字段在同一行,存放也是在一起的;但是列式数据库会按列划分存储,把学号和姓名分开存储,相同的数据类型有利于进行数据压缩、聚合操作等。
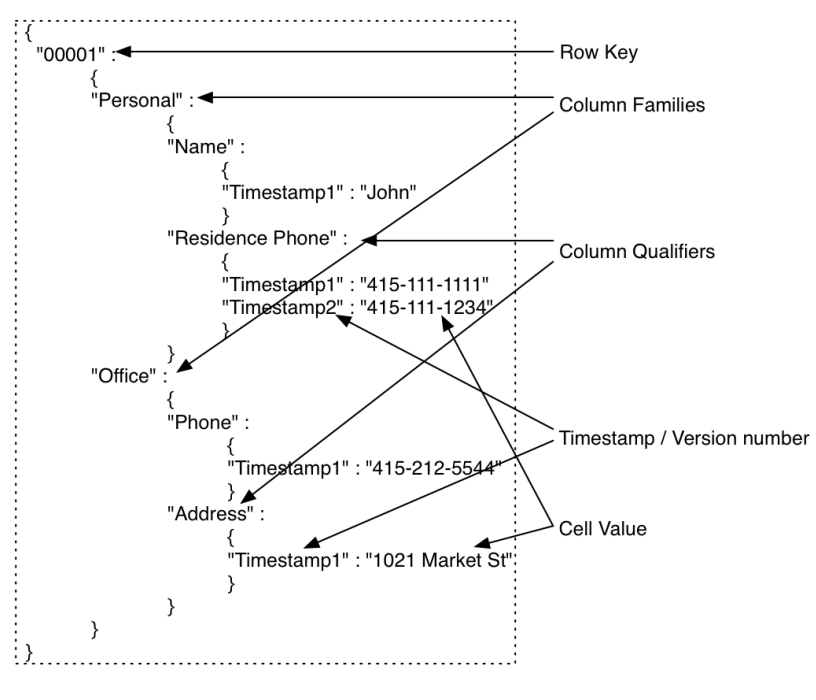
下面是HBase的一条数据组成解析,一个Row Key(行键)下有多个Column Family(列族),列族下面有Column Qualifier(列限定符),最后会根据设置保存若干个版本,形成Timestamp/version: Cell Value的键值对。这里我们只需要知道不同的列族是分开存储的就行了。
1.2.4. 图数据库
图数据库的基本单元是点和边,经典的图数据库包括Neo4j、OrientDB、TigerGraph等。
简单来说点表示实体,而边则表示实体间的关系,组成一个整体后,可以形成知识图谱、社交网络、金融风控网络等。
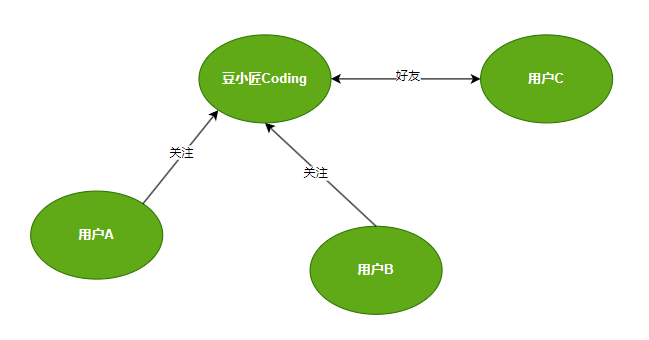
比如存储了上图关系,可以直接查询关注了豆小匠Coding的用户:
MATCH (user:User {name: '豆小匠Coding'})<-[:FOLLOWS]-(follower:User)
RETURN follower.name
上述查询使用了 Neo4j 的图查询语言 Cypher。它首先通过 MATCH 子句找到名为豆小匠的用户节点 user,然后通过 -[:FOLLOWS]-> 关系查找所有关注了该用户的节点 follower。最后,通过 RETURN 子句返回关注者的姓名。
2. 场景下的数据库
2.1. Demo项目
SQLite,一个轻量级的数据库,不需要独立服务器或者系统级别的配置,只需要一个文件,就可以存储数据库所有数据,适用于小型设备或者嵌入式系统等。
如果你只是做一个demo级别的项目,也可以使用SQLite,然后使用ORM框架来操作数据,后面切换MySQL也只需要修改数据库连接逻辑。
2.2. MySQL遇到瓶颈
如果是单机MySQL遭遇性能瓶颈,可以通过主从架构读写分离,堆机器的方式解决,另一个方向是增加缓存,如Redis等,减少打到物理存储的请求量。
如果是数据量太大,单表查询性能下降,可以考虑分库分表,但是分库分表在开发时需要考虑更多分布式事务、水平扩展等因素,对研发效率有影响。因此,这个时候可以考虑使用分布式数据库,如TiDB等。
2.3. 场景专用数据库
随着业务的复杂,我们会发现不同场景下对数据库的要求差异会很大:
- 一致性优先,选用关系型数据库。
- 高性能全文搜索,使用Elasticsearch。
- 非关键数据,读多写少,量大,选用列式存储。
- 离线数据分析,Hive。
这期就喵到这!能读到这里的朋友,点个赞呗!