温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
本文介绍了一项基于Python的B站排行榜大数据分析与可视化系统的研究。通过网络爬虫技术,系统能够自动分析B站网址,提取大量相关文本信息并存储在系统中。通过对这些信息进行统计分析,系统实现了B站排行榜热度的整体分析,热门版块的词云分析以及不同版块热度的详细分析。通过可视化的方式,用户可以清晰直观地了解B站各个排行榜的动态和热度趋势。本系统不仅提供了对B站内容的全面分析,还为用户提供了一种方便、直观的方式来探索和了解B站平台上的热门内容和趋势。
2. 排行榜数据网络爬虫
利用Python网络爬虫,采集排行榜数据:
# 爬取所有类别的排行榜数据
for cate in rank_urls:print('抓取{}栏目的排名TOP100的作品'.format(cate))rank_url = rank_urls[cate]resp = requests.get(rank_url, headers=headers)resp.encoding = 'utf8'soup = BeautifulSoup(resp.text, 'lxml')rank_list = soup.find(name='ul', attrs={'class': 'rank-list'})lis = rank_list.find_all(name='li')for li in lis:rank = li['data-rank']# ..........# titletitle = li.find('a', attrs={'class': 'title'})title = title.text.strip()detail = li.find('div', attrs={'class': 'detail-state'})spans = detail.find_all('span', attrs={'class': 'data-box'})# 播放次数play_count = spans[0].text.strip()# 点赞次数like_count = spans[1].text.strip()# 数据清洗,亿为单位的,统一为"万"为单位# ..........item_info = {'cate': cate,'rank': rank,'title': title,'play_count': play_count,'like_count': like_count}print(json.dumps(item_info, ensure_ascii=False))all_item_info.append(item_info)# 数据存储
# ..........
3. B站排行榜大数据分析与可视化系统
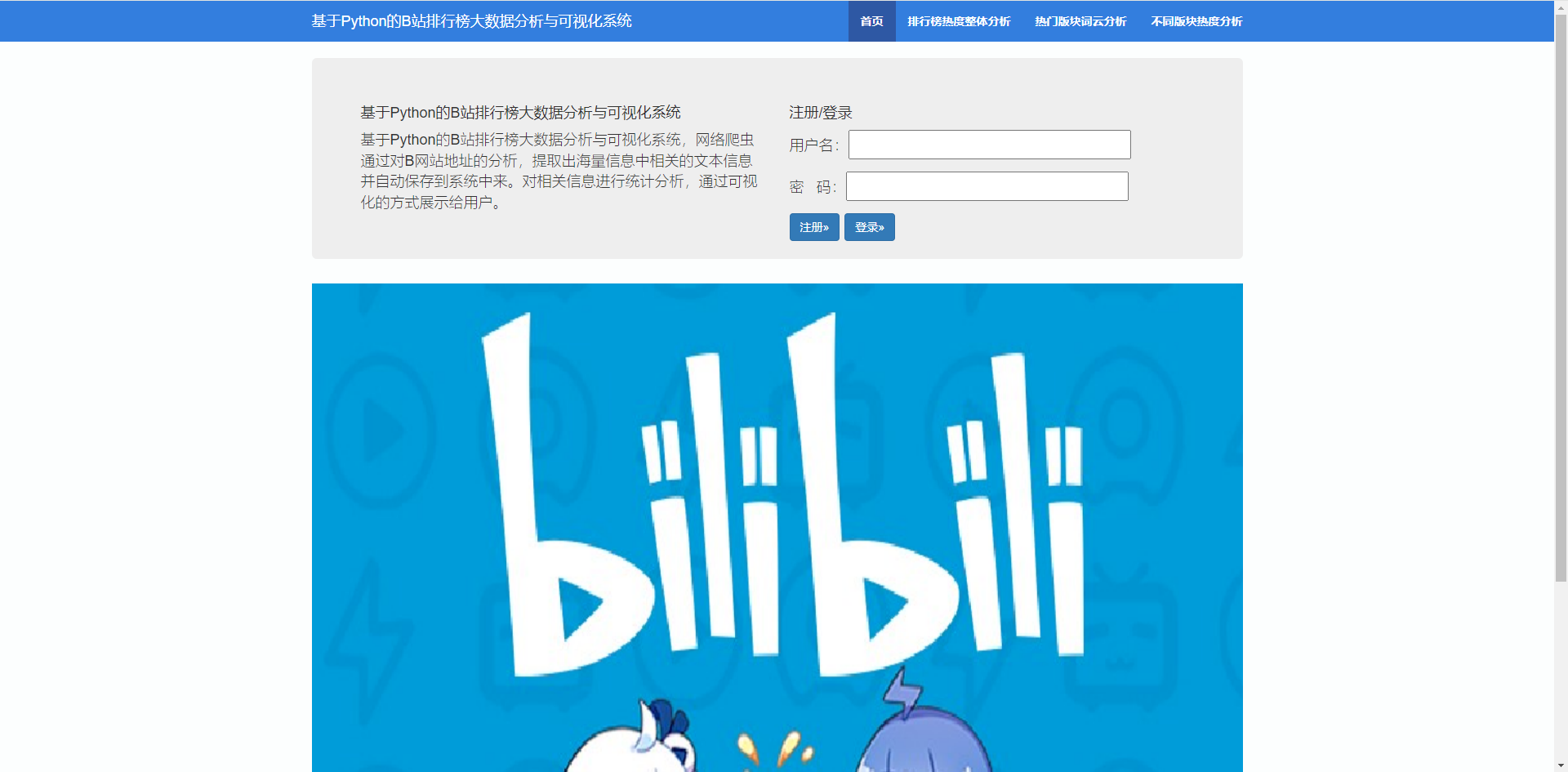
3.1 首页与注册登陆
3.2 排行榜热度整体分析
3.2.1 不同版块播放热度分布情况

3.2.2 不同版块点赞热度分布情况

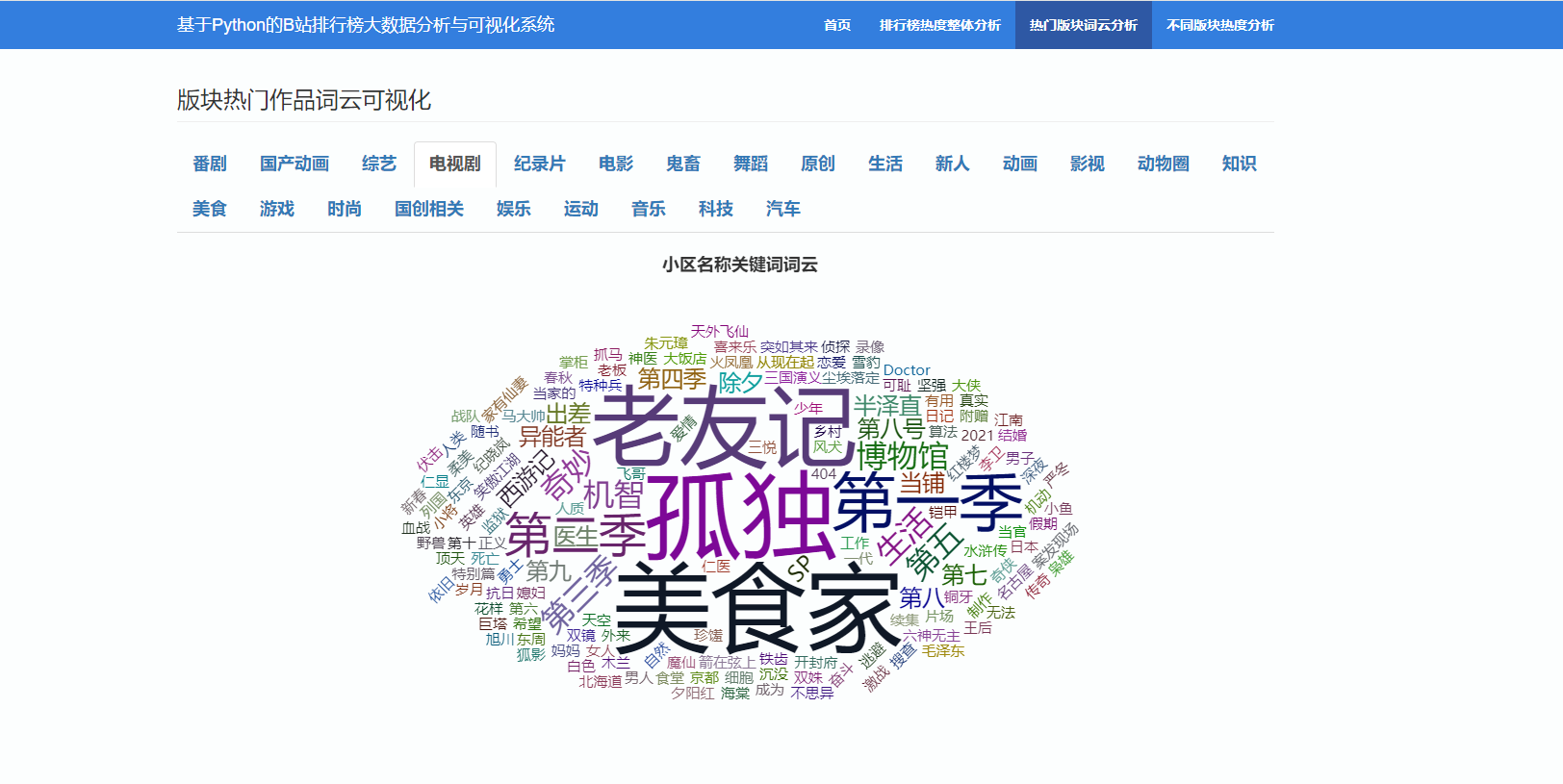
3.3 版块热门作品词云可视化
3.5 版块热门作品播放次数与点赞次数

4. 总结
基于Python的B站排行榜大数据分析与可视化系统通过网络爬虫技术,自动采集B站网址热门排行榜,提取大量相关文本信息并存储在系统中。通过对这些信息进行统计分析,系统实现了B站排行榜热度的整体分析,热门版块的词云分析以及不同版块热度的详细分析。通过可视化的方式,用户可以清晰直观地了解B站各个排行榜的动态和热度趋势。本系统不仅提供了对B站内容的全面分析,还为用户提供了一种方便、直观的方式来探索和了解B站平台上的热门内容和趋势。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
1. Python 毕设精品实战案例
2. 自然语言处理 NLP 精品实战案例
3. 计算机视觉 CV 精品实战案例






![[设计模式 Go实现] 创建型~工厂方法模式](https://img-blog.csdnimg.cn/direct/b81d57e2bf1c442ca08246d226216e50.png)