目录
- 第1关:实现朴素的字符串匹配
- 任务描述
- 相关知识
- 编程要求
- 评测说明
- 完整代码
- 第2关:实现KMP字符串匹配
- 任务描述
- 相关知识
- 编程要求
- 评测说明
- 完整代码
- 第3关:【模板】KMP算法
- 任务描述
- 相关知识
- C++ STL容器string
- 1、string的定义
- 2、string中内容的访问
- 3、string常用函数实例解析
- 4、C语言中将字符串转换为数值的函数
- 5、C++11中将string转换为数值类型
- 6.不同编译器打开-std=c++11编译开关的方法:
- 编程要求:
- 完整代码
- 第4关:利用kmp算法求子串在主串中不重叠出现的次数
- 任务描述
- 编程要求
- 完整代码
- 第5关:利用KMP算法求子串在主串中重叠出现的次数
- 任务描述
- 编程要求
- 完整代码
第1关:实现朴素的字符串匹配
任务描述
本关任务是实现函数int FindSubStr(char* t, char* p)。
相关知识
在一个长字符串中寻找一个短字符串出现的位置,这是字符串匹配问题。
例如:长字符串是 “string” ,短字符串是 “ring” ,那么短字符串在长字符串中出现的位置是 2 ,即 “ring” 在 “string” 中出现的开始位置是 2 。
编程要求
本关的编程任务是补全 step1/mystr.cpp 文件中的FindSubStr函数,以实现朴素的字符串匹配。
具体请参见后续测试样例。
本关涉及的代码文件 mystr.cpp 的代码框架如下:
int FindSubStr(char* t, char* p)
/*
从字符串t查找子字符串p。
字符串以数值结尾,例如p="str",那么p[0]='s',p[1]='t',p[2]='r',p[3]=0。
采用朴素的匹配算法,返回子字符串第一次出现的位置,例如t="string ring",p="ring",则返回2。
若没有找到,则返回-1。
*/
{// 请在此添加代码,补全函数FindSubStr/********** Begin *********//********** End **********/
}
评测说明
本关的测试文件是 step1/Main.cpp ,测试过程如下:
平台编译 step1/Main.cpp ,然后链接相关程序库并生成 exe 可执行文件;
平台运行该 exe 可执行文件,并以标准输入方式提供测试输入;
平台获取该 exe 可执行文件的输出,然后将其与预期输出对比,如果一致则测试通过;否则测试失败。
以下是平台对 step1/Main.cpp 的样例测试集:
样例输入:
string
tri
样例输出:
Location: 1
开始你的任务吧,祝你成功!
完整代码
/*************************************************************date: April 2009copyright: Zhu EnDO NOT distribute this code.
**************************************************************/int FindSubStr(char* t, char* p)
/*
从字符串t查找子字符串p。
字符串以数值结尾,例如p="str",那么p[0]='s',p[1]='t',p[2]='r',p[3]=0。
采用朴素的匹配算法。
返回子字符串第一次出现的位置,例如t="string ring",p="ring",则返回2。
若没有找到,则返回-1。
*/
{// 请在此添加代码,补全函数FindSubStr/********** Begin *********/int cnt=0;char* tr; while(*t!='\0' && *p!='\0'){if(*t!=*p){t++;cnt++;}else{tr=t;t++;p++;while(*p!='\0'){if(*t==*p){t++;p++;}}if(*p=='\0'){return cnt;}else{t = tr;p = &p[0];}}}if(*t=='\0'){return -1;}/********** End **********/
}
第2关:实现KMP字符串匹配
任务描述
本关的编程任务是补全 step2/kmp.cpp 文件中的KmpGenNext函数,以实现 KMP 字符串匹配。该函数生成给定字符串的next数组。
相关知识
第 1 关中实现的朴素的字符串匹配算法在实际应用系统中效率低,而 KMP 字符串匹配算法可以实现高效的匹配。
假设长字符串为t,短字符串为p。为了进行 KMP 匹配,首先需要计算字符串p的next数组,后面实现了计算该数组的函数void KmpGenNext(char* p, int* next)。对于 “abcabcab” ,计算出的next数组如下图:
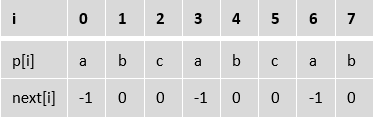
其中:next[i]给出如下信息:从左到右将p的字符与t的字符进行比对时,若在p的i号位置出现不匹配,就将字符串p相对t右移i-next[i]位;若next[i]>=0,则右移后比对位置从next[i]号位置开始,否则从0号位置开始。下图 1 给出了一个匹配示例:
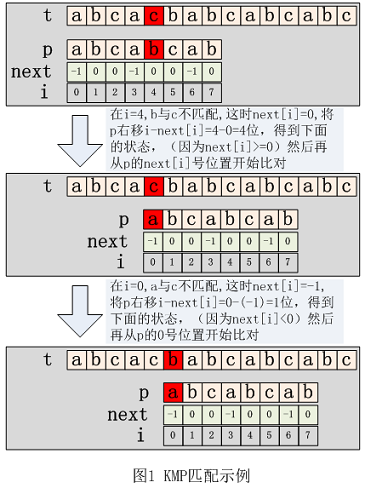
本关涉及两个函数:
void KmpGenNext(char* p, int* next)
// 生成p的next数组, next数组长度大于等于字符串p的长度加1。
int KmpFindSubWithNext(char* t, char* p, int* next)
// 从t中查找子串p的第一次出现的位置。
// 若找到,返回出现的位置,否则返回-1。
编程要求
本关的编程任务是补全 step2/kmp.cpp 文件中的KmpGenNext函数,以实现 KMP 字符串匹配。该函数生成给定字符串的next数组,生成算法请你查阅相关资料。
具体请参见后续测试样例。
本关涉及的代码文件 kmp.cpp 的代码框架如下:
#include <stdio.h>
#include <stdlib.h>
#include "kmp.h"
///
void KmpGenNext(char* p, int* next)
// 生成p的next数组, next数组长度大于等于字符串p的长度加1
{// 请在此添加代码,补全函数KmpGenNext/********** Begin *********//********** End **********/
}
int KmpFindSubWithNext(char* t, char* p, int* next)
// 从t中查找子串p的第一次出现的位置
// 若找到,返回出现的位置,否则返回-1
{int i=0, j=0;while(p[i]!=0 && t[j]!=0) {if(p[i]==t[j]) { i++; j++; }else if (next[i]>=0) {i = next[i];}else { i=0; j++; }}if(p[i]==0) return j-i; //foundelse return -1; //not found
}
评测说明
本关的测试文件是 step2/Main.cpp ,测试过程如下:
平台编译 step2/Main.cpp ,然后链接相关程序库并生成 exe 可执行文件;
平台运行该 exe 可执行文件,并以标准输入方式提供测试输入;
平台获取该 exe 可执行文件的输出,然后将其与预期输出对比,如果一致则测试通过;否则测试失败。
输入输出格式:
输入格式:
第一行输入母串
第二行输入子串
输出格式:
输出Location: #,其中#是子串在母串中的位置编号
以下是平台对 step2/Main.cpp 的样例测试集:
样例输入:
stringabcedf1stringabcdef2stringabcdef3stringabcdef4stringabcdef5stringabcdef6stringabcdef7
stringabcdef7
样例输出:
Location: 78
开始你的任务吧,祝你成功!
完整代码
/*************************************************************date: copyright: Zhu EnDO NOT distribute this code without my permission.
**************************************************************/
//字符串 实现文件
//
#include <stdio.h>
#include <stdlib.h>
#include "kmp.h"
#include<string.h>
/void KmpGenNext(char* p, int* next)
//生成p的next数组, next数组长度大于等于字符串p的长度加1
{// 请在此添加代码,补全函数KmpGenNext/********** Begin *********/int j,k; // j遍历t, k求t[j]前与开头相同的字符个数k = -1;j = 0;next[0] = -1;while(j<strlen(p)-1){ if(k==-1 || p[j]==p[k]){j++;k++;next[j] = k;}else{k=next[k];}}/********** End *********/
}int KmpFindSubWithNext(char* t, char* p, int* next)
//从t中查找子串p的第一次出现的位置
//若找到,返回出现的位置,否则返回-1
{int i=0, j=0;while(p[i]!=0 && t[j]!=0) {if(p[i]==t[j]) { i++; j++; }else if (next[i]>=0) {i = next[i];}else { i=0; j++; }}if(p[i]==0) return j-i; //foundelse return -1; //not found
}
第3关:【模板】KMP算法
任务描述
本关任务: 给出两个字符串text和pattern,其中pattern为text的子串,求出pattern在text中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
相关知识
为了完成本关任务,你需要了解:C++ STL中字符串容器string的使用。
C++ STL容器string
在C语言中,一般使用字符数组char str[]来存放字符串,但是使用字符数组有时会显得操作麻烦,而且容易因经验不足而产生一些错误。为了使编程者可以更方便地对字符串进行操作,C++在STL中加入了 string类型,对字符串常用的需求功能进行了封装,使得操作起来更方便,且不易出错。
如果要使用 string,需要添加 string 头文件,即#include (注意 string.h 和 string 是不一样的头文件)。除此之外,还需要在头文件下面加上一句:“using namespace std;”,这样就可以在代码中使用string 了。下面来看string的一些常用用法。
1、string的定义
定义string的方式跟基本数据类型相同,只需要在string后跟上变量名即可:
string str;
如果要初始化,可以直接给string类型的变量进行赋值:
string str = “abcd”;
//或者:
char* p = “hello”;
string str§;
2、string中内容的访问
(1) 通过下标访问
一般来说,可以直接像字符数组那样去访问string,要注意的是,string中字符的索引值从0开始计算。
#include <stdio.h>
#include <string>
using namespace std;
int main() {string str = "abcd";for (int i = 0; i < str.length(); i++) {printf("%c", str[i]); //输出abcd}return 0;
}
输出结果:abcd
也可以使用string的成员函数at(int index)访问index位置的字符。例如:在上面的示例中,str[i]等价于str.at(i)。
如果要读入和输出整个字符串,则只能使用cin和cout:
#include <iostream> //cin和cout都在iostream头文件中,而不是stdio.h中
#include <string>
using namespace std;
int main() {string str;cin >> str;cout << str;return 0;
}
上面的代码对任意的字符串输入,都会输出同样的字符串。
那么,真的没有办法用printf输出string吗?其实是有的,即用c_str( )将string类型转换为字符数组进行输出,示例如下:
#include <stdio.h>
#include <string>
using namespace std;
int main() {string str = "abcd";printf("%s\n", str.c_str());return 0;
}
输出结果:abcd
(2)通过迭代器访问
一般仅通过(1)即可满足访问的要求,但是有些函数比如insert( )与erase( )则要求以迭代器为参数,因此还是需要学习一下string迭代器的用法。
由于string不像其他STL容器那样需要参数,因此可以直接如下定义:
string::iterator it;
这样就得到了迭代器it,并且可以通过*it来访问string里的每一个字符:
#include <stdio.h>
#include <string>
using namespace std;
int main() {string str = "abcd";string::iterator it;for (it = str.begin(); it != str.end(); it++) {printf("%c", *it);}return 0;
}
输出结果:abcd
最后指出:string和vector 一样,支持直接对迭代器进行加减某个数字,如str.begin( ) + 3的写法是可行的。
3、string常用函数实例解析
事实上,string的函数有很多,伹是有些函数并不常用,因此下面就一些常用的函数举例。
(1)operator+=
这是string的加法,可以将两个`string直接拼接起来。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str1 = "abcd";string str2 = "xyz";string str3 = str1 + str2; //将str1和str2拼接,赋值给str3str1 += str2; //将str2直接拼接到str1上cout << str1 << endl;cout << str3 << endl;return 0;
}
输出结果:
abcdxyz
abcdxyz
(2)比较运算符(compare operator)
两个string类型可以直接使用==、!=、<、<=、>、>=比较大小,比较规则是字典序。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str1 = "aa";string str2 = "aaa";string str3 = "abc";string str4 = "xyz";if (str1 < str2) //如果str1字典序小于str2cout << "ok1" << endl; //则输出ok1if (str1 != str3) //如果str1字典序和str3不等cout << "ok2" << endl; //则输出ok2if (str4 >= str3) //如果str4字典序大于等于str3cout << "ok3" << endl; //则输出ok3return 0;
}
输出结果:
ok1
ok2
ok3
(3)length( ) 和size( )
length( )返回string的长度,即存放的字符数,时间复杂度为O(1)。size( )和length( )功能相同。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str = "abcdxyz";cout << str.length() << " " << str.size() << endl;return 0;
}
输出结果:
7 7
(4)insert( )
string的insert( )函数有多种使用方法,其时间复杂度都是O(n),其中n是字符串的长度。
① insert(pos,string): 在pos位置插入字符串string。
示例如下:
string str = “abcxyz”;
str.insert(3, “789”);
cout << str << endl;
输出结果:
abc789xyz
② insert(it, it2, it3): it为原字符串的待插入位置,it2和it3为待插入的字符串的首尾迭代器,用来表示待插入的字符串[it2, it3)将被插在it的位置上。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str1 = "abcxyz"; //str1为原字符串string str2 = "789"; //str2为待插入的字符串//在str1的3号位,即在字符x的位置插入字符串789str1.insert(str1.begin() + 3, str2.begin(), str2.end());cout << str1 << endl;return 0;
}
输出结果:abc789xyz
(5)erase( )
erase( )有两种用法:删除单个字符、删除一个区间内的所有字符。时间复杂度均为O(n),其中n为字符串的长度。
① 删除单个字符
string str;
str.erase(it)用于删除单个字符,it为需要删除的字符的迭代器。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str = "abcdefg";str.erase(str.begin() + 4); //删除4号位的字符,即字符ecout << str << endl;return 0;
}
输出结果:abcdfg
② 删除一个区间内的所有元素。
删除一个区间内的所有元素有两种方法:
第一种方法:str.erase(first, last),其中first为需要删除的区间的起始迭代器,而last则为需要删除的区间的末尾迭代器的下一个地址,也即为删除[first, last)。 示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str = "abcdefg";str.erase(str.begin() + 2, str.end() - 1); //删除cdefcout << str << endl;return 0;
}
输出结果:abg
第二种方法:str.erase(pos, length),其中pos为需要开始删除的起始位置,length为删除的字符个数。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str = "abcdefg";str.erase(3, 2); //删除从3号位置开始的2个字符,即删除decout << str << endl;return 0;
}
输出结果:abcfg
(6)clear( )
clear( )用于清空string中的数据,时间复杂度一般为O(1)。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str = "abcde";str.clear(); //清空字符串cout << str.length() << endl;return 0;
}
输出结果:0
(7)substr( )
substr(pos, len)返回从pos位置开始、长度为len的子串。如果第二个参数len没有给出,则一直取到末尾。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str = "Thank you for your smile.";cout << str.substr(0, 5) << endl; //Thankcout << str.substr(14, 4) << endl; //yourcout << str.substr(19, 5) << endl; //smilecout << str.substr(14) << endl; //your smile.return 0;
}
输出结果:
Thank
your
smile
your smile.
(8)string::npos
string::npos是一个常数,其本身的值为-1,但是由于是unsigned int类型,因此实际上也可以认为是unsigned int类型的最大值。string::npos一般用作find函数失败时的返回值。例如在下面的示例中可以认为string::npos等于-1或者是4294967295(这个值就是unsigned int类型的最大值2
32
−1)。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {if (string::npos == -1) {cout << "-1 is true." << endl;}if (string::npos == 4294967295) {cout << "4294967295 is also true." << endl;}return 0;
}
输出结果:
-1 is true.
4294967295 is also true.
(9)find( )
find( )函数有2个重载的使用形式,如下:
① str.find(str2):当str2是str的子串时,返回其在str中第一次出现的位置;如果str2不是str的子串,那么返回string::npos。
② str.find(str2, pos):从str的pos位置开始匹配str2,返回值与上面相同。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str = "Thank you for your smile.";string str2 = "you";string str3 = "me";if (str.find(str2) != string::npos) {cout << str.find(str2) << endl;}if (str.find(str2, 7) != string::npos) {cout << str.find(str2, 7) << endl;}if (str.find(str3) != string::npos) {cout << str.find(str3) << endl;} else {cout << "I know there is no position for me." << endl;}return 0;
}
输出结果:
6
14
I know there is no position for me.
(10)replace( )
str.replace(pos, len, str2)把str从pos位置开始、长度为len的子串替换为str2。
str.replace(it1, it2, str2)把str的迭代器[it1, it2)范围的子串替换为str2。
示例如下:
#include <iostream>
#include <string>
using namespace std;
int main() {string str = "Maybe you will turn around.";string str2 = "will not";string str3 = "surely";cout << str.replace(10, 4, str2) << endl;cout << str.replace(str.begin(), str.begin() + 5, str3) << endl;return 0;
}
输出结果:
Maybe you will not turn around.
surely you will not turn around.
(11)reverse()
reverse(): 逆转字符串。string类本身没有提供逆转字符串的成员函数,而是STL算法逆转字符串。实际上,reverse()函数用来逆转序列化容器(如vector、list,包括C/C++的数组)。
使用该函数,需要增加头文件:#include ,该头文件包含次函数的声明。
函数原型如下:
void reverse ( BidirectionalIterator first, BidirectionalIterator last);
示例:
#include <iostream>
#include <string>
#include <algorithm> //使用reverse函数
using namespace std;
int main(int argc, char const *argv[])
{string s = "hello";reverse(s.begin(), s.end());cout << s << endl;return 0;
}
输出结果:
olleh
4、C语言中将字符串转换为数值的函数
注意:在使用下面的函数时,需要包含头文件#include <stdlib.h>``。 (1) atoi( ): 将字符串转换为整数。函数原型如下: int atoi(const char* s);`
示例如下:
/* atoi example */
#include <stdio.h>
#include <stdlib.h>
int main ()
{int i;char szInput [256]; //定义字符数组printf ("Enter a number: ");scanf("%s",szInput); //输入一个数值字符串i = atoi (szInput); //转换为整数printf ("The value entered is %d\n", i);return 0;
}
运行结果1:
Enter a number: 234
The value entered is 234
运行结果2:
Enter a number: 234.567
The value entered is 234
运行结果3:
Enter a number: 234abc567
The value entered is 234
``(2) atol( ): 将字符串转换为长整数(long int)。函数原型如下: long int atol(const char* s);`
示例如下:
/* atol example */
#include <stdio.h>
#include <stdlib.h>
int main ()
{int li;char szInput [256]; //定义字符数组printf ("Enter a long number: ");scanf("%s",szInput); //输入一个数值字符串li = atol (szInput); //转换为长整数printf ("The value entered is %d\n", li);return 0;
}
运行结果:
Enter a number: 23456789
The value entered is 23456789
(3) atof( ): 将字符串转换为double类型。函数原型如下:
double atof(const char* s);
示例如下:
/* atof example: sine calculator */
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main ()
{double n, m;double pi = 3.1415926535;char szInput [256]; //定义字符数组printf ( "Enter degrees: " ); gets ( szInput ); //输入一个角度字符串n = atof ( szInput ); //转换为double类型m = sin (n * pi / 180); //求正弦函数printf ( "The sine of %f degrees is %f\n" , n, m );return 0;
}
运行结果:
Enter degrees: 45
The sine of 45.000000 degrees is 0.707107
其他还有:
strtol: Convert string to long integer (function )
strtoul: Convert string to unsigned long integer (function )
strtod: Convert string to double (function )
不再一一举例。更多详情,参见下面的网址:
http://www.cplusplus.com
在该网址下面的“C Library”分支下面有所有C语言的库函数:
http://www.cplusplus.com/reference/clibrary/
5、C++11中将string转换为数值类型
注意:下面的函数在使用时,要包含头文件#include ,并使用using namespace std; 同时还需要将所使用的编译器的编译开关-std=c++11打开。
(1) stoi( ): 将string转换为int。
示例如下:
// stoi example
#include <iostream>
#include <string>
using namespace std;
int main ()
{int i;string str; //定义string类型的字符串cout << "Enter a number: ";cin >> str; //输入一个string类型的字符串i = stoi ( str ); //转换为int类型cout << "The value entered is " << i << endl;return 0;
}
运行结果:
Enter a number: 234567
The value entered is 234567
(2) stol( ): 将string转换为long int。
(3) stof( ): 将string转换为double。
其他还有:
stoul: Convert string to unsigned integer (function template )
stoull: 将string转换为unsigned long long
不再一一举例。更多详情,参见下面的网址:
http://www.cplusplus.com
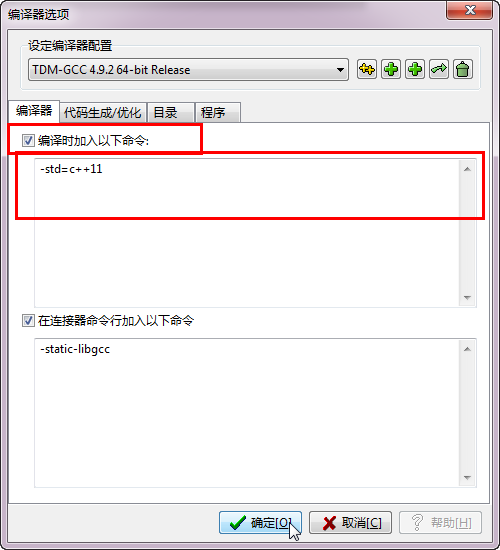
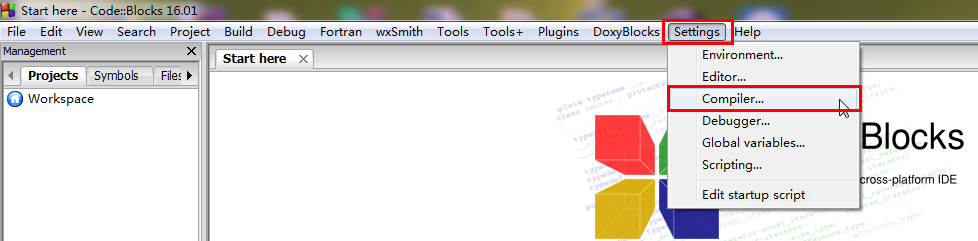
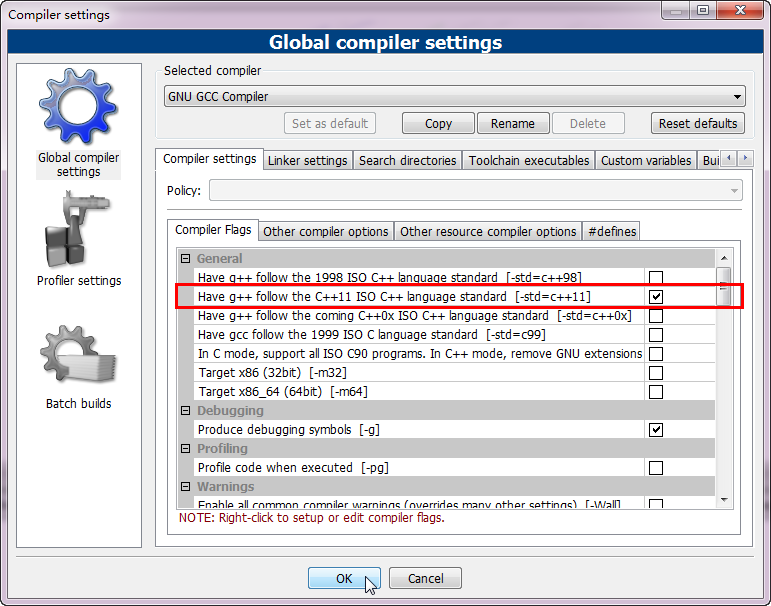
6.不同编译器打开-std=c++11编译开关的方法:
1、 Dev-Cpp

2、CodeBlocks
编程要求:
给出两个字符串text和pattern,其中pattern为text的子串,求出pattern在text中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
输入格式:
第一行为一个字符串,即为text。
第二行为一个字符串,即为pattern。
输出格式:
若干行,每行包含一个整数,表示pattern在text中出现的位置。
接下来1行,包括length(pattern)个整数,表示前缀数组next[i]的值,数据间以一个空格分隔,行尾无多余空格。
输入样例:
ABABABC
ABA
输出样例:
1
3
-1 0 0
样例说明:
kmp算法匹配示例
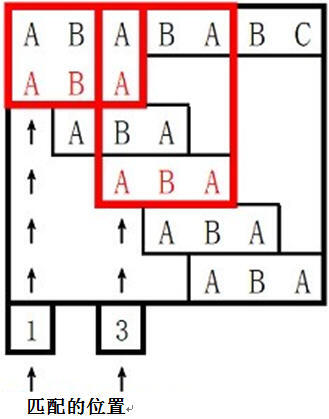
提示: 对于100%的数据:text长度<=1000000,pattern长度<=1000000
开始你的任务吧,祝你成功!
完整代码
#include <iostream>
#include <string>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;/*** txt: 字符串* pat: 模式串* 输出pat在txt中出现的位置* 输出next[]数组的值*/
const int N = 1e6 + 1;
int lps[N];
int nextarray[N];void get_lps(string pat, int * lps) {int m = pat.length();int j = 0, i = 1;lps[0] = 0;while (i < m) {if (pat[j] == pat[i]) {j++;lps[i] = j;i++;} else if (j != 0) {j = lps[j - 1];} else {lps[i] = 0;i++;}}
}void get_next(string pat,int* lps)
{int m = pat.length();get_lps(pat,lps);int i;nextarray[0] = -1;for(i = m - 2; i >= 0 ; i--){lps[i+1] = lps[i];}lps[0]= -1;for(i=0;i<m;i++){printf("%d",lps[i]);if(i<m-1)printf(" ");}
}void KMP(string txt, string pat)
{//请在下面编写代码/*************************Begin*********************/int n = txt.length();int m = pat.length();int i = 0;int j = 0;get_lps(pat, lps);while (i < n && j < m) {if (txt[i] == pat[j]) {i++; j++;} else if (j != 0) {j = lps[j - 1];} else {i++;}if (j == m) {cout << i - j + 1 << endl;j = lps[j - 1];}}get_next(pat,lps);/**************************End**********************/
}int main(int argc, char const *argv[])
{string txt, pat;cin >> txt >> pat; //输入文本串和模式串KMP(txt, pat); //调用kmp算法输出模式串在文本串中的位置以及next[]数组的值return 0;
}
第4关:利用kmp算法求子串在主串中不重叠出现的次数
任务描述
本关任务:编写一个程序,利用kmp算法求子串在主串中不重叠出现的次数。
实验目的:深入掌握KMP算法的应用。
实验内容:编写一个程序,利用KMP算法求子串t在主串s中出现的次数,例如:s=“aabbdaabbde”,t=“aabbd”,t在s中出现2次;再例如:s=“aaaaa”,t=“aa”,t在s中出现2次。
实验工具:本关提供顺序串SqString的基本运算及其实现(在头文件sqstring.h中);您也可以直接使用C++ STL提供的string容器。
编程要求
根据提示,在右侧编辑器补充完成代码,计算并输出字符串t在字符串s中不重叠出现的次数。
测试说明
平台会对你编写的代码进行测试:
输入格式
输入包括2行。
第一行为字符串s,长度不超过10^6 。
第二行为字符串t,长度不超过10^6 。
输出格式
在一行中输出t在s中出现的次数。
样例输入1
aaaaa
aa
样例输出1
2
样例输入2
aabbdaabbde
aabbd
样例输出2
2
开始你的任务吧,祝你成功!
完整代码
/* step4/step4.cpp 作答区文件 */#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <string> //C++ STL之string容器
using namespace std;#include "sqstring.h" //包含顺序串SqString基本运算算法//利用KMP算法求t在s中出现的次数
int Count(string s, string t); //利用KMP算法求t在s中出现的次数
int Count(char* s, char* t); //利用KMP算法求t在s中出现的次数
int Count(SqString s, SqString t); /*** 说明:任选上面三个函数中的一个进行实现。*///请在下面编写代码const int N =1e6;
int lps[N];
int nt[N];
void get_lps(string t,int *lps)
{int m=t.size();int i=1,j=0;lps[0]=0;while(i<m){if(t[i]==t[j]){++j;lps[i]=j;i++;}else if(j !=0){j=lps[j-1];}else{lps[i]=0;i++;}}
}
void get_next(string t,int *next)
{int m=t.length();int k= -1,j=0;next[0]=-1;while(j<m-1){if(k==-1||t[k]==t[j]){k++;j++;next[j]=k;}elsek = next[k];}
}
int Count(string s,string t)
{int n=s.length();int m=t.length();int i=0;int j=0;int tot=0;get_lps(t,lps);while(i<n&&j<m){if(s[i]==t[j]){i++;j++;}else if(j!=0)j=lps[j-1];else i++;if(j==m){tot++;j=0;}}return tot;
}
int main()
{string s,t;cin>>s>>t;cout<<Count(s,t)<<endl;return 0;
}/* step4/sqstring.h 头文件 */#ifndef __SQSTRING_H
#define __SQSTRING_H//顺序串基本运算的算法
#include <stdio.h>
#define MaxSize 1000001
typedef struct
{char data[MaxSize]; //串中字符int length; //串长
} SqString; //声明顺序串类型
void StrAssign(SqString &s, char cstr[]) //字符串常量赋给串s
{int i;for (i = 0; cstr[i] != '\0'; i++)s.data[i] = cstr[i];s.length = i;
}
void DestroyStr(SqString &s) //销毁串
{ }void StrCopy(SqString &s, SqString t) //串复制
{for (int i = 0; i < t.length; i++)s.data[i] = t.data[i];s.length = t.length;
}
bool StrEqual(SqString s, SqString t) //判串相等
{bool same = true;if (s.length != t.length) //长度不相等时返回0same = false;elsefor (int i = 0; i < s.length; i++)if (s.data[i] != t.data[i]) //有一个对应字符不相同时返回假{ same = false;break;}return same;
}
int StrLength(SqString s) //求串长
{return s.length;
}
SqString Concat(SqString s, SqString t) //串连接
{SqString str;int i;str.length = s.length + t.length;for (i = 0; i < s.length; i++) //s.data[0..s.length-1]→strstr.data[i] = s.data[i];for (i = 0; i < t.length; i++) //t.data[0..t.length-1]→strstr.data[s.length + i] = t.data[i];return str;
}
SqString SubStr(SqString s, int i, int j) //求子串
{SqString str;int k;str.length = 0;if (i <= 0 || i > s.length || j < 0 || i + j - 1 > s.length)return str; //参数不正确时返回空串for (k = i - 1; k < i + j - 1; k++) //s.data[i..i+j]→strstr.data[k - i + 1] = s.data[k];str.length = j;return str;
}
SqString InsStr(SqString s1, int i, SqString s2) //插入串
{int j;SqString str;str.length = 0;if (i <= 0 || i > s1.length + 1) //参数不正确时返回空串return str;for (j = 0; j < i - 1; j++) //s1.data[0..i-2]→strstr.data[j] = s1.data[j];for (j = 0; j < s2.length; j++) //s2.data[0..s2.length-1]→strstr.data[i + j - 1] = s2.data[j];for (j = i - 1; j < s1.length; j++) //s1.data[i-1..s1.length-1]→strstr.data[s2.length + j] = s1.data[j];str.length = s1.length + s2.length;return str;
}
SqString DelStr(SqString s, int i, int j) //串删去
{int k;SqString str;str.length = 0;if (i <= 0 || i > s.length || i + j > s.length + 1) //参数不正确时返回空串return str;for (k = 0; k < i - 1; k++) //s.data[0..i-2]→strstr.data[k] = s.data[k];for (k = i + j - 1; k < s.length; k++) //s.data[i+j-1..s.length-1]→strstr.data[k - j] = s.data[k];str.length = s.length - j;return str;
}
SqString RepStr(SqString s, int i, int j, SqString t) //子串替换
{int k;SqString str;str.length = 0;if (i <= 0 || i > s.length || i + j - 1 > s.length) //参数不正确时返回空串return str;for (k = 0; k < i - 1; k++) //s.data[0..i-2]→strstr.data[k] = s.data[k];for (k = 0; k < t.length; k++) //t.data[0..t.length-1]→strstr.data[i + k - 1] = t.data[k];for (k = i + j - 1; k < s.length; k++) //s.data[i+j-1..s.length-1]→strstr.data[t.length + k - j] = s.data[k];str.length = s.length - j + t.length;return str;
}
void DispStr(SqString s) //输出串s
{if (s.length > 0){ for (int i = 0; i < s.length; i++)printf("%c", s.data[i]);printf("\n");}
}#endif
第5关:利用KMP算法求子串在主串中重叠出现的次数
任务描述
本关任务:编写一个程序,利用kmp算法求子串在主串中不重叠出现的次数。
实验目的:深入掌握KMP算法的应用。
实验内容:编写一个程序,利用KMP算法求子串t在主串s中重叠出现的次数,例如:s=“aabbdaabbde”,t=“aabbd”,t在s中出现2次;再例如:s=“aaaaa”,t=“aa”,t在s中出现4次。
实验工具:本关提供顺序串SqString的基本运算及其实现(在头文件sqstring.h中);您也可以直接使用C++ STL提供的string容器。
编程要求
根据提示,在右侧编辑器补充完成代码,计算并输出字符串t在字符串s中重叠出现的次数。
测试说明
平台会对你编写的代码进行测试:
输入格式
输入包括2行。
第一行为字符串s,长度不超过10^6 。
第二行为字符串t,长度不超过10^6 。
输出格式
在一行中输出t在s中出现的次数。
样例输入1
aaaaa
aa
样例输出1
4
样例输入2
aabbdaabbde
aabbd
样例输出2
2
开始你的任务吧,祝你成功!
完整代码
/* step5/step5.cpp 作答区文件*/#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <string> //C++ STL之string容器
using namespace std;#include "sqstring.h" //包含顺序串SqString基本运算算法//利用KMP算法求t在s中重叠出现的次数
int Count(string s, string t); //利用KMP算法求t在s中重叠出现的次数
int Count(char* s, char* t); //利用KMP算法求t在s中重叠出现的次数
int Count(SqString s, SqString t); /*** 说明:任选上面三个函数中的一个进行实现。*///请在下面编写代码
const int N =1e6;
int lps[N];
int nt[N];
void get_lps(string t,int *lps)
{int m=t.size();int i=1,j=0;lps[0]=0;while(i<m){if(t[i]==t[j]){++j;i++;}else if(j !=0){j=lps[j-1];}else{lps[i]=0;i++;}}
}
void get_next(string t,int *next)
{int m=t.length();int k= -1,j=0;next[0]=-1;while(j<m-1){if(k==-1||t[k]==t[j]){k++;j++;next[j]=k;}elsek = next[k];}
}
int Count(string s,string t)
{int n=s.length();int m=t.length();int i=0;int j=0;int tot=0;get_next(t,nt);while(i<n&&j<m){if(j==m-1&&s[i]==t[j]){tot++;j=nt[j];}if(j==-1||s[i]==t[j]){i++;j++;}else j=nt[j];}return tot;
}
int main()
{string s,t;cin>>s>>t;cout<<Count(s,t)<<endl;return 0;
}/*step5/sqstring.h 头文件*/
#ifndef __SQSTRING_H
#define __SQSTRING_H//顺序串基本运算的算法
#include <stdio.h>
#define MaxSize 1000001
typedef struct
{char data[MaxSize]; //串中字符int length; //串长
} SqString; //声明顺序串类型
void StrAssign(SqString &s, char cstr[]) //字符串常量赋给串s
{int i;for (i = 0; cstr[i] != '\0'; i++)s.data[i] = cstr[i];s.length = i;
}
void DestroyStr(SqString &s) //销毁串
{ }void StrCopy(SqString &s, SqString t) //串复制
{for (int i = 0; i < t.length; i++)s.data[i] = t.data[i];s.length = t.length;
}
bool StrEqual(SqString s, SqString t) //判串相等
{bool same = true;if (s.length != t.length) //长度不相等时返回0same = false;elsefor (int i = 0; i < s.length; i++)if (s.data[i] != t.data[i]) //有一个对应字符不相同时返回假{ same = false;break;}return same;
}
int StrLength(SqString s) //求串长
{return s.length;
}
SqString Concat(SqString s, SqString t) //串连接
{SqString str;int i;str.length = s.length + t.length;for (i = 0; i < s.length; i++) //s.data[0..s.length-1]→strstr.data[i] = s.data[i];for (i = 0; i < t.length; i++) //t.data[0..t.length-1]→strstr.data[s.length + i] = t.data[i];return str;
}
SqString SubStr(SqString s, int i, int j) //求子串
{SqString str;int k;str.length = 0;if (i <= 0 || i > s.length || j < 0 || i + j - 1 > s.length)return str; //参数不正确时返回空串for (k = i - 1; k < i + j - 1; k++) //s.data[i..i+j]→strstr.data[k - i + 1] = s.data[k];str.length = j;return str;
}
SqString InsStr(SqString s1, int i, SqString s2) //插入串
{int j;SqString str;str.length = 0;if (i <= 0 || i > s1.length + 1) //参数不正确时返回空串return str;for (j = 0; j < i - 1; j++) //s1.data[0..i-2]→strstr.data[j] = s1.data[j];for (j = 0; j < s2.length; j++) //s2.data[0..s2.length-1]→strstr.data[i + j - 1] = s2.data[j];for (j = i - 1; j < s1.length; j++) //s1.data[i-1..s1.length-1]→strstr.data[s2.length + j] = s1.data[j];str.length = s1.length + s2.length;return str;
}
SqString DelStr(SqString s, int i, int j) //串删去
{int k;SqString str;str.length = 0;if (i <= 0 || i > s.length || i + j > s.length + 1) //参数不正确时返回空串return str;for (k = 0; k < i - 1; k++) //s.data[0..i-2]→strstr.data[k] = s.data[k];for (k = i + j - 1; k < s.length; k++) //s.data[i+j-1..s.length-1]→strstr.data[k - j] = s.data[k];str.length = s.length - j;return str;
}
SqString RepStr(SqString s, int i, int j, SqString t) //子串替换
{int k;SqString str;str.length = 0;if (i <= 0 || i > s.length || i + j - 1 > s.length) //参数不正确时返回空串return str;for (k = 0; k < i - 1; k++) //s.data[0..i-2]→strstr.data[k] = s.data[k];for (k = 0; k < t.length; k++) //t.data[0..t.length-1]→strstr.data[i + k - 1] = t.data[k];for (k = i + j - 1; k < s.length; k++) //s.data[i+j-1..s.length-1]→strstr.data[t.length + k - j] = s.data[k];str.length = s.length - j + t.length;return str;
}
void DispStr(SqString s) //输出串s
{if (s.length > 0){ for (int i = 0; i < s.length; i++)printf("%c", s.data[i]);printf("\n");}
}#endif