一、CUDA层次结构
1.kernel核函数
一个CUDA程序是一个kernel核函数被GPU的多个计算单元并行执行的过程,CUDA给了如下抽象
dim3 threadsPerBlock(4, 3, 1);
dim3 numBlocks(3, 2, 1);
matrixAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
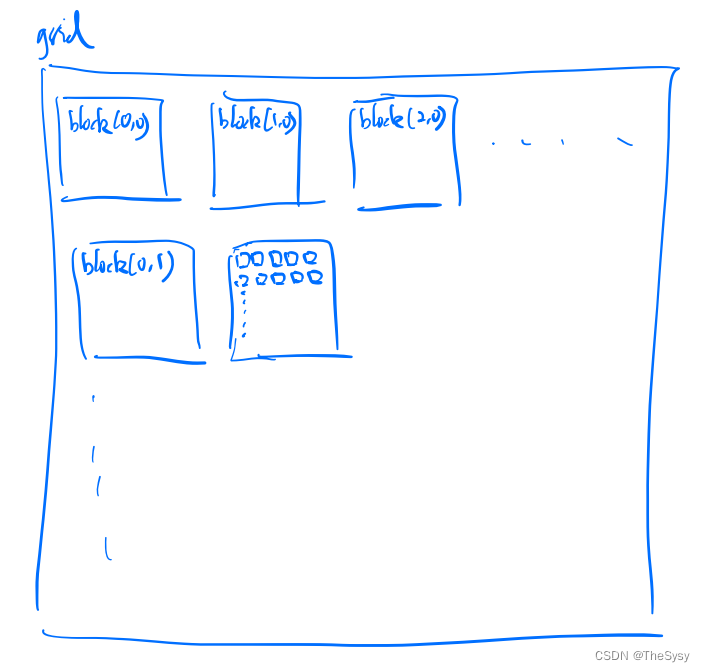
2.Grid,Block,Thread
这样启动核函数,根据CUDA的抽象,就会有下面这样的运行模式,<<<>>>中间的两个参数numblocks和threadsPerBlock都是三维的变量,给予程序员设计的便利。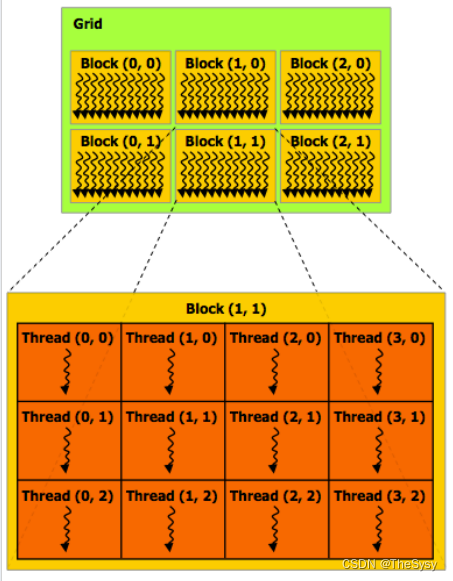
每个thread就是一个实际的核函数在运行,核函数可以根据当前的blockIdx,threadIdx来获得当前核函数所在的三维坐标位置。
int index = blockIdx.x * blockDim.x + threadIdx.x;
3.Streaming Multiprocessor(SM),warp
每个Block会分给一个SM(Streaming Multiprocessor),一个SM可以理解成一个有很多核的处理单元,并且有一个共享内存,下面看看一个SM内部如何工作。

下面这个图是一个典型的SM内部,每个黄方框都是一个SIMD单元,他们共享一个内存,左边的warp是实际分配给这些SIMD单元的任务,一个warp是一些线程的集合,CUDA用行优先的逻辑将一个block里的thread分配给warp,注意CUDA这里dim这个东西横纵坐标跟别的不太一样,如下图,他是Y是行号,X是列号。
在CUDA文档中,有讲到是根据线程id来顺序连续分配的,线程id计算方式如下
对于1维的来说,1维的x就是线程id
对于2维的来说,id是x + y Dx,y是行号,x是列号,所以就是行号乘一行的数量再加上列号。
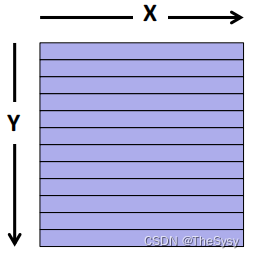
对于3维的来说,id是x + y Dx + z Dx Dy,那就是高(z)乘上一个面的线程数,再加上y乘上行长在加上x。
所以总结来说,就是先分配面,然后在面上行优先分配。
一个warp通常是32个thread来执行SIMD指令,因为每个线程都是同样的核函数。但这里其实会有一个问题,那就是条件分支可能会不一样,最大的效率在这32个线程都执行相同的条件分支时达到,因为不同的分支会导致simd单元先执行一部分,而另一部分会等这部分执行完在执行。
所以一个warp才类似于操作系统中的一个线程,GPU会将warp视为线程来做硬件多线程调度。
看左边这一堆warp,存的就是每个warp的运行时状态,这里面包含了每个warp独立的寄存器、PC等东西,所以这里GPU做的硬件多线程就类似于一种超线程技术,使用多套上下文,使上下文切换没有开销。

二、CUDA内存层次结构

从最快的每个thread私有的内存,然后是整个块共享的一片内存,然后到整个GPU共享的全局内存。
一个值得注意的点,当一个warp访问内存中连续的地址时,会做块读取/写入,一次性将一个块内容读取/写入,所以如果让一个warp内的线程具有连续的内存访问模式,是比较好的,结合刚才的,如果也有同样的条件分支,那更好了。
三、一个矩阵乘法的优化例子
1.最基本的

直接A的行乘B的列相加,这会导致B的内存访问模式是跳跃的,不缓存友好。
2.预转置
那么就把B提前转置了,这样A和B都可以一行一行的访问了。
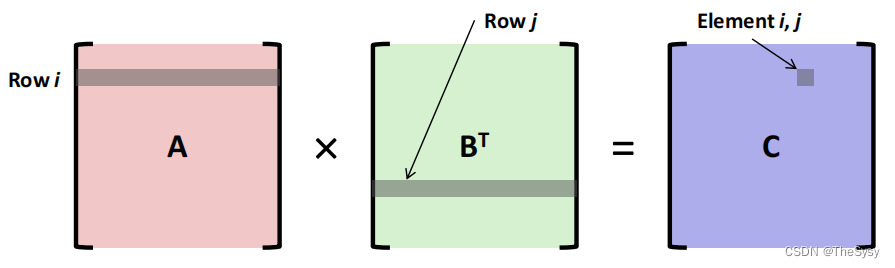
可以看到有一定的优化了

3.变成CUDA代码
最基础的版本,我们让C结果矩阵的每一个元素都用一个核函数来算结果,i和j就是C矩阵的i和j,我们直接将整个grid,映射成一个二维矩阵,那么横坐标i就是先拿块id的y乘上块的长度再加上块里面线程的横坐标y。纵坐标也类似。
___global__ void CUDASimpleKernel(int N, float *dmatA, float *dmatB, float *dmatC)
{int i = blockIdx.y * blockDim.y + threadIdx.y;int j = blockIdx.x * blockDim.x + threadIdx.x;if (i >= N || j >= N)return;float sum = 0.0;for (int k = 0; k < N; k++){sum += dmatA[RM(i, k, N)] * dmatB[RM(k, j, N)];}dmatC[RM(i, j, N)] = sum;
}
然后i,j确定下来后,就去用k遍历A矩阵的一行和B矩阵的一列来计算结果元素。

当然,要变成CUDA代码还需要一些初始化的host代码。
首先要在GPU上分配内存,然后Memcpy过去
然后初始化块的数量和块的大小,就可以启动核函数了
然后算完之后再Memcpy回CPU
最后别忘了free掉GPU上用的内存
void CUDAMultMatrixSimple(int N, float *dmatA, float *dmatB, float *dmatC)
{dim3 threadsPerBlock(LBLK, LBLK);dim3 blocks(updiv(N, LBLK), updiv(N, LBLK));CUDASimpleKernel<<<blocks, threadsPerBlock>>>(N, dmatA, dmatB, dmatC);
}void CUDAMultiply(int N, float *aData, float *bData, float *cData)
{float *aDevData, *bDevData, *cDevData;CUDAMalloc((void **)&aDevData, N * N * sizeof(float));CUDAMalloc((void **)&bDevData, N * N * sizeof(float));CUDAMalloc((void **)&cDevData, N * N * sizeof(float));CUDAMemcpy(aDevData, aData, N * N * sizeof(float), CUDAMemcpyHostToDevice);CUDAMemcpy(bDevData, bData, N * N * sizeof(float), CUDAMemcpyHostToDevice);CUDAMultMatrixSimple(N, aDevData, bDevData, cDevData);CUDAMemcpy(cData, cDevData, N * N * sizeof(float), CUDAMemcpyDeviceToHost);CUDAFree(aDevData);CUDAFree(bDevData);CUDAFree(cDevData);
}好的,这有一个巨额的提升。
4. 考虑一个情况
刚才的i和j计算的代码变成这样,效果会变差十多倍。为什么呢
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y
想想内存访问模式的变化。刚才的代码,一个block里的一个warp是横着连续的,

横着连续说明他们的i一样,j连续,这说明,在对A矩阵的访问上,一直用的都是同一行,是内存中同一个连续的位置,可以进行块读。对B矩阵的访问上,是一列一列访问的,但是整个warp所需要访问的内存是连续的,所以也可以进行块读。
然后,对于写,是写C的连续的位置,因为是横着的,所以可以进行块写。
而新的代码
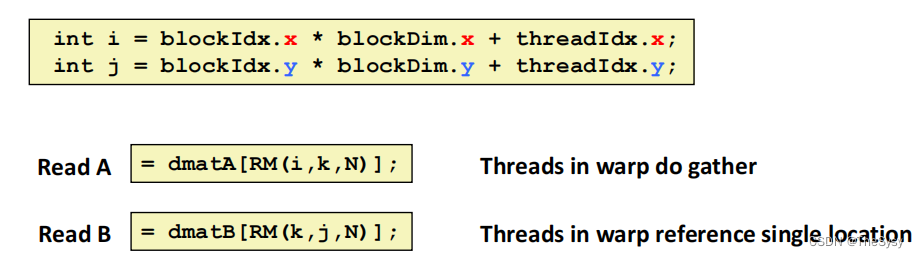
i是列号乘块的纵长,再加上块里的线程纵位置,也就是i和j对比刚才互换了,这样会导致什么,同一个warp里计算的是C矩阵纵向的元素。C矩阵纵向的元素,对于A,是不同的行,这样warp内整体也是连续的,可以进行块读,对于B,是同一列,这里读是不能块读的,因为内存是不连续的。
再看写,是竖着写的,所以写的也是C的不连续的位置,这样写也不能进行块写。
综上,这两个就差在一个块写和块读上了。