3. 线程安全
线程安全:某个代码,不管它是单个线程执行,还是多个线程执行,都不会产生bug,这个情况就成为“线程安全”。
线程不安全:某个代码,它单个线程执行,不会产生bug,但是多个线程执行,就会产生bug,这个情况就成为 “线程不安全”,或者 “存在线程安全问题”。
举个线程不安全例子,我们计算一个变量的自增次数,它循环了100000次,用两个线程去计算,各自计算循环50000次的次数。
3.1 线程不安全样例
根本原因:线程的随机调度,抢占式执行
代码结构:不同线程修改同一数据
直接原因:多线程操作不是原子的
由于线程的随机调度,抢占式执行(不可避免),代码结构会促进该原因加剧不良后果;
1、代码一分析---->代码随机调度,抢占执行的例子
代码如下:
public class ThreadDemo4 {private static int count = 0;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {for (int i = 1; i < 50000; i++) {count++;}});Thread t2 = new Thread(() -> {for (int i = 50000; i <= 100000; i++) {count++;}});t1.start();t2.start();t1.join();t2.join();System.out.println("count: " + count);} }按照我们的逻辑,从1自增到10_0000,肯定是自增了10_0000次,但是结果如下图所示:
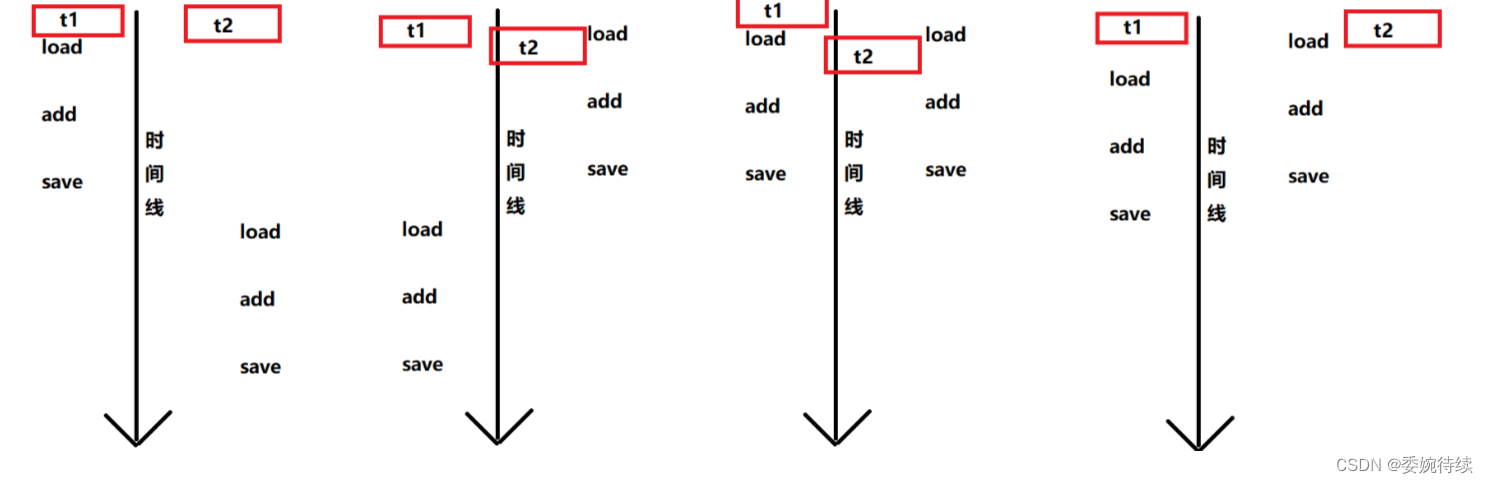
我们实际答案却不是10_0000,是53978次,其出现如上情况的最主原因就是多线程代码它们是并发执行的,且往代码深层次分析,java中的count++语句是由cpu的三个指令构成的:
(1)首先load 从内存中读取数据到cpu的寄存器中;
(2)其次add 把寄存器中的值 + 1;
(3)最后save 把寄存器中的值写回到内存中;
因为上面两个线程t1和t2是并发执行的,那则t1 和 t2 线程的执行顺序就是无序的,他们可能同时读取内存中的数据add,双方都自增完往寄存器+1(应该是+1后再+1),但是最后从寄存器中save到内存中时,却只读取了一个线程自增完后的数值,另外一个自增的过程被忽略了,一些具体的分析如下图所示;
线程并发执行的结果是无数的,并不是简单的排列组合就能穷举出来,因为并发的原因,可能 t1 线程它执行了两次,才执行一次 t2 线程,或者 t2 执行的次数更多,t1 线程只执行一次。等以上这些情况都是有可能出现的。
故此t1 和 t2自增的时候,就可能从寄存器中拿的是同一个值,这两线程的其中一个自增后,没有来得及在内存中进行自加1,另一个线程自增完后就直接往内存中那这个值了,最后的结果肯定是不符合我们预期的。
故此由上图所示,符合我们预期的效果就只有最前面的两个情况了,但是这种情况也就是多线程串行化执行,执行完 t1,再执行t2,代码如下所示:
public class ThreadDemo4 {private static int count = 0;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {for (int i = 1; i < 50000; i++) {count++;}});Thread t2 = new Thread(() -> {try {t1.join();} catch (InterruptedException e) {throw new RuntimeException(e);}for (int i = 50000; i <= 100000; i++) {count++;}});t1.start();t2.start();t2.join();System.out.println("count: " + count);} }结果如下:
但是如此操作的话,这个代码和多线程的运行就完全没有关系了;
2、代码二分析---->内存可见性例子
代码如下:
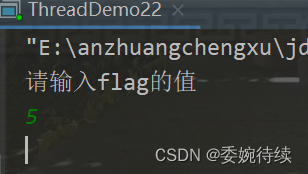
package thread;import java.util.Scanner;public class ThreadDemo22 {private static int flag = 1;public static void main(String[] args) {Thread t1 = new Thread(() -> {while (flag == 1) {System.out.println("这里是线程t1");}System.out.println("t1线程结束");});Thread t2 = new Thread(() -> {System.out.println("请输入flag的值");Scanner scanner = new Scanner(System.in);flag = scanner.nextInt();});t1.start();t2.start();} }执行预期是当我们输入不等于1的值,就打印 “t1线程结束”,但是当我们输入结果为5,最终执行结果却不是我们预期的效果,执行结果如下:
flag值是!=1,但是t1线程一直在循环运行,虽然t2线程是在按照我们的要求改变flag的值,为什么结果与预期是相悖的,如此就涉及到了jvm内部的优化了,和内存可见性相关;
t1线程中的flag==1这一操作有两个核心指令:
(1)load,读取内存中的flag值到寄存器
(2)拿着寄存器中的值和1进行比较(条件跳转指令)
这里load的每次操作取到的值都是一样的,而当我们执行scanner操作修改flag的值时,load这一指令,已经执行上百亿次了;且从内存中取数据这一操作是非常耗时的,远远比条件跳转指令花时间,这时由于load开销太大,jvm就会产生怀疑,怀疑这个load继续操作的必要性;从而给出优化,把从内存读数据load这一操作给优化掉了,这样一来,jvm就不会再从内存中拿数据,而是把load拿到的值放到寄存器中,从寄存器拿到数据,进行比较。这样可以大幅度的提高循环的执行速度。
上面的例子,t2修改了内存,但是t1没看到内存变化,就称为内存可见性问题。而内存可见性问题,是高度依赖编译器优化的问题;


3.2 线程不安全问题解决方法
3.2.1 t1 循环里加sleep
代码如下:
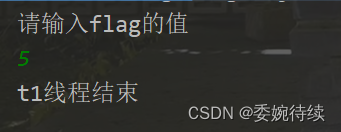
public class ThreadDemo3 {private static int flag = 1;public static void main(String[] args) {Thread t1 = new Thread(() -> {while (flag == 1) {try {Thread.sleep(10);} catch (InterruptedException e) {throw new RuntimeException(e);}//循环题里,啥也不写}System.out.println("t1线程结束");});Thread t2 = new Thread(() -> {System.out.println("请输入flag的值");Scanner scanner = new Scanner(System.in);flag = scanner.nextInt();});t1.start();t2.start();} }结果如下:
方法详解:因为10秒中都可以让t1线程里面的循环执行上百亿次(cpu飞快的从内存中网寄存器中读取数据),这样会导致load的开销就非常大,代码的优化迫切程度就比较大;但是加了sleep后,我们让线程t1进行休眠,如此load的开销就小了很多,代码的优化迫切程度就降低了,故此load就能将5这个值在优化前读取到寄存器和flag进行比较,最终达到我们预期的效果;
3.3.2 给flag变量加volatile修饰
代码如下:
public class ThreadDemo3 {private volatile static int flag = 1;public static void main(String[] args) {Thread t1 = new Thread(() -> {while (flag == 1) {//循环题里,啥也不写}System.out.println("t1线程结束");});Thread t2 = new Thread(() -> {System.out.println("请输入flag的值");Scanner scanner = new Scanner(System.in);flag = scanner.nextInt();});t1.start();t2.start();} }结果与之前类似,略;
方法分析:
1、java提供volatile关键字,其核心作用,就是保证 “内存可见性”(另一功能:禁止指令重排序)可以使jvm强迫的优化强制关闭,这样就可以确保循环每次都是从内存中拿数据了,虽然这样执行效率也会下降,但数据更为准确了;
2、我们对编译器优化是这样表述的:
编译器发现,每次循环都要从内存中读取数据,内存开销都太大了,于是把读取内存这一操作优化成读取寄存器这一操作。
在JMM模型是这样描述的:
编译器发现,每次循环都要从 “主内存” 中读取数据,就会把数据从 “主内存” 中复制下到 “工作内存” 中,后续每次读取都是在 “工作内容” 这读取。(这里的“工作内容代指cpu寄存器 + 缓存”)---->这里的 “主内存” 翻译成内存,“工作内存” 翻译成cpu寄存器 ;
3.3 线程不安全的原因
1、根本原因
操作系统上的线程是“抢占式执行”,随机调度的---->给线程之间的执行顺序带来了很多变数。2、代码结构
多个线程同时修改同一个变量。2.1、如果一个线程修改一个变量,没事。
2.2、多个线程读取同一个变量,没事的-->如果只是读取,变量的内容是固定不变的。
2.3、多个线程修改不同的变量,没事--->如果是两个不同的变量,彼此之间就不会产生相互覆盖的情况了
3、直接原因
多线程修改操作,本身不是原子的即count++:该操作可以被细分为3个cpu指令,一个线程执行这些指令,执行到一半会被调走,从而给其他线程“可乘之机”------>每个cpu指令,都是原子的,要么不执行,要么执行完
4、内存可见性
一个线程读,一个线程写,也会导致线程安全的问题。5、指令重排序
编译器的一种优化,在保证代码逻辑不变的情况下,将一些代码的指令重新排序,从而提高代码的执行效率,但是有时候会因为重排序后,多线程编程就会出现线程安全问题。
番外:
String是一个不可变对象
好处:
- 方便jvm进行缓存(放到字符串常量池中)
- Hash值固定
- String的对象是线程安全的-à意味着只能读取,不能修改
为什么说string是不可变的?
- 持有的数据(char 【】数组)是private的
- 里面没有提供public的方法来修改char数组的相关内容。
- Final只是表示不可被继承,和可变没有关系。
3.4 针对上述原因给出的解决方案
针对原因1:
我们无法给出解决方案,因为操作系统内部已经实现了“抢占式执行”,我们干预不了
针对原因2:
分情况,有的时候,代码结构可以调整,有的时候调整不了。
针对原因3:
把要修改的变量这操作,通过特殊手段,把这操作在系统里的多个指令打包成一个“整体”。例如加锁操作,而加锁的操作(下一篇详细讲解),就是把多个指令打包成一个原子的操作。
针对原因4:
可以对代码进行调整,避免内存可见性的问题;也可以使用volatile进行修饰,强制把代码优化关了,这样数据就更准确了,但执行效率也就变慢了。
针对原因5:
将某些可能会指令重排序的变量,加volatile修饰,强制取消指令重排序的优化。
ps:本次的内容就到这里了,如果感兴趣的话就请一键三连哦!!!