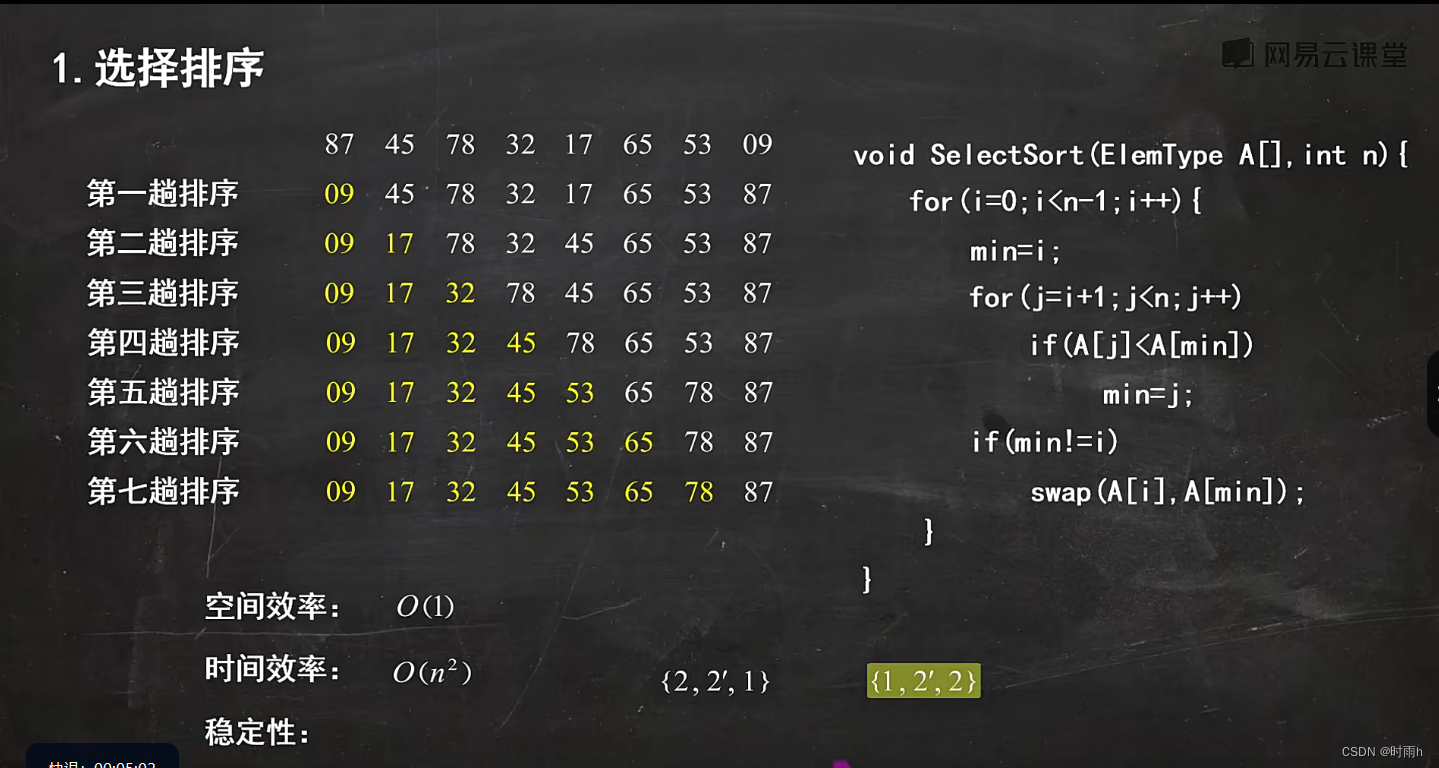
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 文献阅读:用于密集预测的多路径视觉Transformer
- 1、研究背景
- 2、方法提出
- 3、相关方法
- 3.1、Vision Transformers for dense predictions
- 3.2、Comparison to Concurrent work
- 4、Multi-Path Vision Transformer 结构实现
- 4.1、Multi-Scale Patch Embedding
- 4.2、Multi-path Transformer
- 5、实验测试
- 6、文章贡献
- Transformer 复习
- 1、什么是Transformer
- 2、Transformer模型的框架
- 3、Encoder
- 3.1、Encoder的作用
- 3.2、Encoder中Block的详细实现
- 4、Decoder
- 4.1、Decoder的作用
- 4.2、可能性序列的产生过程
- 5、Encoder和Decoder之间的连接
- Encoder和Decoder之间的连接主要集中在Cross attention当中,其主要两个输入由Encoder输入,另外一个由Decoder输入,这些输入都是通过各自的Self-attention(Mask)处理后输入到Cross attention进行下一步处理,这样便完成了两个结构之间的连接。 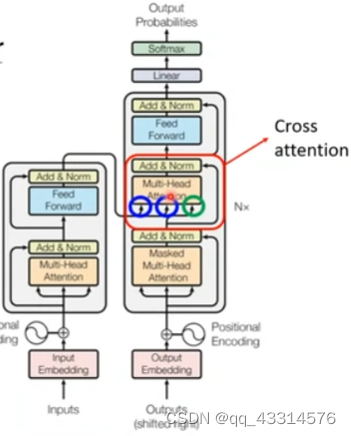
摘要
本周主要阅读了2022CVPR的文章,用于密集预测的多路径视觉Transformer,在文章中讲解了当前Transformer对于多尺度的密集预测的困难之处,并提出了一种方法多路径视觉Transformer方法来解决,其主要思路就是通过嵌入CNN对多路径的物体进行特征提取,最后将特征重新聚合得到一种多路径的视觉密集预测的方法。在最终测试下,都取得比较好的成绩。另外我还对Transformer的相关知识进行了复习。
Abstract
This week I mainly read articles from CVPR 2022, focusing on the multi-path visual Transformer for dense prediction. In the article, the difficulties of current Transformer for dense prediction at multiple scales are explained, and a method, the multi-path visual Transformer method, is proposed to solve them. The main idea is to extract features from multiple paths of objects through embedding CNN, and finally re-aggregate the features to obtain a method for dense prediction of multiple paths of vision. In the final test, good results were achieved. In addition, I also reviewed the related knowledge of Transformer.
文献阅读:用于密集预测的多路径视觉Transformer
Title: MPViT: Multi-Path Vision Transformer for Dense Prediction
Author:Youngwan Lee, Jonghee Kim, Jeff Willette, Sung Ju Hwang
From:2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、研究背景
⾃推出以来,Transformer 对⾃然语⾔处理(NLP)产⽣了巨⼤影响。同样Vision Transformer (ViT) 的出现推动了计算机视觉社区的发展。因此,最近基于 Transformer 的视觉⼯作出现了爆炸式增⻓,涵盖静态图像分类等任务,物体检测和语义分割到视频分类等时间任务和对象跟踪 。对于诸如对象检测和分割之类的密集预测任务来说,表示关重要多尺度特征⽤于区分不同⼤⼩的物体或区域。现代 CNN 主⼲在密集预测⽅⾯表现出更好的性能,在卷积核级别利⽤多个尺度,或特征级别。初始⽹络 或 VoVNet 在同⼀特征级别利⽤多粒度卷积核,产⽣不同的感受野,进⽽提⾼检测性能。⼈⼒资源⽹通过同时聚合整个卷积层的精细和粗略特征来表⽰多尺度特征。尽管 CNN 模型被⼴泛⽤作密集预测的特征提取器,CNN的性能已经被ViT超越。ViT 变体重点关注如何解决应⽤于⾼分辨率密集预测时⾃注意⼒的⼆次复杂度,他们较少关注构建有效的多尺度表⽰。
2、方法提出
作者以不同于现有Transformer的视角,探索多尺度path embedding与multi-path结构,提出了Multi-path Vision Transformer(MPViT)。通过使用 overlapping convolutional patch embedding,MPViT同时嵌入相同大小的patch特征。然后,将不同尺度的Token通过多条路径独立地输入Transformer encoders,并对生成的特征进行聚合,从而在同一特征级别上实现精细和粗糙的特征表示。在特征聚合步骤中,引入了一个global-to-local feature interaction(GLI)过程,该过程将卷积局部特征与Transformer的全局特征连接起来,同时利用了卷积的局部连通性和Transformer的全局上下文。
3、相关方法
3.1、Vision Transformers for dense predictions
密集的计算机视觉任务,如目标检测和分割,需要有效的多尺度特征表示,以检测或分类不同大小的物体或区域。Vision Transformer(ViT)构建了一个简单的多阶段结构(即精细到粗糙),用于使用单尺度patch的多尺度表示。然而ViT的变体专注于降低自注意的二次复杂度,较少关注构建有效的多尺度表示。CoaT通过使用一种co-scale机制,同时表示精细和粗糙的特征,允许并行地跨层注意,从而提高了检测性能。然而,co-scale机制需要大量的计算和内存开销,因为它为基础模型增加了额外的跨层关注(例如,CoaT-Lite)。因此,对于ViT体系结构的多尺度特征表示仍有改进的空间。
3.2、Comparison to Concurrent work
CrossViT利用了不同的patch大小和单级结构中的双路径,如ViT和XCiT。然而,CrossViT的分支之间的相互作用只通过[CLS]token发生,而MPViT允许所有不同规模的patch相互作用。此外,与CrossViT(仅限分类)不同的是,MPViT更普遍地探索更大的路径维度(例如,超过两个维度),并采用多阶段结构进行密集预测。
4、Multi-Path Vision Transformer 结构实现

4.1、Multi-Scale Patch Embedding
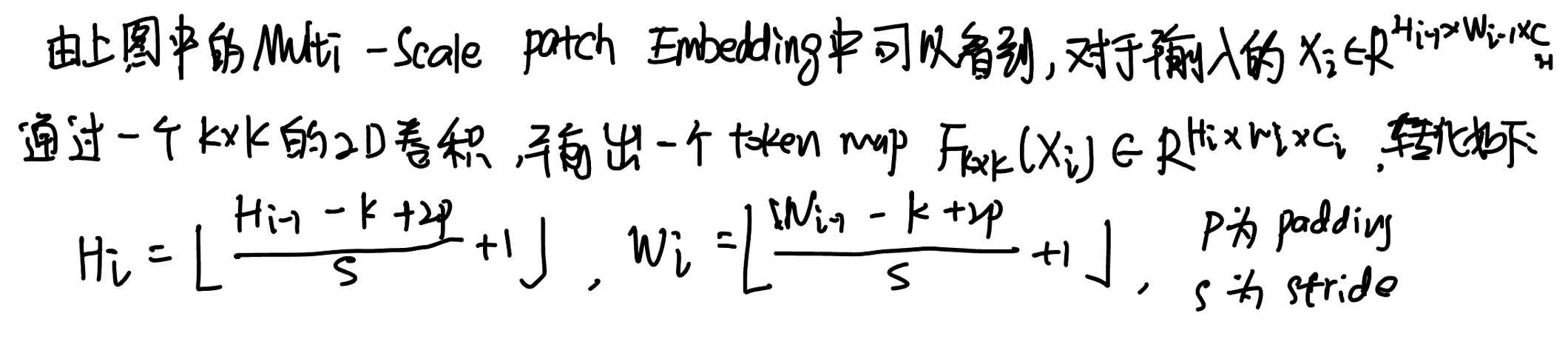
通过改变stride和padding来调整token的序列长度。也就是说,可以输出具有不同patch大小的相同大小(即分辨率)的特征。因此,这样就能并行地形成了几个具有不同卷积核大小的卷积patch embedding层。例如,如上图的Multi-Scale Patch Embedding 结构种,可以生成相同序列长度的不同大小的vision token,patch大小分别为3×3,5×5,7×7。
由于具有相同通道和滤波器大小的连续卷积操作扩大了接受域,并且需要更少的参数,在实践中选择了连续的3×3卷积层。为了减少参数量,在实践中选择了两个连续的3×3卷积层代替5×5卷积。对于triple-path结构,使用三个连续的3×3卷积,通道大小为C’,padding为1,步幅为s,其中s在降低空间分辨率时为2,否则为1。因此通过该层可以得到相同大小的特征F3x3(Xi)、F5x5(Xi)、F7x7(Xi)
- 注意:为了减少模型参数和计算开销,采用3×3深度可分离卷积,包括3×3深度卷积和1×1点卷积。每个卷积之后都是Batch Normalization 和一个Hardswish激活函数。接着,不同大小的token embedding features 分别输入到Multi-path transformer Block 中的 encoder 中。
4.2、Multi-path Transformer
- Convolutional Local Feature 和 Transformer Encoder
Transformer中的self-attention可以捕获长期依赖关系(即全局上下文),但它很可能会忽略每个patch中的结构性信息和局部关系。相反,cnn可以利用平移不变性中的局部连通性,使得CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状。因此,MPViT以一种互补的方式将CNN与Transformer结合起来。其中为了表示局部特征,其采用了一个 depthwise residual bottleneck block,包括1×1卷积、3×3深度卷积和1×1卷积和残差连接。 - Global-to-Local Feature Interaction

5、实验测试
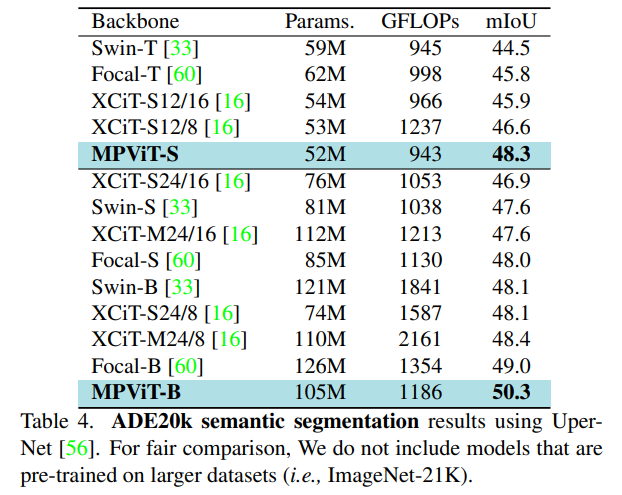
使用upernet作为分割方法,并将ImageNet-1k预训练的MPViTs集成到supernet中。接下来,为了公平比较,训练模型160k次迭代,批大小为16,使用AdamW[38]优化器,学习率为6e-5,权重衰减为0.01。使用标准的单尺度协议报告性能。使用mmseg[11]库实现mpvit。与其他Swin-T、Focal-T和XCiT-S12/16相比,mpvits的性能(48.3%)更高,分别为+3.8%、+2.5%和+2.4%。有趣的是,mpvit也超过了更大的型号,如Swin-S/B, XCiT-S24/16, -M24/16, -S24/8和Focal-S。此外,mpvitb性能优于最近(和更大的)SOTA变压器Focal-B[67]。这些结果表明,MPViT的多尺度嵌入和多路径结构使其具有多样化的特征表示能力。
6、文章贡献
- 通过多路径并行设计实现了对多尺度信息的利用
- 通过深度卷积操作实现了全局上下文的利用(Mask2Former也有一摸一样的结构)
- 通过对照试验探究了多尺度多路径模型在不同尺度及路径数量下的效果
Transformer 复习
1、什么是Transformer
Transformer其实是一个sequence-to-sequence的模型,而Seq2seq模型是一个输入是sequence以及输出也是一个sequence的模型,其中需要注意的是输出有几种可能,和输入一样长、更短以及更长,当然还有让机器自己决定输出多长的情况。
2、Transformer模型的框架
Transformer模型,即Sequence-to-sequence模型,主要分为两个部分Encoder以及Decoder。输入的sequence经过Encoder进行编码处理,输出处理好的数据向量,之后将该数据向量输入到Decoder进行解码处理,这样最后就能得到想要的最后的输出Sequence结果。
3、Encoder
3.1、Encoder的作用
Sequence-to-sequence模型的Encoder主要作用就是处理一个向量,输出另外一个向量。当然其他模型也能够完成同样的任务,就比如RNN和CNN等模型。然后Encoder处理单元里面,包含了多重的Block,每一层的Block中会经过Self-attention处理。然后再通过Fully Connection进行连接,给下一层的block输出向量。
3.2、Encoder中Block的详细实现
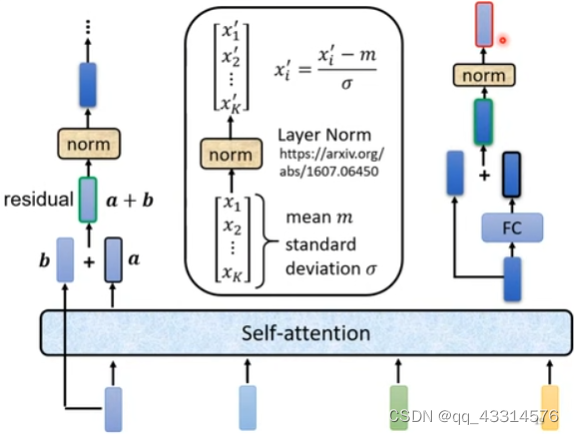
Encoder的每一个Block输出都要经过如下图的步骤,首先原向量要经过self-attention处理得到一个预处理向量,预处理向量再与原向量进行Residual处理,紧接着是进行norm处理,norm处理是为了防止向量值出现过大的偏差,实现方式就是原向量与mean标准值的差,再除以偏离值。norm处理后的向量,会进行fully connection处理,得到新的fc处理向量,与原向量进行residual处理,最后再经过norm处理得到最后的结果。
4、Decoder
4.1、Decoder的作用
Sequence-to-sequence模型的Decoder主要作用就是把Encoder输出的向量。经过一系列的处理,最后输出一个可能性序列。如下图所示,将Encoder的输出向量,经过处理,输出成“机器学习”这样的一个序列,就好像机器识别到“机”这个字以后会判断出下一个字是“器”,整个序列是一个可能性序列,是经过softmax处理得到的。

4.2、可能性序列的产生过程
由上面的学习可以知道,Decoder会输出一个可能性序列,这个可能性序列实现的方式主要是根据前面的字符影响后面输出的字符,不断重复的影响及输出,就能够输出这样的可能性序列。这样的重复影响就能够联想到self-attention,但是self-attention是所有输出都彼此影响,是无法实现我们所说的可能性序列。因为只需要前者对后者的影响,而不需要后者对前者的影响。所以需要对self attention进行改进,变成masked self attention。如下图所示,它只会让前者影响后者,而不会导致后者影响前者的情况。向量内容的输入顺序是逐个输入,而不是同时输入,这是一个比较大的区别。