爬虫概念:
通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程
分类:
1,通用爬虫:抓取一整张页面数据
2,聚焦爬虫:抓取页面中的局部内容
3,增量式爬虫:只会抓取网站中最新更新出来的数据
反爬协议robots.txt协议
http协议:
服务器与客户端进行数据交互的一种形式
User-Agent:请求载体的身份标识
Connection:请求完毕是断开还是保持连接
Content-Type: 服务器响应回客户端的数据类型
https协议:证书认证加密,安全的超文本传输协议
1,requests模块:
作用:模拟浏览器发请求
流程:1,指定url 2,发起请求 3,获取响应数据 4,持久化存储
1.1爬取搜狗首页:
import requests
if __name__ == '__main__':url='https://www.sogou.com/'response=requests.get(url=url)page_text=response.text#返回字符串形式的响应数据print(page_text)with open('./sougou.html','w',encoding='utf-8') as fp:fp.write(page_text)print('爬取数据结束!')
1.2网页采集器
User-Agent:请求载体的身份标识
UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
import requests
if __name__ == '__main__':#UA伪装:将对应的UA封装到一个字典里headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2669.400 QQBrowser/9.6.10990.400'}url='https://www.sogou.com/sie?hdq=AQxRG-0000&'#处理URL参数分装到字典里kw=input('enter a word:')param={'query':kw}
#对指定URL发起的请求对应的url是携带参数的请求过程中处理了参数response=requests.get(url=url,params=param,headers=headers)page_text=response.text#返回字符串形式的响应数据fileName=kw+'.html'with open(fileName,'w',encoding='utf-8') as fp:fp.write(page_text)print(fileName,'保存成功!!')

1.3破解百度翻译
打开百度翻译官网,右键检查
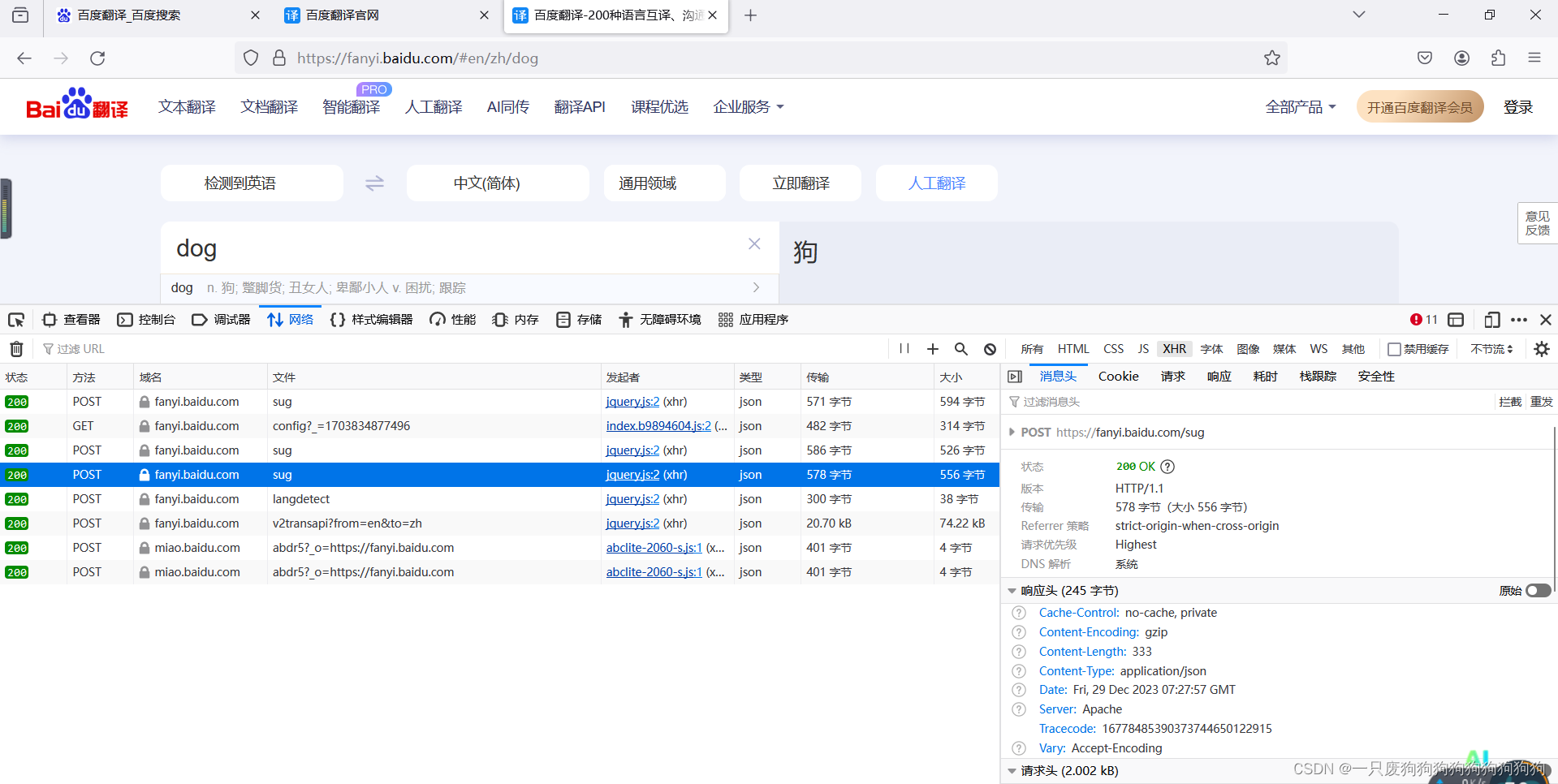
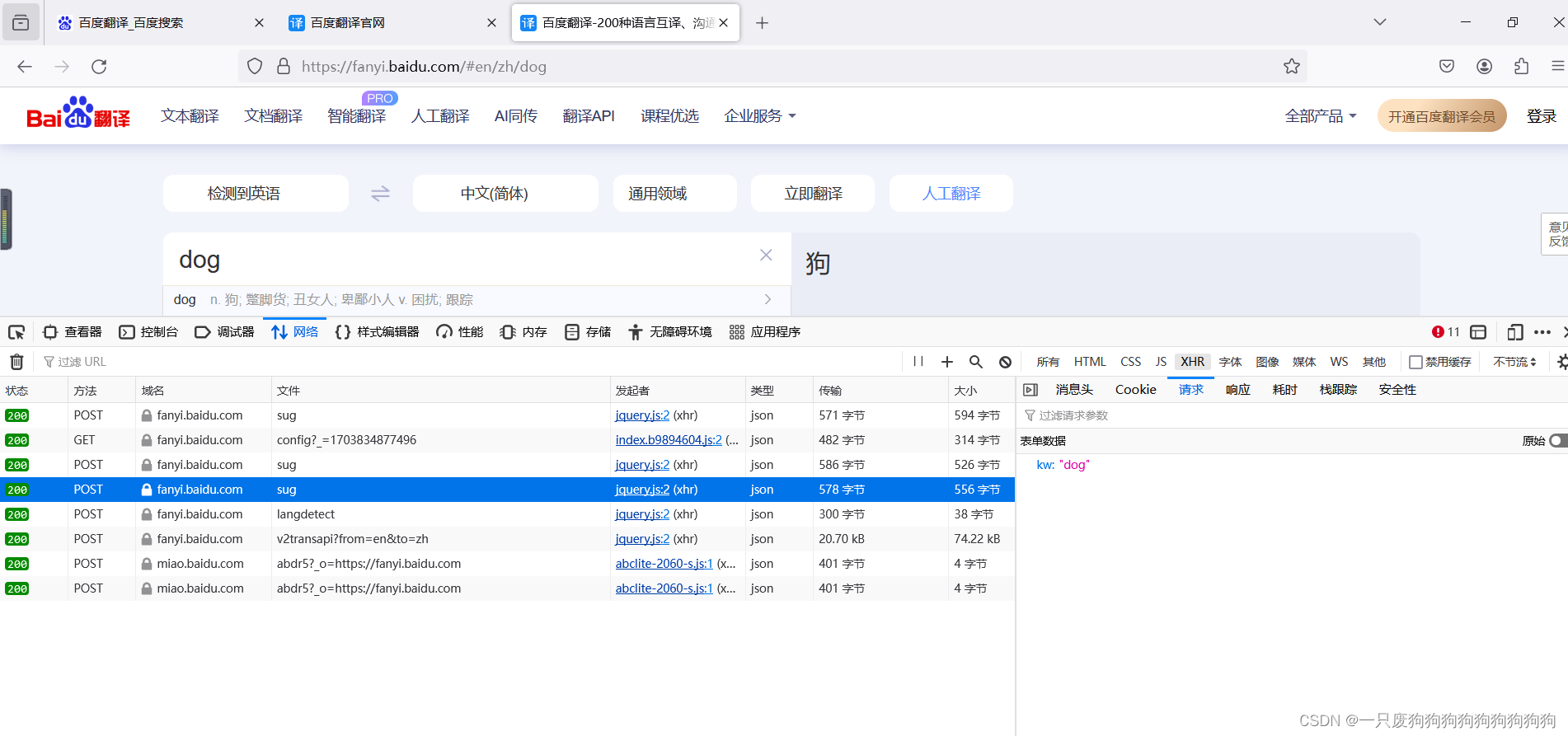
发出的是一个post请求(携带参数),响应数据是一组json数据
import requests
import json#导入模块
if __name__ == '__main__':post_url='https://fanyi.baidu.com/sug'#1,指定urlheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2669.400 QQBrowser/9.6.10990.400'}#经行UA伪装#3,post请求参数处理(与get类似)word=input('enter a word:')data={'kw':word}#4,发送请求response=requests.post(url=post_url,data=data,headers=headers)#5,获取响应数据:json()方法返回的是obj(提前确定是json类型)dic_obj=response.json()#持久化存储fileName=word+'.json'fp=open(fileName,'w',encoding='utf-8')json.dump(dic_obj,fp=fp,ensure_ascii=False)#中文不可以用ASCII码print('over!!')效果:

1.4,豆瓣电影爬取

文件类型为json,地址中有参数,获取方式为get
import requests
import json#导入模块
if __name__ == '__main__':url='https://movie.douban.com/j/chart/top_list'param={'type':'24','interval_id':'100:90','action':'','start':'3',#第一个电影'limit':'20'#数量}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2669.400 QQBrowser/9.6.10990.400'}response=requests.get(url=url,params=param,headers=headers)#请求list_data=response.json()#json类型fp=open('./douban.json','w',encoding='utf-8')#生成文件json.dump(list_data,fp=fp,ensure_ascii=False)print('over!!!')1.5爬取肯德基餐厅
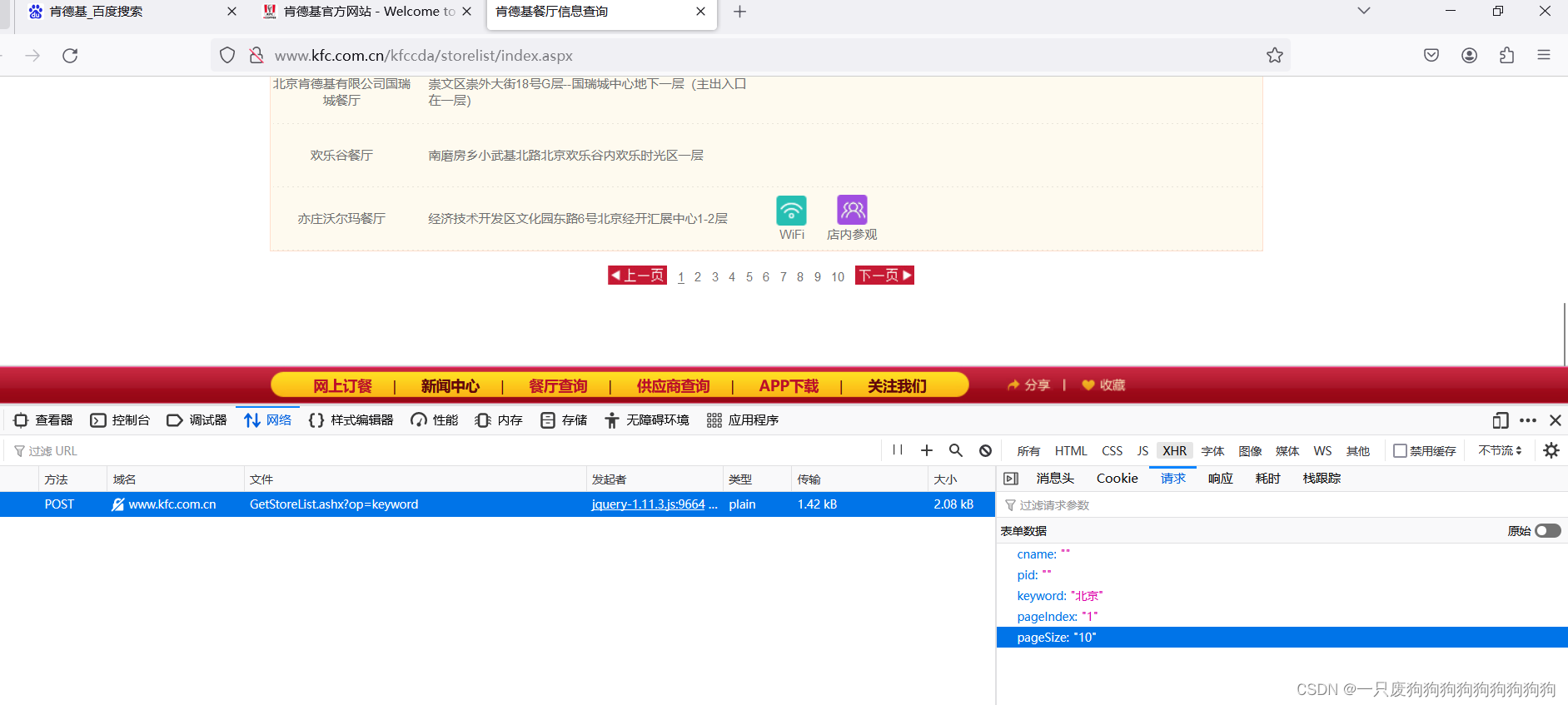
要求:统计各个城市共有多少家肯德基餐厅,并打印门店信息
请求方式为post,文本类型(content-Type):text

参数:
import requestsurl = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
# UA伪装
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
word = input("请输入地址: ")
numbers = 1
# 页数
number_pages = 0
# 第一次检测页数
state = True
while numbers != 0:number_pages += 1data = {'cname': '','pid': '','keyword': word,'pageIndex': number_pages,'pageSize': '10',}# 请求发送response = requests.post(url=url, data=data, headers=header)text = response.textnumbers -= 1# 计算页数,因为只需要一次即可if state:# 将列表text转化为字典dictionary = eval(text)# 获取第一段Table的页数rowcount = dictionary['Table']# 将这个列表中的字典赋给dictsdicts = rowcount[0]# 查询rowcount所指的页数numbers = dicts['rowcount']if numbers == 0:print("抱歉,您所输入的地址没有肯德基餐厅")else:print(f"{word}一共有{numbers}家肯德基餐厅")if numbers % 10 == 0:numbers = numbers // 10#整除else:numbers = numbers // 10 # 不加一是因为已经检查过一次了state = Falseprint(text)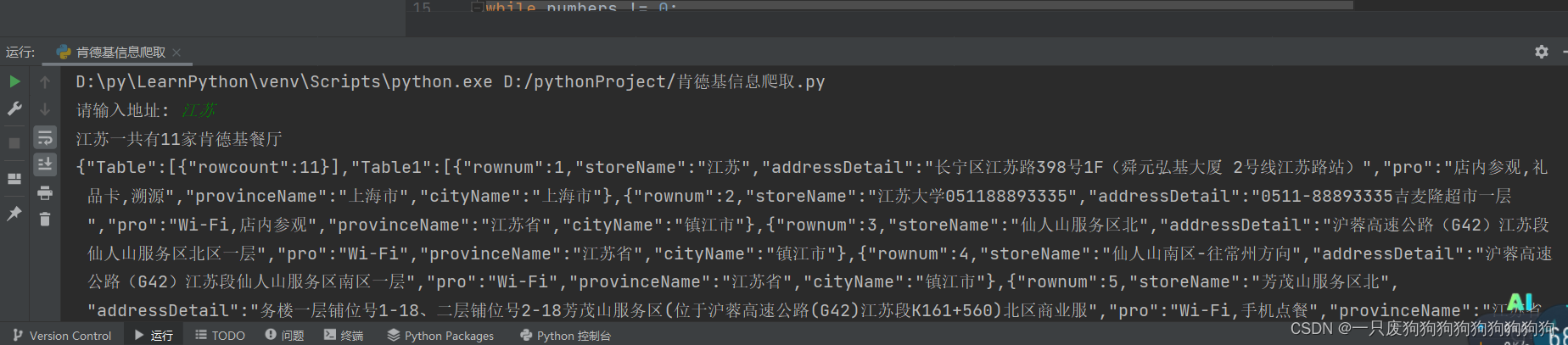


![[C#]OpenCvSharp结合yolov8-face实现L2CS-Net眼睛注视方向估计或者人脸朝向估计](https://img-blog.csdnimg.cn/direct/909af88688144d84b280121f3fd6305d.jpeg)
![Matlab技巧[绘画逻辑分析仪产生的数据]](https://img-blog.csdnimg.cn/direct/2d9aabee8a4f40e484181d7d0e218033.png)
