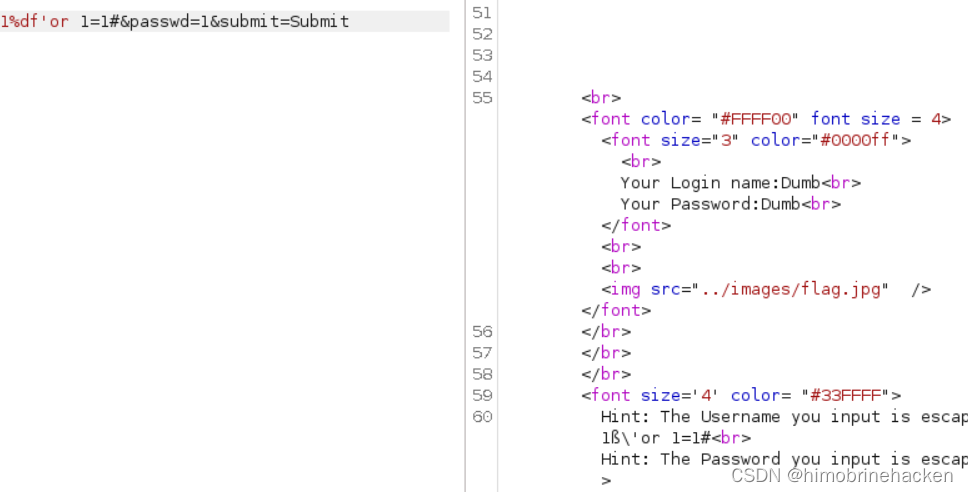
- 基于Redis集群解决单机Redis存在的问题,在之前学Redis一直都是单节点部署
单机或单节点Redis存在的四大问题:

- 数据丢失问题:Redis是内存存储,服务重启可能会丢失数据 => 利用Redis数据持久化的功能将数据写入磁盘
- 并发能力问题:单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景 => 搭建一主多从集群,实现读写分离
- 单点故障 - 故障恢复问题:如果Redis宕机,则服务不可用,需要一种自动的故障恢复手段 => 利用Redis哨兵,实现健康检测和自动故障恢复
- 存储能力问题:Redis基于内存存储,单节点能存储的数据量难以满足海量数据要求 => 搭建分片集群,利用插槽机制实现动态扩容,从理论上来讲,它的存储能力是没有上限的
1. Redis主从
- 搭建主从架构
- 主从数据同步原理
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
1.1.主从集群结构
- Redis的集群往往都是主从集群,它往往会有一个Master主节点,多个Slave / Replica从节点。
下图就是一个简单的Redis主从集群结构:

如图所示,集群中有一个Master主节点、两个Slave从节点(现在叫Replica) => 起码要包含三个节点,要有三个Redis实例,一主两从。
- 在Redis 5.0以前,从节点是叫Slave的,后来改名叫Replica => 都是代表从节点
当我们通过Redis的Java客户端访问主从集群时,应该做好路由:
-
如果是写操作,应该访问Master主节点,Master主节点会自动将数据同步给两个Slave从节点
-
如果是读操作,建议访问各个Slave从节点,从而分担并发压力
Master主节点可以执行set命令(写操作),Replica从节点只能执行get命令(读操作) 。
为什么Redis要做成这种主从的集群,而不是传统的负载均衡集群呢?
- 这是因为Redis应用当中大多数都是读多写少的场景,也就是查询比较多,而增删改比较少,既然如此,我们更多要应对的是读的压力,那我做了主从以后,我们还可以去做读写分离, 也就是说,我在执行写操作时,我让它去访问Master主节点,但如果执行的是读操作,那我就把你的请求分发到各个Slave或Replica从节点,这样我们一主多从,多个从节点共同承担读的请求,我们的读并发能力就可以得到一个比较大的提升,所以这就是为什么要搭建主从集群的一个原因了。
- 但是做主从集群,必须保证一点,就是客户端在读取的时候,不管访问到哪个Slave从节点,都必须要保证拿到相同的结果 => 如何保证? 需要让Master主节点把它上面的数据同步给每一个Slave从节点,这就是Redis主从架构的一个基本模式了
1.2 搭建主从集群
1. 准备实例和配置
- 我们会在同一台虚拟机中开启3个Redis实例,模拟主从集群。
-
我们会在同一个虚拟机中利用3个Docker容器来搭建主从集群。
-
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
-
在同一个机器下还要修改每个实例的端口
2. 启动 & 开启主从关系
分别启动多个Redis实例,虽然我们启动了3个Redis实例,但是它们并没有形成主从关系,我们需要通过命令来配置主从关系:
# Redis5.0以前
slaveof <masterip> <masterport>
# Redis5.0以后
replicaof <masterip> <masterport>有临时和永久两种模式:
-
永久生效:在redis.conf文件中利用slaveof命令指定Master主节点的IP和端口
-
临时生效:直接利用redis-cli控制台输入slaveof命令,指定Master主节点的IP和端口
INFO replication:查看集群的状态信息
这样,就可以实现读写分离了,如果在Slave从节点上执行set写操作,会报错:

假设有A、B两个Redis实例,如何让B作为A的Slave从节点?
- 在B节点执行命令:slaveof A的IP A的Port端口
1.3 数据同步原理