一、引言
1. 索引的重要性
MySQL数据库索引的重要性主要体现在,一是查询速度优化,索引可以极大地提高查询速度。对于没有索引的表,MySQL必须进行全部扫描来找到所需的行,如果表中数据量很大,那么通常很慢。通过适当的索引,可以快速定位到表中的数据,显著提高查询速度。二是可以保证数据完整性,比如唯一索引可以确保某列中的数据是唯一的,可以防止重复的数据。当然还有其他的一些好处,比如加速Order By、Group By等操作,这里就不一一列举了。
不过尽管索引提供了很多好处,但是使用索引也有代价,主要是索引本身需要占用额外的磁盘空间,并且在数据发生变化时,相关的索引也要进行更新,影响写操作的性能。
2. 为什么需要进行索引优化
MySQL索引优化的主要原因是提高查询速度,减少数据库的响应时间,提高系统的整体性能。
二、 索引的基本概念
1. 什么是索引
索引是一种数据库结构,是对一列或者多列的值进行排序,从而达到快速访问表中特定信息,避免全表扫描。索引类似于图书的目录,可以根据目录中的页码快速找到内容。MySQL中,索引主要有两种结构:BTree和Hash,平时常用的是BTree。
2. 索引的基本原理
索引是建立一个映射关系,将数据的关键字与其所在位置建立对应关系,这样在进行搜索的时候可以快速定位到目标数据的位置,而不需要遍历整个数据集。MySQL数据库的索引采用B+树的结构进行存储,B+树的特点是非叶子节点只存储索引(key),叶子节点存放所有索引和数值(Key+Value),叶子节点具有相同深度,并且叶子节点之间按照顺序通过指针连接。结构如下:
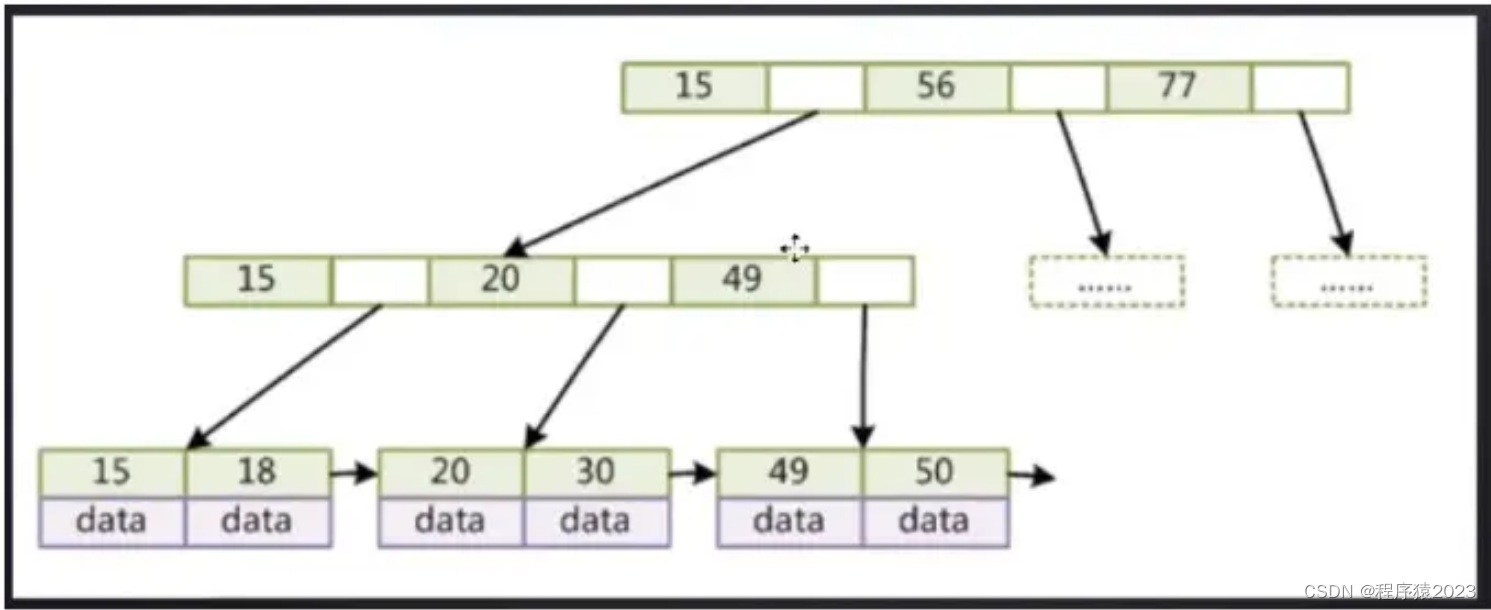
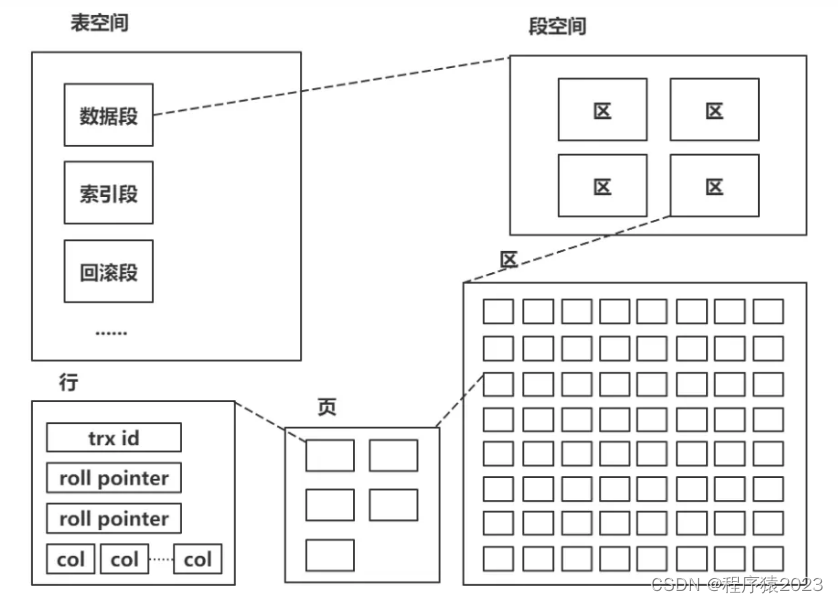
索引的存储,在innodb存储引擎下, 由段、区、页组成,区大小为1MB(一个区由64个联系页构成),页的默认值是16KB。
B+树的一个节点对应一个数据页,B+树的层越高,那么要读取到内存的数据页越多,IO次数越多,innodb存储引擎的B+树中的一个节点16KB
假设:key+指针大小是16byte,一行数据的大小为1KB,
那么一个非叶子节点可存储16KB/16byte=1024个; 每个叶子节点可存储1024行数据。
那么:
2层B+树,最大可容纳的记录数为: 1024*16=16384
3层B+数,最大可容纳的记录数为: 1024*1024*16=16777216
4层B+数,最大可容纳的记录数为: 1024*1024*1024*16=17179869184
三、索引的创建和使用
1. 如何创建索引
1.1 在MySQL中,可以使用以下语法来创建索引:
CREATE INDEX index_name ON table_name(column1, column2, ...);
其中, index_name是索引的名称, table_name是要创建索引的表名称,column1,column2是要创建索引的列名称举例示范:比如在RECV_LIST表创建telephone_list和status的索引
create index idx_recv_list_telephone_status on recv_list(telephone_list, status);由于该表有100万的数据,创建索引花费了32秒的时间。MySQL5.6版本之后,创建索引默认使用在线DDL(Data Definition Language)方法,意味着创建索引时不会锁定整个表。
1.2 在MySQL中,创建唯一索引
CREATE UNIQUE INDEX index_name ON table_name (column1, column2, ...);
举例示范: 比如在RECV_LIST表创建ID的索引
create unique index idx_recv_list_id on recv_list(id);
四、索引优化策略
MySQL索引优化策略一般会从以下几个方面入手:
1. 查看数据库INSERT、UPDATE、DELETE、SELECT的访问频次
索引优化一般只针对查询多的表、库进行,如果该表或者库都是以INSERT为主的,那么其实没有必要进行索引优化。查看数据库INSERT、UPDATE、DELETE、SELECT的访问频次的语句如下:
SHOW GLOBAL STATUS LIKE 'Com_______'Com后面是7个下横线。 查询结果如下所示:

2. 慢查询日志的分析
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒)的所有SQL语句的日志,MySQL的慢查询日志默认没有开启,配置信息在my.ini(Linux系统在my.cnf)中。
查看long_query_time的配置参数
show variables like '%long_query_time%';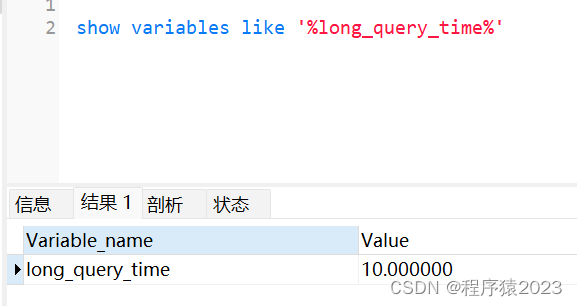
MySQL慢查询的参数long_query_time的默认值是10秒,只要sql的执行时间超过10秒,就会被记录在慢查询日志。如何查看慢查询是否开启,默认MySQL是不开启慢查询日志记录,开启慢查询日志记录会有一定性能的损耗。
查看慢日志记录是否开启
show variables like '%slow_query_log%';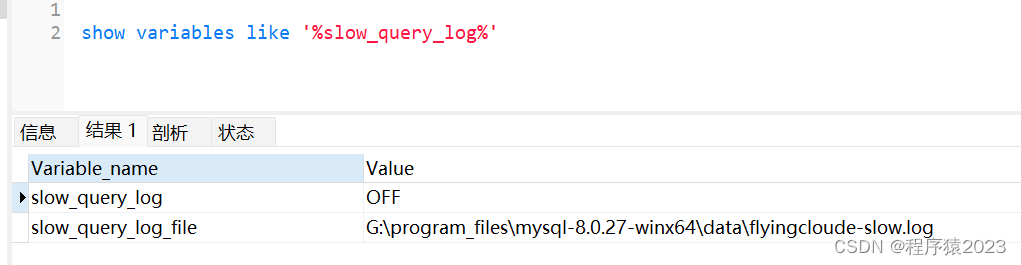
可以看到,慢日志记录开启之后,日志保存的路径。
开启慢查询日志记录,在my.ini新增如下配置参数, 配置完参数后,重启MySQL服务。
#开启MySQL慢日志查询开关
slow_query_log=1#设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2完成配置后,再进行select count(*) from recv_list查询,由于表中有100万条数据,count时间比较长,就会被记录在slow日志文件中
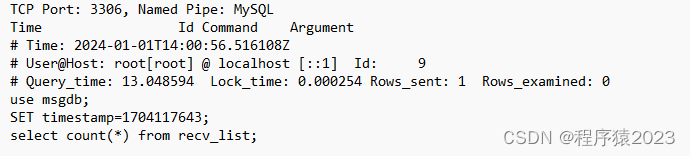
3. show profiles
慢查询日志只是会记录sql执行时间超过了我们配置的慢查询时间,但是如果在业务系统里有执行频率很高的又比较接近慢查询时间,这些sql执行是不会记录在慢查询日志里的。 这个sql,我们可以通过show profiles来分析, show profiles能够在做sql优化时帮忙我们了解时间都消耗到哪里去了。通过have_profiling参数,能够看到当前MySQL是否支持profile操作:
SELECT @@HAVE_PROFILING;默认profiling是关闭的,可以通过set语句在session/global级别开启profiling
set profiling=1;可以通过,select @@profiling查看开关是否打开。
select @@profiling;执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
#查看每一条SQL的耗时基本情况
show profiles;#查看指定query_id的sql语句每个阶段的耗时情况
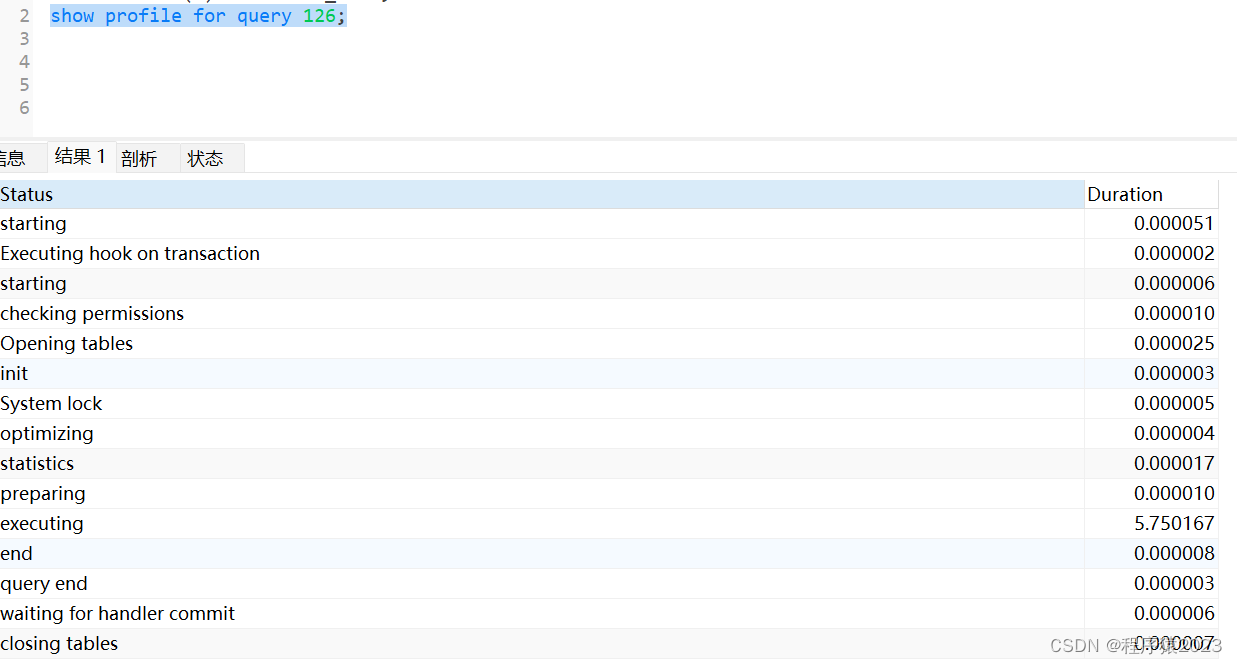
show profile for query query_id;#查看指定query_id的sql语句cpu使用情况
show profile cpu for query query_id; 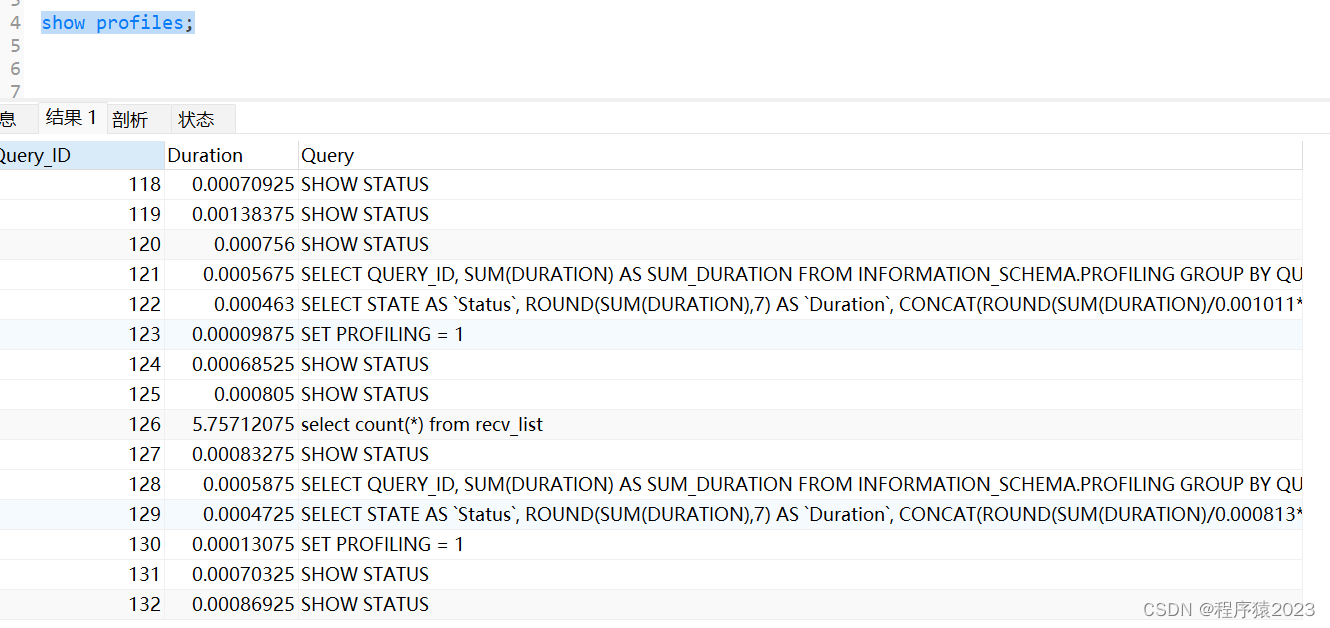
4. 使用explain进行sql语句执行计划的分析
上面三种方式都是从时间的层面判断sql语句的执行性能。explain命令是获取MySQL如何执行SELECT语句的信息,包括在SELECT语句执行过程中如何连接和连接的顺序。
explain select count(*) from recv_list;
explain执行计划各字段含义:
id:select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行)。
select_type:表示select的类型,常见的取值有simple(简单表,即不使用表连接或者子查询),primary(主查询,即外层的查询)、union(union中的第二个或者后面的查询语句)、subquery(select/where之后包含了子查询)等。
type: 表示连接类型,性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、index、all;优化过程中尽量往前靠。当访问的时候,不访问任何表,这个时候是NULL,在业务系统中不太可能是NULL;system是访问系统表的时候,可能会出现的。
possible_key: 显示可能应用在这张表上的索引,一个或者多个。
key:实际使用的索引,如果为null,则没有使用索引。
key_len:表示索引中使用的字节数,该值为索引字段最大可能长岛,并非实际使用长度,在不损失精确性的前提下,长度越短越好。
rows:MySQL任务必须要执行查询的行数,是一个估计值。
filtered:表示返回结果的行数占需读取行数的百分比,filtered的值越大越好。
本篇主要在理论上针对MySQL索引的重要性、概念以及如何创建索引和索引优化策略作了介绍,下一篇,将针对实际的索引优化过程进行介绍。


![[Redis实战]分布式锁](https://img-blog.csdnimg.cn/direct/c9a2ed94483143cb83a26cc9d9294c68.png)