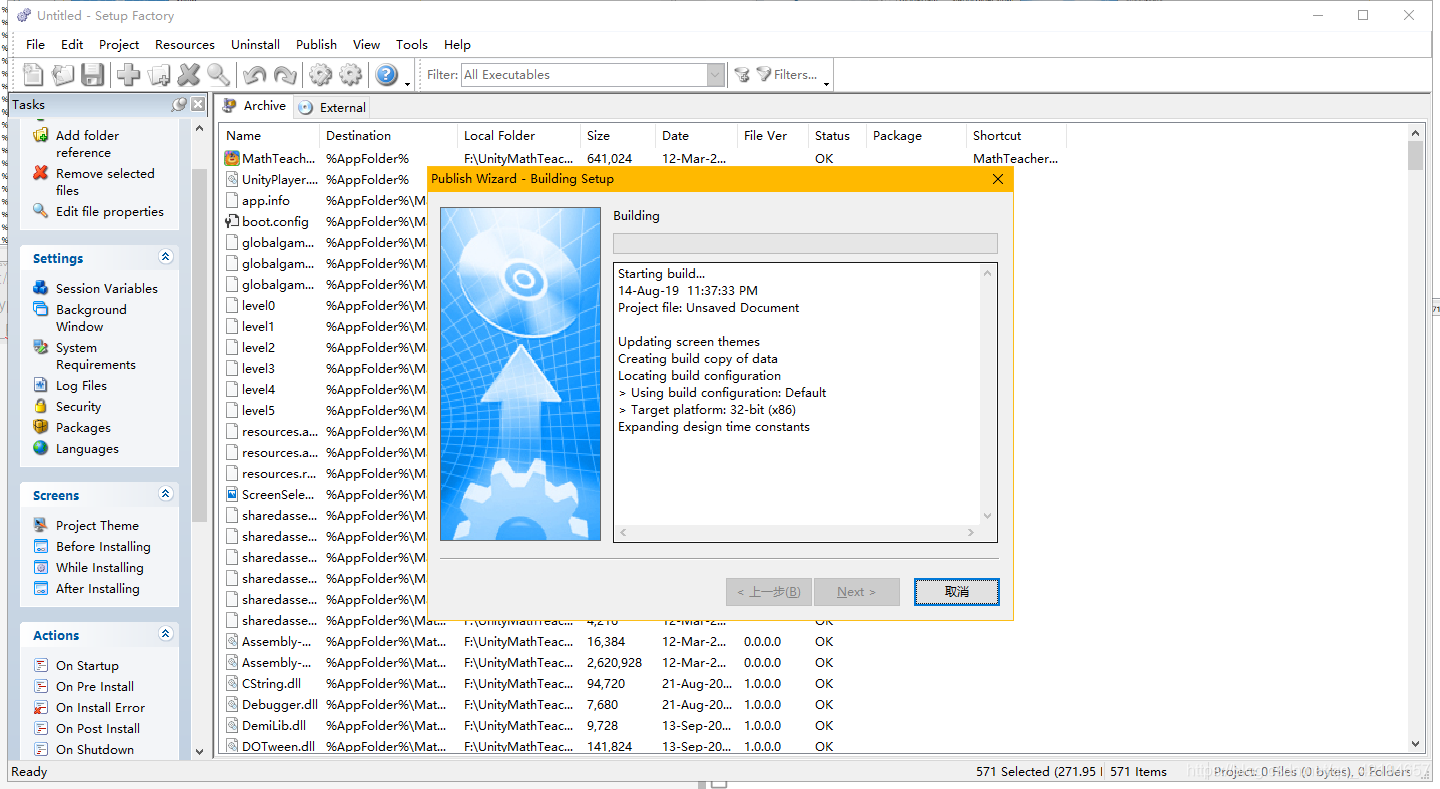
本次搭建使用的是Kafka3.6.1,zookeeper3.9.1。
1、zookeeper集群安装
zookeeper下载:Apache Download Mirrors
1.1、zookeeper解压修改配置文件名
# 1、解压到指定目录
tar -zxvf apache-zookeeper-3.9.1-bin.tar.gz -C /opt/software
# 2、需改配置文件名称
cp zoo_sample.cfg zoo.cfg1.2、zookeeper配置文件详解(zoo.cfg)
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 指定数据保存路径
dataDir=/opt/software/zookeeper3.9.1/data
# 客户端连接的端口
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
# 配置集群信息,格式为:server.myid=ip:数据同步端口:选举端口
server.1=192.168.30.88:2888:3888
server.2=192.168.30.89:2888:3888
server.3=192.168.30.90:2888:38881.3、配置集群myid文件信息
# 1、进入配置的数据目录
cd /opt/software/zookeeper3.9.1/data
# 2、创建myid文件
vim myid # 根据配置文件中的定义的server.myid,分别在对应ip的机器上保存对应数字。
# 例如:192.168.30.88 这台服务器myid文件内容为 1。1.4、配置环境变量
# 1、配置环境变量 vim /etc/profile
export ZOOKEEPER_HOME=/opt/software/zookeeper3.9.1
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# 2、激活环境变量
source /etc/profile1.5、zookeeper集群启动/停止脚本
#! /bin/bash
case $1 in
"start"){for i in "node-1" "node-2" "node-3"doecho " --------启动 $i zookeeper-------"ssh $i "/opt/software/zookeeper3.9.1/bin/zkServer.sh $1"done
};;
"stop"){for i in "node-1" "node-2" "node-3"doecho " --------停止 $i zookeeper-------"ssh $i "/opt/software/zookeeper3.9.1/bin/zkServer.sh $1 "done
};;
"status"){for i in "node-1" "node-2" "node-3"doecho " --------$i zookeeper-------"ssh $i "/opt/software/zookeeper3.9.1/bin/zkServer.sh $1 "done
};;
esac至此,zookeeper集群安装完毕。
2、Kafka集群安装
Kafka下载:Apache Kafka
2.1、Kafka解压安装
# 解压
tar -zxvf kafka_2.13-3.6.1.tgz -C /opt/software2.2、Kafka配置详解(server.properties)
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
# 设置每个Kafka的broker.id,这个号是集群中唯一的
broker.id=0 # 另外节点为 broker.id=1 或 broker.id=2
############################# Socket Server Settings #############################
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
# 指定Kafka数据保存路径
log.dirs=/opt/software/kafka3.6.0/datas
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Retention Policy #############################
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
#log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000############################# Zookeeper #############################
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
# 配置Kafka使用的zookeeper,这里的node-1 ... 是配置在/etc/hosts文件中的IP地址映射的别名
zookeeper.connect=node-1:2181,node-2:2181,node-3:2181/kafka
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=02.3、配置环境变量
# 1、配置环境变量 vim /etc/profile
export KAFKA_HOME=/opt/software/kafka3.6.0
export PATH=$PATH:$KAFKA_HOME/bin
# 2、激活环境变量
source /etc/profile2.4、启动Kafka集群脚本
#! /bin/bash
case $1 in
"start"){for i in "node-1" "node-2" "node-3"doecho " --------启动 $i Kafka-------"# kafka 后台启动ssh $i "/opt/software/kafka3.6.0/bin/kafka-server-start.sh -daemon /opt/software/kafka3.6.0/config/server.properties"done
};;
"stop"){for i in "node-1" "node-2" "node-3"doecho " --------停止 $i Kafka-------"ssh $i "/opt/software/kafka3.6.0/bin/kafka-server-stop.sh "done
};;
esac注:集群启动先启动zookeeper,再启动Kafka;关闭先关闭Kafka,然后关闭zookeeper。
3、注意
以上提到的集群启动脚本命名为 **.sh,如果不能运行,需要添加执行权限:chmod 755 **.sh。
总结:本文详细介绍了zookeeper集群的搭建,以及kafka集群的搭建,以及介绍可能会遇到的坑,在本文的帮助下,按照步骤可以无脑实现kafka集群的搭建。
本人是一个从小白自学计算机技术,对运维、后端、各种中间件技术、大数据等有一定的学习心得,想获取自学总结资料(pdf版本)或者希望共同学习,关注微信公众号:上了年纪的小男孩。后台回复相应技术名称/技术点即可获得。(本人学习宗旨:学会了就要免费分享)