0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习的人体跌倒检测算法研究与实现 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:5分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate

1.前言
人体跌倒是人们日常生活中常见姿态之一,且跌倒的发生具有随机、难以预测的特点;其次,跌倒会给人体造成不同程度的伤害,很多人跌倒后由于得不到及时的救助而加重受到的伤害,甚至出现残疾或者死亡的情况;同时随着人口老龄化问题的日渐加剧,跌倒已经成为了我国65周岁以上老人受伤致死的主要原因。因此,跌倒事件严重影响着人们的身体健康,跌倒检测具有十分重要的研究意义。
2.实现效果
跌倒效果

站立、蹲坐效果

3.相关技术原理
3.1卷积神经网络
简介
CNN 是目前机器用来识别物体的图像处理器。CNN
已成为当今自动驾驶汽车、石油勘探和聚变能研究领域的眼睛。在医学成像方面,它们可以帮助更快速发现疾病并挽救生命。得益于 CNN 和递归神经网络
(RNN),各种 AI 驱动型机器都具备了像我们眼睛一样的能力。经过在深度神经网络领域数十年的发展以及在处理海量数据的 GPU
高性能计算方面的长足进步,大部分 AI 应用都已成为可能。
原理
人工神经网络是一个硬件和/或软件系统,模仿神经元在人类大脑中的运转方式。卷积神经网络 (CNN)
通常会在多个全连接或池化的卷积层中应用多层感知器(对视觉输入内容进行分类的算法)的变体。
CNN
的学习方式与人类相同。人类出生时并不知道猫或鸟长什么样。随着我们长大成熟,我们学到了某些形状和颜色对应某些元素,而这些元素共同构成了一种元素。学习了爪子和喙的样子后,我们就能更好地区分猫和鸟。
神经网络的工作原理基本也是这样。通过处理标记图像的训练集,机器能够学习识别元素,即图像中对象的特征。
CNN
是颇受欢迎的深度学习算法类型之一。卷积是将滤波器应用于输入内容的简单过程,会带来以数值形式表示的激活。通过对图像反复应用同一滤波器,会生成名为特征图的激活图。这表示检测到的特征的位置和强度。
卷积是一种线性运算,需要将一组权重与输入相乘,以生成称为滤波器的二维权重数组。如果调整滤波器以检测输入中的特定特征类型,则在整个输入图像中重复使用该滤波器可以发现图像中任意位置的特征。

关键代码
基于tensorflow的代码实现
import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets('MNIST_data_bak/', one_hot=True)sess = tf.InteractiveSession()# 截断的正太分布噪声,标准差设为0.1def weight_variable(shape):initial = tf.truncated_normal(shape, stddev=0.1)return tf.Variable(initial)def bias_variable(shape):initial = tf.constant(0.1, shape=shape)return tf.Variable(initial)# 卷积层和池化层也是接下来要重复使用的,因此也为它们定义创建函数# tf.nn.conv2d是TensorFlow中的2维卷积函数,参数中x是输入,W是卷积的参数,比如[5, 5, 1, 32]# 前面两个数字代表卷积核的尺寸,第三个数字代表有多少个channel,因为我们只有灰度单色,所以是1,如果是彩色的RGB图片,这里是3# 最后代表核的数量,也就是这个卷积层会提取多少类的特征# Strides代表卷积模板移动的步长,都是1代表会不遗漏地划过图片的每一个点!Padding代表边界的处理方式,这里的SAME代表给# 边界加上Padding让卷积的输出和输入保持同样SAME的尺寸def conv2d(x, W):return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')# tf.nn.max_pool是TensorFlow中的最大池化函数,我们这里使用2*2的最大池化,即将2*2的像素块降为1*1的像素# 最大池化会保留原始像素块中灰度值最高的那一个像素,即保留最显著的特征,因为希望整体上缩小图片尺寸,因此池化层# strides也设为横竖两个方向以2为步长。如果步长还是1,那么我们会得到一个尺寸不变的图片def max_pool_2x2(x):return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')# 因为卷积神经网络会利用到空间结构信息,因此需要将1D的输入向量转为2D的图片结构,即从1*784的形式转为原始的28*28的结构
# 同时因为只有一个颜色通道,故最终尺寸为[-1, 28, 28, 1],前面的-1代表样本数量不固定,最后的1代表颜色通道数量
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1])# 定义我的第一个卷积层,我们先使用前面写好的函数进行参数初始化,包括weights和bias,这里的[5, 5, 1, 32]代表卷积
# 核尺寸为5*5,1个颜色通道,32个不同的卷积核,然后使用conv2d函数进行卷积操作,并加上偏置项,接着再使用ReLU激活函数进行
# 非线性处理,最后,使用最大池化函数max_pool_2*2对卷积的输出结果进行池化操作
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)# 第二层和第一个一样,但是卷积核变成了64
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)# 因为前面经历了两次步长为2*2的最大池化,所以边长已经只有1/4了,图片尺寸由28*28变成了7*7
# 而第二个卷积层的卷积核数量为64,其输出的tensor尺寸即为7*7*64
# 我们使用tf.reshape函数对第二个卷积层的输出tensor进行变形,将其转成1D的向量
# 然后连接一个全连接层,隐含节点为1024,并使用ReLU激活函数
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)# 防止过拟合,使用Dropout层
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)# 接 Softmax分类
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)# 定义损失函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
3.1YOLOV5简介
基于卷积神经网络(convolutional neural network, CNN)的目标检测模型研究可按检测阶段分为两类,一 类 是 基 于 候 选 框
的 两 阶 段 检 测 , R-CNN 、 Fast R-CNN、Faster R-CNN、Mask R-CNN都是基于
目标候选框的两阶段检测方法;另一类是基于免候选框的单阶段检测,SSD、YOLO系列都是典型的基于回归思想的单阶段检测方法。
YOLOv5 目标检测模型 2020年由Ultralytics发布的YOLOv5在网络轻量化 上贡献明显,检测速度更快也更加易于部署。与之前
版本不同,YOLOv5 实现了网络架构的系列化,分别 是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、
YOLOv5x。这5种模型的结构相似,通过改变宽度倍 数(Depth multiple)来改变卷积过程中卷积核的数量, 通 过 改 变 深 度 倍 数
(Width multiple) 来 改 变 BottleneckC3(带3个CBS模块的BottleneckCSP结构)中
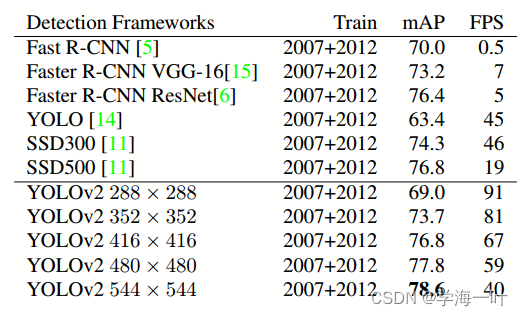
C3的数量,从而实现不同网络深度和不同网络宽度之 间的组合,达到精度与效率的平衡。YOLOv5各版本性能如图所示:

模型结构图如下:

3.2 YOLOv5s 模型算法流程和原理
YOLOv5s模型主要算法工作流程原理:
(1) 原始图像输入部分加入了图像填充、自适应 锚框计算、Mosaic数据增强来对数据进行处理增加了 检测的辨识度和准确度。
(2) 主干网络中采用Focus结构和CSP1_X (X个残差结构) 结构进行特征提取。在特征生成部分, 使用基于SPP优化后的SPPF结构来完成。
(3) 颈部层应用路径聚合网络[22](path-aggregation network, PANet)和CSP2_X进行特征融合。
(4) 使用GIOU_Loss作为损失函数。
关键代码:
4.数据集处理
获取摔倒数据集准备训练,如果没有准备好的数据集,可自己标注,但过程会相对繁琐
深度学习图像标注软件众多,按照不同分类标准有多中类型,本文使用LabelImg单机标注软件进行标注。LabelImg是基于角点的标注方式产生边界框,对图片进行标注得到xml格式的标注文件,由于边界框对检测精度的影响较大因此采用手动标注,并没有使用自动标注软件。
考虑到有的朋友时间不足,博主提供了标注好的数据集和训练好的模型,需要请联系。
3.1 数据标注简介
通过pip指令即可安装
pip install labelimg
在命令行中输入labelimg即可打开

打开你所需要进行标注的文件夹,点击红色框区域进行标注格式切换,我们需要yolo格式,因此切换到yolo
点击Create RectBo -> 拖拽鼠标框选目标 -> 给上标签 -> 点击ok
3.2 数据保存
点击save,保存txt。

5.模型训练
配置超参数
主要是配置data文件夹下的yaml中的数据集位置和种类:

配置模型
这里主要是配置models目录下的模型yaml文件,主要是进去后修改nc这个参数来进行类别的修改。

目前支持的模型种类如下所示:

训练
如果上面的数据集和两个yaml文件的参数都修改好了的话,就可以开始yolov5的训练了。首先我们找到train.py这个py文件。
然后找到主函数的入口,这里面有模型的主要参数。修改train.py中的weights、cfg、data、epochs、batch_size、imgsz、device、workers等参数

至此,就可以运行train.py函数训练自己的模型了。
训练代码成功执行之后会在命令行中输出下列信息,接下来就是安心等待模型训练结束即可。

6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate