资料
- 课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php
- Github:https://github.com/Fafa-DL/Lhy_Machine_Learning
- B站课程:https://space.bilibili.com/253734135/channel/collectiondetail?sid=2014800
一、对Chatgpt的误解
常见误解:
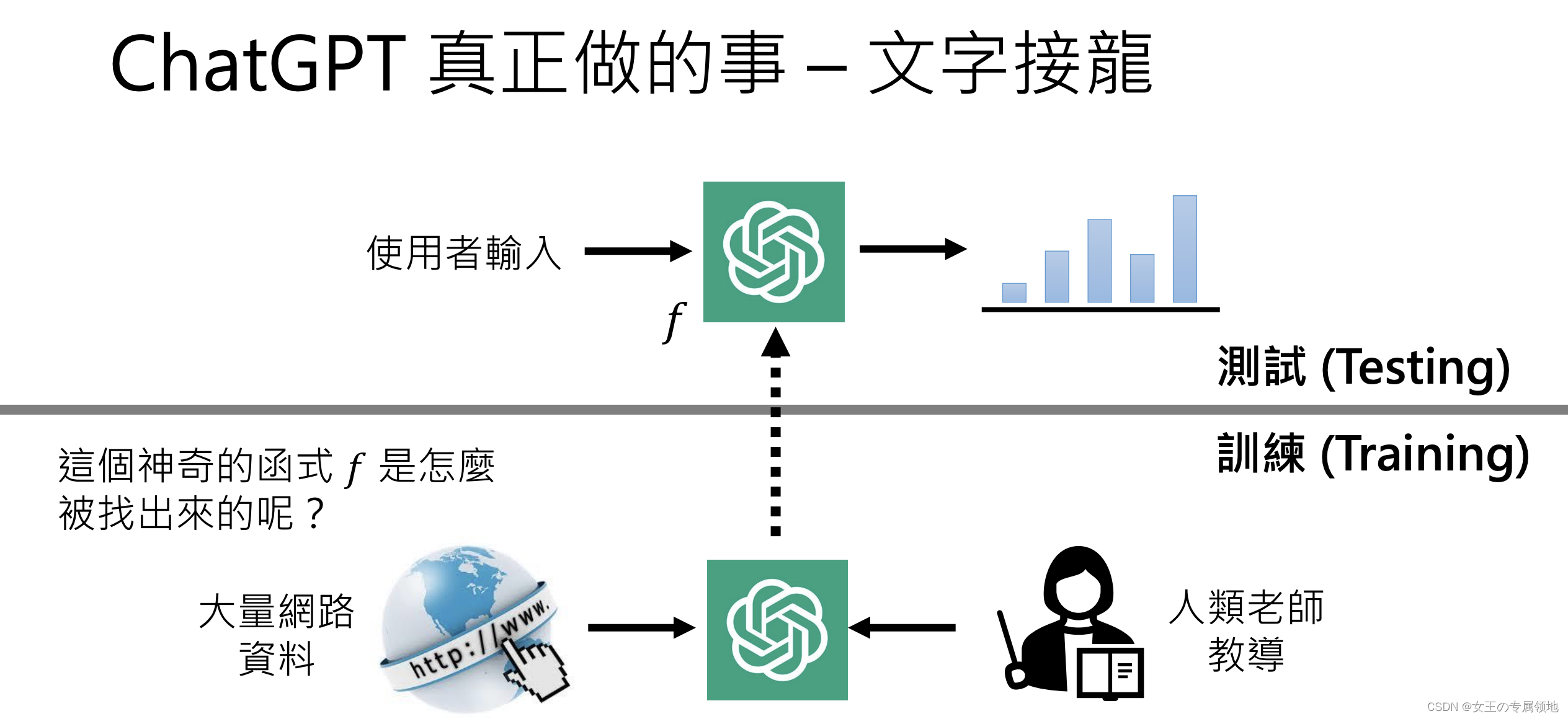
- 给出的回答不是已经准备好的(罐头回应×)
- 不是网络上搜索得出的答案(甚至有很多幻想出来的答案)
原理:
二、预训练
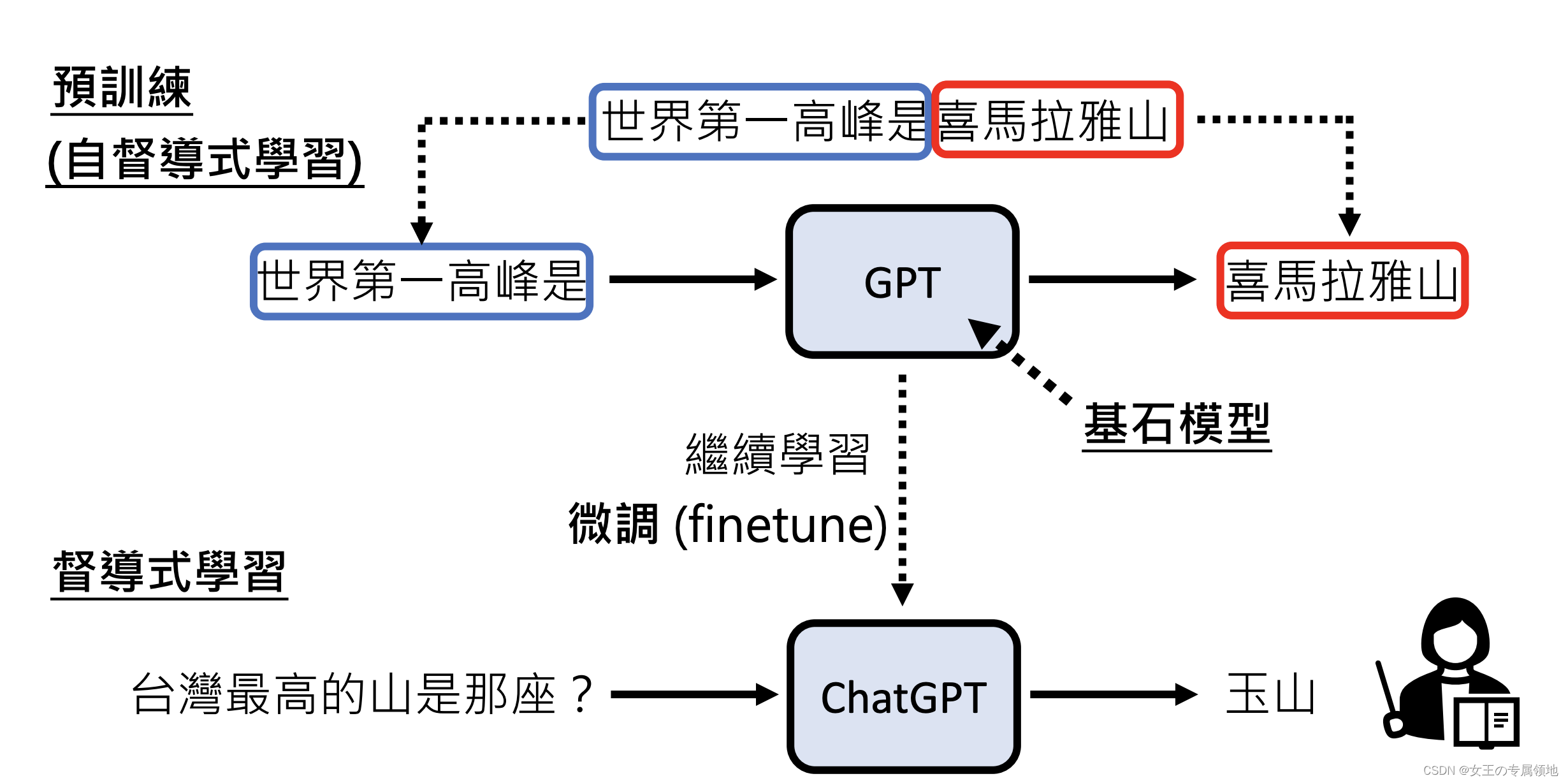
ChatGPT:chat Generative Pre-trained Transformer
关键技术:
- Pre-train(预训练)=Self supervised Leaarning(自督导式学习)
- Foundation Model:基石模型
- Fintune:微调
三、ChatGPT带来的研究问题
- 如何精准提出需求?
目前使用的方法:Prompting
创新点:有没有比人工尝试更加系统性的方法? - 如何更正错误?
目前没有较好的解决方法
创新点:新研究题目Neural Editing - 甄别AI生成的内容
- 泄露秘密、隐私信息
创新点:新的研究题目:Machine Unlearning
四、文字冒险游戏
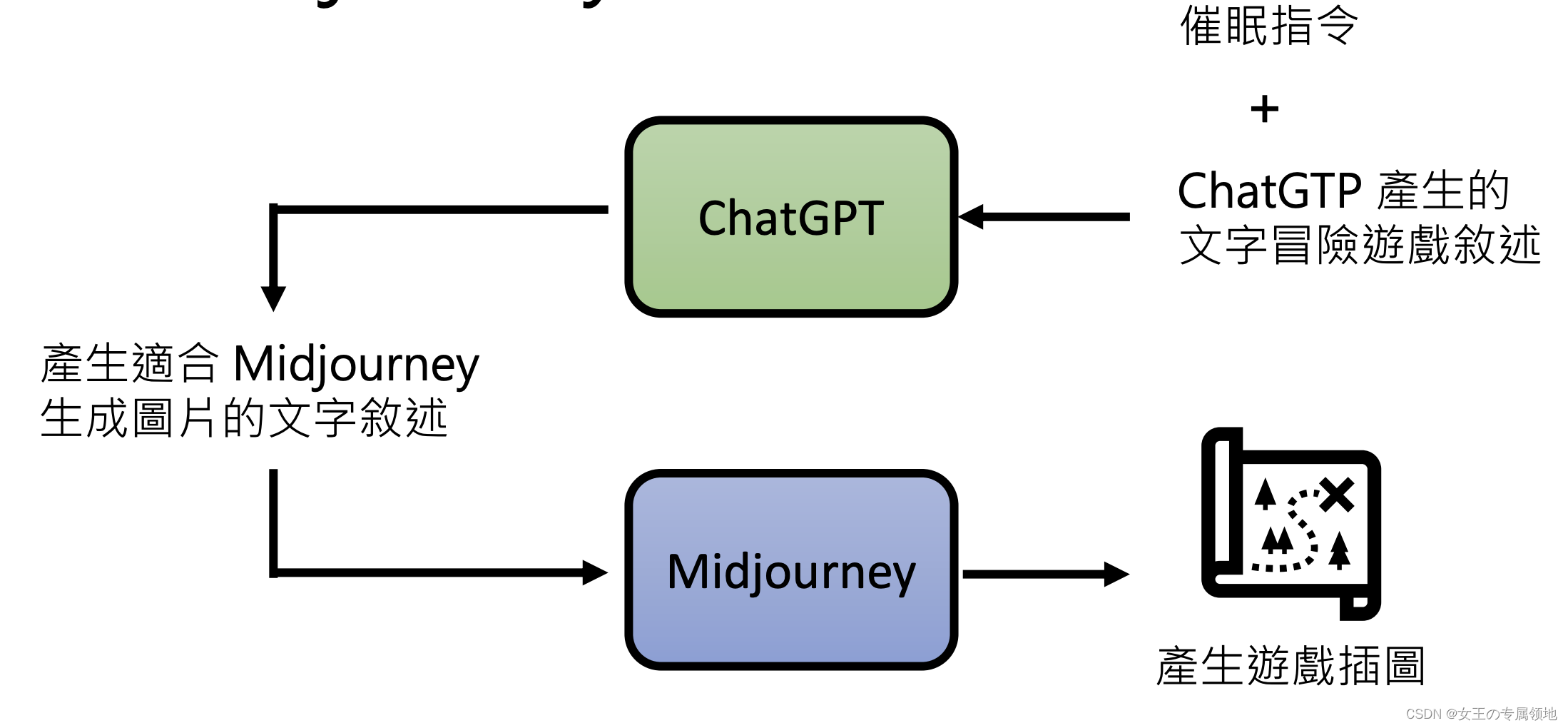
五、ChatGPT是怎么练成的?
ChatGPT的“兄弟”:InstructGPT,论文地址:https://arxiv.org/abs/2203.02155
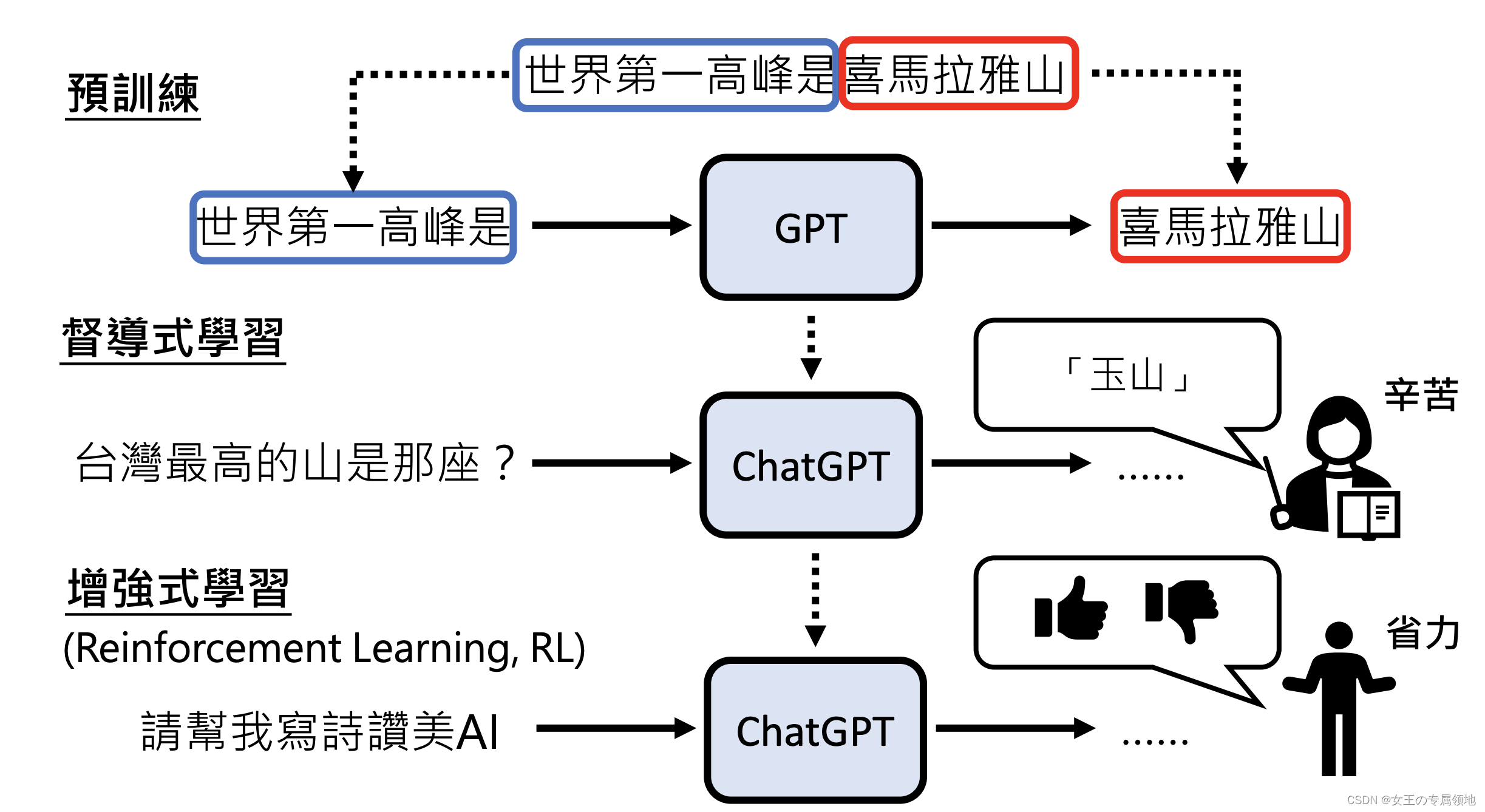
ChatGPT学习四阶段
-
学习文字接龙
不需要人工标注,在网络上收集语句,对输入句子(字)后面可以接的字进行概率统计,每次输出高概率的字(每一次输出都不同) -
人类老师引导文字接龙方向
人来思考问题,并人工提供答案(不需要很多,目的只是为了让GPT知道人们希望得到的答案) -
模仿人类老师的喜好
训练Teacher Model让希望输出的答案的“分数”大于其他输出 -
用增强式学习向模拟老师学习
六、延伸学习
分类
回归