前言
第一次写卷积神经网络,也是照着paddlepaddle的官方文档抄,这里简单讲解一下心得。
首先我们要知道之前写的那些东西都是什么,之前写的我们称之为简单神经网络,也就是简单一层连接输出和输出,通过前向计算和逆向传播,以及梯度下降的方式让结果慢慢滑向我们期望的终点。
这种方法固然好,但是它的限制也是显而易见的:
- 需要我们提供损失函数
- 需要对数据进行相当大量的计算
- 只能处理线性函数,而对非线性的函数处理能力有限
- 只能处理特定问题,扩展性很差
ok为了解决以上的这些问题,人们又研发出了全连接神经网络和卷积神经网络,当然了全连接神经网络作为老黄历,本身在paddle教程中相当于是一个对于卷积神经网络更好的理解的渐进式的介绍,这里也简单聊聊。
我们说的简单神经网络就是直接计算结果,由之前的那种方式去计算线性的方程,然后通过梯度下降的方式让数值自动调参。
那什么是全连接神经模型和卷积神经模型呢?可以参考下面这两个视频,可以让你很简单的对这两个概念有一个印象:
全连接神经模型:【五分钟机器学习】神经网络:一个小人国投票的故事
卷积神经网络: 【五分钟机器学习】什么是卷积神经网络?
全连接模型
简单的来说,全连接神经模型就像是人大代表制度,由底层的神经进行学习并向上一层层传播,比如从群众->村级->县级->市级->省级->国级 层层递进,交由全国人大最终得到议案,也就是我们的结果。
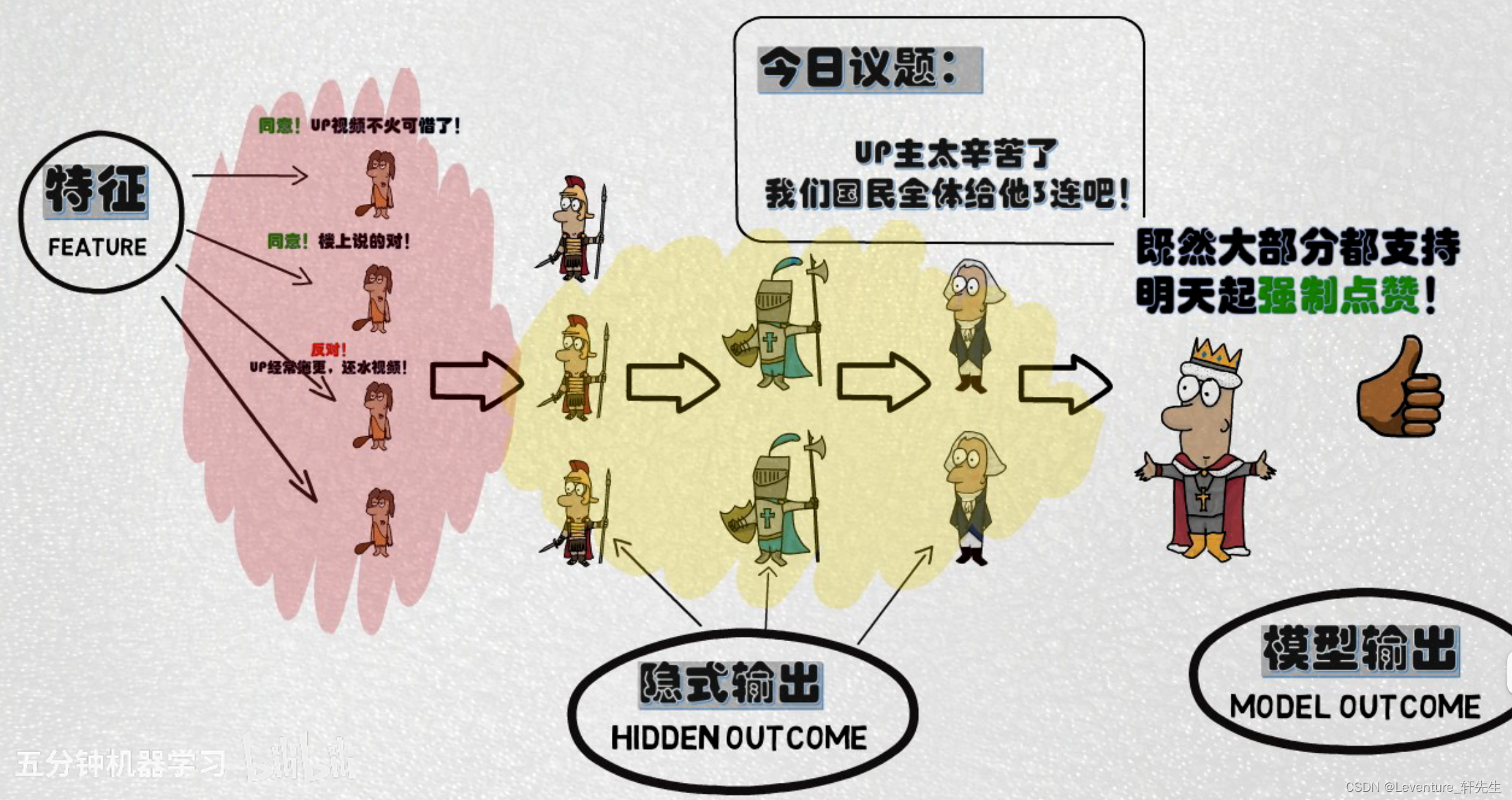
我们一般管输入的学习数据叫 特征(Feature),中间层层递进的信息叫隐式输出(Hidden Outcome),最终由最后一层输出层得到模型输出(Model Outcome)
实际的使用中,随着中间隐式层的不断传递,中间需要慢慢调整的层间权重、模型偏见和激活函数会越来越多,而且每层这些参数造成的影响也会越来越难以估计,实际的工作情况中,我们要做的是通过调整W和B,使得损失函数Loss最小。
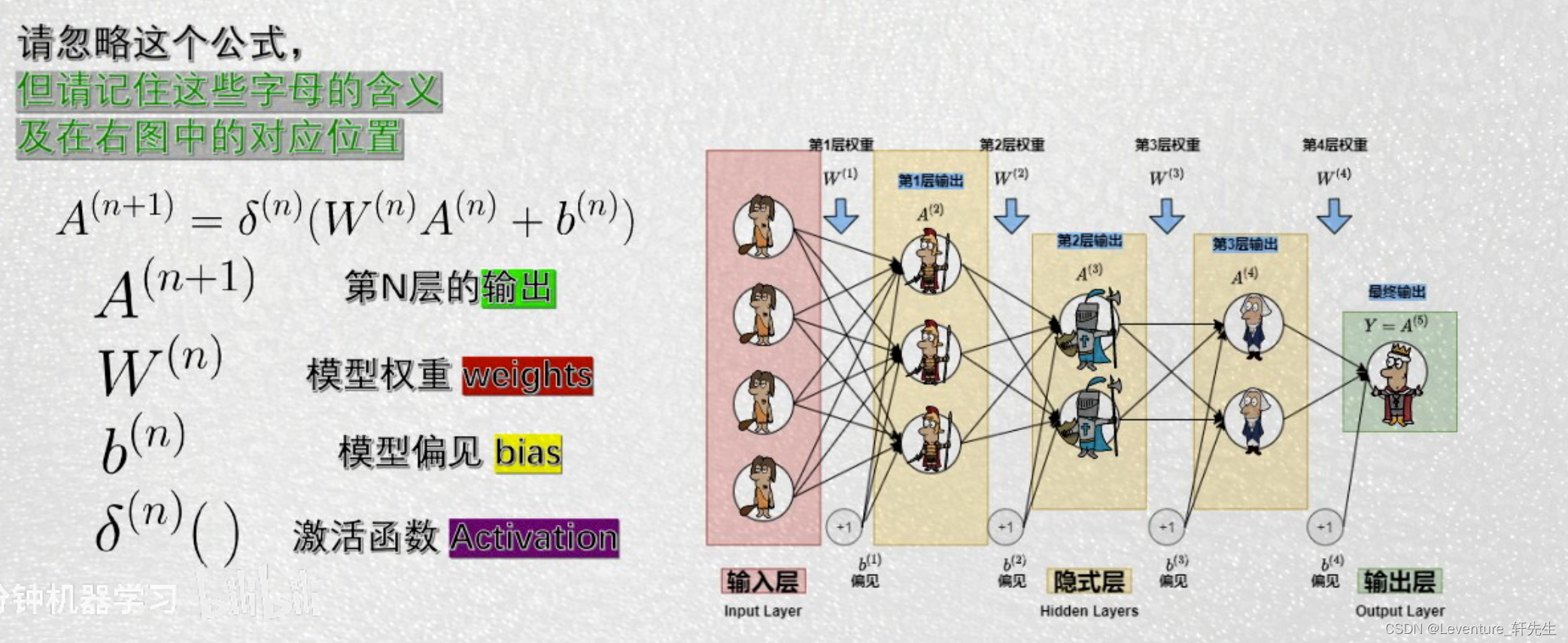
但是问题也随之而来了,这样的模型实际上优缺点也很好看出来
全连接模型:
优点:
1.模型性能出色
2.模型中可用参数多
3.激活函数任意变化,理论上可以兼容任意分布
缺点:
1.参数多意味着训练难,训练慢。
这里说的训练难不是指的代码难写,而是指模型容易过拟合或者欠拟合。而这个缺点是非常致命的。
训练慢指的是每一个村民都需要向每一个村长汇报,这个效率想必不言而喻。
为了解决全连接神经网络的缺点,又同时继承它的优点,于是就有了卷积神经网络。
卷积神经网络CNN
什么是卷积神经网络呢?就是在原有的全连接神经网络中添加两个规则,分别是:
- 权力划分:
在每一层中成立特定部门,接受特定信息。特定的任务只向特定的管理者汇报,这样就可以提高效率。
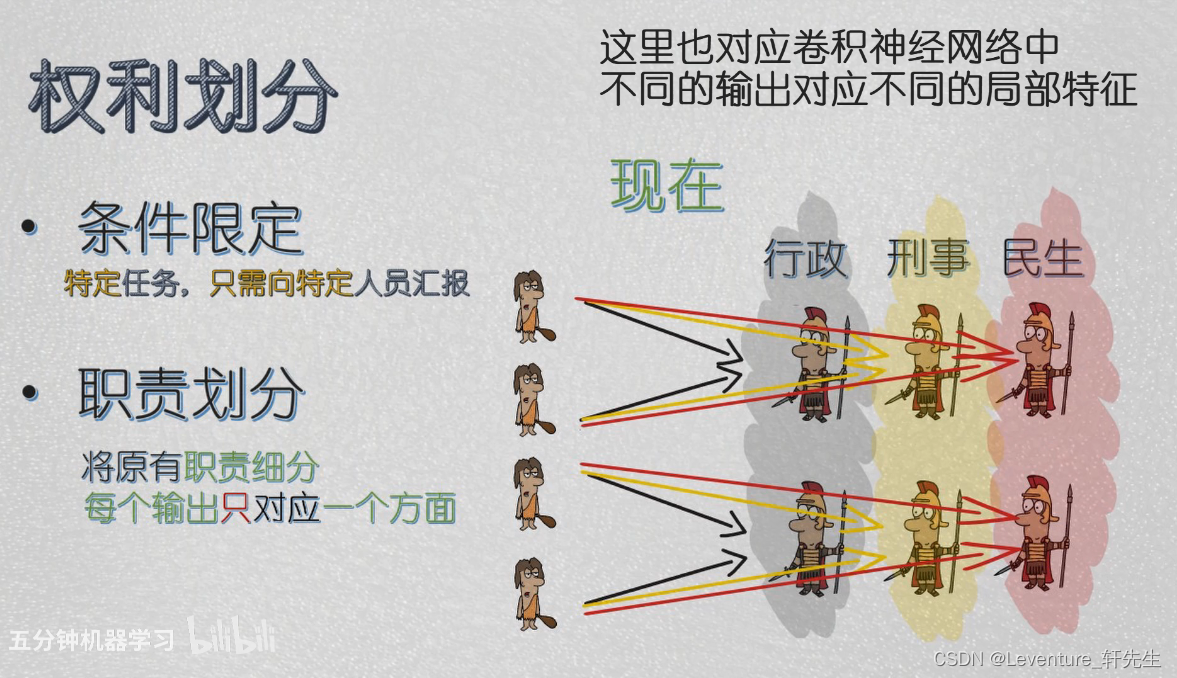
- 规则共享:
在每一层中信息传递的方式需要共享。
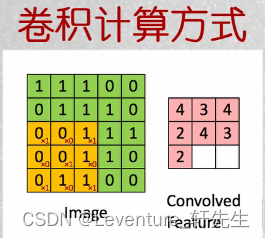
卷积的计算就是类似像素的抽稀算法计算,如图大概是:
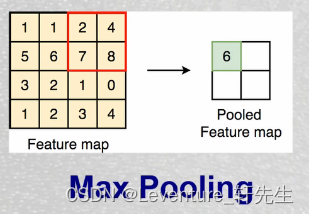
池化则也是一个局部取样的方式,大概如图:
实际代码
在实际开发中,其实现有的框架已经做了绝大多数事了,现在只需要简单改写一下模型即可,我这里直接放完整代码,可以看注释,写的比较详尽了
实际上唯一改动的地方是模型中关于添加了新的卷积层、池化层的定义,以及前向计算的流程。这里并不需要懂太多原理,只需要知道上面视频和图文对卷积神经的大致定义,就能明白为什么代码是这么写的了。其中具体的细节和举证则是选做内容,想知道详情可以深入学习,如果不需要,则随便玩玩即可。
#当然了,简单神经网络没有办法解决我们目前的问题,所以为此要通过别的算法来解决,这个算法就是卷积神经网络#数据处理函数#数据处理部分之前的代码,保持不变
import os
import random
import paddle
import numpy as np
import matplotlib.pyplot as plt
from PIL import Imageimport gzip
import json# 定义数据集读取器
def load_data(mode='train'):# 加载数据datafile = 'mnist.json.gz'print('loading mnist dataset from {} ......'.format(datafile))data = json.load(gzip.open(datafile))print('mnist dataset load done')# 读取到的数据区分训练集,验证集,测试集train_set, val_set, eval_set = data# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLSIMG_ROWS = 28IMG_COLS = 28if mode == 'train':# 获得训练数据集imgs, labels = train_set[0], train_set[1]elif mode == 'valid':# 获得验证数据集imgs, labels = val_set[0], val_set[1]elif mode == 'eval':# 获得测试数据集imgs, labels = eval_set[0], eval_set[1]else:raise Exception("mode can only be one of ['train', 'valid', 'eval']")#校验数据imgs_length = len(imgs)assert len(imgs) == len(labels), \"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(labels))# 定义数据集每个数据的序号, 根据序号读取数据index_list = list(range(imgs_length))# 读入数据时用到的batchsizeBATCHSIZE = 100# 定义数据生成器def data_generator():if mode == 'train':random.shuffle(index_list)imgs_list = []labels_list = []for i in index_list:img = np.array(imgs[i]).astype('float32')label = np.array(labels[i]).astype('float32')# 在使用卷积神经网络结构时,uncomment 下面两行代码img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')label = np.reshape(labels[i], [1]).astype('float32')imgs_list.append(img) labels_list.append(label)if len(imgs_list) == BATCHSIZE:yield np.array(imgs_list), np.array(labels_list)imgs_list = []labels_list = []# 如果剩余数据的数目小于BATCHSIZE,# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batchif len(imgs_list) > 0:yield np.array(imgs_list), np.array(labels_list)return data_generator#输入层:将数据输入给神经网络。在该任务中,输入层的尺度为28×28的像素值。
#隐含层:增加网络深度和复杂度,隐含层的节点数是可以调整的,节点数越多,神经网络表示能力越强,参数量也会增加。
# 在该任务中,中间的两个隐含层为10×10的结构,通常隐含层会比输入层的尺寸小,以便对关键信息做抽象,激活函数使用常见的Sigmoid函数。# 输出层:输出网络计算结果,输出层的节点数是固定的。如果是回归问题,节点数量为需要回归的数字数量。
# 如果是分类问题,则是分类标签的数量。在该任务中,模型的输出是回归一个数字,输出层的尺寸为1。# 隐含层引入非线性激活函数Sigmoid是为了增加神经网络的非线性能力。# 针对手写数字识别的任务,网络层的设计如下:# 输入层的尺度为28×28,但批次计算的时候会统一加1个维度(大小为batch size)。
# 中间的两个隐含层为10×10的结构,激活函数使用常见的Sigmoid函数。
# 即:
# def sigmoid(x):
# # 直接返回sigmoid函数
# return 1. / (1. + np.exp(-x))
# 与房价预测模型一样,模型的输出是回归一个数字,输出层的尺寸设置成1。import paddle.nn.functional as F
from paddle.nn import Linear
from paddle.nn import Conv2D, MaxPool2D, Linear
class MNIST(paddle.nn.Layer):def __init__(self):super(MNIST,self).__init__()#定义卷积层,输出特征通道out_channels设置为 20,卷积核大小kernel_size为5,卷积步长stride=1,padding=2self.conv1 = Conv2D(in_channels=1,out_channels=20,kernel_size=5,stride=1,padding=2)#定义池化层,池化核大小为 kernel_size为2,池化步长为2self.max_pool1=MaxPool2D(kernel_size=2,stride=2)# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2self.conv2 = Conv2D(in_channels=20, out_channels=20, kernel_size=5, stride=1, padding=2)# 定义池化层,池化核的大小kernel_size为2,池化步长为2self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)#定义一层全连接层,输出的维度是1self.fc = Linear(in_features=980,out_features=1)#定义网络的前向计算,隐含层的激活函数为sigmoid,输出层不使用激活函数# 定义网络前向计算过程,卷积后紧接着使用池化层,最后使用全连接层计算最终输出# 卷积层激活函数使用Relu,全连接层不使用激活函数def forward(self,inputs):# inputs = paddle.reshape(inputs, [inputs.shape[0], 784])x = self.conv1(inputs)x = F.relu(x)x = self.max_pool1(x)x = self.conv2(x)x = F.relu(x)x = self.max_pool2(x)x = paddle.reshape(x, [x.shape[0], -1])x = self.fc(x)return x#这样一个卷积神经网络就定义完毕了,接下来我们开始写训练函数,训练函数和之前保持一致#网络结构部分之后的代码,保持不变
def train(model):model.train()#调用加载数据的函数,获得MNIST训练数据集train_loader = load_data('train')# 使用SGD优化器,learning_rate设置为0.01opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())# 训练5轮EPOCH_NUM = 10# MNIST图像高和宽IMG_ROWS, IMG_COLS = 28, 28loss_list = []for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据images, labels = dataimages = paddle.to_tensor(images)labels = paddle.to_tensor(labels)#前向计算的过程predicts = model(images)#计算损失,取一个批次样本损失的平均值loss = F.square_error_cost(predicts, labels)avg_loss = paddle.mean(loss)#每训练200批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:loss = avg_loss.numpy()loss_list.append(loss)print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, loss))#后向传播,更新参数的过程avg_loss.backward()# 最小化loss,更新参数opt.step()# 清除梯度opt.clear_grad()#保存模型参数paddle.save(model.state_dict(), 'mnist.pdparams')return loss_listmodel = MNIST()
loss_list = train(model)def plot(loss_list):plt.figure(figsize=(10,5))freqs = [i for i in range(len(loss_list))]# 绘制训练损失变化曲线plt.plot(freqs, loss_list, color='#e4007f', label="Train loss")# 绘制坐标轴和图例plt.ylabel("loss", fontsize='large')plt.xlabel("freq", fontsize='large')plt.legend(loc='upper right', fontsize='x-large')plt.show()
plot(loss_list)