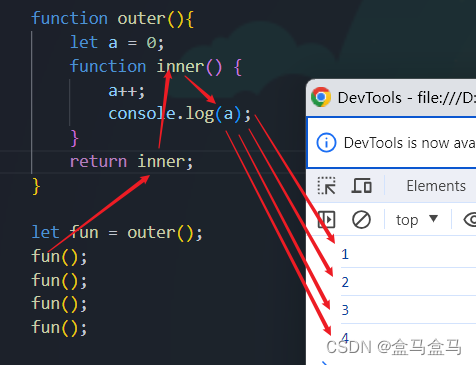
1. 模型架构
提起一个新模型,我想大家最关心的事就是:它到底长什么样?输入输出是什么?我要怎么用?所以,我们先来看模型架构。
1.1 Bert结构
前面说过,VIT几乎和Bert一致,我们来速扫一下Bert模型:
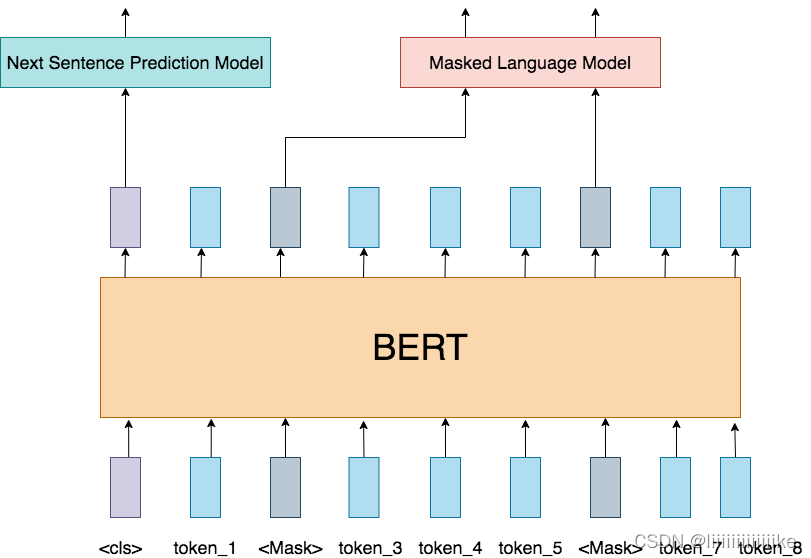
- input:输入是一条文本。文本中的每个词(token)我们都通过embedding把它表示成了向量的形式。
- 训练任务:在Bert中,我们同时做2个训练任务:
- Next Sentence Prediction Model(下一句预测): input中会包含两个句子,这两个句子有50%的概率是真实相连的句子,50%的概率是随机组装在一起的句子。我们在每个input前面增加特殊符,这个位置所在的token将会在训练里不断学习整条文本蕴含的信息。最后它将作为“下一句预测”任务的输入向量,该任务是一个二分类模型,输出结果表示两个句子是否真实相连。
- Masked Language Model(遮蔽词猜测):在input中,我们会以一定概率随机遮盖掉一些token,以此来强迫模型通过Bert中的attention结构更好抽取上下文信息,然后在“遮蔽词猜测”任务重,准确地将被覆盖的词猜测出来。
- Bert模型:Transformer的Encoder层。
1.2 VIT模型结构
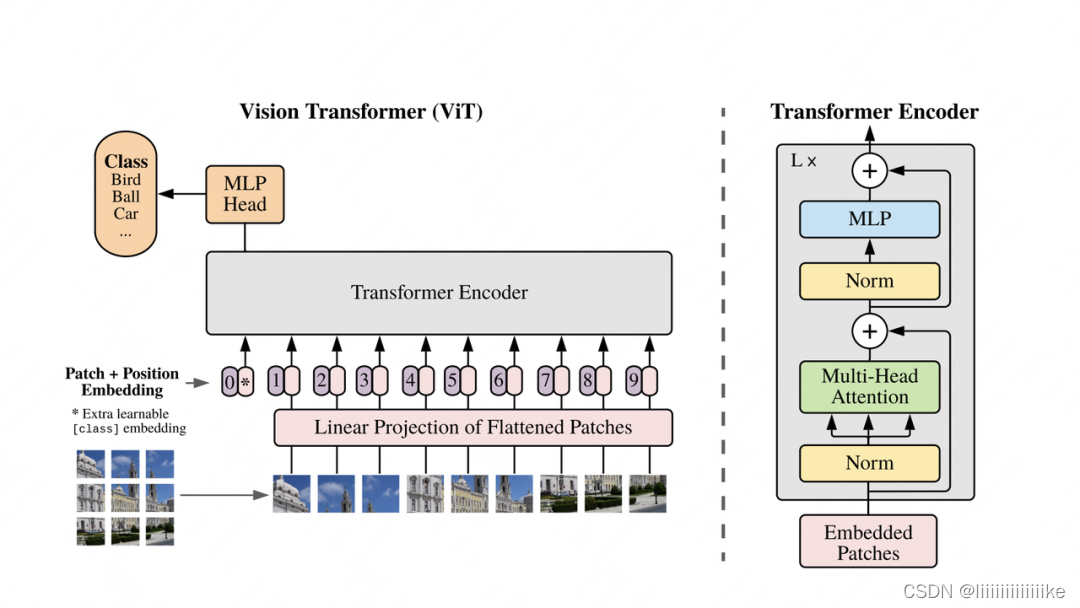
- Patch:对于输入图片,首先将它分成几个patch(例如图中分为9个patch),每个patch就类似于NLP中的一个token(具体如何将patch转变为token向量,在下文会细说)。
- Position Embedding:每个patch的位置向量,用于指示对应patch在原始图片中的位置。和Bert一样,这个位置向量是learnable的,而并非原始Transformer中的函数式位置向量。同样,我们会在下文详细讲解这一块。
- Input: 最终传入模型的Input = patching_emebdding + position embedding,同样,在输入最开始,我们也加一个分类符,在bert中,这个分类符是作为“下一句预测”中的输入,来判断两个句子是否真实相连。在VIT中,这个分类符作为分类任务的输入,来判断原始图片中物体的类别。
总结起来,VIT的训练其实就在做一件事:把图片打成patch,送入Transformer Encoder,然后拿对应位置的向量,过一个简单的softmax多分类模型,去预测原始图片中描绘的物体类别即可。
分类任务仅用一个softmax,准确率能有保证吗?
其实,这就是VIT的精华所在了:VIT的目的不是让这个softmax分类模型强大,而是让这个分类模型的输入强大。这个输入就是Transformer Encoder提炼出来的特征。分类模型越简单,对特征的要求就越高。(基于transformer预训练模型强大的地方,例如预训练模型+不同任务)
2. 从patch到token
讲完了基本框架,我们现在来看细节。首先我们来看看,图片的patch是怎么变成token embedding的。
2.1 patch变token的过程
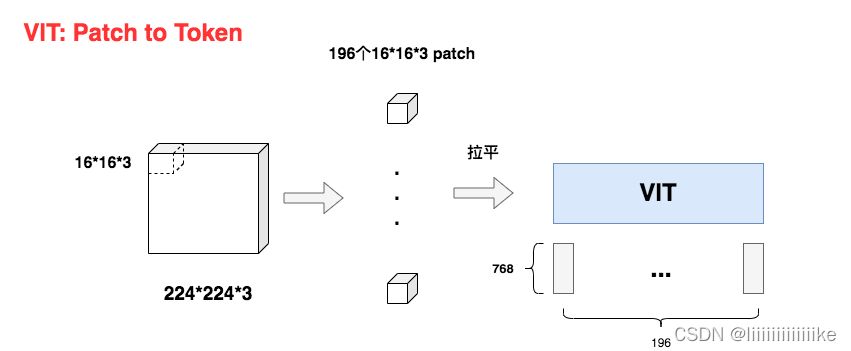
如图,假设原始图片尺寸大小为:224 x 224 x 3 (H * W * C)。现在我们要把它切成小patch,每个patch的尺寸设为16(P=16),则每个patch下图片的大小为16 x 16 x 3。不难看出每个patch对应着一个token,将每个patch展平,则得到输入矩阵X,其大小为(196, 768),也就是每个token是768维。
好,那么现在问题来了,对于图中每一个16 x 16 x 3的小方块,我要怎么把它拉平成1*768维度的向量呢?
比如说,我先把第一个channel拉成一个向量,然后再往后依次接上第二个channel、第三个channel拉平的向量。但这种办法下,同一个pixel本来是三个channel的值共同表达的,现在变成竖直的向量之后,这三个值的距离反而远了。基于这个原因,你可能会想一些别的拉平方式,但归根究底它们都有一个共同的问题:太规则化,太主观。
所以,有办法利用模型来做更好的特征提取吗? 当然没问题。VIT中最终采用CNN进行特征提取,具体方案如下:
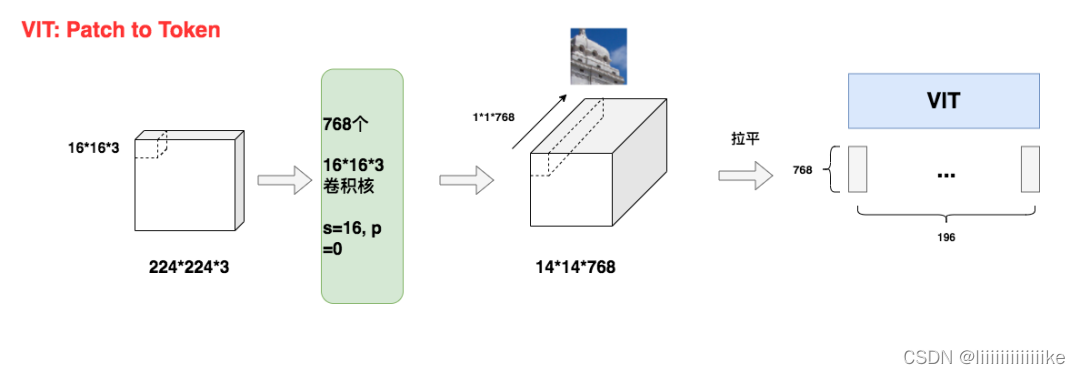
采用768个16 x 16 x 3尺寸的卷积核,stride=16,padding=0。这样我们就能得到14 x 14 x 768大小的特征图。如同所示,特征图中每一个1 x 1 x 768大小的子特征图,都是由卷积核对第一块patch做处理而来,因此它就能表示第一块patch的token向量。
你可能会问,前面不是说VIT已经摆脱CNN了吗?这里怎么又用卷积了? 由于这一步只是输入预处理阶段,和主体模型没有关系,只要将其试为一致特征提取方法即可,并不影响我们之前的结论。
2.2 为什么要处理成patch
- 为了减少模型计算量:,因为在transformer中,计算复杂度和输入序列长度成平方的关系,拆成patch后,计算attention时仅在patch内部做。
- 图像数据带有较多的冗余信息:和语言数据中蕴含的丰富语义不同,像素本身含有大量的冗余信息。比如,相邻的两个像素格子间的取值往往是相似的。因此我们并不需要特别精准的计算粒度(比如把P设为1)。
3. Embedding
3.1 Token Emebdding
由前文知经过patch处理后输入X的形状为(196, 768),则输入X过toke_embedding后的结果为:
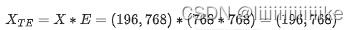
你可能想问,输入X本来就是一个(196,768)的矩阵啊,我为什么还要过一次embedding呢?
这个问题的关键不在于数据的维度,而在于embedding的含义。原始的X仅是由数据预处理而来,和主体模型毫无关系。而token_embedding却参与了主体模型训练中的梯度更新,在使用它之后,能更好地表示出token向量。更进一步,E的维度可以表示成(768, x)的形式,也就是第二维不一定要是768,你可以自由设定词向量的维度。
3.2 Position Embedding(位置向量)
方案一:不添加任何位置信息
将输入视为一堆无序的patch,不往其中添加任何位置向量。
方案二:使用1-D绝对位置编码
也就是我们在上文介绍的方案,这也是VIT最终选定的方案。1-D绝对位置编码又分为函数式(Transformer的三角函数编码,详情可参见这篇文章)和可学习式(Bert采用编码方式),VIT采用的是后者。之所以被称为“绝对位置编码”,是因为位置向量代表的是token的绝对位置信息(例如第1个token,第2个token之类)
方案三:使用2-D绝对位置编码
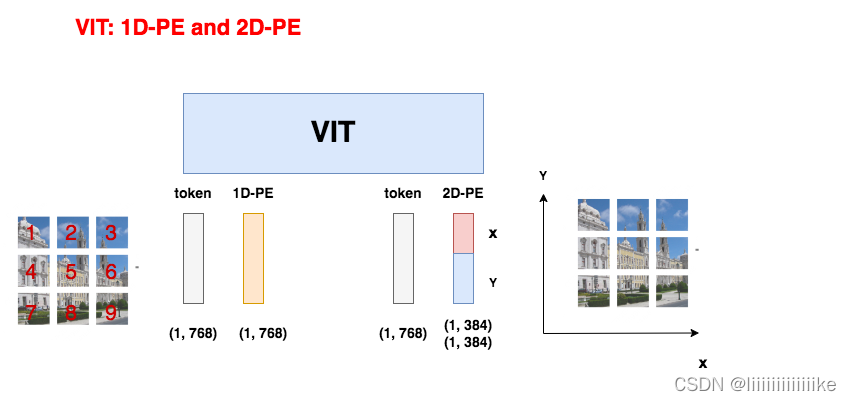
如图所示,因为图像数据的特殊性,在2-D位置编码中,认为按全局绝对位置信息来表示一个patch是不足够的(如左侧所示),一个patch在x轴和y轴上具有不同含义的位置信息(如右侧所示)。因此,2-D位置编码将原来的PE向量拆成两部分来分别训练。
方案四:相对位置编码(relative positional embeddings)
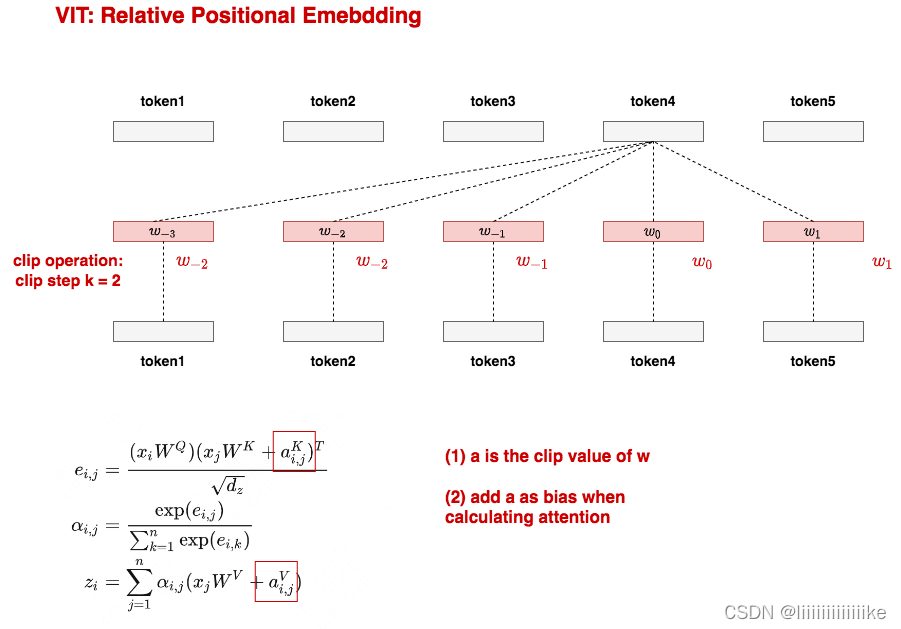
参考原文: https://arxiv.org/pdf/1803.02155.pdf
实验结果:
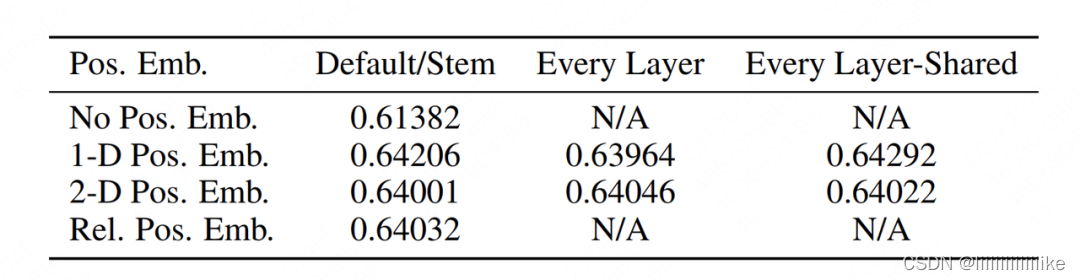
可以发现除了“不加任何位置编码”的效果显著低之外,其余三种方案的结果都差不多。所以作者们当然选择最快捷省力的1-D位置编码方案啦。当你在阅读VIT的论文中,会发现大量的消融实验细节(例如分类头要怎么加),作者这样做的目的也很明确:“我们的方案是在诸多可行的方法中,逐一做实验比对出来的,是全面考虑后的结果。”这也是我一直觉得这篇论文在技术之外值得借鉴和反复读的地方。
4. 模型架构的数学表达
到这一步位置,我们已基本将VIT的模型架构部分讲完了。结合1.2中的模型架构图,我们来用数学语言简练写一下训练中的计算过程:
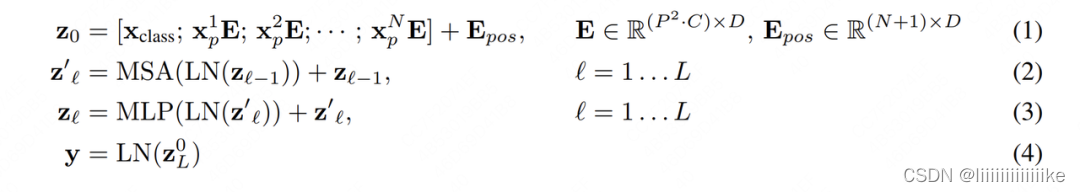

5. VIT的Attention到底看到了什么
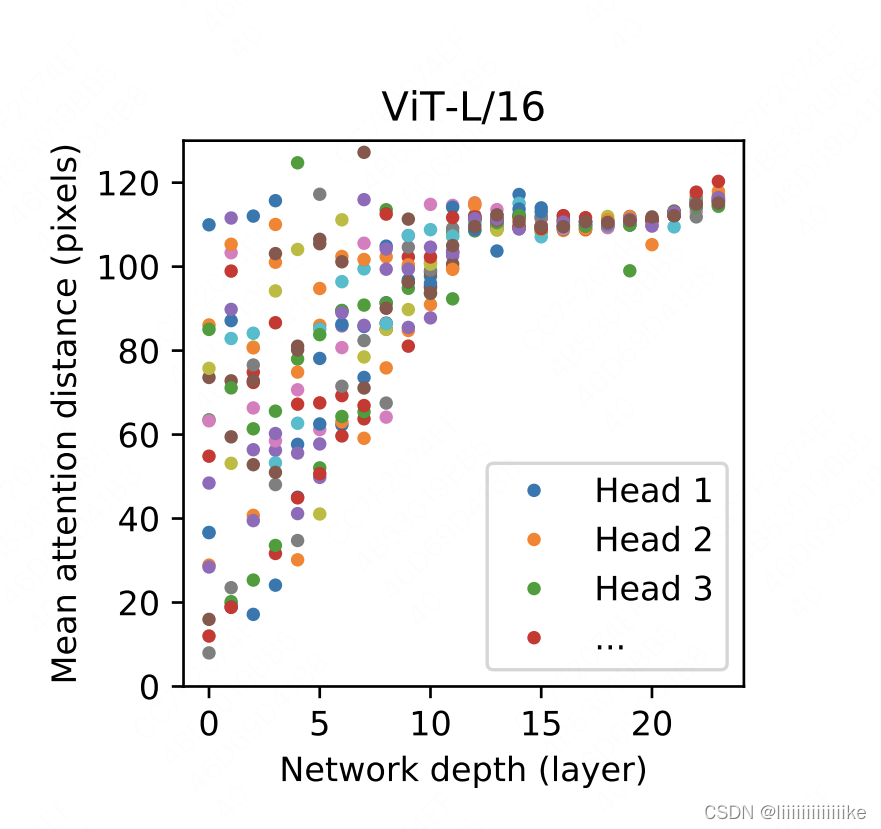
图中每一列上,都有16个彩色原点,它们分别表示16个head观测到的平均像素距离。由图可知,在浅层网络中,VIT还只能关注到距离较近的像素点,随着网络加深,VIT逐渐学会去更远的像素点中寻找相关信息了。这个过程就和用在CNN中用卷积逐层去扩大感受野非常相似。
下图的左侧表示原始的输入图片,右侧表示VIT最后一层看到的图片信息,可以清楚看见,VIT在最后一层已经学到了将注意力放到关键的物体上了,这是非常有趣的结论:

6. VIT的位置编码学到了什么
我们在上文讨论过图像的空间局部性(locality),即有相关性的物体(例如太阳和天空)经常一起出现。CNN采用卷积框取特征的方式,极大程度上维护了这种特性。其实,VIT也有维护这种特性的方法,上面所说的attention是一种,位置编码也是一种。
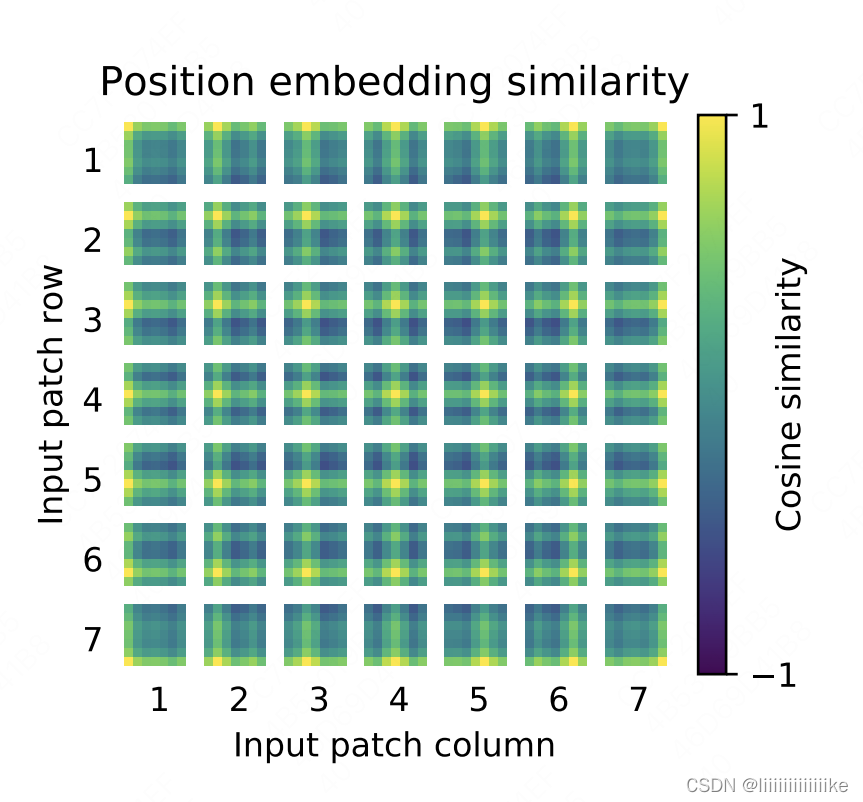
上图是VIT-L/32模型下的位置编码信息,图中每一个方框表示一个patch,图中共有7_7个patch。而每个方框内,也有一个7_7的矩阵,这个矩阵中的每一个值,表示当前patch的position embedding和其余对应位置的position embedding的余弦相似度。颜色越黄,表示越相似,也即patch和对应位置间的patch密切相关。
注意到每个方框中,最黄的点总是当前patch所在位置,这个不难理解,因为自己和自己肯定是最相似的。除此以外颜色较黄的部分都是当前patch所属的行和列,以及以当前patch为中心往外扩散的一小圈。这就说明VIT通过位置编码,已经学到了一定的空间局部性。
7. 总结:VIT的意义何在
一顿读下来,你可能有个印象:如果训练数据量不够多的话,看起来VIT也没比CNN好多少呀,VIT的意义是什么呢?
这是个很好的问题,因为在工业界,人们的标注数据量和算力都是有限的,因此CNN可能还是首要选择。但是,VIT的出现,不仅是用模型效果来考量这么简单,今天再来看这个模型,发现它的意义在于:
- 证明了一个统一框架在不同模态任务上的表现能力。在VIT之前,NLP的SOTA范式被认为是Transformer,而图像的SOTA范式依然是CNN。VIT出现后,证明了用NLP领域的SOTA模型一样能解图像领域的问题,同时在论文中通过丰富的实验,证明了VIT对CNN的替代能力,同时也论证了大规模+大模型在图像领域的涌现能力(论文中没有明确指出这是涌现能力,但通过实验展现了这种趋势)。这也为后续两年多模态任务的发展奠定了基石。
- 虽然VIT只是一个分类任务,但在它提出的几个月之后,立刻就有了用Transformer架构做检测(detection)和分割(segmentation)的模型。而不久之后,GPT式的无监督学习,也在CV届开始火热起来。
- 工业界上,对大部分企业来说,受到训练数据和算力的影响,预训练和微调一个VIT都是困难的,但是这不妨碍直接拿大厂训好的VIT特征做下游任务。同时,低成本的微调方案研究,在今天也层出不穷。长远来看,2年前的这个“庞然大物”,已经在逐步走进千家万户。