前言
(1)如果有嵌入式企业需要招聘湖南区域日常实习生,任何区域的暑假Linux驱动实习岗位,可C站直接私聊,或者邮件:zhangyixu02@gmail.com,此消息至2025年1月1日前均有效
(2)今天在一个交流群看到一个有意思的问题,网友问:开发32位单片机,能够使用unsigned char 就不使用unsigned int,这样是否可以节约内存呢?
(3)当时我看到这个问题是懵的,uint8怎么会比uint32更节省空间呢?
(4)学习本文之前,需要先了解数据的内存分配知识,所以需要各位先了解这篇博客:
RAM明明断电会丢失数据,为什么初始化的全局变量存储在RAM?详细分析程序的存储
网友问题解决思路
(1)首先申明一下这位网友的测试环境,是在STM32F103中进行的相关测试。
问题
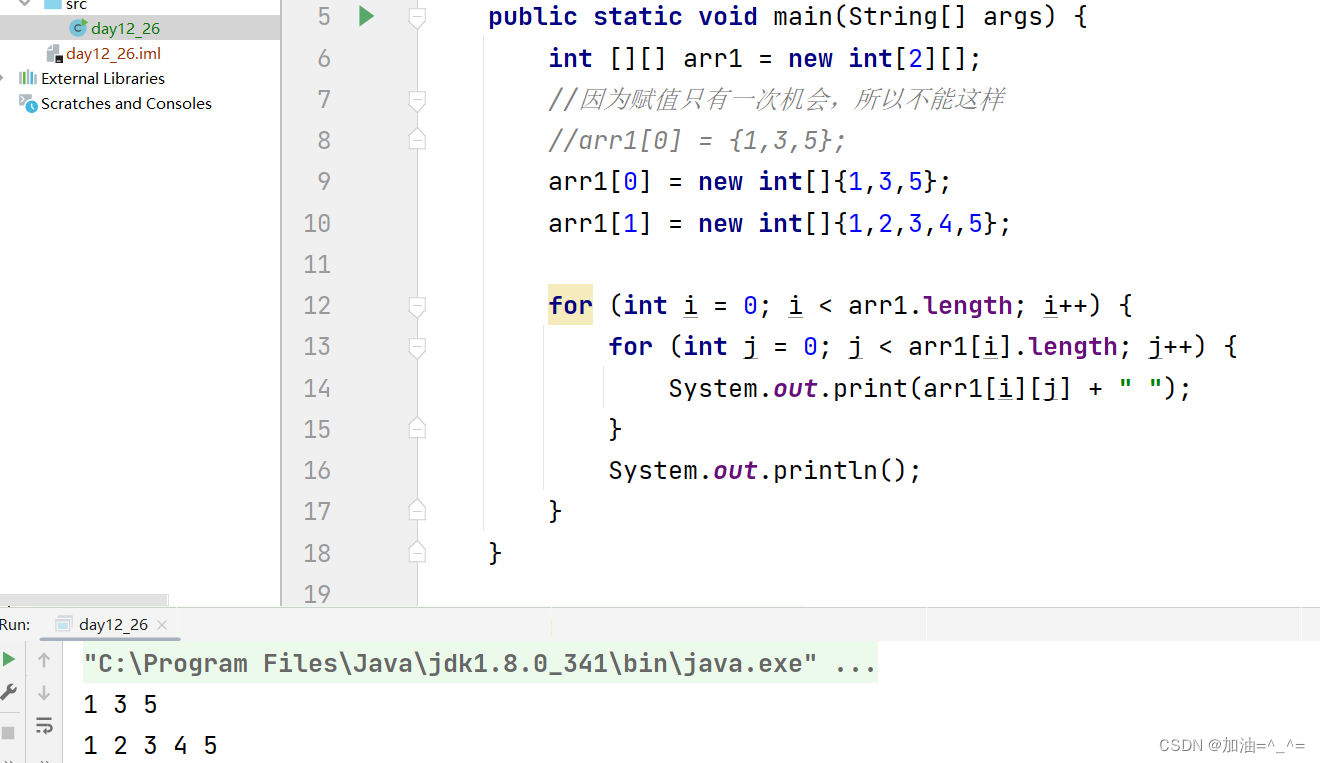
(1)这位网友在测试代码工程的时候,发现将
unsigned char修改为unsigned int的时候,工程代码会减少4字节。

解决思路
(1)对于这个问题,很容易知道大体问题是在哪里。
<1>首先,这个是局部变量,他不会占用实际的空间,因此我们发现,实际变化的内存大小是在code段。
<2>其次,在32位的机器中,CPU寄存器都是32位的,因此在处理数据的时候,低于4字节数据会被提升到4字节再进行处理。
(2)那么,我们就可以大致的推断出,这个地方大概率是需要汇编指令进行字节提升,新增加的汇编指令导致code段增多了。
(3)既然有了上述的基础概念之后,就开始定位问题。
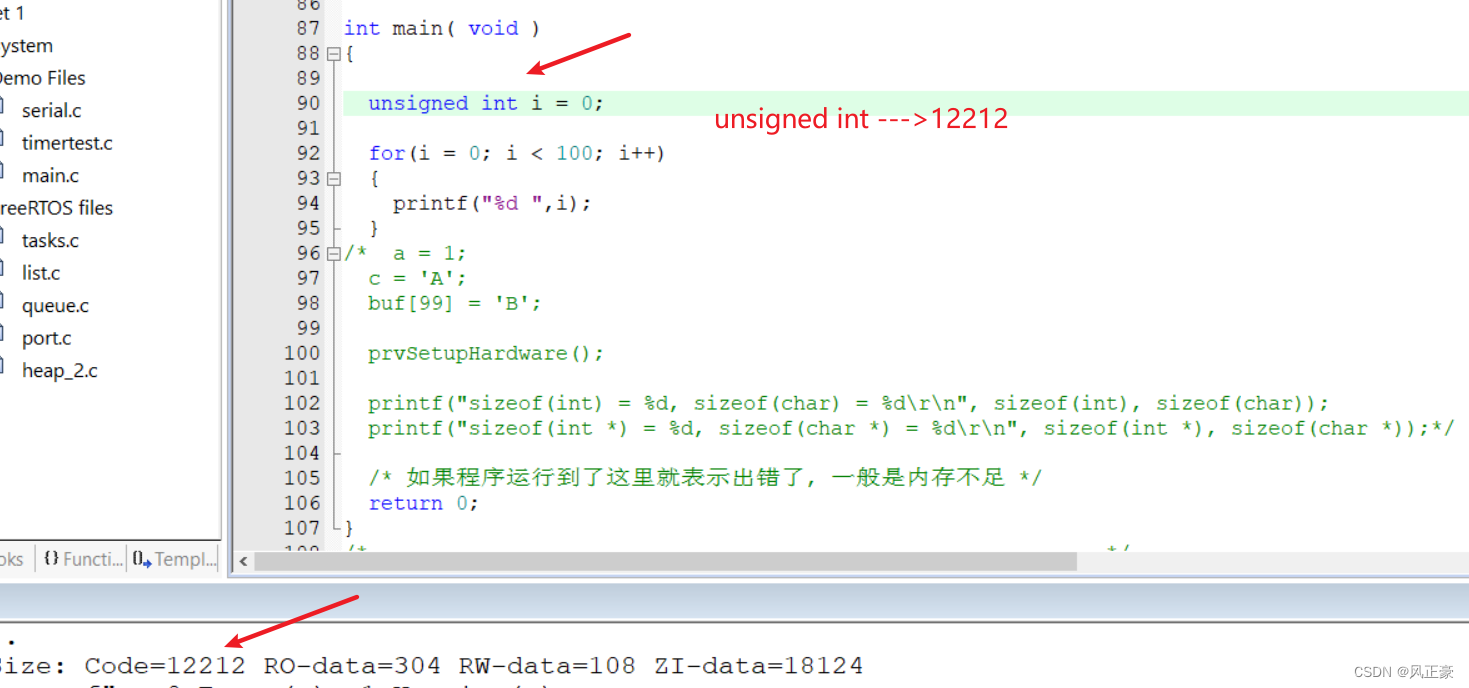
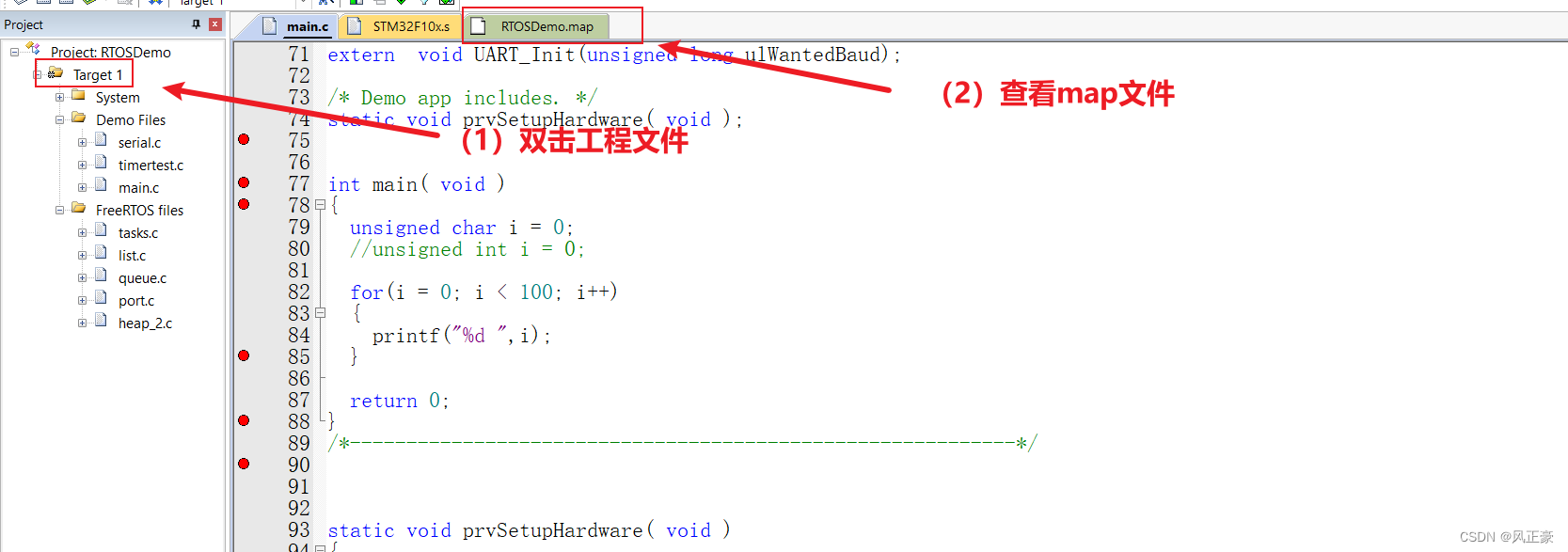
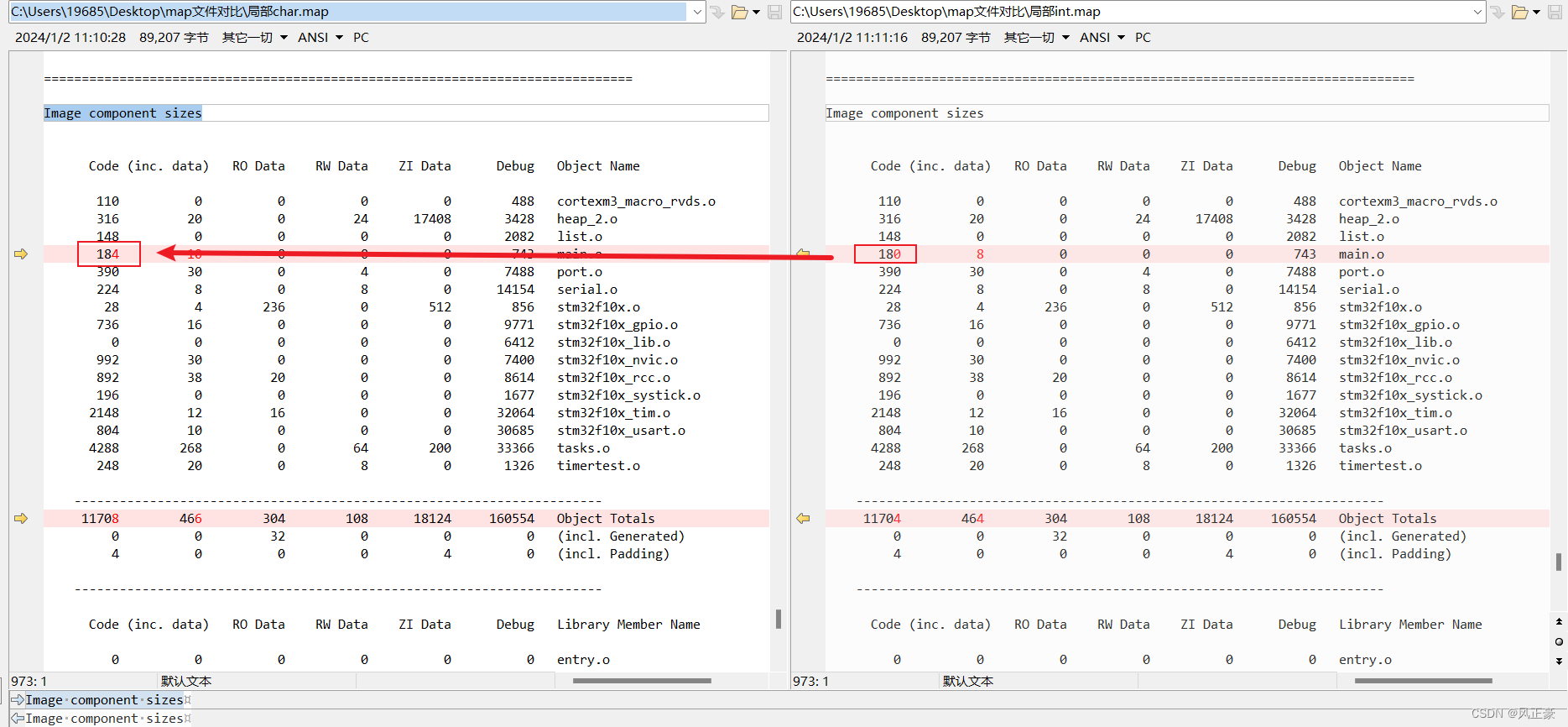
<1>第一步,查看map文件。我们需要知道,这个增加的汇编指令具体是在那个文件中。
<2>对比
uint8和uint32的map文件中Image component sizes部分,我们能够发现,提升的4字节果然是在main.o中,因此此时就知道是在main.c中的在汇编阶段导致的汇编代码不同的问题。
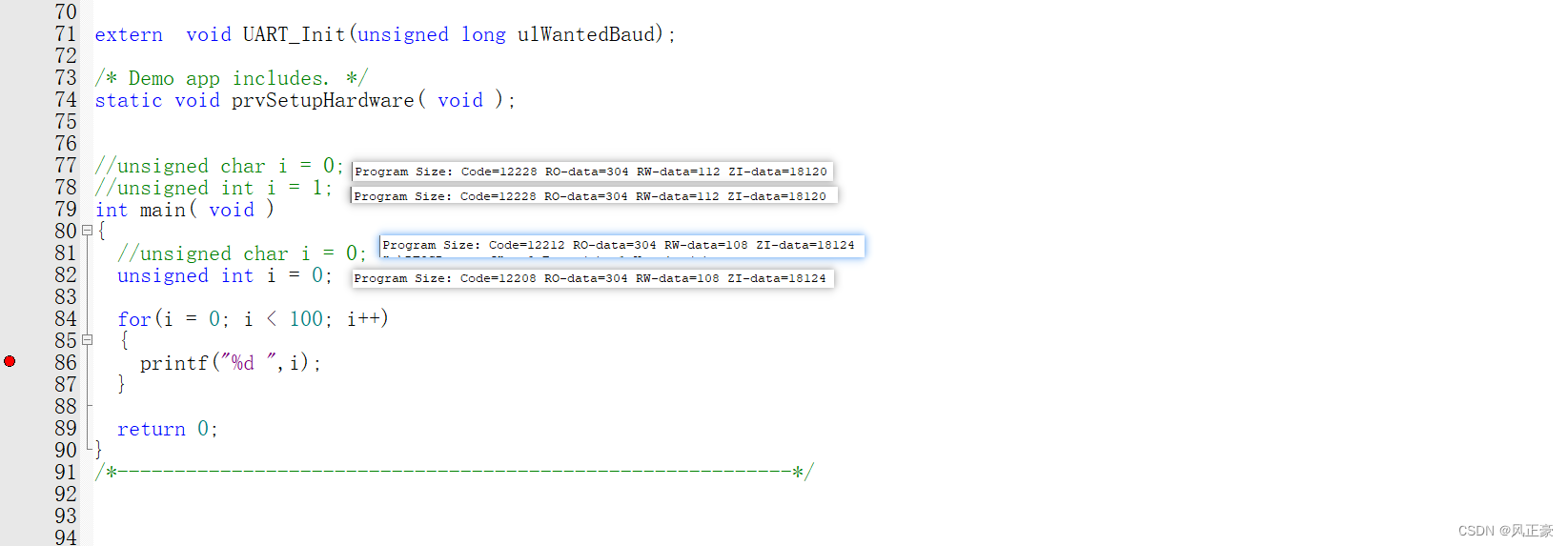
<3>查看汇编,使用keil的Debug功能,能够帮我们看到汇编内容,直接在mian.c中开断点,对比汇编代码。我们能够发现,如果是
uint32,只有一个BCC的指令,但是如果是uint8就是UXTB和BLT。

<4>既然知道的区别之后,开始研读这几条汇编代码,进行对比分析。因为这里是无符号数据的对比,所以说,
BCC和BLT其实是等效的。如果是有符号数据比较,那么就需要使用BLT。(这是arm汇编的内容,简单了解即可,不会的时候查谷歌、百度、chatgpt)
# uint8
UXTB r4 , r0 ;将一个8位无符号字节零扩展为32位无符号整数,高位的24位填充为零
CMP r4 , 0x64 ;将寄存器r4的值和0x64(十进制就是100)对比
BLT 0x0800aA8C ; 如果CMP指令的比较结果是负数(即r4<0x64),则跳转到0x0800aA8C 地址
# uint32
CMP r4 , 0x64 ;将寄存器r4的值和0x64(十进制就是100)对比
BCC 0x0800aA8C ; 如果前一条CMP指令的比较结果没有产生进位(即r4>=0x64),则执行分支
<5>知道汇编代码的大致意思之后,此时就要考虑汇编代码的大小问题。通过询问chatgpt可知,这三条指令都是4字节,因此,当我们main.c中汇编之后多了一条汇编指令,code段就会增加4字节。

扩展测试1
问题
(1)我们发现,上面测试的都是局部变量,我们要不试试全局变量看看结果如何?
(2)我们能够发现两个有意思的问题:
<1>对比两个全局变量,我们会发现,生成的代码一模一样。
<2>对比全局变量和局部变量:code段增加了,rodata不变,rw增加4字节,zi段减少了4字节。(这个我也不会,苦笑。查了很久资料,也调了很久,不知道为啥怎么是这样的结果。应该是工程中某些细节影响,具体细节没排查到)
解决思路
(1)首先我们先看两个全局变量工程怎么会一模一样的。还是直接看map文件,通过对比
map文件知道内存布局信息。
(2)我们能够发现main.o的RW-data确实少了3字节数据,但是呢,在(incl. Padding),RW-data却多了3字节数据。
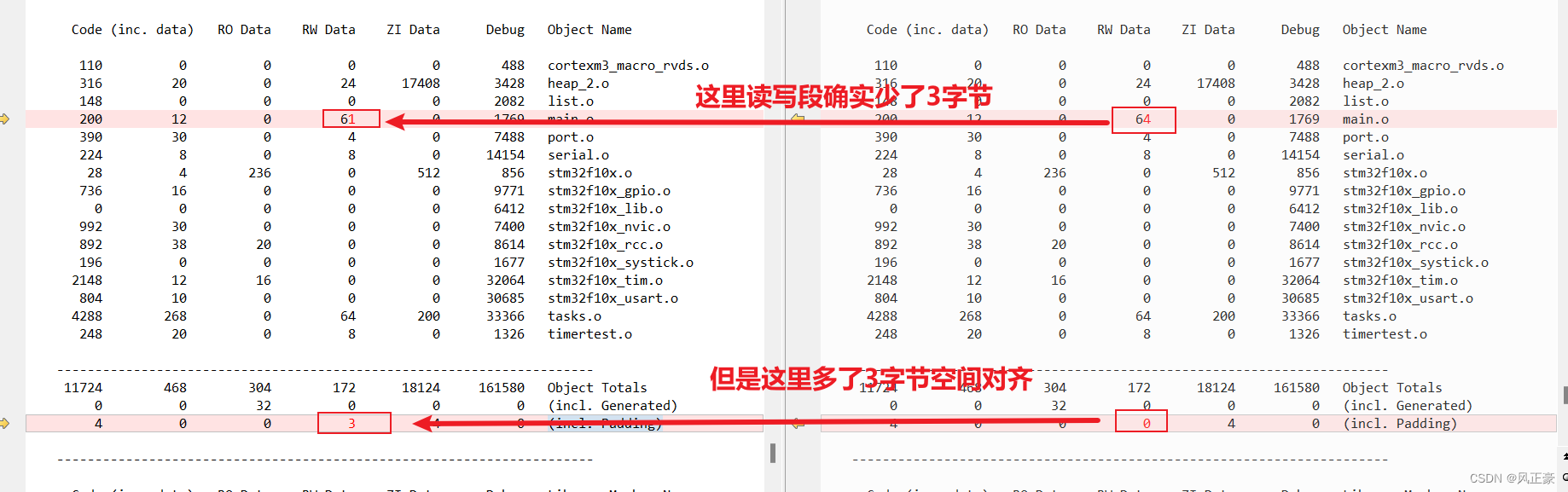
(3)为什么在
(incl. Padding),RW-data却多了3字节数据呢?查阅资料可知,编译器为了满足对齐要求而在数据或代码之间插入额外的填充字节。一般来说,字节对齐只有两种可能:
<1>硬件要求: 许多计算机体系结构对于某些数据类型的访问有硬件对齐的要求。例如,一些处理器可能要求访问特定大小的数据类型的变量时,其地址必须是该数据类型大小的倍数。如果不满足这些要求,可能导致性能下降或者引发硬件异常。如果是采用的冯诺依曼结构,不进行字节对齐,可能导致指令和数据弄混淆。
<2>性能优化: 计算机系统通常会将数据加载到寄存器中进行处理,而寄存器的大小通常是2的幂。如果数据类型的大小是寄存器大小的倍数,那么从内存加载数据到寄存器的操作就更为高效。字节对齐可以确保数据在内存中的地址是寄存器大小的倍数,提高访问速度。
(4)因为这里的测试平台是STM32F103,采用的是CM3内核,因此我打开CM3内核手册可知,寄存器的PUSH和POP永远是4字节对齐的。因此,这里是硬件层面要求进行字节对齐操作。因此,uint8和uint32的全局变量产生的代码工程是一样的效果。

扩展测试2
问题
(1)上面我们发现,uint8和uint32的全局变量结果一模一样。那么我们尝试创建两个全局变量试试呢?
(2)结果发现,RW-data增加了4字节,ZI-data增加4字节。
解决思路
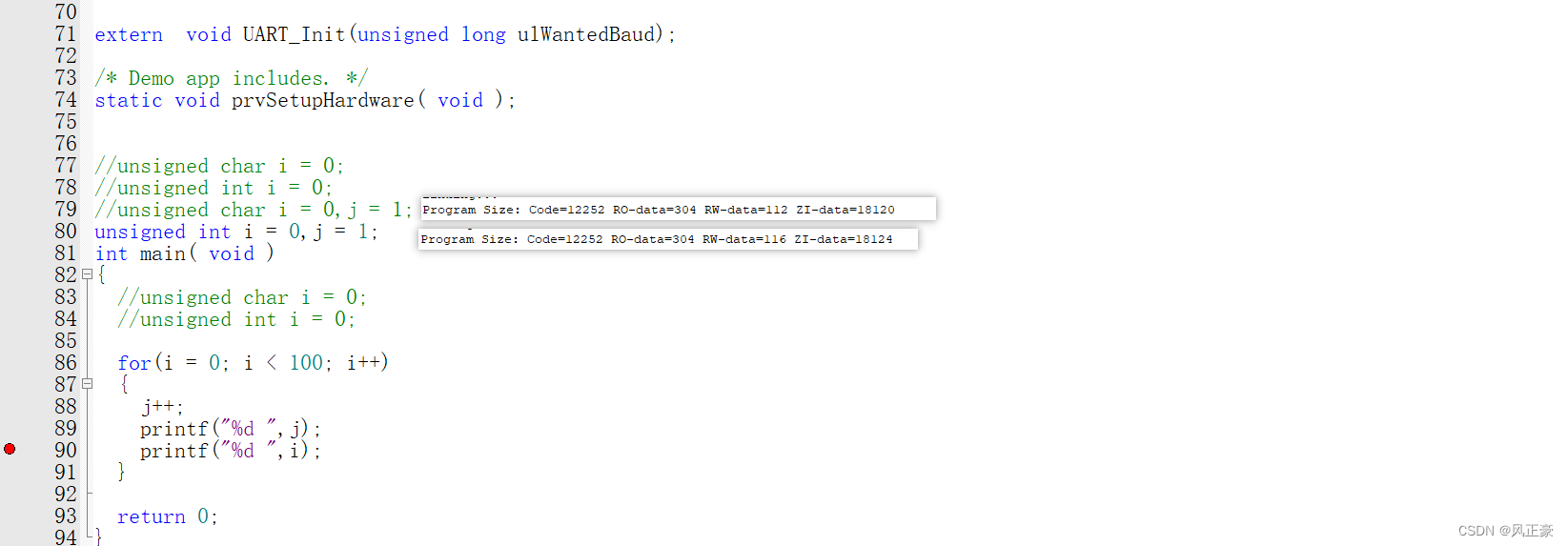
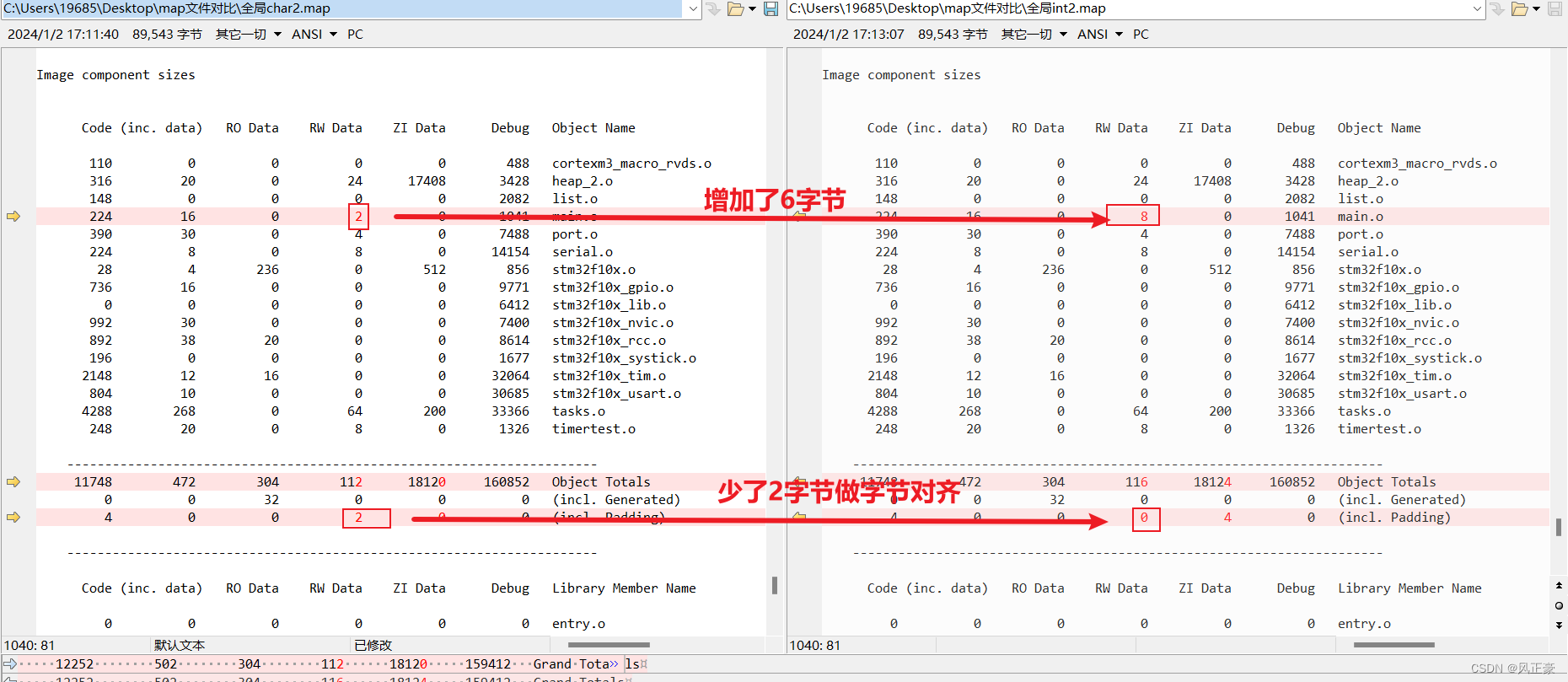
(1)依旧是看
map文件,我们发现main.o的RW-data确实是从2字节变成了8字节,但是同时也少了2字节的字节对齐。因此RW-data是增加了4字节。
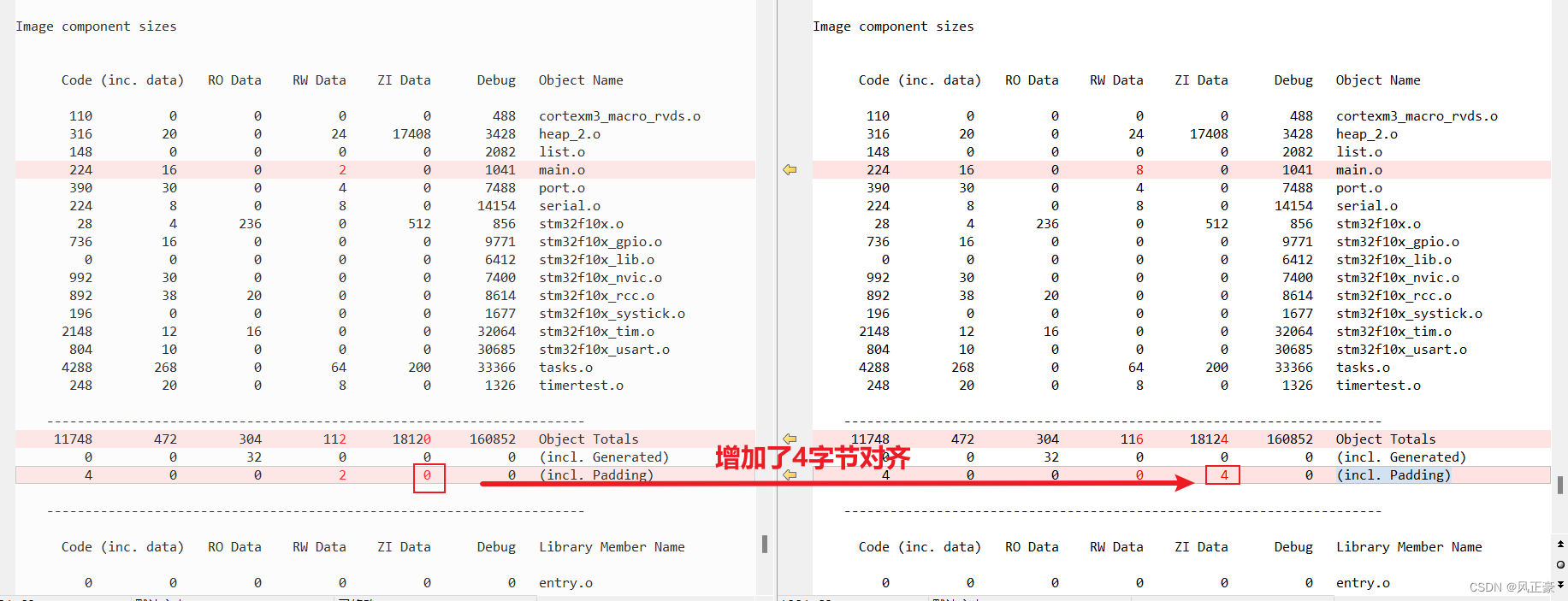
(2)看ZI-data,发现这里会增加4字节对齐,具体原因不清楚
总结
(1)关于
uint8占用空间更多,还是uint32占用空间更多,这个取决于编译器的编译策略,硬件特性,性能优化。我们无法一概而论。正因如此,在目前内存不那么紧张的时代,不要过分的纠结于这个问题。什么时候用那个数据,就用那个,不要抱有心理负担。否则只会适得其反,拖慢研发速度。
参考
(1)CM3权威指南
(2)关于ARM中的tst、cmp、bne、beq指令
(3)用Keil生成bin、汇编、C与汇编混合文件,再也不想debug了!


![[讲座] - 闲聊工业设计](https://img-blog.csdnimg.cn/direct/12be0a3b9cd44e37a19e227c75216cd9.png)