| Leetcod面试经典150题刷题记录-系列 |
|---|
| Leetcod面试经典150题刷题记录——数组 / 字符串篇 |
| Leetcod面试经典150题刷题记录 —— 双指针篇 |
| Leetcod面试经典150题刷题记录 —— 矩阵篇 |
| Leetcod面试经典150题刷题记录 —— 滑动窗口篇 |
| Leetcod面试经典150题刷题记录 —— 哈希表篇 |
| Leetcod面试经典150题刷题记录 —— 区间篇 |
| Leetcod面试经典150题刷题记录——栈篇 |
Leetcod面试经典150题刷题记录 —— 栈篇
- 1. 环形链表
- 1.1 集合法
- 1.2 快慢指针法
- 2. 两数相加
- 2.1原地解法(原创,仍有改进空间,可以取消多次遍历)
- 2.2新建链表空间解法
- 3. 合并两个有序链表
- 3.1 开辟新的链表空间
- 3.2 在原链表空间上直接合并
- 4. 复制带随机指针的链表
- 5. 反转链表 II
- 5.1 前导题(反转链表)
- 5.2 本题解法
- 6. K 个一组翻转链表
- 7. 删除链表的倒数第 N 个结点
- 8. 删除排序链表中的重复元素 II
- 9. 旋转链表
- 10. 分隔链表
- 11. LRU 缓存
1. 环形链表
题目链接:环形链表 - leetcode
题目描述:
给你一个链表的头节点head,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪next指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数pos来表示链表尾连接到链表中的位置(索引从0开始)。注意:pos不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回true。 否则,返回false。
题目归纳:
经典面试题,一定要掌握
解题思路:
解法: 环形链表 - leetcode官方题解
(1) 集合法。把每个访问过的节点,添加到集合中去,如果下一个要访问的节点在集合中出现过,那么说明链表循环了。时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)。
(2) 快慢指针法,我觉得也可以叫套圈法。想象有一个操场,一个人跑得快,一个人跑得慢,不考虑体力消耗,跑得快的人一定会把跑得慢的人套圈,田径比赛中一旦被套圈了,那是神仙也难帮。链表存在环,使用快慢指针求解也是一样的道理。时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1)。
1.1 集合法
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = Noneclass Solution:def hasCycle(self, head: Optional[ListNode]) -> bool:visited_table = set()while head:if head in visited_table: # 访问过,说明链表循环了return Truevisited_table.add(head)head = head.nextreturn False
1.2 快慢指针法
# Definition for singly-linked list# class ListNode:# def __init__(self, x):# self.val = x# self.next = Noneclass Solution:def hasCycle(self, head: Optional[ListNode]) -> bool:if not head or not head.next:return Falseslow = headfast = head.nextwhile slow != fast:if not fast.next or not fast.next.next:return Falseslow = slow.nextfast = fast.next.nextreturn True
2. 两数相加
题目链接:两数相加 - leetcode
题目描述:
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。示例:
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.每个链表中的节点数在范围 [1, 100] 内
0 <= Node.val <= 9
题目数据保证列表表示的数字不含前导零题目归纳:
考察的是:新建一个链表,手动实现进位。
解题思路:
解法: 两数相加 - leetcode官方题解
(1)原地解法。把值都加到长度更长的那条链表上去
(2)新建链表法。
2.1原地解法(原创,仍有改进空间,可以取消多次遍历)
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def addTwoLinkTogether(self, l1: Optional[ListNode], l2: Optional[ListNode]):# 默认len(l1) > len(l2),将l2加到l1身上去p1 = l1p2 = l2carry = 0remain = 0while p1 and p2:res = (p1.val + carry) + p2.valcarry = int(res//10) # 进位remain = res % 10 # 余数# 更新p1.val = remain# 继续往后走pre = p1p1 = p1.nextp2 = p2.next# 满足下面的条件,说明末尾还有进位,需要新建节点if carry > 0 and not p1:pre.next = ListNode(carry)# 现在的情况:# (1)p1和p2均空# (2)p2为空,p1还有剩余。因为默认len1 > len2while p1 != None:res = (p1.val + carry)carry = int(res//10) # 进位remain = res % 10 # 余数# 更新p1.val = remain# 继续往后走pre = p1p1 = p1.next# 满足下面的条件,说明末尾还有进位,需要新建节点if carry > 0 and not p1:pre.next = ListNode(carry)return l1def get_len_of_two_links(self, l1: Optional[ListNode], l2: Optional[ListNode]): # 这会开辟新的空间吗?不会,是地址传递,所以要额外的用p1,p2指针len1 = 0len2 = 0p1 = l1p2 = l2while p1:len1 += 1p1 = p1.nextwhile p2:len2 += 1p2 = p2.nextreturn [len1, len2]def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:# 原地解法,操作长度更长的那条链表len1, len2 = self.get_len_of_two_links(l1, l2)dum_head = ListNode(-1)if len1 > len2:dum_head.next = self.addTwoLinkTogether(l1, l2) # 返回相加后得到的head节点 else:dum_head.next = self.addTwoLinkTogether(l2, l1)return dum_head.next
2.2新建链表空间解法
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:# 由于输入的两个链表,都是逆序存储数字位数的,因此两个链表中的同一位置的数字可以直接相加# 同时遍历两个链表,逐位计算它们的和,并与当前位置的进位值相加。# 具体的,若当前两个链表处所处相应位置的数字为n1,n2,进位值为carry,则它们的和为 n1 + n2 + carry# 其中,答案链表处相应的位置数字为 (n1 + n2 + carry) % 10,新的进位值为 int((n1 + n2 + carry) // 10)# 若两个链表长度不同,可以认为长度短的链表,后面有若干个0# 若链表遍历结束后,有carry > 0,需在答案链表后,附加一个新节点,值为carryhead, tail = None, Nonecarry = 0n1, n2 = 0, 0while l1 != None or l2 != None: # 遍历链表if l1 != None: n1 = l1.val else: n1 = 0if l2 != None: n2 = l2.valelse: n2 = 0Sum = n1 + n2 + carry if not head:head = ListNode(Sum % 10) tail = headelse:tail.next = ListNode(Sum % 10)tail = tail.nextcarry = int(Sum // 10) # 进位值if l1 != None: l1 = l1.next # 继续遍历if l2 != None: l2 = l2.nextif carry > 0: # 出l1,l2链表后,仍存在进位值,还需要新创建一个节点tail.next = ListNode(carry)return head
3. 合并两个有序链表
题目链接:合并两个有序链表 - leetcode
题目描述:
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]题目归纳:
解题思路:
解法: 合并两个有序链表 - leetcode官方题解
(1)开辟新的链表空间
(2)在原链表空间上直接合并
3.1 开辟新的链表空间
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:prehead = ListNode(-1) # 伪头部节点,初始化用-1prev = preheadwhile list1 and list2:if list1.val <= list2.val:prev.next = ListNode(list1.val)prev = prev.nextlist1 = list1.nextelse:prev.next = ListNode(list2.val)prev = prev.nextlist2 = list2.next# list1,list2最多还有一个未被合并完while list1:prev.next = ListNode(list1.val)prev = prev.nextlist1 = list1.nextwhile list2:prev.next = ListNode(list2.val)prev = prev.nextlist2 = list2.nextreturn prehead.next
3.2 在原链表空间上直接合并
受上一题的启发,可以在原链表空间上直接合并,不需要开辟新的链表空间
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:# dum_head = ListNode(-1) # 伪头结点tail = dum_headwhile list1 and list2:if list1.val <= list2.val: # 按升序排列,存较小的值tail.next = list1list1 = list1.nextelse:tail.next = list2list2 = list2.nexttail = tail.nextif list1:tail.next = list1elif list2:tail.next = list2return dum_head.next # 伪头结点.next 才是链表的真正开端
4. 复制带随机指针的链表
题目链接:复制带随机指针的链表 - leetcode
题目描述:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。
题目归纳:
手动实现深拷贝。
解题思路:
解法: 复制带随机指针的链表 - leetcode官方题解
"""
# Definition for a Node.
class Node:def __init__(self, x: int, next: 'Node' = None, random: 'Node' = None):self.val = int(x)self.next = nextself.random = random
"""class Solution:def copyRandomList(self, head: 'Optional[Node]') -> 'Optional[Node]':# 一个链表,长度为n,每个节点包含一个额外增加的随机指针random,该random指针可以指向链表中的任何节点或空节点。# 请构造这个链表的深拷贝。深拷贝应,正好由n个全新节点组成,其中,每个新节点的值都设置为对应的原节点的值# 新节点的next和random也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能表示相同的链表状态。# 最后,返回复制链表的头节点。# 三次遍历if not head:return None# (1)遍历,以 A -> B -> C 为基础构造 A -> A' -> B -> B' -> C -> C'node = headwhile node:nodeNew = Node(node.val)nodeNew.next = node.nextnode.next = nodeNewnode = nodeNew.next# (2)遍历,复制random随机节点的信息node = headwhile node:nodeNew = node.nextif node.random:nodeNew.random = node.random.next # node.random.next是其自身的nodeNew节点else:nodeNew.random = Nonenode = nodeNew.next# (3)遍历,拆分node和nodeNewheadNew = head.nextnode = headwhile node:nodeNew = node.nextnode.next = node.next.next # A->A'->B 变为 A->Bif nodeNew.next:nodeNew.next = nodeNew.next.nextelse:nodeNew.next = Nonenode = node.next # A->B. node从此刻的A变为Breturn headNew
5. 反转链表 II
5.1 前导题(反转链表)
题目链接:反转链表 - leetcode
题目描述:
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
题目归纳:
解题思路:
解法: 反转链表 - leetcode官方题解
完成链表反转共需三步:
(1)暂存。暂存下一个节点信息,以免被反转过程丢失。
(2)反转。
(3)后移。继续反转下一个节点
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:prev = Nonecurr = headwhile curr:# 暂存next_node = curr.next# ***反转***curr.next = prev # 后移prev = curr curr = next_node return prev
5.2 本题解法
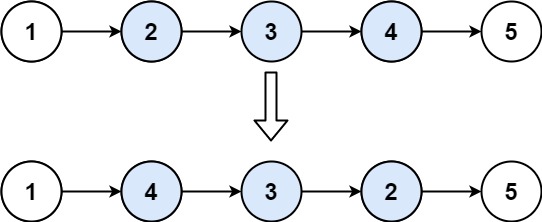
题目链接:反转链表 II - leetcode
题目描述:
给你单链表的头指针head和两个整数left和right,其中left <= right。请你反转从位置left到位置right的链表节点,返回 反转后的链表 。
题目归纳:
是前导题反转链表的升级版。
解题思路:
解法: 反转链表 II - leetcode官方题解
完成区间链表反转共需6步:
(1)从虚拟头节点走left-1步,来到left节点的前一个节点
(2)从pre再走 right-left + 1步,来到right节点
(3)截取链表,并记录好right的下一个节点位置
(4)切断链接,以便反转区间[left, right]
(5)反转链表区间[left, right]
(6)反转链表接上原来的链表之中, right_node成为反转链表的head
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def reverseBetween(self, head: Optional[ListNode], left: int, right: int) -> Optional[ListNode]:# 定义一个函数,用来反转链表def reverse_linked_list(head: ListNode):pre = Nonecurr = headwhile curr != None:# 暂存curr_next = curr.next# 反转curr.next = pre# 后移pre = currcurr = curr_nextdum_head = ListNode(-1)dum_head.next = headpre = dum_head# (1)从虚拟头节点走left-1步,来到left节点的前一个节点for _ in range(left-1):pre = pre.next# (2)从pre再走 right-left + 1步,来到right节点right_node = prefor _ in range(right-left + 1):right_node = right_node.next# (3)截取链表left_node = pre.nextsucc = right_node.next# 切断链接,以便反转区间[left, right]pre.next = Noneright_node.next = None# (4)反转区间[left, right]reverse_linked_list(left_node)# (5)反转链表接上原来的链表之中, right_node成为反转链表的headpre.next = right_nodeleft_node.next = succreturn dum_head.next
6. K 个一组翻转链表
题目链接:K 个一组翻转链表 - leetcode
题目描述:
给你链表的头节点head,每k个节点一组进行翻转,请你返回修改后的链表。k是一个正整数,它的值小于或等于链表的长度。如果节点总数不是k的整数倍,那么请将最后剩余的节点保持原有顺序。你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
题目归纳:
升级了一段代码的理解:反转链表。反转链表可以作为反转一个链表区间来理解。
解题思路:
解法: K 个一组翻转链表 - leetcode官方题解
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:# 翻转一个子链表。这段代码是对反转链表的提炼,升华,重点在prev的含义理解上def reverse(self, head: ListNode, tail: ListNode):prev = tail.next # 第一次翻转时,要续上尾,tail.next = None是特例p = headwhile prev != tail:# 暂存next_node = p.next# 翻转p.next = prev# 后移prev = pp = next_nodereturn tail, head # 新的头节点和尾节点def reverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:# 把链表节点按 k个一组 分组,使用一个head指针,依次指向每组的头节点。head指针每次向前移动k步,直到链表结尾# 对于每个分组,先判断其长度是否 >= k,若是,翻转着部分链表,否则不翻转hair = ListNode(-1) # 头head上面是头发hair,不要怕head找不到,有hair拎着头发拽头皮hair.next = headpre = hairwhile head:# tail起点是pre,这样0+k步的偏移量才对tail = pre# 剩余部分长度是否 >= kfor i in range(k):tail = tail.nextif not tail: # 剩余部分长度 < kreturn hair.nextnext_node = tail.nexthead,tail = self.reverse(head, tail) # 反转后,新的头节点与尾节点# 把反转后的子链表重新接回原链表pre.next = headtail.next = next_node# 后移pre = tailhead = tail.nextreturn hair.next
7. 删除链表的倒数第 N 个结点
题目链接:删除链表的倒数第 N 个结点 - leetcode
题目描述:
给你一个链表,删除链表的倒数第n个结点,并且返回链表的头结点。
题目归纳:
(1)双指针解法:记得题目求倒数第几个位置时,如果预先不知道长度,可以用双指针,其本质类似于滑动窗口。
解题思路:
解法: 删除链表的倒数第N个节点 - leetcode官方题解
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def removeNthFromEnd(self, head: Optional[ListNode], n: int) -> Optional[ListNode]:# 题目保证n不会超出链表的长度,但最好还是做一个判断# 伪头节点dum_head = ListNode(-1)dum_head.next = head# 双指针解法,记得求倒数第几个位置时,如果预先不知道长度,可以用双指针,其本质类似于滑动窗口fast = headslow = dum_head# (1)fast先走n步,并且要保证走完n步不超出链表# reach_n_step = Truefor i in range(0,n):if i < n-1 and not fast: # # 没走完n步就出现了fast=None,故不存在倒数第n个节点,不再继续往后走# reach_n_step = False # continuereturn headelse:fast = fast.next# (2)slow和fast一起走,直到fast为Nonewhile fast:fast = fast.nextslow = slow.next# (3)此时slow指向倒数第n个节点的pre位置slow.next = slow.next.next # 删除倒数第n个节点return dum_head.next # 之所以不返回head,是为避免当head本身被删除时出现错误
8. 删除排序链表中的重复元素 II
题目链接:删除排序链表中的重复元素 II - leetcode
题目描述:
给定一个已排序的链表的头head, 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
题目归纳:
(1)双指针解法:记得题目求倒数第几个位置时,如果预先不知道长度,可以用双指针,其本质类似于滑动窗口。
解题思路:
解法: 删除排序链表中的重复元素 II - leetcode官方题解
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def deleteDuplicates(self, head: Optional[ListNode]) -> Optional[ListNode]:# 很类似于一道题:【删除有序数组中的重复项】,【删除有序数组中的重复项】那道题有一个重要的性质,即# 若linklist[i] == linklist[k],则必有i <= j <= k,linklist[i] == linklist[k] == linklist[j]# 但本题是把重复的链表元素都删除,而不是删到只剩下一个# 一次遍历即可以删除重复元素# (1)建立一个dummy_head伪头节点,你可以叫它hair这样更直观,我也是刷其它题遇到的这个命名方式,十分形象,以后就固定用hair了# (2)cur指向hair节点,然后对链表开始遍历# (3)若cur.next与cur.next.next的val值相同,则需要将 cur节点 之后(另一种表述方式为:cur.next以及cur.next之后的节点)# 的所有相同元素值的链表节点全部删除,直到cur.next为空节点或cur.next的val值不等于x,此时链表中所有元素值为x的重复节点全部删除# (4)返回hair.next# 注意cur.next与cur.next.next的判断,当cur.next为None时,cur.next.next会报错,and短路运算可以避免该问题,所以判断顺序是重要的# 另外,需要释放已经被删除节点的空间,这是官方题解没有完成的。if not head:return Nonehair = ListNode(-1, head) # hair.next = headcurr = hairwhile curr.next and curr.next.next: # 节点存在,关键逻辑(1)if curr.next.val == curr.next.next.val: # 值重复,关键逻辑(2)x = curr.next.valwhile curr.next and curr.next.val == x: # 指针跨指下一个,关键逻辑(3) wait_tobe_del_node = curr.next # 等待被从内存中释放空间的节点 curr.next = curr.next.nextdel wait_tobe_del_nodeelse:curr = curr.nextreturn hair.next
9. 旋转链表
题目链接:旋转链表 - leetcode
题目描述:
给你一个链表的头节点head,旋转链表,将链表每个节点向右移动k个位置。
题目归纳:
容易让人联想到旋转数组,旋转数组一题需要3次原地反转,但这道题是链表,可以利用链表特性
解题思路:
解法: 旋转链表 - leetcode官方题解
尾头相连,找到新的尾部断开,即是符合要求的链表。
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def get_len_and_tailNode(self, head) -> int: # 确保 head!=Nonecnt = 1tail = headwhile tail.next:cnt += 1tail = tail.nextreturn cnt, tail # 链表长度与尾节点def rotateRight(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:# 旋转数组的进阶版,但是有一种更快的解法是,把链表作为一个环闭起来,然后在闭环中移动,最后在指定位置处断开即可。# 给定链表长度为n,当移动次数k>=n时,只需要移动 k mod n 次即可# 因此,新链表的最后一个节点为 原链表的 第 n - (k mod n)个节点,(此处认为下标从1开始)# 故可以先将给定的链表连成环,然后在指定位置断开,就是向右旋转后的链表了,妙!if k == 0 or head == None or head.next == None: # 特例判断return head # (1)先计算出链表的长度n 与 尾节点n,tail = self.get_len_and_tailNode(head)# (2)找到该链表的末尾节点,将其与头节点相连add = n - (k%n) # add:偏移量if add == n: # k是n的整数倍return headtail.next = head # 尾头相连# (3)查找断开位置,即尾节点位置while add > 0: # tail = tail.nextadd -= 1# (4)断开new_head = tail.nexttail.next = Nonereturn new_head
10. 分隔链表
题目链接:分隔链表 - leetcode
题目描述:
给你一个链表的头节点head和一个特定值x,请你对链表进行分隔,使得所有 小于x的节点都出现在 大于或等于x的节点之前。你应当 保留 两个分区中每个节点的初始相对位置。
题目归纳:
容易让人联想到旋转数组,旋转数组一题需要3次原地反转,但这道题是链表,可以利用链表特性
解题思路:
解法: 分隔链表 - leetcode官方题解
见官方题解
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def partition(self, head: Optional[ListNode], x: int) -> Optional[ListNode]:# 快速排序链表版?有人确实采用了快排的思路来解本题,但官方解法不是这样做的,官方解法很直接,就像分别拎着两挂爆竹,一串爆竹小,一串爆竹大# 特定值x出现的节点就类似于快排的pivot轴点,比pivot位置值小的被放到左边,比pivot位置值大的被放到右边# 不清楚快排工作原理的请看#【快速排序(双指针法)动画演示】 https://www.bilibili.com/video/BV1rW4y1x7Kh/?share_source=copy_web&vd_source=9105639a94a36385de5325000172f507# 维护两个链表,small和large。small按顺序存储所有小于x的节点,large按顺序存储所有大于x的节点。遍历完原链表后,将small末尾指向large头部,即完成了对链表的分隔# hair_small, hair_large分别为small, large链表的伪头节点,hair_small.next = head, hair_large.next = head# 同时假设small和large节点指向当前链表的末尾节点,随后,从前往后遍历链表,判断当前链表的节点值是否小于x,若小于,则将small.next指向该节点,否则将large.next指向该节点# 遍历结束后,将large.next置空,这是因为当前节点是复用的原链表节点,large.next可能指向一个小于x的节点,因此要切断该引用。同时将small.next指向hair_head.next指向的节点,即真正意义上的large链表头节点,最后返回hair_small.next即为答案。small = ListNode(-1)hair_small = smalllarge = ListNode(-1)hair_large = largewhile head: # 一次遍历,不用额外变量if head.val < x: # small串起来small.next = headsmall = small.nextelse:large.next = headlarge = large.nexthead = head.next# 断链large.next = None# 续链small.next = hair_large.nextreturn hair_small.next
11. LRU 缓存
题目链接:LRU 缓存 - leetcode
题目描述:
请你设计并实现一个满足LRU(最近最少使用) 缓存 约束的数据结构。
实现LRUCache类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化LRU缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。- 函数
get和put必须以 O ( 1 ) O(1) O(1) 的平均时间复杂度运行。题目归纳:
LRU缓存在计算机组成原理与OS课程中是常客,在OS中的Cache替换算法出现次数尤其频繁,先复习下LRU的定义
LRU(Least(最少) Recently(近) Used 最近最少使用)侧重于观察最近访问,实现起来比LFU更简单,LFU(Least Frequently Used 最不经常使用)侧重于根据数据的访问次数所得出的统计规律。
当场景满足以下两个特点时,使用LFU
(1) 长期的数据访问模式是稳定的。
(2) 重视数据项的频率 > 重视数据项的时效,也就是关注长期 > 关注短期。
参考文章或视频链接 [1] LRU算法 - 百度百科 [2] LFU算法 - Wikipedia [3] 【Java面试】LRU算法和LFU算法的本质区别?- bilibili [4] Difference between LRU and LFU Page Replacement Algorithm [5] What is the difference between LRU and LFU [6] Cache replacement policies
解题思路:
解法: LRU缓存机制 - leetcode官方题解
class DLinkNode: # 双向链表def __init__(self, key=0, value=0):self.key = key # 比普通的双向链表多个keyself.value = valueself.prev = Noneself.next = None# 因为要求O(1)时间复杂度,才会用到Hash表
class LRUCache:# 哈希表+双向链表(自带的Dqueue)def __init__(self, capacity: int):# 以 正整数 作为容量 capacity 初始化 LRU 缓存self.cache = {}self.dum_head = DLinkNode()self.dum_tail = DLinkNode()self.dum_head.next = self.dum_tailself.dum_tail.next = self.dum_headself.capacity = capacity self.size = 0 # size <= capacitydef get(self, key: int) -> int:# 平均时间复杂度: O(1)# 关键字 key 不存在于缓存中,返回 -1 。if key not in self.cache: return -1# 如果关键字 key 存在于缓存中,则返回关键字的值。# 通过哈希表定位,再移动到双向链表的头部node = self.cache[key]self.moveToHead(node)return node.valuedef put(self, key: int, value: int) -> None:# 如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。# 平均时间复杂度: O(1)if key not in self.cache: # 如果不存在,则向缓存中插入该组 key-value 。node = DLinkNode(key, value)self.cache[key] = nodeself.addToHead(node)self.size += 1if self.size > self.capacity:removed = self.removeTail()self.cache.pop(removed.key)self.size -= 1else: # 关键字 key 已经存在,先通过哈希表定位,变更其数据值 value,再移动到头部node = self.cache[key]node.value = valueself.moveToHead(node)def addToHead(self, node): # (1)添加到头部# (1)新节点构建双向关系node.prev = self.dum_headnode.next = self.dum_head.next# (2)老节点拆除旧关系的同时构建新关系self.dum_head.next.prev = nodeself.dum_head.next = nodedef removeNode(self, node): # (2)移除节点,提供给moveToHead()与removeTail()使用node.prev.next = node.nextnode.next.prev = node.prevdef moveToHead(self, node): # (3)移动到头部是一个组合操作 = 移除节点+添加到头部self.removeNode(node)self.addToHead(node)def removeTail(self): # (4)淘汰尾部节点node = self.dum_tail.prevself.removeNode(node)return node# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)





![[Vulnhub靶机] DriftingBlues: 2](https://img-blog.csdnimg.cn/ee58c53007d2447f8f2e01ff9a64fa46.png)