- 本篇文章学习总结 李宏毅 2021 Spring 课程中关于 Transformer 相关的内容。
- 课程链接以及PPT:李宏毅Spring2021ML
- 这篇Blog需要Self-Attention为前置知识。
Transfomer 简介
- Transfomer 架构主要是用来解决 Seq2Seq 问题的,也就是 Sequence to Sequence 问题。
- 输入是一个长度不确定的Sequence。
- 输出是一个长度不确定,由机器自动决定的Sequence。
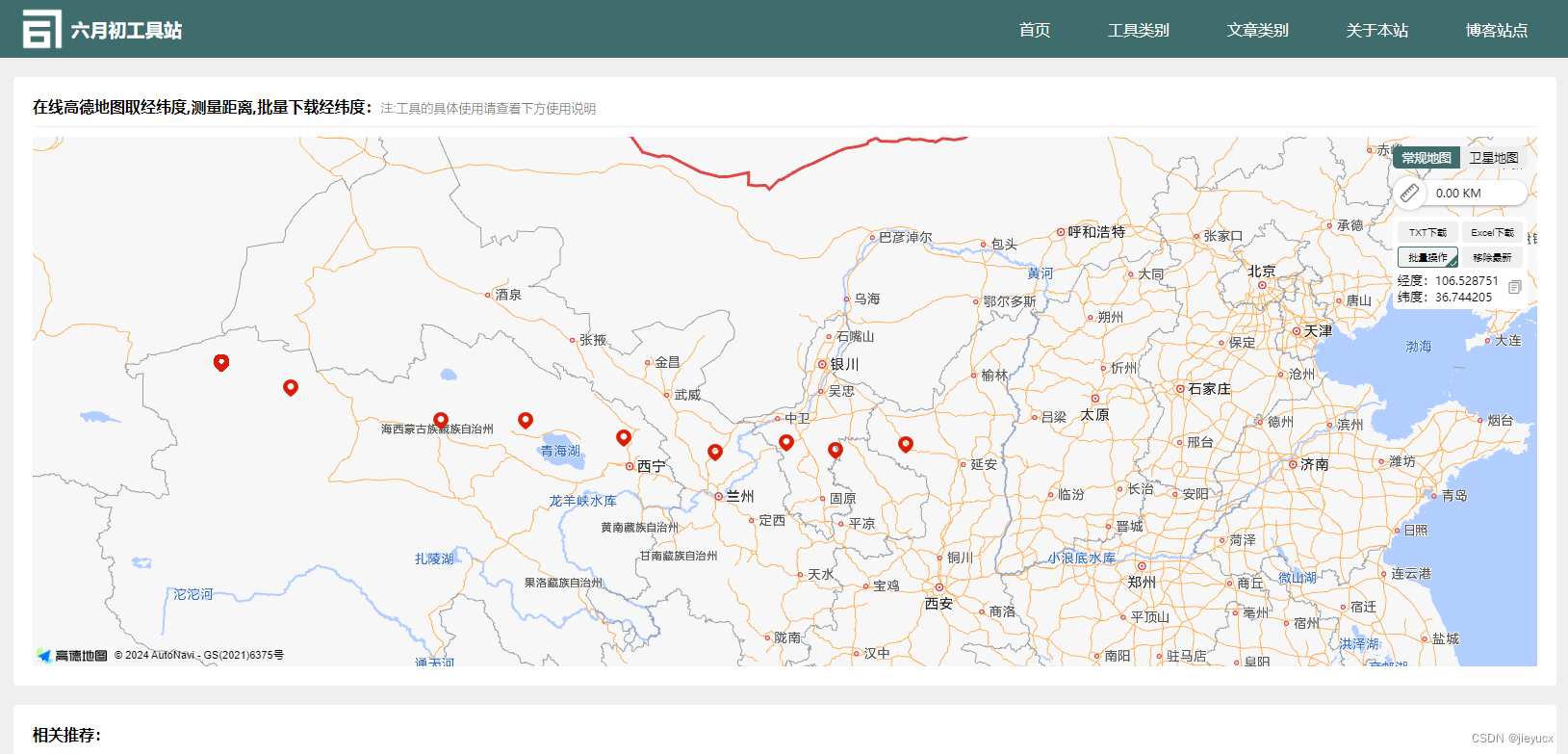
下面是一些常见的Seq2Seq的例子:
- Speech Recognition 语音识别
- Machine Translation 机器翻译
- Speech Translation 语音翻译
如下图所示:
我们常见聊天机器人(Chat bot)其实就是一种 Seq2Seq 模型。

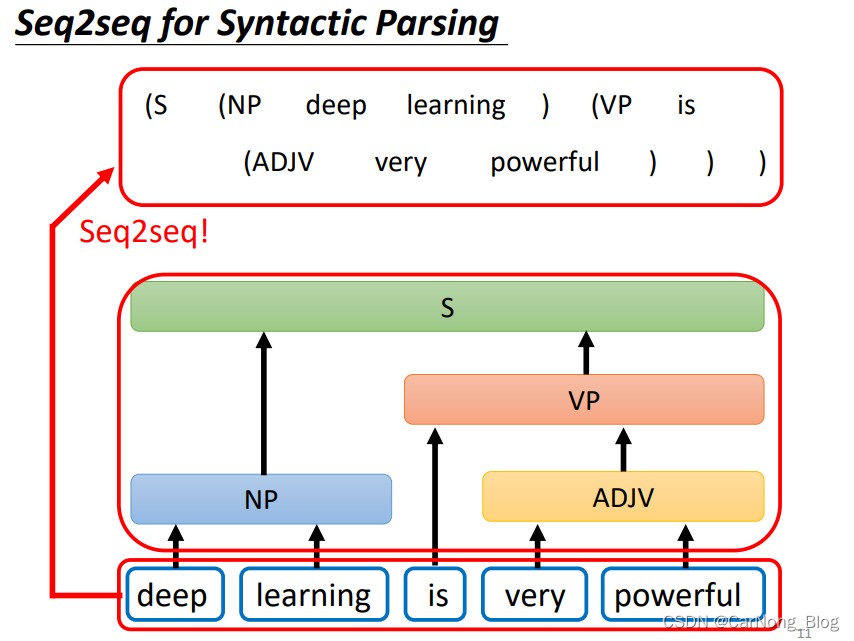
Seq2Seq for Syntactic Parsing
Seq2Seq 在 文法解析 任务中也能得到应用,如下图所示,模型会得到一个句子的输入,模型需要输入出句子中每个词在句子中的词性分析。
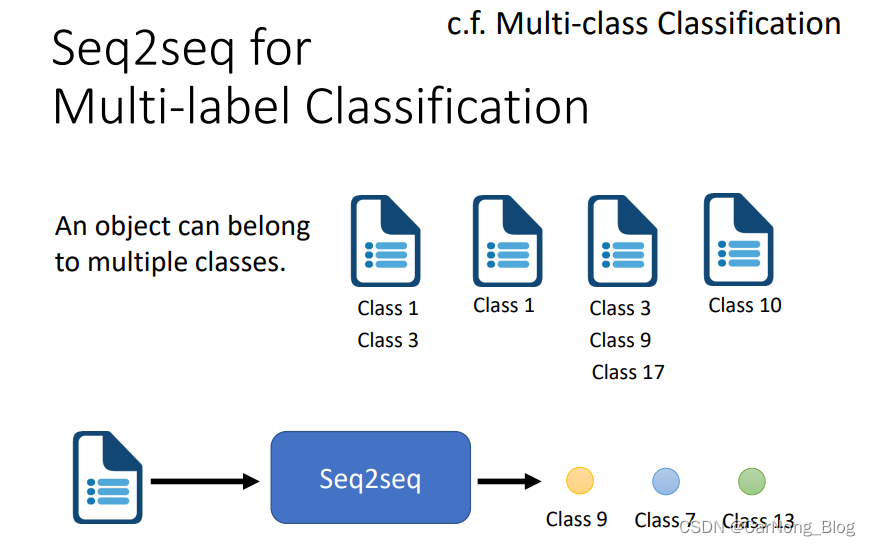
Seq2Seq for Mutil-label Classification
- Mutil-lable Classification: 一个物体可能会被分到多个标签,比如 对于一个人来说,他的标签有 男人、老师、儿子 等标签。
所以,对于 Mutil-label Classification 来说,输出的也是一个sequence,是不确定长度的。
Seq2Seq for Object Detection
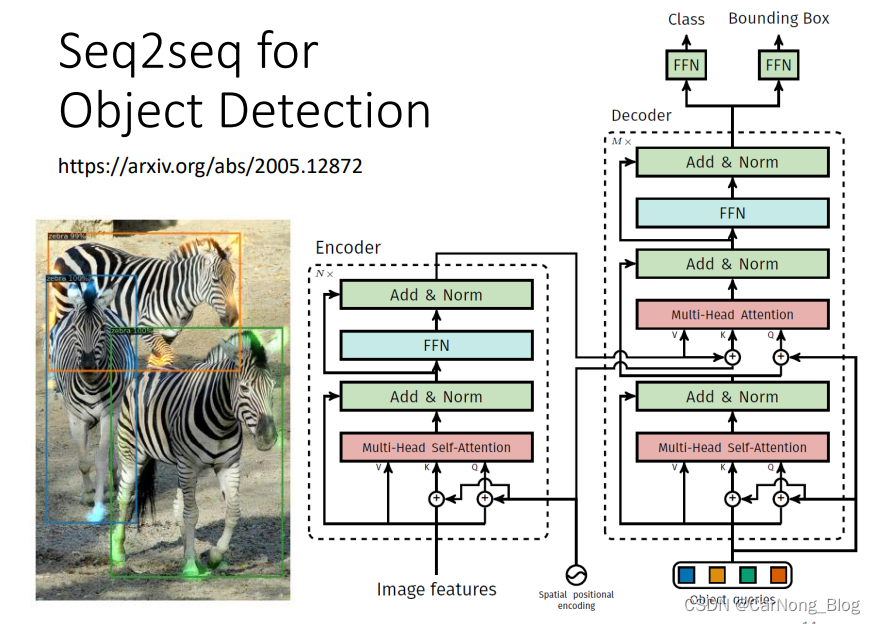
综上,我们直到 Seq2Seq Model 是一个非常有用的model,是一个powerful 的model,在很多不同种类的任务下都有不错的表现。
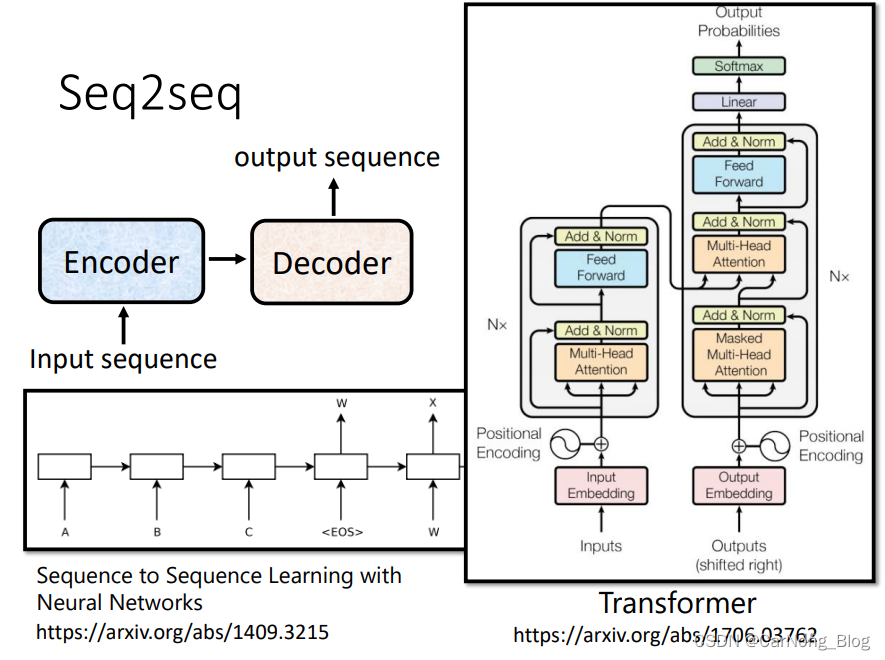
Seq2Seq’s Model in Transformer
一般来说,Seq2Seq‘s Model 由两部分组成:
- Encoder:接收 input sequence,并且将处理好的input,传递给Decoder。
- Decoder:输出 output sequence。
如下图,接下来,我们依次学习 Encoder 和 Decoder。
Encoder
- Encoder 所要做的事情用白话来讲就是:接收一排向量,输出数量相同的一排向量。
- 要完成这件事情,其实 CNN 和 RNN 都能做到,但是 Transformer 中是使用 Self-Attention 这个方法来实现的。
如下图所示:
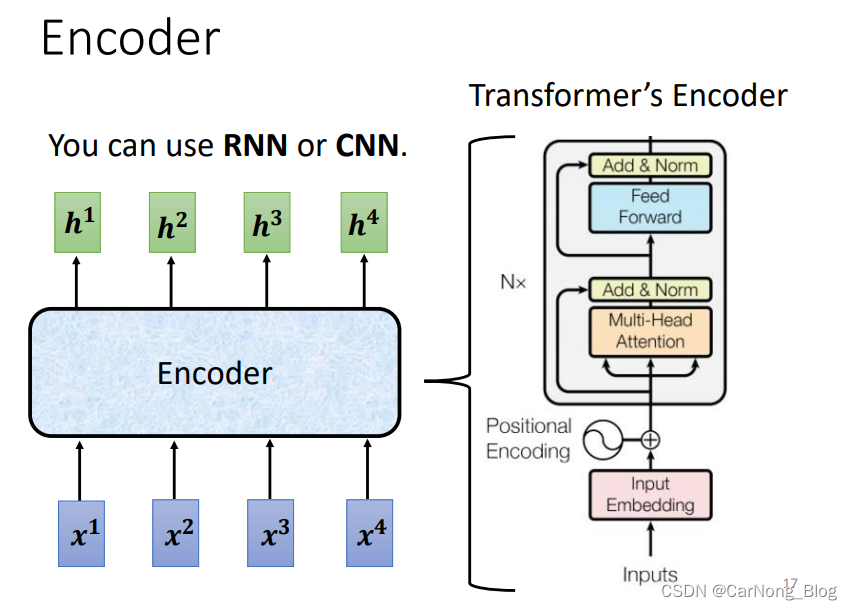
上图右边就是Transformer中Encoder的架构图,我们先不管这个复杂的架构,我们先从简单的方面讲讲它的架构。
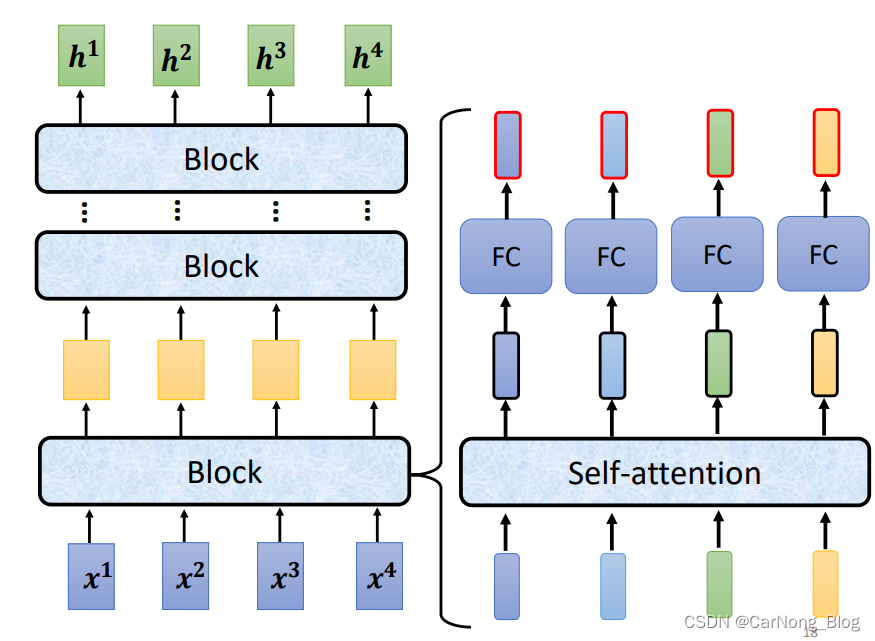
在Encoder中,会分成非常多的Block,这些Block有以下特点:
- 不是单独的layer,它里面会包含几层layer。
- 每一个Block输出一排向量,输出数量相同的一排的向量。
- 每一个Block做的事情,将输入经过Self-Attention,然后经过FC,得到最终输出的一排向量。
如下图:
但是,在Transformer中的Block稍微更复杂一些: - 它使用Residual Connected,每个output不只是output,而会加上input,有助于较少梯度消失的情况。
- 得到残差的Self-Attention之后,还需要经过 Layer Normalization,也就是规范化。
- 经过Layer Normalization 之后,会经过FC,FC的输出也是一种Residual Connected,也需要加上input到最终的output中。
- 最终,再经过一次 Layer Normalization,即可获得 Block 最终输出的一排向量。
如下图所示:
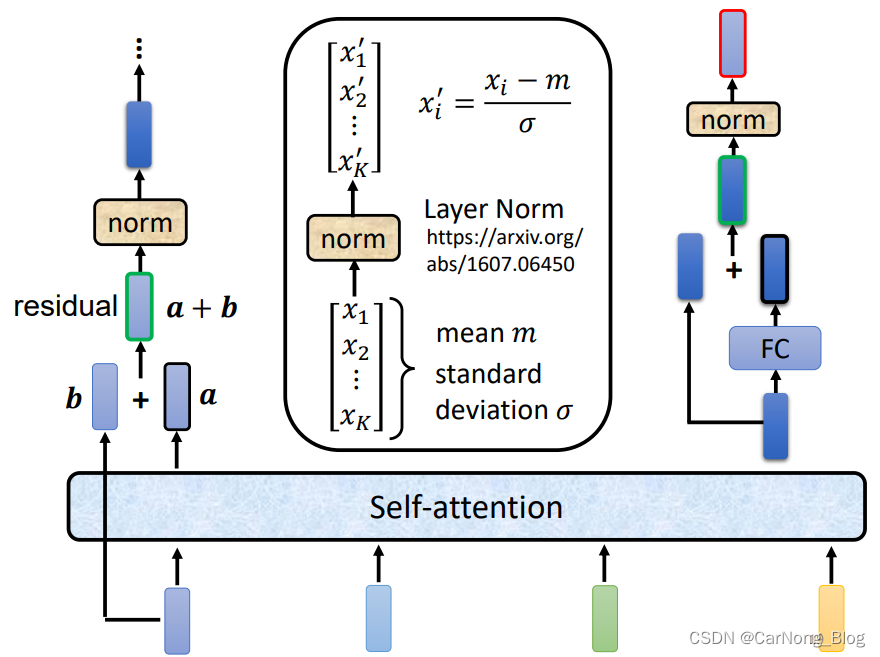
现在我们充分理解了每个Block内部的机制,我们再回过头来看之前复杂的Encoder架构图:
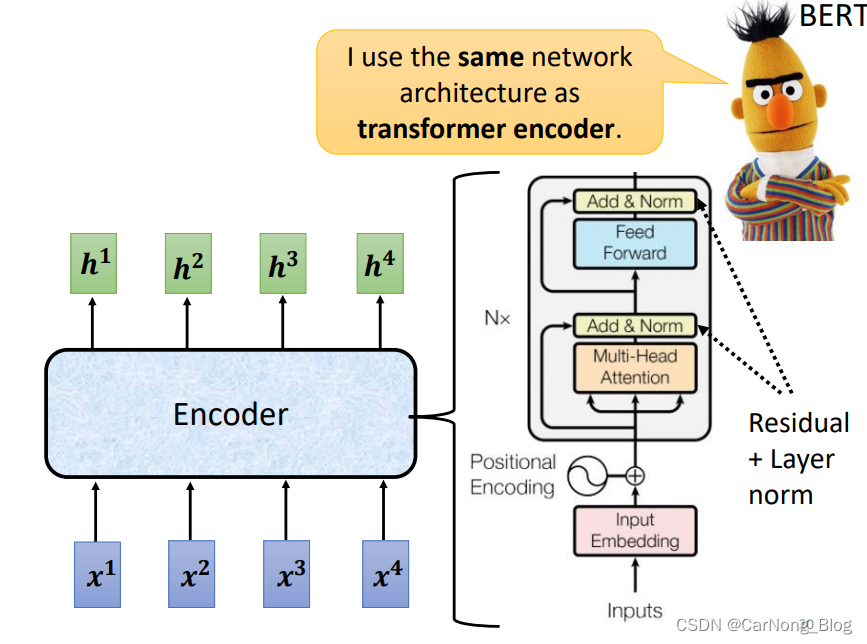
其中有两点值得注意的是:
- 在 input的时候,加入了Positional Encoding,携带了位置信息。
- 使用的是 Mutil-Head Attention。
Decoder
Decoder 其实有两种:
- Autoregressive (AT)Decoder
- Non-Autoregressive (NAT)Decoder
Autoregressive Decoder’ s Example in Speech Recognition
-
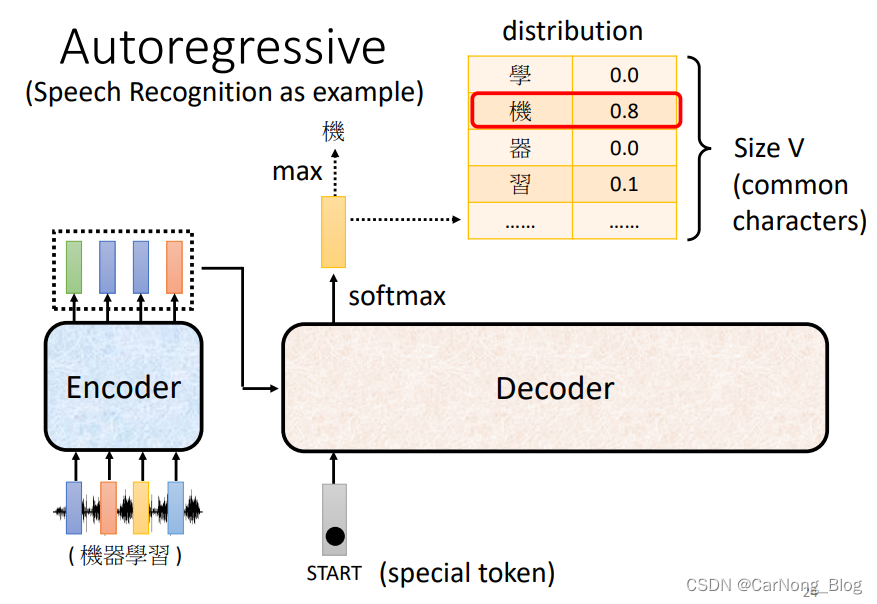
首先,我们观察上图,左边是一个Encoder,刚刚已经讲解过了,现在我们只需要将其理解为一个输入一排向量,输出相同数量一排向量的模块即可。
-
Encoder的输入会以某种方式(现在暂时不用理解)将输入传递给Decoder。
-
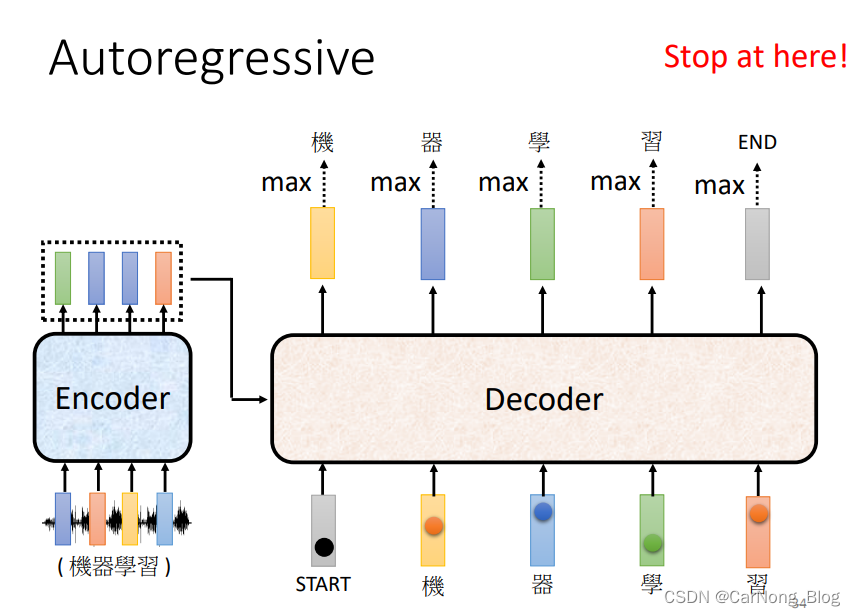
Decoder 首先会获取第一个输入向量,这个向量是一个特别的token,代表句子的开始。
-
然后Decoder会输出一个向量,这个向量的长度是这个任务的词汇表的长度,每个位置代表该位置字的出现概率,是经过Softmax的输出。
-
因此,第一个向量中 “机” 的概率是最大的,第一个输出的向量代表 “机” 字。
-
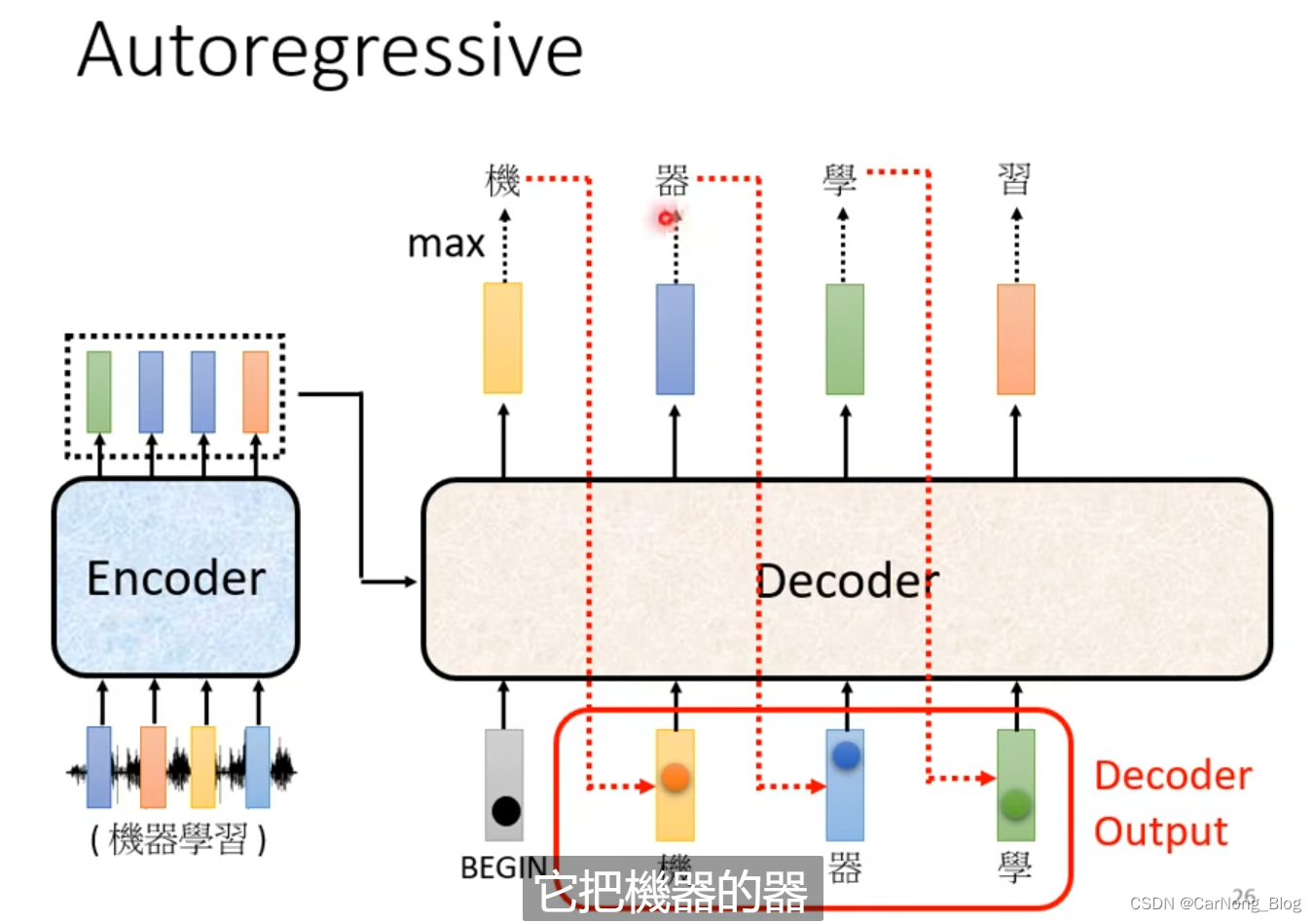
之后,Decoder 会得到第二个输入,而第二个输入就是 (开始的Special Token + 刚刚输出的”机“)作为输入,然后产生第二个输出向量,而这个向量中,概率最大的是 ”器“ 这个字。
-
再然后,Decoder 会得到第三个输入,而第三个输入就是(开始的Special Token + 刚刚输出的”机“ + 刚刚输出的”器“)作为输入,然后产生第三个输出向量,这个向量中,概率最大的是”学“这个字。
-
依次类推,每次输入都是包含之前的输出。
注意点:每一次的输出都依赖于前一次的输出,这样可能会产生 Error Propagation 的问题,也就是”一步错,步步错“。
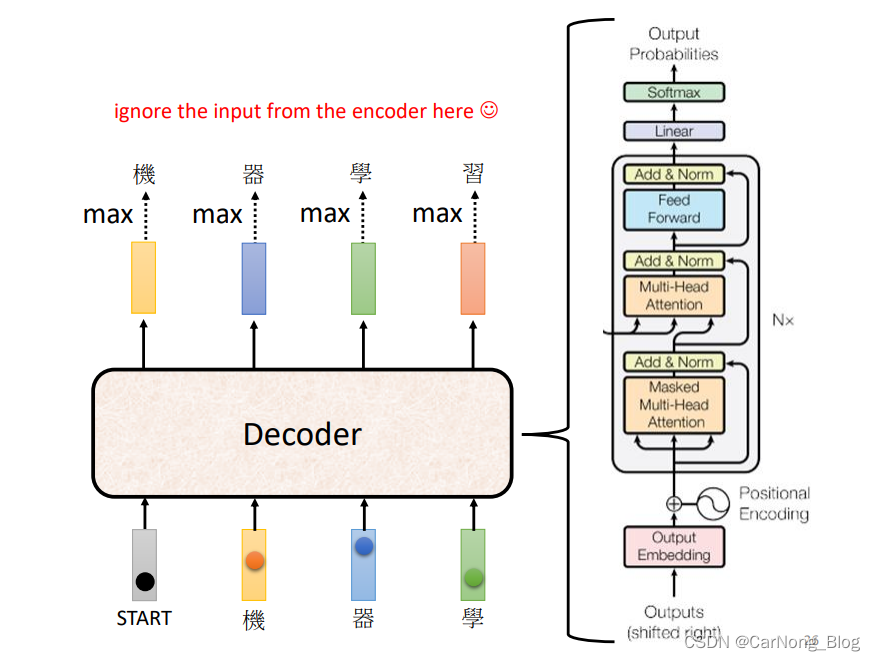
至此,我们大致了解Decoder中的机制。
下面,我们来对比一下 Encoder 和 Decoder ,如下图所示:
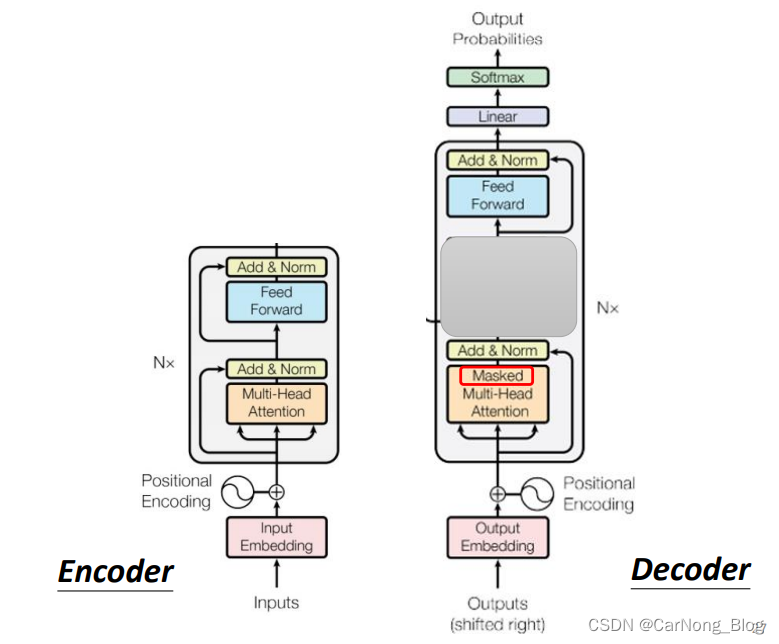
我们发现,其实出了被灰色盖住的地方,Encoder 和 Decoder 的结构其实是差不多的,除了这个Masked。
下面我们介绍一下Masked Self-Attention
它的核心思想其实很简单,Self-Attention 是为了融合上下文信息的,Masked Self-Attention 其实就是只是融合之前的上下文信息,而不去融合之后的上下文信息,如下图所示:
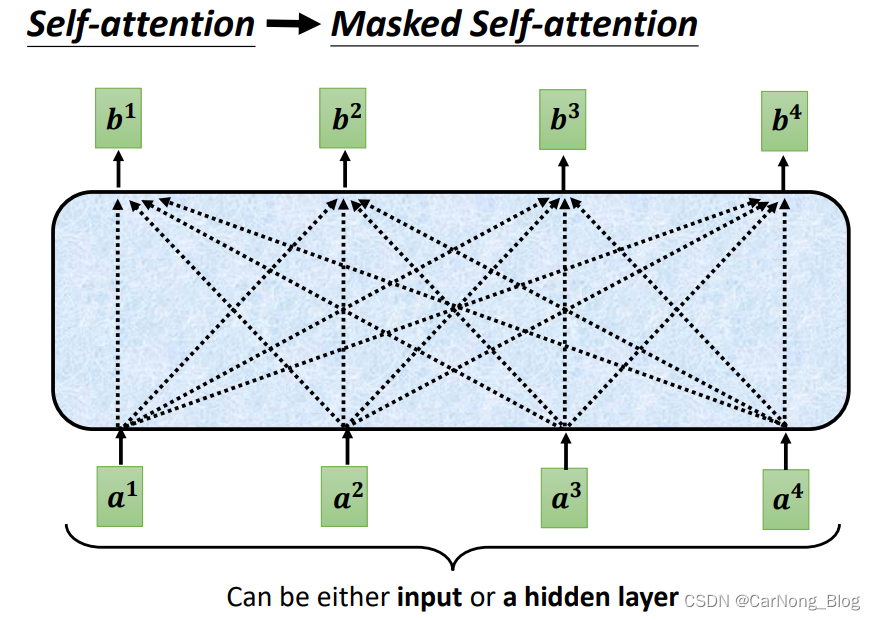
按照之前一般的情况来说,输出b2,需要融合a1、a2、a3、a4 这4个向量的信息。
但是Masked Self-Attention 只会融合之前的信息,也就是对于输出b2,只会融合 a1、a2 的信息。
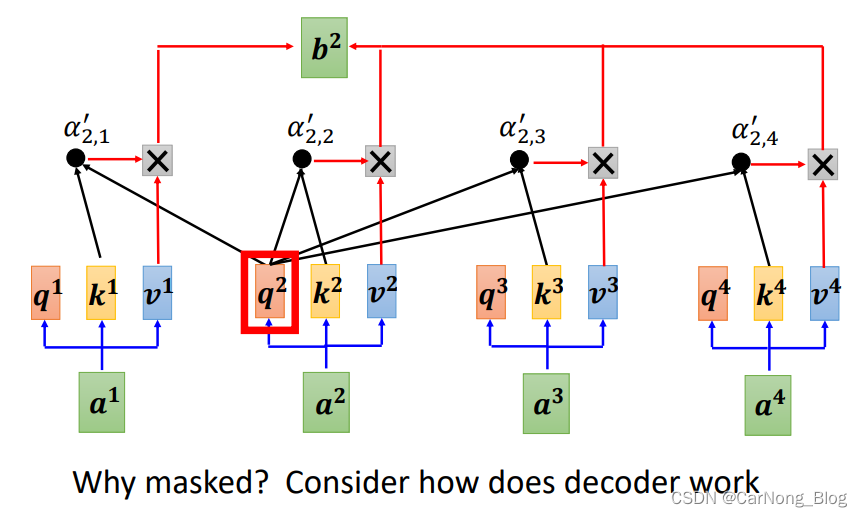
为什么需要Masked Self-Attention?
- 因为我们的输出是一个一个产生的,先有 a1 再有 a2 再有 a3。
- Encoder 是一次性将所有的输入读取。
- Decoder 的输入是自己一步一步产生出来的。
Decoder 需要自己决定输出 Sequence 的长度
简单来说,刚刚提到一个Special Token表示句子开始,所以我们也可以设置一个Special Token作为结束,这个特殊字符放进Vocabulary中,当输出的向量中概率最大的是这个表示结束的特殊字符,即代表输出结束。
Non-Autoregressive Decoder
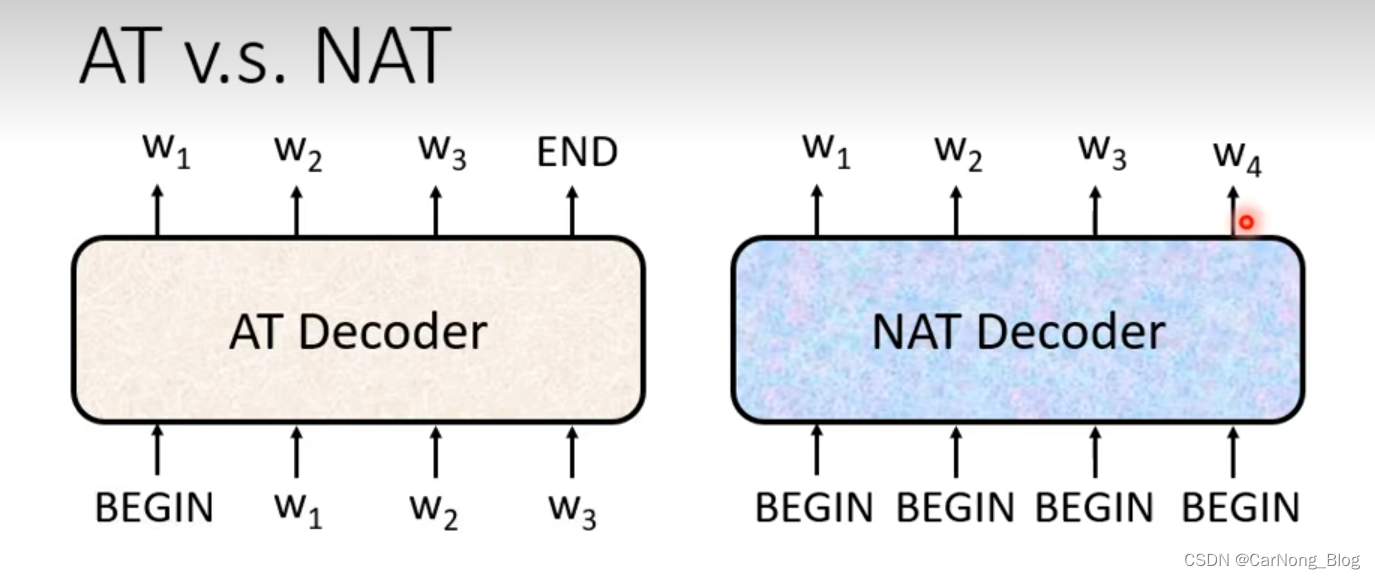
- AT Decoer:刚刚已经介绍了 AT Decoer,它是逐步产生输出的Sequence,通过读取之前的输出作为输出来产生当前的输出,是一步一步产生所有输出的。
- NAT Decoder:相比于AT Decoder,它是一次性产生全部的输出,一次性产生整个Sequence。
这里会有一个问题,NAT Decoder 怎么决定输出Sequence输出长度的呢?
-
- 额外训练一个Classifier,它读取Encoder的输出,然后输出一个数字,这个数字代表NAT Decoder 输出Sequence的长度。
-
- 也用一个特殊的字符代表结束,每次输出忽略掉结束字符后面的输出。
NAT Decoder 优点:
- 速度快,因为是一次性产生所有的输出。
- 可以通过对Classifier的设置,人可以控制输出的长短。
但是,目前来说,AT Decoder 会比 NAT Decoder 要更好。
Encoder - Decoder
下面我们来学习 Encoder 和 Decoder 的具体联系。
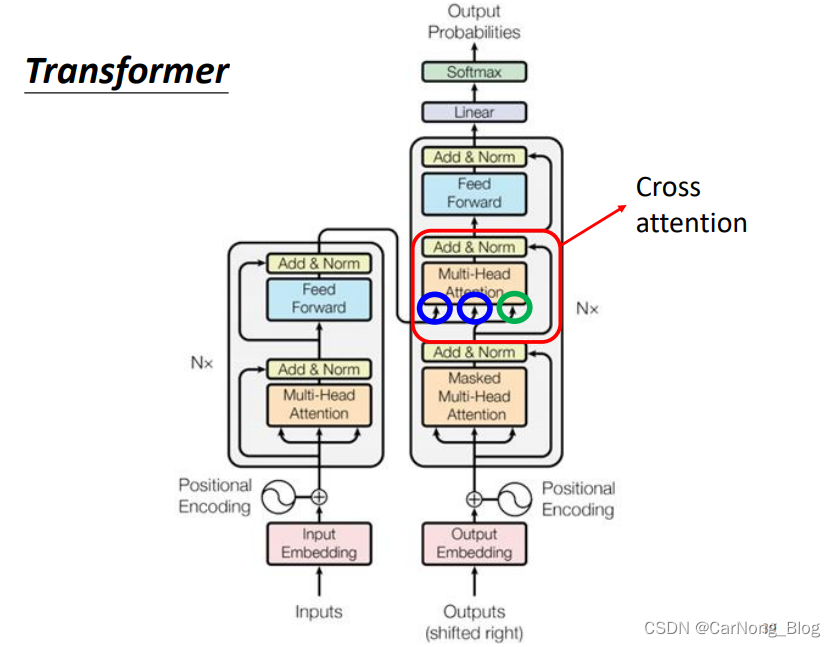
在上图中,Encoder的输出在Decoder中间的一个Block处进行传递,主要是通过一种叫做Cross Attention的机制。
Cross Attention
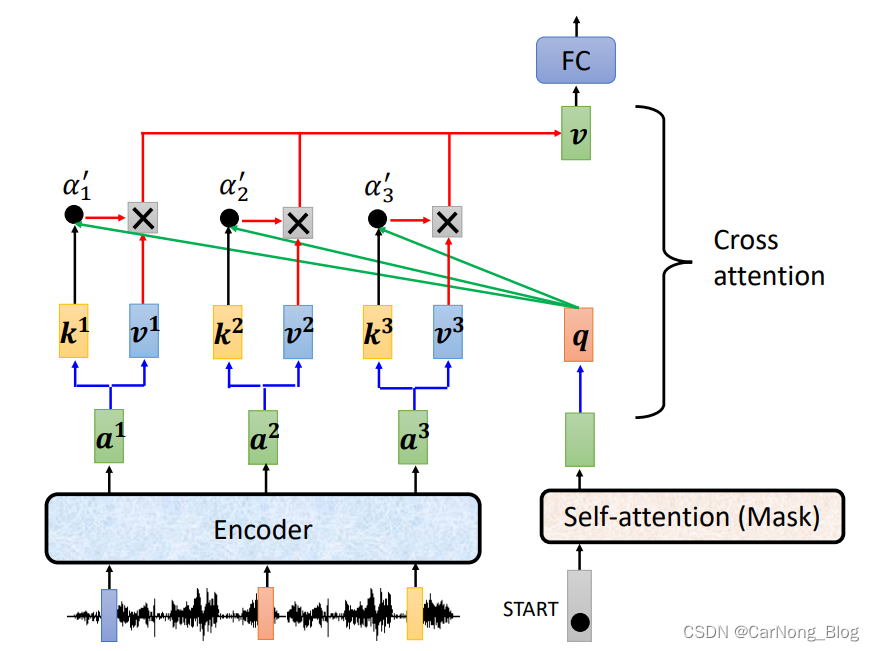
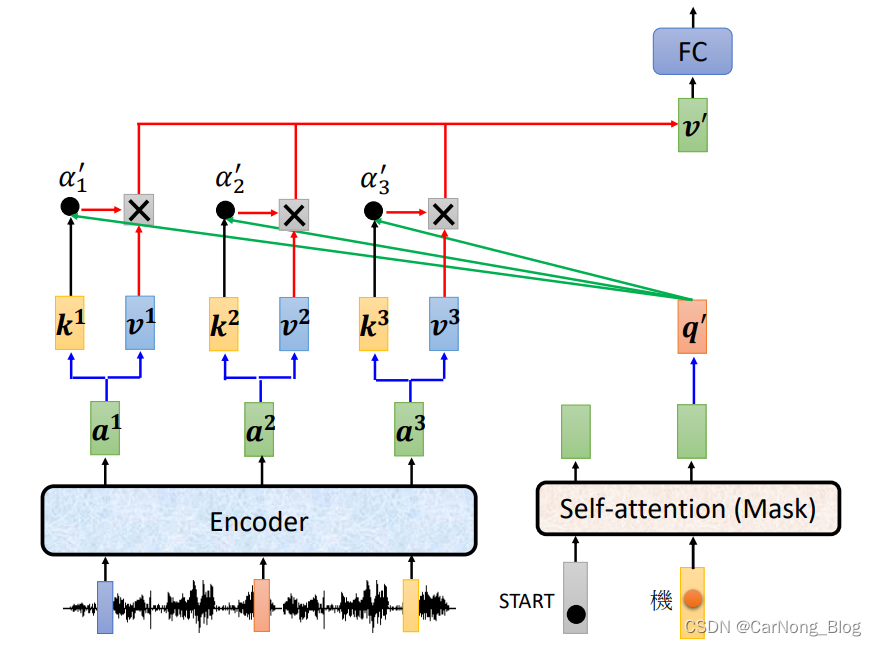
其中,Decoder经过Masked Attention会输出一个向量,这个向量需要和Encoder产生的向量融合上下文信息产生新的输出。
- Decoder向量提供q向量,而Encoder的向量提供k向量用于计算Attention Socre。
- 通过获得的Attention Score 和 对应v 向量相乘,再经过FC,获得最终的融合上下文的输出向量。
- 之所以成为 Cross Attention,是因为一部分向量来自于Encoder的输出,一部分向量来自于Decoder自己,将这些向量的相关信息进行融合。
这就是 Cross Attention 机制的原理。
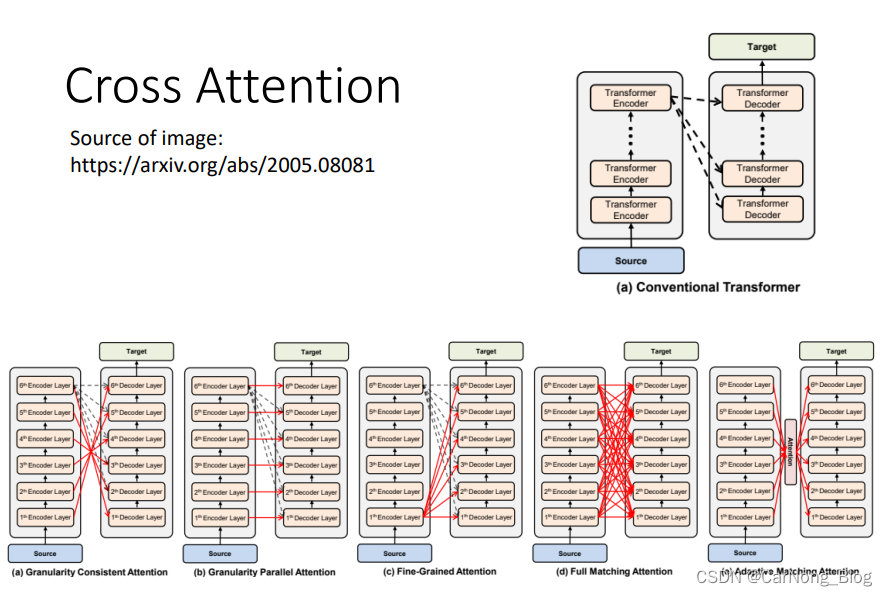
在原始Paper中,Decoder拿到的关于Encoder的输出向量是Encoder最终的输出,但是经过各个方面的改进,Decoder也可以拿到Encoder不同层次的输出进行融合上下文信息,如下图所示:
Training
对于Training这件事,我们以语音辨识作为例子来讲解。
首先,我们需要一个训练资料,包含语音以及它的label。
- 语音就是听上去是 ”机器学习“ 这四个字的语音材料。
- label就是这段语音的文字”机器学习“。
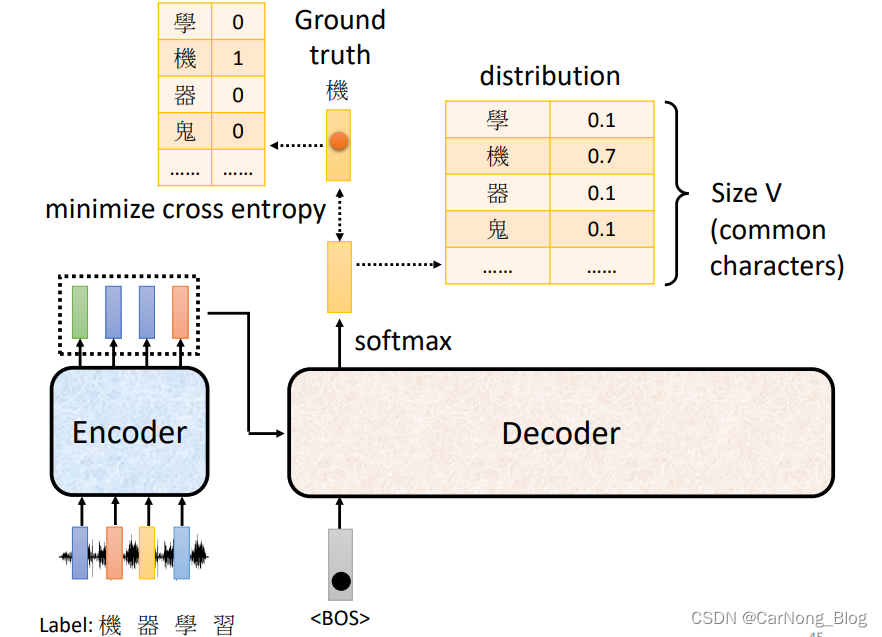
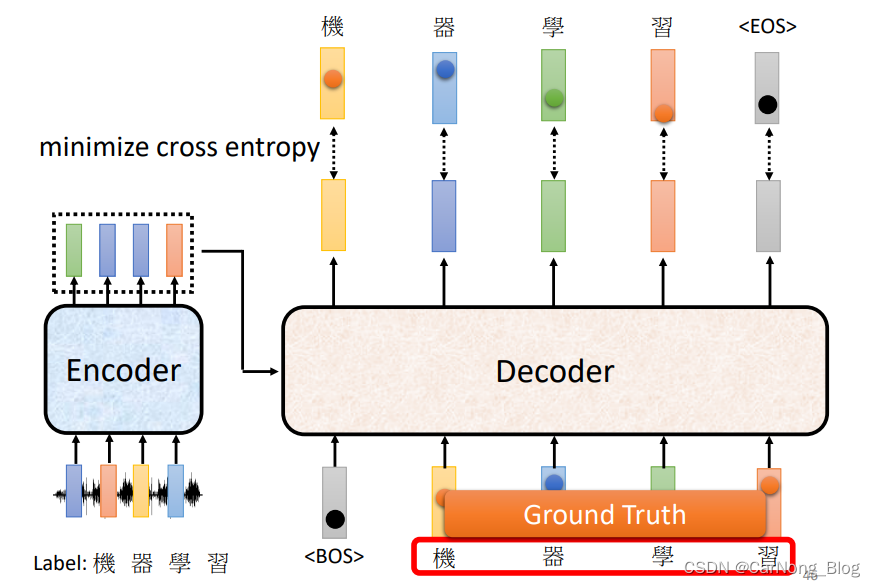
对于Decoder来说,它的输出是一个一个产生的。
对于第一个输出,它首先读取 BOS (Begin of Sentence)这样一个Special Token,然后产生一个向量,这个向量包含了所有可能输出字符的概率,也就是一个概率分布,而这个概率分布应该和 Ground Truth 越接近越好,也就是使真实值和预测值之间的 Cross Entropy 越小越好。
这个训练过程其实就是和分类问题的训练过程使一致的,都是通过Minimize Cross Entropy 来进行训练的。
一个值得注意的地方是:不要忘记最后一个表示 结束含义的Special Token。
Tips
下面是一些 Seq2Seq 训练的tips。
- Copy Machanism
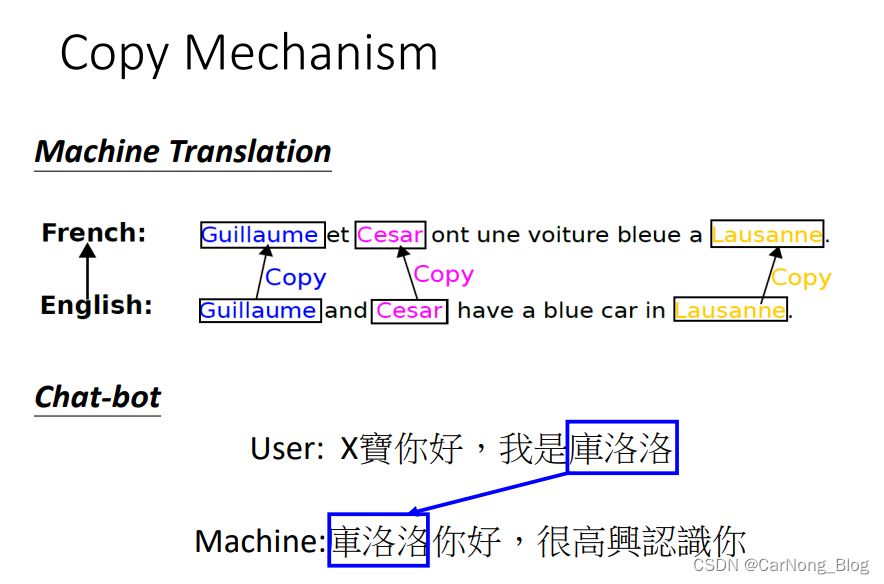
有时候,模型所需要学习的并不是创造某段文字,而是在某些时刻,直接复制输出当前的输入文字。
比方说:欢迎语、摘要。
这种具有输入复制能力的模型:Pointer Network
- Guided Attention

课程中给出了一个语音合成的例子,也就是给定一段文字,需要机器将文字转为语音念出来。
但是,对于 ”发财发财发财发财“ 、”发财发财发财“、”发财发财“ 这样重复出现的词汇,机器可以非常正确的念出来,但是对于”发财“ 这样单独的一个词汇,机器反而出现问题,只念了一个 ”财“ 字。
这样的错误表明,输入的有一些东西机器忽略掉了,没有看到。
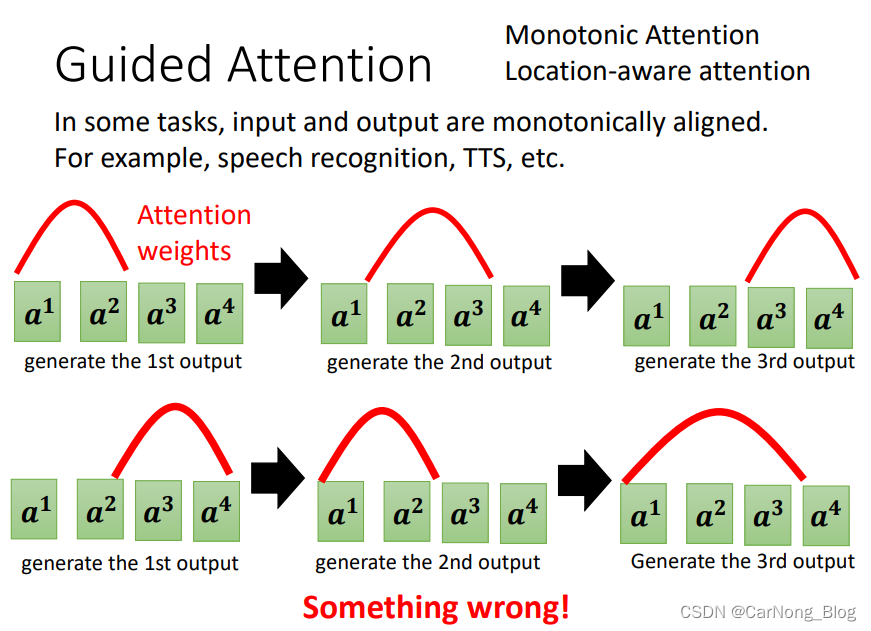
简单来说,机器的Attention需要被引导,也就是 Guided Attention,不然机器可能会产生一些乱七八糟的Attention顺序,以至于忽略掉一些重要的信息。
- Beam Search
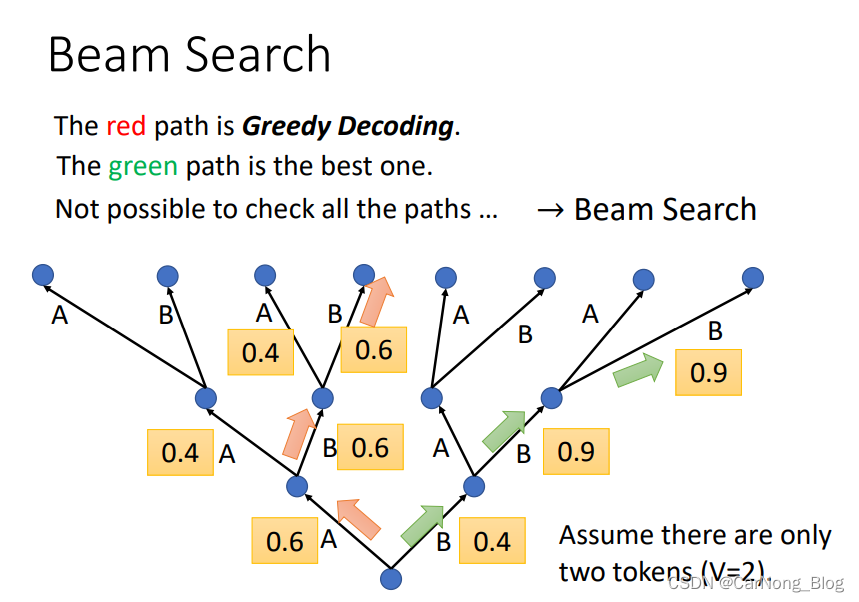
假设某种情况下,模型只会产生两个词汇,A和B。 - 首先,产生第一个词汇的时候,发现 A 的可能性更大,所以产生A。
- 第二步,产生第二个词汇的时候,发现B的可能性更大,所以产生B。
…
这种方式每次都产生可能性更大的那种情况。
有没有可能在某些情况下, 舍弃当前最优解,而会获得全局最优解呢?
这个问题就是Beam Search所解决的问题。
- 一般来说,对于有准确答案的问题,只有一个答案的问题,比如语音辨识,这个时候采用Bean Search 会更好一些。
- 而对于一些具有创造性的回答来说,会需要一些随机性,这个时候往往用一般的每次采用最优解会更好一些。