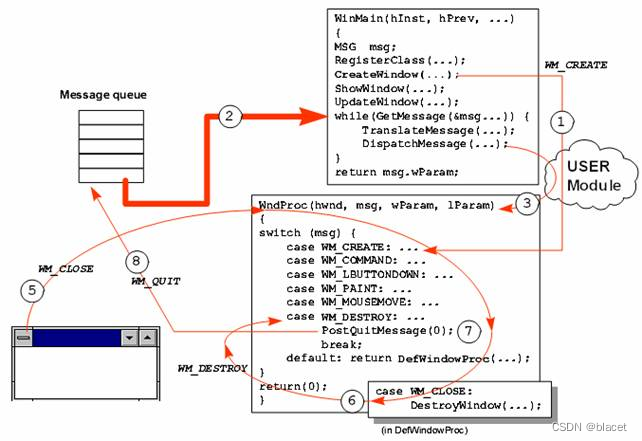
XPath是一种用于在XML文档中定位和选择节点的语言。如果你要提取script标签中的数据,可以使用XPath表达式来定位包含脚本数据的节点。以下是一些示例XPath表达式,以及如何在Python中使用lxml库来实现:
假设有如下HTML文档结构:
<html><head><title>Example</title></head><body><script type="text/javascript">var data = "Hello, world!";</script></body>
</html>
以下是如何使用XPath提取script标签中的数据的示例:
from lxml import html# HTML文档字符串
html_content = """
<html><head><title>Example</title></head><body><script type="text/javascript">var data = "Hello, world!";</script></body>
</html>
"""# 将HTML文档字符串解析为Element对象
root = html.fromstring(html_content)# 使用XPath表达式提取script标签中的数据
script_data = root.xpath('//script[@type="text/javascript"]/text()')[0]# 打印提取的数据
print(script_data.strip())
在这个例子中,XPath表达式是//script[@type="text/javascript"]/text(),它的意思是选择类型为"text/javascript"的script标签,并提取其文本内容。
请注意,[0]索引用于获取XPath返回的结果列表中的第一个元素,因为我们只选择了一个script标签。在实际使用中,你可能需要根据具体的HTML结构和需求来调整XPath表达式。