官网地址:MySQL :: MySQL 5.7 Reference Manual :: 14.5 InnoDB In-Memory Structures
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
缓冲池是主内存中的一个区域,在 InnoDB访问时缓存表和索引数据。缓冲池允许直接从内存访问经常使用的数据,从而加快处理速度。在专用服务器上,高达 80% 的物理内存通常分配给缓冲池。
为了提高大容量读取操作的效率,缓冲池被划分为可以容纳多行的页面。为了提高缓存管理的效率,缓冲池被实现为页面的链表;使用最近最少使用 (LRU) 算法的变体,很少使用的数据会从缓存中老化。
了解如何利用缓冲池将频繁访问的数据保留在内存中是MySQL调优的一个重要方面。
缓冲池使用 LRU 算法的变体作为列表进行管理。当需要空间向缓冲池添加新页面时,最近最少使用的页面将被逐出,并将新页面添加到列表的中间。这种中点插入策略将列表视为两个子列表:
-
在头部,最近访问的 新( “年轻” )页面的子列表
-
在尾部,是最近访问较少的旧页面的子列表

该算法将经常使用的页面保留在新的子列表中。旧的子列表包含不常用的页面;这些页面是被驱逐的候选页面。
默认情况下,该算法的运行方式如下:
-
缓冲池的 3/8 专用于旧子列表。
-
列表的中点是新子列表的尾部与旧子列表的头部相交的边界。
-
当
InnoDB将页面读入缓冲池时,它最初将其插入到中点(旧子列表的头部)。可以读取页面是因为用户启动的操作(例如 SQL 查询)需要该页面,或者作为 .NET 自动执行的预读InnoDB操作的一部分。 -
访问旧子列表中的页面使其变得 “年轻”,将其移动到新子列表的头部。如果该页是因为用户启动的操作需要而被读取的,则第一次访问会立即发生,并且该页会变为年轻页。如果由于预读操作而读取该页,则第一次访问不会立即发生,并且在该页被逐出之前可能根本不会发生。
-
当数据库运行时,缓冲池中未访问的页面会通过向列表尾部移动而“老化” 。新旧子列表中的页面随着其他页面的更新而老化。当页面在中点插入时,旧子列表中的页面也会老化。最终,未使用的页面到达旧子列表的尾部并被驱逐。
默认情况下,查询读取的页面会立即移动到新的子列表中,这意味着它们在缓冲池中停留的时间更长。例如,针对mysqldump操作或 SELECT不带子句的语句 执行的表扫描WHERE可以将大量数据放入缓冲池并逐出等量的旧数据,即使新数据不再使用。类似地,由预读后台线程加载且仅访问一次的页面将被移动到新列表的头部。这些情况可能会将经常使用的页面推送到旧的子列表,在那里它们会被驱逐。有关优化此行为的信息,请参阅 第 14.8.3.3 节,“使缓冲池防扫描”,以及 第 14.8.3.4 节,“配置 InnoDB 缓冲池预取(预读)”。
InnoDB标准监视器输出在BUFFER POOL AND MEMORY有关缓冲池 LRU 算法操作的部分中包含多个字段。有关详细信息,请参阅使用 InnoDB 标准监视器监视缓冲池。
您可以配置缓冲池的各个方面来提高性能。
-
理想情况下,您将缓冲池的大小设置为尽可能大的值,为服务器上的其他进程留下足够的内存来运行,而不会出现过多的分页。缓冲池越大,就越
InnoDB像内存数据库,从磁盘读取数据一次,然后在后续读取时从内存访问数据。请参见 第 14.8.3.1 节,“配置 InnoDB 缓冲池大小”。 -
在内存充足的 64 位系统上,您可以将缓冲池拆分为多个部分,以最大程度地减少并发操作之间对内存结构的争用。有关详细信息,请参见第 14.8.3.2 节 “配置多个缓冲池实例”。
-
您可以将频繁访问的数据保留在内存中,而不管操作活动是否突然出现峰值,这些操作会将大量不经常访问的数据带入缓冲池。有关详细信息,请参见 第 14.8.3.3 节 “使缓冲池防扫描”。
-
您可以控制如何以及何时执行预读请求,以异步方式将页面预取到缓冲池中,以预测很快需要这些页面。有关详细信息,请参见 第 14.8.3.4 节 “配置 InnoDB 缓冲池预取(预读)”。
-
您可以控制何时发生后台刷新以及是否根据工作负载动态调整刷新速率。有关详细信息,请参见 第 14.8.3.5 节 “配置缓冲池刷新”。
-
您可以配置如何
InnoDB保留当前缓冲池状态,以避免服务器重新启动后出现过长的预热期。有关详细信息,请参见 第 14.8.3.6 节 “保存和恢复缓冲池状态”。
InnoDB标准监视器输出(可使用 访问 SHOW ENGINE INNODB STATUS)提供有关缓冲池操作的指标。缓冲池指标位于标准监视器输出BUFFER POOL AND MEMORY部分 InnoDB:
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 2198863872
Dictionary memory allocated 776332
Buffer pool size 131072
Free buffers 124908
Database pages 5720
Old database pages 2071
Modified db pages 910
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 4, not young 0
0.10 youngs/s, 0.00 non-youngs/s
Pages read 197, created 5523, written 5060
0.00 reads/s, 190.89 creates/s, 244.94 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not
0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read
ahead 0.00/s
LRU len: 5720, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]下表描述了 InnoDB标准监视器报告的缓冲池指标。
标准监视器输出中提供的每秒平均值InnoDB基于自上次 InnoDB打印标准监视器输出以来经过的时间。
表 14.2 InnoDB 缓冲池指标
| 姓名 | 描述 |
|---|---|
| 分配的总内存 | 为缓冲池分配的总内存(以字节为单位)。 |
| 分配的字典内存 | 为数据字典分配的总内存(InnoDB以字节为单位)。 |
| 缓冲池大小 | 分配给缓冲池的总大小(以页为单位)。 |
| 空闲缓冲区 | 缓冲池空闲列表的总大小(以页为单位)。 |
| 数据库页面 | 缓冲池 LRU 列表的总大小(以页为单位)。 |
| 旧数据库页面 | 缓冲池旧 LRU 子列表的总大小(以页为单位)。 |
| 修改的数据库页面 | 缓冲池中当前修改的页数。 |
| 待读 | 等待读入缓冲池的缓冲池页数。 |
| 等待写入 LRU | 缓冲池中从 LRU 列表底部开始写入的旧脏页数。 |
| 等待写入刷新列表 | 检查点期间要刷新的缓冲池页数。 |
| 待写入单页 | 缓冲池内待处理的独立页写入数。 |
| 页面变得年轻 | 缓冲池 LRU 列表中年轻的页面总数(移动到“新”页面子列表的头部)。 |
| 页面制作不年轻 | 缓冲池 LRU 列表中未年轻化的页面总数(保留在“ old ”子列表中而未年轻化的页面)。 |
| 幼鸽/秒 | 每秒对缓冲池 LRU 列表中的旧页面进行的平均访问次数,导致页面年轻化。有关详细信息,请参阅此表后面的注释。 |
| 非幼鸟/秒 | 每秒对缓冲池 LRU 列表中的旧页面进行的平均访问次数,导致页面不成为年轻页面。有关详细信息,请参阅此表后面的注释。 |
| 已读页数 | 从缓冲池读取的总页数。 |
| 创建的页面 | 在缓冲池中创建的页面总数。 |
| 已写页数 | 从缓冲池写入的总页数。 |
| 读取/秒 | 每秒平均读取缓冲池页面数。 |
| 创建/秒 | 每秒创建的平均缓冲池页数。 |
| 写入/秒 | 每秒写入缓冲池页的平均数。 |
| 缓冲池命中率 | 从缓冲池读取的页面与从磁盘存储读取的页面的缓冲池页面命中率。 |
| 育雏率 | 页面访问的平均命中率导致页面年轻化。有关详细信息,请参阅此表后面的注释。 |
| 不(年轻化率) | 页面访问的平均命中率并未导致页面年轻化。有关详细信息,请参阅此表后面的注释。 |
| 预读页面 | 每秒预读操作的平均值。 |
| 页面被驱逐而无法访问 | 每秒平均逐出未从缓冲池访问的页面。 |
| 随机预读 | 随机预读操作的每秒平均值。 |
| LRU长度 | 缓冲池 LRU 列表的总大小(以页为单位)。 |
| unzip_LRU 长度 | 缓冲池 unzip_LRU 列表的长度(以页为单位)。 |
| 输入输出总和 | 访问的缓冲池 LRU 列表页面总数。 |
| 输入/输出电流 | 当前时间间隔内访问的缓冲池 LRU 列表页总数。 |
| I/O 解压总和 | 解压缩的缓冲池 unzip_LRU 列表页总数。 |
| I/O 解压当前 | 当前时间间隔内解压缩的缓冲池 unzip_LRU 列表页总数。 |
注意事项:
-
该
youngs/s指标仅适用于旧页面。它基于页面访问的数量。给定页面可以有多次访问,所有访问都会被计数。youngs/s如果在没有发生大型扫描时看到非常低的值,请考虑减少延迟时间或增加用于旧子列表的缓冲池的百分比。增加百分比会使旧子列表变大,从而使该子列表中的页面移动到尾部需要更长的时间,这增加了这些页面被再次访问并成为年轻页面的可能性。请参见 第 14.8.3.3 节“使缓冲池防扫描”。 -
该
non-youngs/s指标仅适用于旧页面。它基于页面访问的数量。给定页面可以有多次访问,所有访问都会被计数。如果在执行大型表扫描时没有看到更高的non-youngs/s值(以及更高的youngs/s值),请增加延迟值。请参见 第 14.8.3.3 节“使缓冲池防扫描”。 -
该
young-making速率考虑了所有缓冲池页面访问,而不仅仅是旧子列表中页面的访问。速率young-making和not速率通常不会合计到总体缓冲池命中率。旧子列表中的页面命中会导致页面移动到新子列表,但新子列表中的页面命中只会在距离头部一定距离时才会导致页面移动到列表的头部。 -
not (young-making rate)是由于未满足定义的延迟 innodb_old_blocks_time,或由于新子列表中的页面命中未导致页面移至头部而导致页面访问未导致页面年轻的平均命中率。此速率考虑了所有缓冲池页面访问,而不仅仅是旧子列表中页面的访问。
缓冲池服务器状态变量和 INNODB_BUFFER_POOL_STATS表提供了许多与 InnoDB标准监视器输出中相同的缓冲池指标。有关更多信息,请参见 例 14.10 “查询 INNODB_BUFFER_POOL_STATS 表”。
更改缓冲区是一种特殊的数据结构, 当辅助索引页不在 缓冲池中时,它会缓存这些页的更改。缓冲的更改可能由 INSERT、 UPDATE、 或 DELETE操作 (DML) 导致,稍后当其他读取操作将页面加载到缓冲池中时,这些更改将被合并。
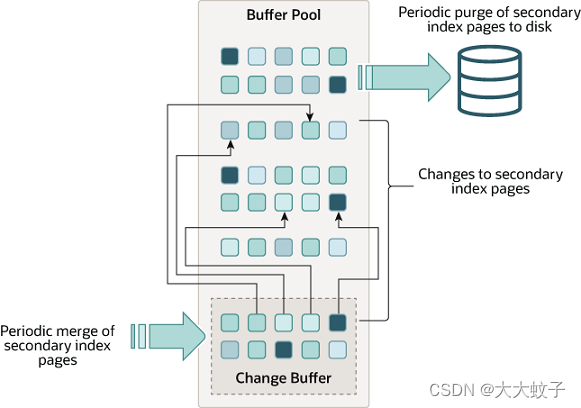
图片来自于官网原文
与聚集索引 不同,二级索引通常是非唯一的,并且插入二级索引的顺序相对随机。类似地,删除和更新可能会影响索引树中不相邻的二级索引页。当其他操作将受影响的页面读入缓冲池时,稍后合并缓存的更改可以避免从磁盘将辅助索引页读入缓冲池所需的大量随机访问 I/O。
系统大部分空闲时或缓慢关闭期间运行的清除操作会定期将更新的索引页写入磁盘。与立即将每个值写入磁盘相比,清除操作可以更有效地写入一系列索引值的磁盘块。
当有许多受影响的行和大量二级索引需要更新时,更改缓冲区合并可能需要几个小时。在此期间,磁盘 I/O 会增加,这可能会导致磁盘绑定查询显着减慢。提交事务后,甚至在服务器关闭并重新启动后,更改缓冲区合并也可能继续发生(有关更多信息,请参阅第 14.22.2 节“强制 InnoDB 恢复” )。
在内存中,更改缓冲区占用缓冲池的一部分。在磁盘上,更改缓冲区是系统表空间的一部分,当数据库服务器关闭时,索引更改将被缓冲在系统表空间中。
更改缓冲区中缓存的数据类型由 innodb_change_buffering变量控制。有关更多信息,请参阅 配置更改缓冲。您还可以配置最大更改缓冲区大小。有关详细信息,请参阅 配置更改缓冲区最大大小。
如果索引包含降序索引列或主键包含降序索引列,则辅助索引不支持更改缓冲。
有关更改缓冲区的常见问题解答,请参阅第 A.16 节“MySQL 5.7 常见问题解答:InnoDB 更改缓冲区”。
当对表执行INSERT、 UPDATE、 和 DELETE操作时,索引列的值(特别是辅助键的值)通常处于未排序的顺序,需要大量 I/O 来更新辅助索引。当相关 页面不在 缓冲池中时,更改 缓冲区会缓存对辅助索引条目的更改,从而通过不立即从磁盘读取页面来避免昂贵的 I/O 操作。当页面加载到缓冲池中时,缓冲的更改将被合并,更新的页面稍后会刷新到磁盘。这InnoDB当服务器几乎空闲时以及 缓慢关闭期间,主线程合并缓冲的更改。
因为它可以减少磁盘读取和写入,所以更改缓冲对于 I/O 密集型工作负载最有价值;例如,具有大量 DML 操作(例如批量插入)的应用程序可以从更改缓冲中受益。
但是,更改缓冲区占用了缓冲池的一部分,从而减少了可用于缓存数据页的内存。如果工作集几乎适合缓冲池,或者表的二级索引相对较少,则禁用更改缓冲可能会很有用。如果工作数据集完全适合缓冲池,则更改缓冲不会施加额外的开销,因为它仅适用于不在缓冲池中的页面。
该变量控制 执行更改缓冲innodb_change_buffering 的程度。InnoDB您可以启用或禁用插入、删除操作(当索引记录最初标记为删除时)和清除操作(当索引记录被物理删除时)的缓冲。更新操作是插入和删除的组合。默认 innodb_change_buffering值为 all。
允许的innodb_change_buffering 值包括:
-
all默认值:缓冲区插入、删除标记操作和清除。
-
none不要缓冲任何操作。
-
inserts缓冲区插入操作。
-
deletes缓冲区删除标记操作。
-
changes缓冲插入和删除标记操作。
-
purges缓冲在后台发生的物理删除操作。
innodb_change_buffering您可以在 MySQL 选项文件(my.cnf或 )中 设置 变量my.ini,或者使用语句动态更改它 SET GLOBAL ,这需要足够的权限来设置全局系统变量。请参见 第 5.1.8.1 节“系统变量权限”。更改设置会影响新操作的缓冲;现有缓冲条目的合并不受影响。
该innodb_change_buffer_max_size 变量允许将更改缓冲区的最大大小配置为缓冲池总大小的百分比。默认情况下, innodb_change_buffer_max_size设置为 25。最大设置为 50。
考虑 innodb_change_buffer_max_size在具有大量插入、更新和删除活动的 MySQL 服务器上进行增加,其中更改缓冲区合并与新的更改缓冲区条目保持同步,导致更改缓冲区达到其最大大小限制。
innodb_change_buffer_max_size考虑在具有用于报告的静态数据的 MySQL 服务器上 减少 ,或者如果更改缓冲区消耗了太多与缓冲池共享的内存空间,导致页面比预期更快地从缓冲池中老化。
使用代表性工作负载测试不同的设置以确定最佳配置。该 innodb_change_buffer_max_size 变量是动态的,允许在不重新启动服务器的情况下修改设置。
以下选项可用于更改缓冲区监控:
-
InnoDB标准监视器输出包括更改缓冲区状态信息。要查看监控数据,请发出该SHOW ENGINE INNODB STATUS语句。mysql> SHOW ENGINE INNODB STATUS\G更改缓冲区状态信息位于
INSERT BUFFER AND ADAPTIVE HASH INDEX标题下方,类似于以下内容:------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1, free list len 0, seg size 2, 0 merges merged operations:insert 0, delete mark 0, delete 0 discarded operations:insert 0, delete mark 0, delete 0 Hash table size 4425293, used cells 32, node heap has 1 buffer(s) 13577.57 hash searches/s, 202.47 non-hash searches/s有关更多信息,请参见 第 14.18.3 节 “InnoDB 标准监视器和锁定监视器输出”。
-
信息架构 INNODB_METRICS表提供了标准监视器输出中的大部分数据点
InnoDB以及其他数据点。要查看更改缓冲区指标及其描述,请发出以下查询:mysql> SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME LIKE '%ibuf%'\G有关INNODB_METRICS表使用信息,请参阅 第 14.16.6 节 “InnoDB INFORMATION_SCHEMA 指标表”。
-
信息架构 INNODB_BUFFER_PAGE表提供有关缓冲池中每个页面的元数据,包括更改缓冲区索引和更改缓冲区位图页面。更改缓冲区页由 标识
PAGE_TYPE。IBUF_INDEX是更改缓冲区索引页面的页面类型,IBUF_BITMAP是更改缓冲区位图页面的页面类型。警告查询INNODB_BUFFER_PAGE 表可能会带来显着的性能开销。为了避免影响性能,请在测试实例上重现您要调查的问题并在测试实例上运行查询。
例如,您可以查询该 INNODB_BUFFER_PAGE表以确定页面的大致数量
IBUF_INDEX以及IBUF_BITMAP占缓冲池页面总数的百分比。mysql> SELECT (SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE PAGE_TYPE LIKE 'IBUF%') AS change_buffer_pages,(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE) AS total_pages,(SELECT ((change_buffer_pages/total_pages)*100))AS change_buffer_page_percentage; +---------------------+-------------+-------------------------------+ | change_buffer_pages | total_pages | change_buffer_page_percentage | +---------------------+-------------+-------------------------------+ | 25 | 8192 | 0.3052 | +---------------------+-------------+-------------------------------+有关该 INNODB_BUFFER_PAGE表提供的其他数据的信息,请参阅 第 24.4.2 节 “INFORMATION_SCHEMA INNODB_BUFFER_PAGE 表”。有关相关使用信息,请参阅 第 14.16.5 节,“InnoDB INFORMATION_SCHEMA 缓冲池表”。
-
性能模式 提供更改缓冲区互斥锁等待检测,以实现高级性能监控。要查看更改缓冲区检测,请发出以下查询:
mysql> SELECT * FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%wait/synch/mutex/innodb/ibuf%'; +-------------------------------------------------------+---------+-------+ | NAME | ENABLED | TIMED | +-------------------------------------------------------+---------+-------+ | wait/synch/mutex/innodb/ibuf_bitmap_mutex | YES | YES | | wait/synch/mutex/innodb/ibuf_mutex | YES | YES | | wait/synch/mutex/innodb/ibuf_pessimistic_insert_mutex | YES | YES | +-------------------------------------------------------+---------+-------+有关监视
InnoDB互斥等待的信息,请参阅 第 14.17.2 节,“使用性能模式监视 InnoDB 互斥等待”。
自适应哈希索引能够InnoDB在具有适当的工作负载组合和足够的缓冲池内存的系统上执行更像内存数据库的操作,而不会牺牲事务功能或可靠性。自适应哈希索引由 innodb_adaptive_hash_index 变量启用,或在服务器启动时由 关闭 --skip-innodb-adaptive-hash-index。
根据观察到的搜索模式,使用索引键的前缀构建哈希索引。前缀可以是任意长度,并且可能只有B树中的某些值出现在哈希索引中。哈希索引是根据需要为经常访问的索引页构建的。
如果表几乎完全适合主内存,则哈希索引可以通过直接查找任何元素、将索引值转换为某种指针来加速查询。 InnoDB有一个监视索引搜索的机制。如果InnoDB注意到查询可以从构建哈希索引中受益,它会自动执行此操作。
对于某些工作负载,哈希索引查找所带来的加速远远超过了监视索引查找和维护哈希索引结构的额外工作。在繁重的工作负载(例如多个并发联接)下,对自适应哈希索引的访问有时会成为争用的根源。LIKE使用运算符和通配符的查询 % 往往也不会受益。对于无法从自适应哈希索引中受益的工作负载,将其关闭可以减少不必要的性能开销。由于很难提前预测自适应哈希索引功能是否适合特定系统和工作负载,因此请考虑在启用和禁用该功能的情况下运行基准测试。
在MySQL 5.7中,自适应哈希索引功能是分区的。每个索引都绑定到一个特定的分区,并且每个分区都由单独的锁存器保护。分区由变量控制 innodb_adaptive_hash_index_parts 。在早期版本中,自适应哈希索引功能由单个锁存器保护,这在繁重的工作负载下可能成为争论点。该 innodb_adaptive_hash_index_parts 变量默认设置为 8。最大设置为 512。
SEMAPHORES您可以在输出部分 监视自适应哈希索引的使用和争用 SHOW ENGINE INNODB STATUS。如果有大量线程等待在 中创建的 rw-latches btr0sea.c,请考虑增加自适应哈希索引分区的数量或禁用自适应哈希索引。
有关哈希索引的性能特征的信息,请参阅第 8.3.8 节“B 树和哈希索引的比较”。
日志缓冲区是保存要写入磁盘上日志文件的数据的内存区域。日志缓冲区大小由变量定义 innodb_log_buffer_size。默认大小为 16MB。日志缓冲区的内容会定期刷新到磁盘。大型日志缓冲区允许大型事务运行,而无需在事务提交之前将重做日志数据写入磁盘。因此,如果您有更新、插入或删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘 I/O。
该 innodb_flush_log_at_trx_commit 变量控制如何将日志缓冲区的内容写入并刷新到磁盘。该 innodb_flush_log_at_timeout 变量控制日志刷新频率。
有关相关信息,请参阅 内存配置和 第 8.5.4 节 “优化 InnoDB 重做日志记录”。