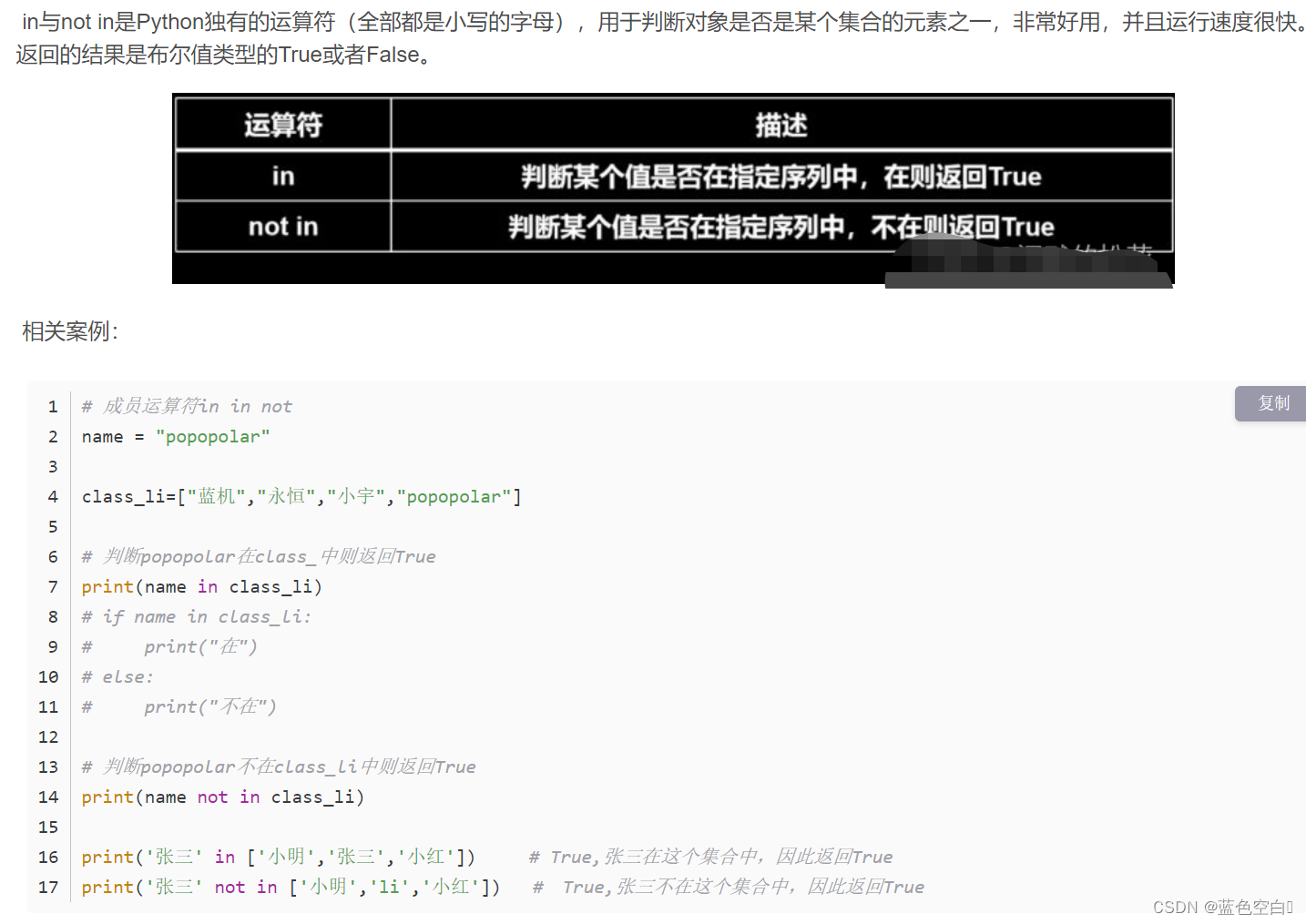
作者:Zichen Liu, Siyi Li, Wee Sun Lee, Shuicheng YAN, Zhongwen Xu
论文链接:Efficient Offline Policy Optimization with a Learned Model | OpenReview
发表时间: ICLR 2023年1月21日
代码链接:https://github.com/sail-sg/rosmo
摘要
MuZero的离线版本算法(MuZero Unplugged)为基于日志数据的离线策略学习提供了一种很有前途的方法。它使用学习模型进行蒙特卡罗分析树搜索( MCTS ),并利用重新分析(Reanalyze)算法从离线数据中学习。为了获得良好的性能,MCTS需要精确的学习模型和大量的仿真,从而耗费巨大的计算时间。
本文研究了MuZero的离线版本算法(MuZero Unplugged)在离线RL设置下可能无法正常工作的几个假设,包括
1 )数据覆盖范围有限的学习;
2 )从随机环境的离线数据中学习;
3 )给定离线数据,模型参数化不当;
4 )具有较低的计算预算。
我们提出使用正则化的一步前瞻方法来解决上述问题。而不是使用昂贵的MCTS进行规划,我们使用学习到的模型来构建基于一步滚动的优势估计。政策改进正朝着通过数据集的正则化来最大化估计优势的方向发展。我们在BSuite环境下进行了大量的实证研究,以验证假设,然后在RL油墨塞住孔版网孔的情况Atari基准测试集上运行我们的算法。实验结果表明,即使在学习到的模型不准确的情况下,本文提出的方法也能获得稳定的性能。在大规模数据集Atari上,该方法比MuZero油墨塞住孔版网孔的情况提高了43 %。最重要的是,与MuZero离线(MuZero Unplugged)的情况(即17.8小时)相比,它仅使用5.6 %的墙钟时间(即1小时),在相同的硬件和软件栈下实现了150 %的IQM归一化分数。我们的实现是开放源代码的https://github.com/sail-sg/rosmo。
论文概述
这篇论文主要讲了一种用于离线强化学习的高效策略优化方法,名为ROSMO(Regularized One-Step Model-based algorithm for Offline reinforcement learning)。该方法通过一步前瞻搜索来寻找改进目标,并使用行为正则化来约束策略。
论文的创新点包括:
采用一步前瞻搜索,比MCTS更高效且不易受到累积推理误差影响;
引入行为正则化来约束策略,以避免过度偏离行为策略;
在多个基准测试中,ROSMO表现出最佳性能,且实验成本较低。
具体解决方法如下:
使用一步前瞻搜索来寻找改进目标,而不是使用MCTS;
在策略优化过程中加入行为正则化,以约束策略不过分偏离行为策略;
通过实验证明ROSMO具有更高的计算效率、对累积推理误差更具鲁棒性以及适当的策略约束。
本文所采取的优化措施包括:
① 使用one-step模型产生的结果来提升策略学习而不使用MCTS
② 使用策略正则化的方式来减缓OOD的影响
前瞻搜索(Look-ahead Search)是一种通过在状态空间中探索未来状态以找到最佳行动序列的方法。在强化学习(Reinforcement Learning, RL)中,前瞻搜索用于根据当前策略和模型预测未来奖励和状态,从而更新策略以获得更高的回报。这种方法可以在离线强化学习(Offline RL)和在线强化学习(Online RL)中使用,以提高智能体在不同任务中的性能。典型的前瞻搜索算法包括蒙特卡洛树搜索(MCTS)和随机采样方法,如蒙特卡洛树搜索(RS)。
论文贡献
- 分析了MuZero Unplugged在离线强化学习中的局限性,包括计算效率、对累积推理错误的敏感性以及缺乏适当的正则化。
- 提出了ROSMO(Regularized One-Step Model-based algorithm for Offline reinforcement learning),一种基于值等价原则的正则化一步模型算法,以解决上述问题。
- 通过实验验证了ROSMO相较于MuZero Unplugged及其他离线RL方法在标准离线Atari基准上的优越性能。
1.INTRODUCTION
-
离线强化学习(Offline RL)的目的是从收集的静态经验中学习高回报策略,而无需代理与环境进行昂贵或危险的互动。
-
离线RL在机器人和医疗等领域具有广泛的应用潜力,但挑战性很高。
-
仅依赖静态数据集进行价值或策略学习时,离线RL中的代理容易出现动作值过高估计或在分布之外(OOD)区域进行不当推断。
-
先前的研究通过施加特定的价值惩罚或策略约束来解决这些问题,取得了令人鼓舞的结果。
-
基于模型的强化学习(MBRL)方法在离线RL问题中表现出了有效性。
-
最先进的离线RL MBRL算法是MuZero Unplugged,它是其在线RL前身MuZero的简单扩展。
-
MuZero Unplugged通过学习动态和进行蒙特卡洛树搜索(MCTS)规划,在完全离线的设置下提高了价值和策略。
2.BACKGROUND
离线强化学习(Offline RL):离线强化学习的目标是仅通过收集到的静态经验,在不与环境发生过昂贵或不安全交互的情况下,学习到高回报的策略。
基于模型的强化学习(Model-based RL):基于模型的强化学习方法在离线强化学习问题中表现出色。MuZero Unplugged是一种最先进的基于模型的离线强化学习算法,它通过在完全离线的设置下学习动态并进行蒙特卡洛树搜索(MCTS)规划,以改进价值和策略。
挑战和问题:MCTS需要准确的学习模型来生成改进的学习目标。然而,在离线RL设置中,特别是当数据覆盖较低时,学习一个准确的模型本身就具有挑战性。此外,MuZero Unplugged不适合在随机环境中计划动作序列。
ROSMO算法:为解决这些问题,作者提出了一种名为ROSMO(Regularized One-Step Model-based algorithm for Offline reinforcement learning)的算法,它利用一步前瞻来寻找改进目标,并通过行为正则化对策略进行调整。ROSMO在计算效率、对累积推断误差的鲁棒性以及策略约束方面具有优势。
学习强化学习应该先学一下马尔可夫过程
OFFLINE POLICY IMPROVEMENT VIA LATENT DYNAMICS MODEL
给定轨迹: τi=o1,a1,r1,...,oTi,aTi,rTi∈D,t∈[1,Ti] ,通过表示函数获得隐变量:
hθ:st0=hθ(ot)
使用dynamic model来产生imaginary rollout:
rtk+1,stk+1=gθ(stk,at+k)
其中 k∈[0,K] 表示imagination rollout horizon的深度
学习一个预测函数用于衡量策略和价值函数:
πtk,vtk=fθ(stk)
学习阶段,神经网络参数的更新使用梯度下降,损失函数如下:

其中第一项代表奖励的损失函数, rt+kenv 指的是环境中产生的真实reward target,第二项和第三项代表价值函数和策略函数的损失函数,其中:
zt+k,pt+k=I(g,f)θ′(st+k)
代表使用improvement operator I利用target网络的参数产生的输出,作为label
dynamic model产生的下一时刻状态的预测并没有使用重建进行监督,而是基于value equivalence principle使用t时刻rollout深度为k的策略和价值的预测与真实环境 t+k 时刻的target形成监督
improvement operator的一个可选方案即是MCTS
Monte-Carlo Tree Search For Policy Improvement
每次遍历过程current从根状态开始,若current不是指向叶节点,则通过下式的argmax形式选取子节点更新current

若指向叶节点,则判断是否已经被访问过。若没有被访问过,则直接利用dynamic model产生rollout到达终止状态,并反向传播至根节点更新访问频率和折扣期望回报;若被访问过,则首先对所有合理动作产生expansion扩容树,而后选择一个子节点做为叶节点进行rollout并反向传播。该过程完成一次traverse
当traverse次数达到N后,最终的policy target和value target可通过如下方式获取:

3.METHODOLOGY
3.1 MOTIVATION
分析了现有的基于模型的离线强化学习(offline RL)算法MuZero Unplugged的局限性。主要问题包括:
- 计算效率低:MuZero Unplugged使用蒙特卡洛树搜索(MCTS)进行政策改进,这需要大量计算资源。
- 对累积推断错误敏感:在离线RL设置中,MCTS可能进入数据覆盖范围之外的不安全区域,导致错误的政策和值估计。
- 缺乏适当的正则化:MuZero Unplugged缺乏适当的正则化来约束策略,以应对分布偏移。
为了解决这些问题,作者提出了ROSMO算法,即基于值等价原理的正则化一步模型算法。ROSMO相较于MuZero Unplugged具有以下优势:
- 计算效率高:ROSMO使用一步前瞻搜索,比MCTS更高效。
- 对累积推断错误具有鲁棒性:ROSMO通过一次前瞻搜索找到改进目标,受累积推断错误的影响较小。
- 适当的正则化:ROSMO使用行为正则化来约束策略,以应对分布偏移。
图1 (左)说明了当MCTS作为改进算子出错时。假设通过h θ对观测值进行编码,得到潜在状态st,st + 1,st + 2,..,我们称之为观测节点,如图所示。左图中的点状边和节点在节点st处描述了一个简单的MCTS搜索树,仿真预算N = 7,深度d = 3。我们将未被学习模型控制的状态{ stk }称为想象节点,k = 1,2,3表示搜索深度。距离观测节点较远的区域和阴影区域以外的区域被认为是不安全区域,在这些区域收集的数据点很少或没有。直觉上,对不安全区域中想象节点的政策和价值预测很可能是错误的,奖励和下一状态想象也可能是错误的。这使得式( 3 )得到的改进目标不可靠。此外,我们还认为,MuZero Unplugged缺乏适当的正则化,限制了政策远离行为政策,以对抗分配转变。在他们的算法中,' reg = c | | θ | | 2(式中:)只是为了学习的稳定性而施加权重衰减。
下图展示了MCTS将可能出现extrapolation error的直观原因(将使得(3)的target值不准确),且one-step将会明显的降低这种情况的发生概率,并且本文认为原始的MuZero Unplugged缺乏对行为策略和目标策略更新的限制用于防止分布迁移;(1)中的正则化损失只能使得训练稳定,防止过拟合

Figure 1: An illustration on the differences of Monte-Carlo Tree Search (left) and one-step look-ahead (right) for policy improvement. With limited offline data coverage, the search entering regions beyond the observed data may expand nodes on which fθ fails to provide accurate estimations, and gθ even leads to a worse region. These errors are compounded along the path as the search gets deeper, leading to detrimental improvement targets. One-step look-ahead is less likely to go outside the safe region. Illustrations are best viewed on screen.
图1:蒙特卡洛树搜索(左)和一步前瞻(右)对政策改进的差异图。在离线数据覆盖范围有限的情况下,搜索进入观测数据之外的区域可能会扩大节点,f θ无法提供准确的估计,g θ甚至会导致更糟糕的区域。随着搜索的深入,这些误差沿着路径不断加剧,导致不利的改进目标。一步向前看更不容易走出安全区域。插画最好在屏幕上观看。
总体算法框架
本文的总体算法框架如下,蓝色小三角包含了改进内容

3.2 A SIMPLE AND EFFICIENT IMPROVEMENT OPERATOR
主要讨论了一种简单且高效的改进算子,作为在离线强化学习中的一种替代方案。这种改进算子通过以下方法实现:
对模型进行一次展开,以获取改进方向;
使用行为正则化调整当前策略,使其接近改进方向。
这种方法相较于 MuZero Unplugged 的 Monte-Carlo Tree Search (MCTS) 更加高效,且受到累积推理误差的影响较小。通过一次展开来寻找改进目标,可以在更安全的区域内进行策略更新,从而提高策略质量。
MuZero Unplugged利用复杂的MCTS来达成该目的,但是其会受到extrapolation error和组合误差的影响。原始的策略损失函数为交叉熵,如下所示:

而本文的策略更新是希望最小化one-step改进的target与策略的交叉熵,如下:

在状态s下,策略的target p可以使用下式衡量

其中 πprior 一般利用target network实现, advg(s,a)=qg(s,a)−v(s) 是优势函数值,其中两项的获取方式如下:【one-step look ahead】
rg,sg′=gθ(s,a), qg(s,a)=rg+γfθ,v(sg′), v(s)=fθ,v(s)
其中Z是一个归一化量,用于保证是合适的概率分布
(6)式直观的看表明了能够对先验概率分布进行调节,具有正优势的动作将会提升,负优势的动作将会下降
价值函数的target利用n-step return,如下。其中 vt+n=fθ′,v(st+n) , rt′ 来源于数据集

当动作空间较大时,计算(5)式需要遍历整个动作空间,计算资源消耗过大,因此本文采取近似方法,采样 N≤|A| 个动作,满足 a(i)∼πprior(s) ,(5)式计算如下

归一化因子Z可以用下式进行估计:

3.3 BEHAVIOR REGULARIZATION FOR POLICY CONSTRAINT
讨论了行为正则化以约束策略的问题。在 MuZero Unplugged 中,策略更新通过最小化标准访问计数和参数策略分布之间的交叉熵进行。然而,这种方法缺乏适当的正则化来约束策略远离行为策略以应对分布漂移问题。为了解决这个问题,作者在策略 π 上施加了一种简单的行为正则化,让学习到的策略保持接近行为策略。这种行为正则化与 Siegel 等人的方法类似,但作者没有学习一个显式的行为策略。相反,他们直接在 π 上应用了一个优势过滤回归,而不需要学习一个独立的行为策略。
虽然上述算法仅考虑了one-step ahead,但是仍然可能出现超出offline dataset的情况。为了进一步降低extrapolation error,本文对策略进行正则化,约束行为策略的分布与目标策略的分布接近
不过本文没有显式的学习一个行为分布,而是使用以下方式直接基于当前策略 π 构造优势损失,该损失可看作最大化由优势过滤的log概率,其中 H(x)=1x>0

Experiment
4.1 HYPOTHESIS VERIFICATION
为了说明ROSMO相较于MuZero Unplugged的优势,本文展开了四点假设用于验证:
(1) MuZero Unplugged fails to perform well in a low-data regime
随着数据覆盖的降低,本文认为MuZero Unplugged将表现很差,这是因为MCTS将会很容易陷入不安全的区域(extrapolation error),以下(a)图展示了本文的方法将比MuZero Unplugged更可靠

Figure 2: (a) IQM normalized score with different data coverage. (b) IQM normalized score with different dynamics model capacities. (c) IQM normalized score of MuZero Unplugged with different simulation budgets (N ) and search depths (d).
图2:( a )不同数据覆盖率下的IQM标准化得分。( b )不同动力学模型容量下的IQM归一化得分。( c )不同模拟预算( N )和搜索深度( d )下MuZero油墨塞住孔版网孔的情况的IQM归一化得分。
(2)ROSMO is more robust in learning from stochastic transitions than MuZero Unplugged:
为了评测,在收集经验过程中为动作添加噪声,发现ROSMO对噪声的敏感度不高。

(3)MuZero Unplugged suffers from dynamics mis-parameterization while ROSMO is less affected
学习模型的参数不合适在model-based问题中起着至关重要的作用,因为欠拟合或过拟合将严重影响整体算法的性能。本文假设MuZero Unplugged相较于ROSMO对模型的参数更加敏感,如Fig2(b)所示,ROSMO比MuZero效果更好。
(4)MuZero Unplugged is sensitive to simulation budget and search depth
在Online的情况下,一些工作表明MuZero对simulation budget较为敏感,但是对rollout的depth不敏感。不过本文认为MuZero Unplugged对二者都很敏感,因为较深的rollout将会导致extrapolation error积累。从Fig(c)图的实验说明,当N较大且深度较少的情况下性能较好,这也印证了one-step look-ahead的必要性。
4.2 BENCHMARK RESULTS
- 基线方法:包括行为克隆(Behavior Cloning)和保守Q学习(Conservative Q-Learning,简称CQL)。
- 消融研究:对ROSMO进行了多个消融研究,包括数据覆盖、学习效率、模型累积错误和解耦ROSMO。
- 主要结果:展示了ROSMO与其他基线方法在BSuite基准测试中的性能。ROSMO在catch和mountain car任务中取得了最高的回合回报,且标准差最低。对于cartpole任务,CRR的表现略好于ROSMO,但我们仍然观察到ROSMO明显优于其他基线方法。
- 对MuZero Unplugged的敏感性分析:分析了MuZero Unplugged对模拟预算和搜索深度的敏感性。结果表明,当模拟预算较低时,MuZero Unplugged无法学习,而在模拟预算较高但搜索深度较深时,其表现较差。这进一步支持了在一步模型中进行改进的方法。
baseline:BC CQL CRR MZU
发现虽然CRR比本文的方法稍微好一点,但是本文的方法比其它方法都好很多

Table 2: BSuite benchmark results. Averaged episode returns measured at the end of training (200K steps) across 5 seeds.
表2:BSuite基准测试结果。在训练结束时( 200K步)测量5个种子的平均情节回报率。
Main results.
表2展示了我们的算法和其他基线方法的BSuite基准测试结果。ROSMO以最低的标准差实现了最高的渔获量和山地车回报率。对于cartpole,CRR的表现略好于ROSMO,但我们仍然可以观察到我们的表现明显优于其他基线。
下图展示出ROSMO的最终性能(IQM归一化分数)和采样效率都比较击败了baseline

Figure 3: Atari benchmark results. Aggregated IQM normalized score of different algorithms in terms of (left) sample efficiency and (right) wall-clock efficiency.
图3:Atari基准测试结果。在(左)样本效率和(右)壁时钟效率方面,对不同算法的聚合IQM进行了归一化评分。
Main results.
图3 (左)给出了关于学习器更新步骤的学习曲线,可以清楚地看到,ROSMO优于所有基线,并取得了最佳的学习效率。就最终的IQM归一化得分而言,所有离线RL算法都优于行为克隆基线,这表明当数据集包含不同质量的轨迹时,奖励信号是非常有用的。ROSMO获得了194 %的最终IQM标准化分数,优于MuZero Unplugged的情况( 151 % )、Critic Regularized Regression ( 105 % )和Conservative Q-Learning ( 83.5 % )。除了最高的最终性能,作者还注意到ROSMO在所有比较的方法中学习效率最高。
图3 (右)对比了相同硬件资源下不同算法的墙钟效率。值得注意的是,与MuZero Unplugged的情况相比,ROSMO仅使用5.6 %的壁钟时间,即可达到150 %的IQM标准化得分。通过轻量级的一步前瞻设计,基于模型的ROSMO消耗了与无模型方法相似的学习时间,拓宽了其对离线RL研究和实际应用的适用性。
Ablations.

Figure 4: Learning curves of IQM normalized score on MsPacman. (a) Comparison of ROSMO and MuZero Unplugged in low data regime. (b) Comparison of ROSMO, MuZero Unplugged and MZU-Q when limiting the number of simulations (number of samples) to be N = 4. (c) Comparison of ROSMO and MuZero Unplugged when the model is unrolled with different steps for learning. (d) Ablation of the one-step policy improvement and the behavior regularization.
图4:IQM标准化得分在MsPacman上的学习曲线。( a ) ROSMO和MuZero Unplugged的情况在低数据率下的比较。( b )比较了ROSMO,MuZero Unplugged的情况和MZU - Q在限制模拟次数(样本数)为N = 4时的表现。( c ) ROSMO和MuZero Unplugged的情况在模型展开不同步骤学习时的比较。( d )消融"一步到位"的政策改进和行为规则化。
① low-data regime: 本文的方法在10%和1%的low-data-regime情况下都比MuZero Unplugged更好,如(a)图
② 在simulation budget = 4的情况下比较,发现本文的方法性能更好,如(b)图
③ 为了减轻组合误差的影响,考虑multi-step过程,发现ROSMO能够较好的对抗组合误差,而MZU不行,如(c)图
④ 测试了策略正则化的有效性,与之对比的是OneStep(完全没有正则化项);Behaviour(通过行为正则化);CRR(一种Behavior的变体),如(d)图展示了本文方法的有效性
CONCLUSION
首先,作者通过实证验证了关于MuZero Unplugged算法在离线RL设置中可能失败的假设。接下来,作者提出了一种名为ROSMO(Regularized One-Step Model-based Offline Reinforcement Learning)的有效算法,该算法采用了更简单、更高效的一步先进方法来提供策略改进。实验结果表明,ROSMO在BSuite环境和大规模RL Unplugged Atari基准测试中的表现优于MuZero Unplugged和其他离线RL方法。最后,作者得出结论,在低计算资源下,可以实现高性能且易于理解的基于模型的离线RL算法。




![[Unity]实时阴影技术方案总结](https://img-blog.csdnimg.cn/direct/7708bb572f7e4a43845a1b636394a17b.png)

