基于 LightGBM 的系统访问风险识别
文章目录
- 基于 LightGBM 的系统访问风险识别
- 一、课题来源
- 二、任务描述
- 三、课题背景
- 四、数据获取分析及说明
- (1)登录https://www.datafountain.cn并获取相关数据
- (2)数据集文件说明
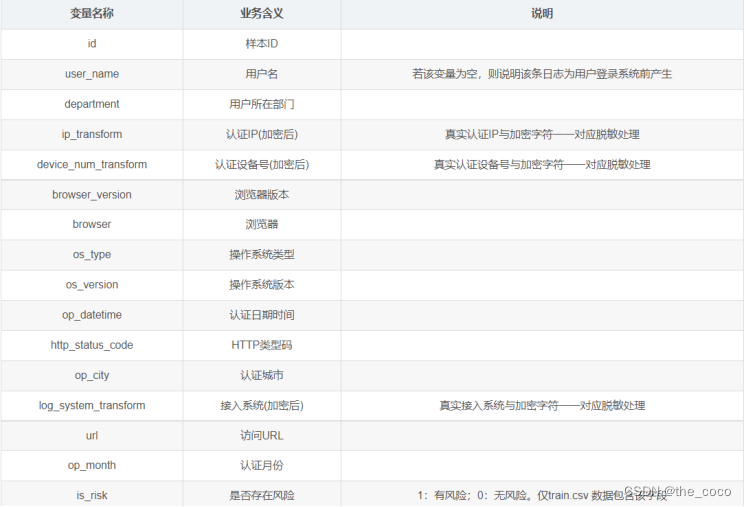
- (3)训练集和测试集含义说明
- 五、实验过程详细描述及程序清单
- (1)数据处理
- (2)特征抽取
- (3)模型训练
- (4)预测
- 六、个人总结
- 七、源码
一、课题来源
分类预测/回归预测相关内容,从阿里天池或datafountain下载作业数据datafountain:系统访问风险识别
二、任务描述
系统访问风险识别
(1)本赛题中,参赛团队将基于用户历史的系统访问日志及是否存在风险标记等数据,结合行业知识,构建必要的特征工程,建立机器学习、人工智能或数据挖掘模型,并用该模型预测将来的系统访问是否存在风险。
(2)本赛题数据是从竹云日志库中抽取某公司一定比例的员工从2022年1月到6月的系统访问日志数据,主要涉及认证日志与风险日志数据。部分字段经过一一对应脱敏处理,供参赛队伍使用。其中认证日志是用户在访问应用系统时产生的行为数据,包括用户名、认证时间、认证城市、接入系统、访问URL等关键信息。
三、课题背景
随着国家、企业对安全和效率越来越重视,作为安全基础设施之一——统一身份管理(IAM,Identity and Access Management)系统也得到越来越多的关注。 在IAM领域中,其主要安全防护手段是身份鉴别,身份鉴别主要包括账密验证、扫码验证、短信验证、人脸识别及指纹验证等方式。这些身份鉴别方式一般可分为三类,即用户所知(如口令)、所有(如身份证)、特征(如人脸识别及指纹验证)。这些鉴别方式都有其各自的缺点——比如口令,强度高了不容易记住,强度低了又容易丢;又比如人脸识别,做活体验证用户体验不好,静默检测又容易被照片、视频、人脸模型绕过。也因此,在等保2.0中对于三级以上系统要求必须使用两种及以上的鉴别方式对用户进行身份鉴别,以提高身份鉴别的可信度,这种鉴别方式也被称为双因素认证。
对用户来说,双因素认证在一定程度上提高了安全性,但也极大地降低了用户体验。也因此,IAM厂商开始参考用户实体行为分析(UEBA,User and Entity Behavior Analytics)、用户画像等行为分析技术,来探索一种既能确保用户体验,又能提高身份鉴别可信度的方法。而在当前IAM的探索过程中,目前最容易落地的方法是基于规则的行为分析技术,因为它可理解性较高,且容易与其它身份鉴别方式进行联动。
但基于规则的行为分析技术局限性也很明显,首先这种技术是基于经验的,有“宁错杀一千,不放过一个”的特点,其次它也缺少从数据层面来证明是否有人正在尝试窃取或验证非法获取的身份信息,又或者正在使用窃取的身份信息。鉴于此,我们举办这次竞赛,希望各个参赛团队利用竞赛数据和行业知识,建立机器学习、人工智能或数据挖掘模型,来弥补传统方法的缺点,从而解决这一行业难题。
四、数据获取分析及说明
本赛题数据是从竹云日志库中抽取某公司一定比例的员工从2022年1月到6月的系统访问日志数据,主要涉及认证日志与风险日志数据。部分字段经过一一对应脱敏处理,供参赛队伍使用。其中认证日志是用户在访问应用系统时产生的行为数据,包括用户名、认证时间、认证城市、接入系统、访问URL等关键信息。
(1)登录https://www.datafountain.cn并获取相关数据
找不到数据集的可以私信我。
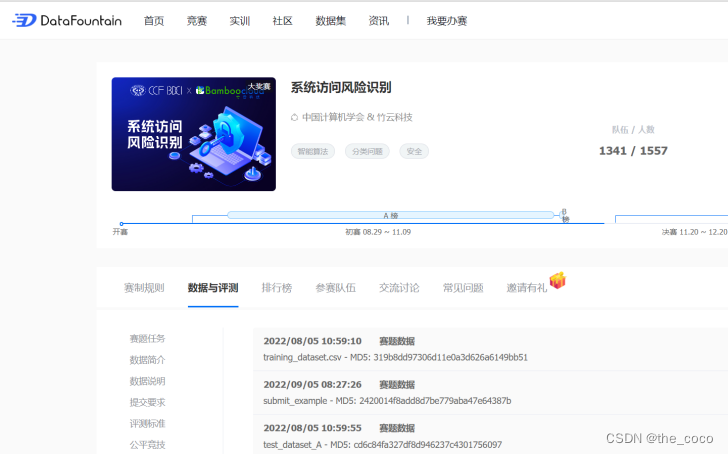
(2)数据集文件说明

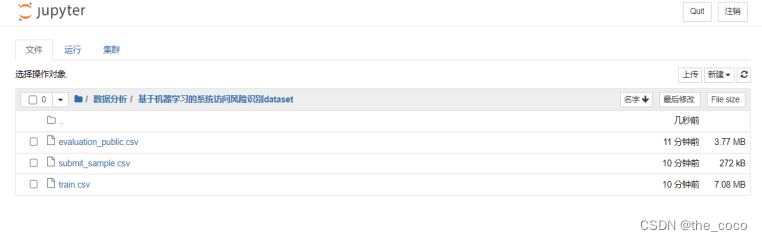
(3)训练集和测试集含义说明
五、实验过程详细描述及程序清单
(1)数据处理
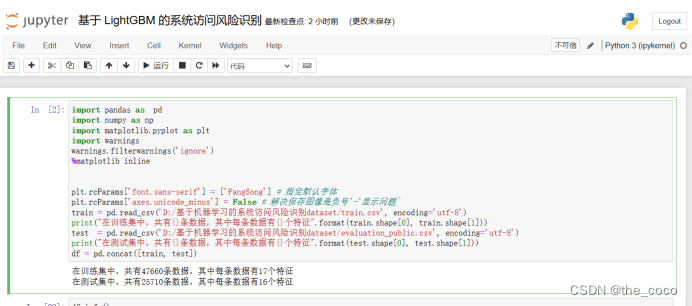
读取数据
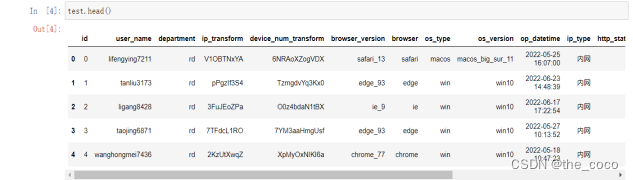
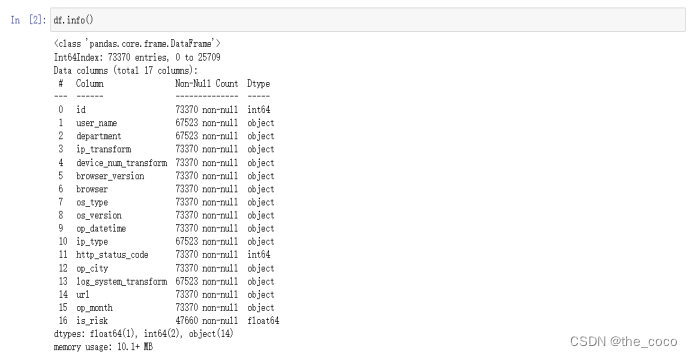
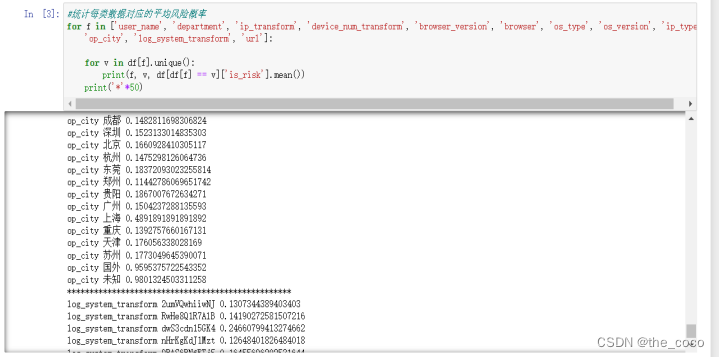
统计每类数据的平均风险概率
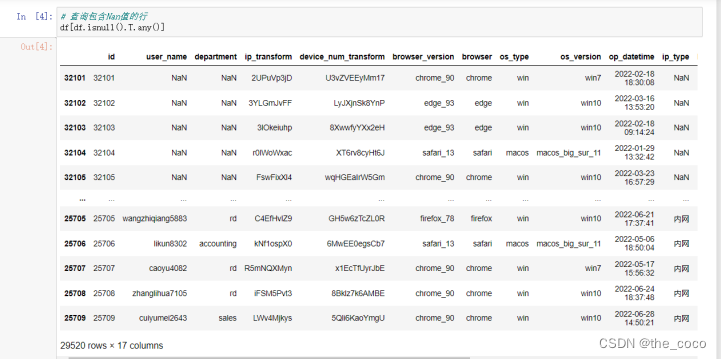
查询包含Nan值的行
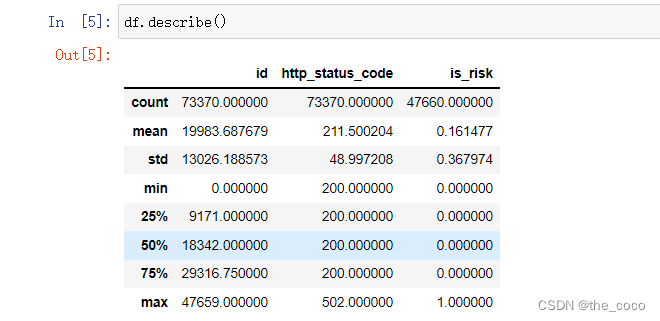
查看数据描述
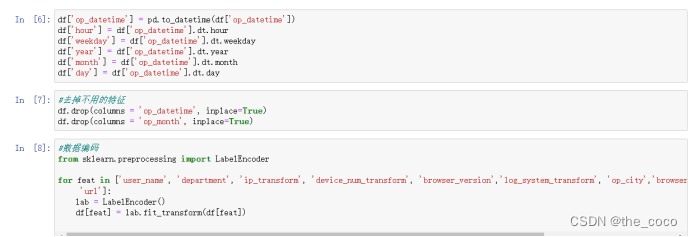
进行一定的数据处理以及数据初始化,调用Sklearn库中的特征预处理API sklearn.preprocessing 进行特征预处理使用labelEncoder函数将离散型的数据转换成 0 到 n − 1 之间的数,这里 n 是一个列表的不同取值的个数,可以认为是某个特征的所有不同取值的个数。
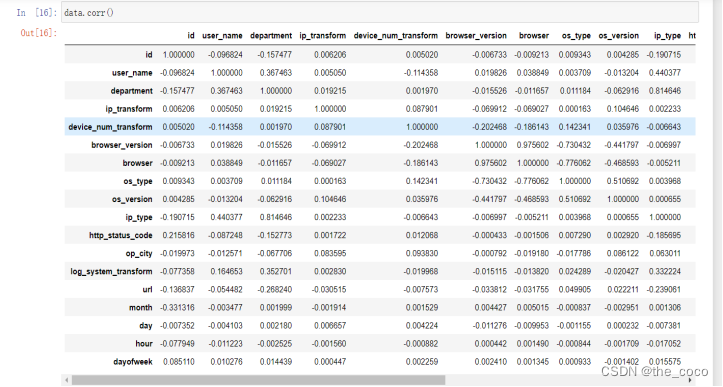
填充空值并使用Corr函数,使用相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。默认空参情况下传入值为Pearson
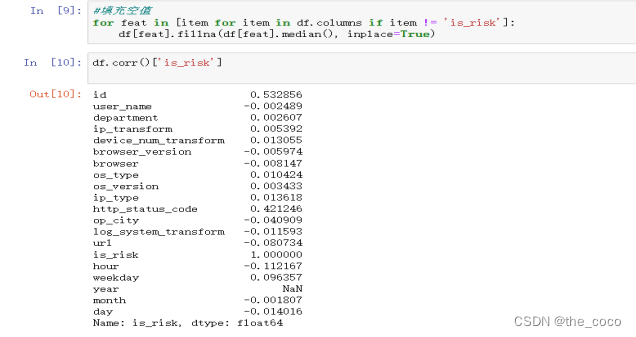
继续处理数据并将后续数据归一化,通过对原始数据进行变换把数据映射到(0,1)之间
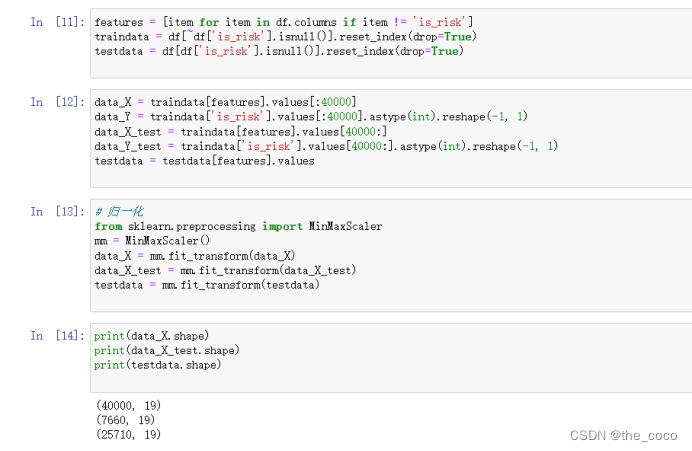
(2)特征抽取
1.时间特征提取
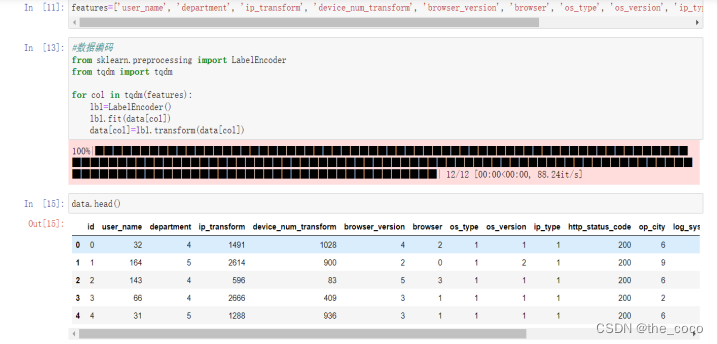
2.离散数据处理
3.数据集分割

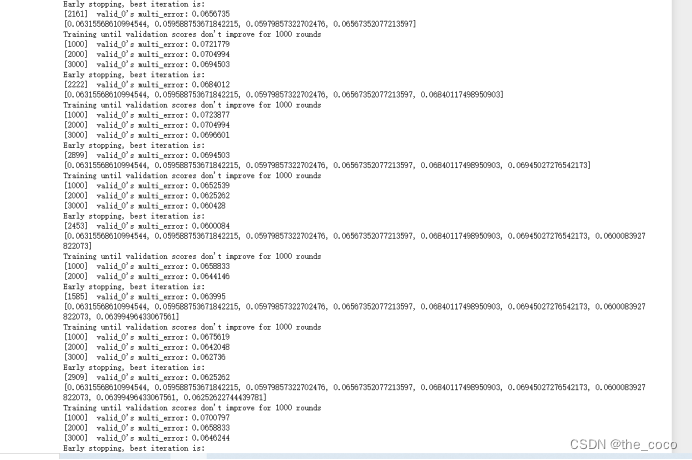
(3)模型训练
(4)预测
保存至相应csv文件

1表示有风险,0表示没有风险
六、个人总结
这次大作业让我对数据挖掘和分析这门课程有了更深一步的了解,学习利用机器学习算法中的LightGBM算法对离散数据进行分析,同时也对Python代码有了更深层次的认识,认识了机器学习算法的优势,通过这次大作业的学习学会了建模分析方法,同时也学会了如何用Python代码实现对数据的删除和清洗,对模型本身的算法、适用范围、参数、优劣性有充分的了解。同时掌握了离散型数据的特征处理和时间处理,表格数据也可以轻易解决了。
七、源码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%matplotlib inlineplt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示问题`
train = pd.read_csv('D:/基于机器学习的系统访问风险识别dataset/train.csv', encoding='utf-8')
print("在训练集中,共有{}条数据,其中每条数据有{}个特征".format(train.shape[0], train.shape[1]))
test = pd.read_csv('D:/基于机器学习的系统访问风险识别dataset/evaluation_public.csv', encoding='utf-8')
print("在测试集中,共有{}条数据,其中每条数据有{}个特征".format(test.shape[0], test.shape[1]))
df = pd.concat([train, test])df.info()#统计每类数据对应的平均风险概率
for f in ['user_name', 'department', 'ip_transform', 'device_num_transform', 'browser_version', 'browser', 'os_type', 'os_version', 'ip_type','op_city', 'log_system_transform', 'url']:for v in df[f].unique():print(f, v, df[df[f] == v]['is_risk'].mean())
print('*'*50)train.head()
# 查询包含Nan值的行
df[df.isnull().T.any()]
df.describe()
df['op_datetime'] = pd.to_datetime(df['op_datetime'])
df['hour'] = df['op_datetime'].dt.hour
df['weekday'] = df['op_datetime'].dt.weekday
df['year'] = df['op_datetime'].dt.year
df['month'] = df['op_datetime'].dt.month
df['day'] = df['op_datetime'].dt.day#去掉不用的特征
df.drop(columns = 'op_datetime', inplace=True)
df.drop(columns = 'op_month', inplace=True)#数据编码
from sklearn.preprocessing import LabelEncoderfor feat in ['user_name', 'department', 'ip_transform', 'device_num_transform', 'browser_version','log_system_transform', 'op_city','browser', 'os_type', 'os_version', 'ip_type','url']:lab = LabelEncoder()df[feat] = lab.fit_transform(df[feat])#填充空值
for feat in [item for item in df.columns if item != 'is_risk']:
df[feat].fillna(df[feat].median(), inplace=True)df.corr()['is_risk']features = [item for item in df.columns if item != 'is_risk']
traindata = df[~df['is_risk'].isnull()].reset_index(drop=True)
testdata = df[df['is_risk'].isnull()].reset_index(drop=Truedata_X = traindata[features].values[:40000]
data_Y = traindata['is_risk'].values[:40000].astype(int).reshape(-1, 1)
data_X_test = traindata[features].values[40000:]
data_Y_test = traindata['is_risk'].values[40000:].astype(int).reshape(-1, 1)
testdata = testdata[features].values# 归一化
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
data_X = mm.fit_transform(data_X)
data_X_test = mm.fit_transform(data_X_test)
testdata = mm.fit_transform(testdata)
print(data_X.shape)
print(data_X_test.shape)
print(testdata.shape)test.head()
print(train.shape)
print(test.shape)data=pd.concat([train, test])
data=data.fillna('NAN')# 时间特征
def add_datetime_feats(df):df['time'] = pd.to_datetime(df['op_datetime'])# df['year'] = df['time'].dt.yeardf['month'] = df['time'].dt.monthdf['day'] = df['time'].dt.daydf['hour'] = df['time'].dt.hourdf['dayofweek'] = df['time'].dt.dayofweek
return dfdata=add_datetime_feats(data)#去掉不用的特征
data.drop(columns = 'op_datetime', inplace=True)
data.drop(columns = 'op_month', inplace=True)
data.drop(columns = 'time', inplace=True)print(data.columns.tolist())features=['user_name', 'department', 'ip_transform', 'device_num_transform', 'browser_version', 'browser', 'os_type', 'os_version', 'ip_type', 'op_city', 'log_system_transform', 'url']#数据编码
from sklearn.preprocessing import LabelEncoder
from tqdm import tqdmfor col in tqdm(features):lbl=LabelEncoder()lbl.fit(data[col])
data[col]=lbl.transform(data[col])data.head()
data.corr()
train, test = data[:len(train)], data[len(train):]from sklearn.model_selection import StratifiedKFold
from lightgbm import early_stopping
from lightgbm import log_evaluation # 要升级后,重启notebook
import numpy as np
import lightgbm as lgb# label转为int类型
train['is_risk']=train['is_risk'].apply(lambda i:int(i)) features.extend(['http_status_code','month','day','hour','dayofweek'])
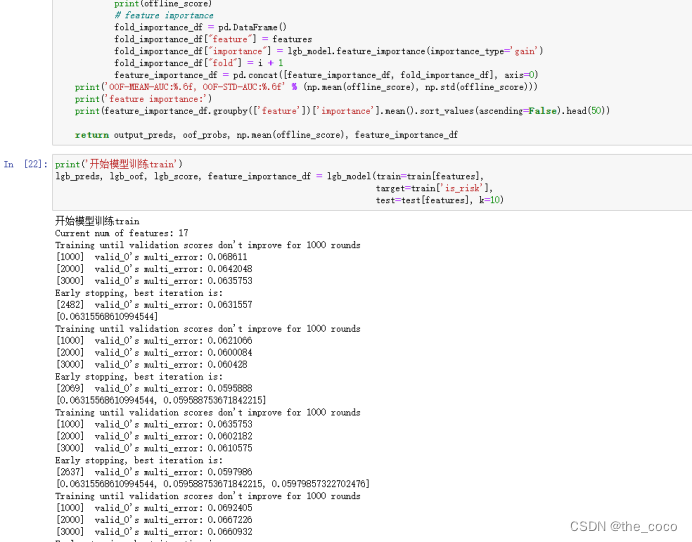
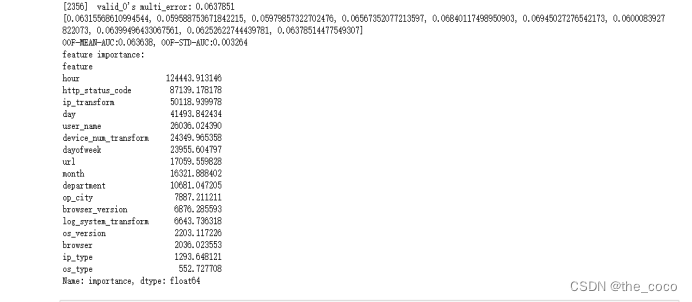
print(features)def lgb_model(train, target, test, k):print('Current num of features:', len(features))oof_probs = np.zeros((train.shape[0],2))output_preds = 0offline_score = []feature_importance_df = pd.DataFrame()parameters = {'learning_rate': 0.03,'boosting_type': 'gbdt','objective': 'multiclass','metric': 'multi_error','num_class': 2,'num_leaves': 31,'feature_fraction': 0.6,'bagging_fraction': 0.8,'min_data_in_leaf': 15,'verbose': -1,'nthread': 4,'max_depth': 7}seeds = [2020]for seed in seeds:folds = StratifiedKFold(n_splits=k, shuffle=True, random_state=seed)for i, (train_index, test_index) in enumerate(folds.split(train, target)):train_y, test_y = target.iloc[train_index], target.iloc[test_index]train_X, test_X = train[features].iloc[train_index, :], train[features].iloc[test_index, :]dtrain = lgb.Dataset(train_X,label=train_y)dval = lgb.Dataset(test_X,label=test_y)lgb_model = lgb.train(parameters,dtrain,num_boost_round=20000,valid_sets=[dval],callbacks=[early_stopping(1000), log_evaluation(1000)],)oof_probs[test_index] = lgb_model.predict(test_X[features], num_iteration=lgb_model.best_iteration) / len(seeds)offline_score.append(lgb_model.best_score['valid_0']['multi_error'])output_preds += lgb_model.predict(test[features],num_iteration=lgb_model.best_iteration) / folds.n_splits / len(seeds)print(offline_score)# feature importancefold_importance_df = pd.DataFrame()fold_importance_df["feature"] = featuresfold_importance_df["importance"] = lgb_model.feature_importance(importance_type='gain')fold_importance_df["fold"] = i + 1feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)print('OOF-MEAN-AUC:%.6f, OOF-STD-AUC:%.6f' % (np.mean(offline_score), np.std(offline_score)))print('feature importance:')print(feature_importance_df.groupby(['feature'])['importance'].mean().sort_values(ascending=False).head(50))return output_preds, oof_probs, np.mean(offline_score), feature_importance_dfprint('开始模型训练train')
lgb_preds, lgb_oof, lgb_score, feature_importance_df = lgb_model(train=train[features],target=train['is_risk'],test=test[features], k=10)from sklearn.metrics import accuracy_score
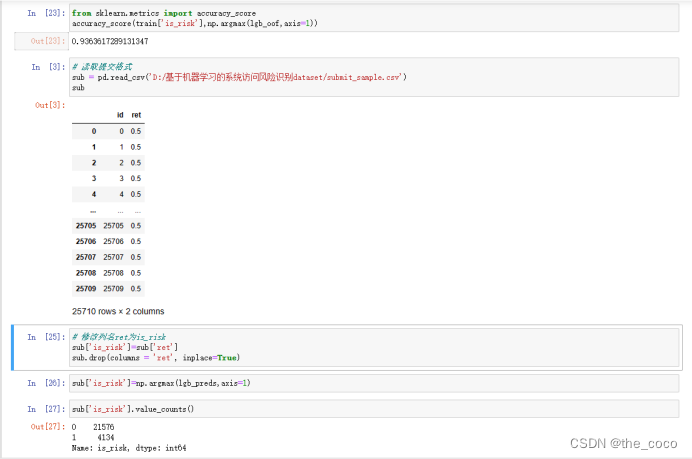
accuracy_score(train['is_risk'],np.argmax(lgb_oof,axis=1))# 读取提交格式
sub = pd.read_csv('D:/基于机器学习的系统访问风险识别dataset/submit_sample.csv')
Sub# 修改列名ret为is_risk
sub['is_risk']=sub['ret']
sub.drop(columns = 'ret', inplace=True)sub['is_risk']=np.argmax(lgb_preds,axis=1)
sub['is_risk'].value_counts()
# 保存
sub.to_csv('D:\sub.csv',index=None)