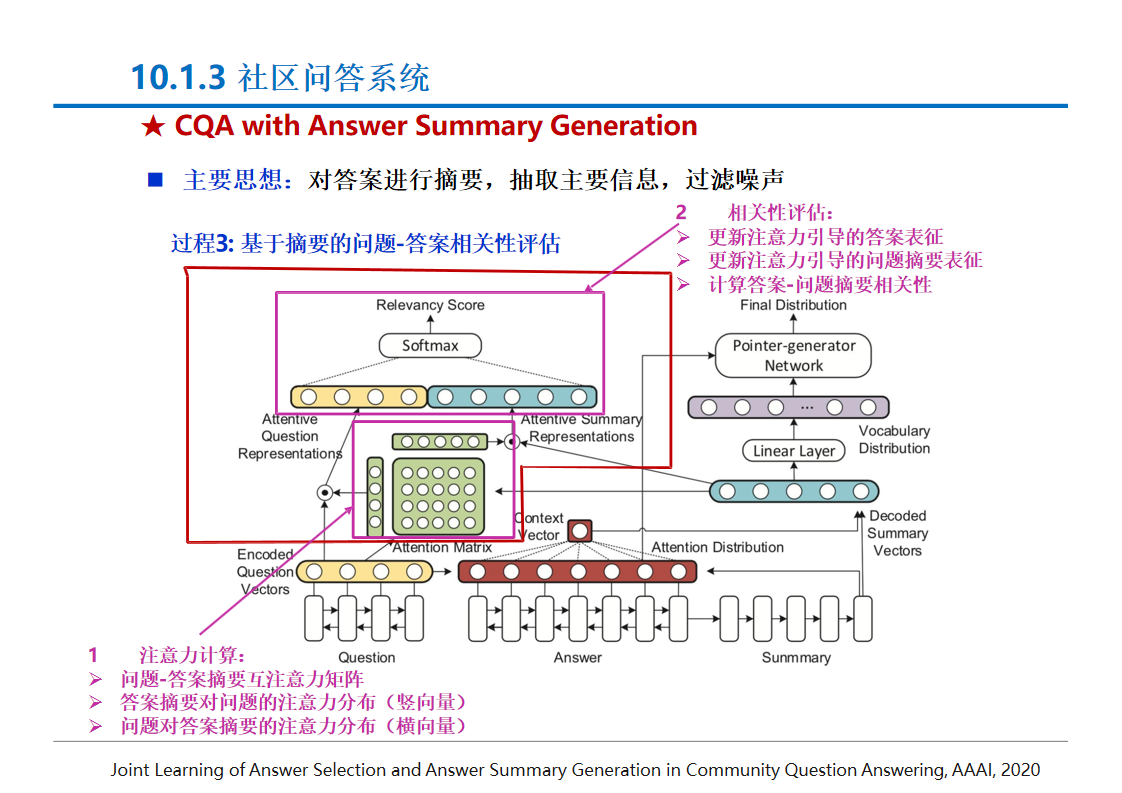
如果你想使用正则表达式来去除HTML标签与标签之间的空格,你需要注意正则表达式并不是解析或处理HTML的最佳工具。HTML是一个复杂的嵌套结构,正则表达式很难完全理解和处理这种结构。在处理HTML时,最好使用专门的HTML解析器。
然而,如果你只是想进行简单的文本处理,并且了解正则表达式的局限性,以下是一个示例正则表达式,用于去除HTML标签之间的多余空格(包括换行符和制表符):
const htmlString = `<div><p> This is a test. </p><span> Another test. </span></div>
`;const cleanedHtmlString = htmlString.replace(/>\s+</g, '><').replace(/\s+/g, ' ').trim();console.log(cleanedHtmlString);
这个正则表达式做了两件事:
>\s+<匹配标签之间的多余空格(包括换行符和制表符),并将其替换为没有空格的><。\s+匹配标签内的多余空格,并将其替换为单个空格。注意,这也会影响到标签内的文本内容。
最后,使用trim()函数去除字符串开头和结尾的空格。
请注意,这个方法并不完美,并且可能不适用于所有情况。特别是当HTML代码包含属性或复杂的嵌套结构时,这个方法可能会产生意外的结果。
更好的方法是使用HTML解析器,如JavaScript中的DOMParser,来解析和处理HTML:
const parser = new DOMParser();
const doc = parser.parseFromString(htmlString, 'text/html');
const cleanedHtmlString = doc.documentElement.outerHTML.replace(/\s+/g, ' ').trim();console.log(cleanedHtmlString);
这个方法更可靠,因为它基于浏览器的HTML解析能力,而不是简单的文本替换。然而,它仍然使用正则表达式来清理空格,因此你可能需要根据具体需求调整正则表达式。

![[2025.1.17 JavaSE学习]文件基础知识](https://img2024.cnblogs.com/blog/3574171/202501/3574171-20250117032150883-1053952146.png)



![[2025.1.16 JavaSE学习]线程的生命周期 线程同步机制](https://img2024.cnblogs.com/blog/3574171/202501/3574171-20250117012945035-22803814.png)