最后找到问题的根因:
NVME硬盘(mdts参数为10)的`max_hw_sectors_kb`设置为4096KB。当进行流式DMA映射时。如果单次请求的数据量过大,超过了128KB,导致无法有效利用IOVA优化机制,进而引发了对iova_rbtree_lock锁的竞争。

为了解决这个问题,建议根据DMA优化限制来限制max_hw_sectors的值,这样可以确保系统能够利用到可扩展的IOVA机制,减少锁竞争并提升系统性能。
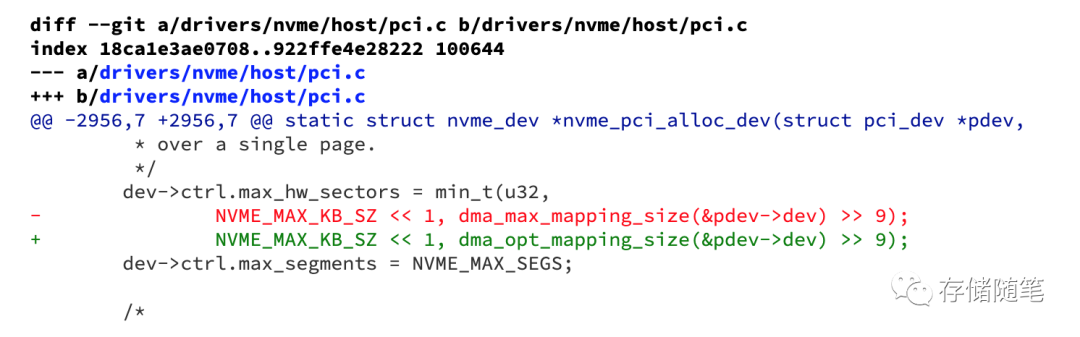
将原来使用的dma_max_mapping_size()函数改为了dma_opt_mapping_size()函数。
-
dma_max_mapping_size()通常返回系统支持的最大连续内存区域可被映射用于DMA操作的大小;
-
dma_opt_mapping_size()则代表一个更优化的、基于特定设备或场景的DMA映射大小,它可能会根据设备的具体特性或者DMA引擎的能力来提供一个更为高效且适合当前设备的DMA映射大小。
在Linux内核中,dma_opt_mapping_size()函数的具体定义取决于不同的架构和平台。这个函数通常用于获取一个特定设备的DMA优化映射大小,即最适合该设备进行高效DMA操作的内存区域大小。
由于每个硬件平台和驱动实现可能不同,dma_opt_mapping_size()的实现和返回值也会有所差异。通常,它会考虑诸如CPU缓存行对齐、设备DMA引擎特性(如最大传输单元MTU)、以及系统对DMA一致性要求等因素来决定最优的内存映射大小。
回归测试中,除了修改max_hw_sectors,另外一块NVME硬盘MDTS参数为5且max_hw_sectors_kb为128,并未出现同样的问题,说明其硬件配置更适合于新的IOVA可扩展机制。
Linux DMA分类介绍:
在Linux内核中,DMA(Direct Memory Access)映射是系统为设备提供直接访问内存的一种机制。为了支持不同的硬件特性和需求,内核提供了两种主要的DMA映射接口:Consistent mapping和Stream mapping。
1. Consistent DMA Mapping
Consistent DMA mapping 主要针对的是需要保持CPU缓存与设备之间数据一致性的场景。在现代多核处理器系统中,为了提高性能,CPU使用缓存来加速对内存的访问。然而,如果设备通过DMA直接访问主内存,而这些内存区域的数据又被缓存了,可能会导致CPU缓存与实际物理内存内容不一致的问题。因此,consistent DMA映射会在进行DMA操作前确保内存区域的内容已经刷新到内存,并且在DMA操作完成后,如果必要的话,会再次同步内存以确保设备写入的数据也反映到了CPU缓存中。
-
特点:
-
-
确保CPU缓存与物理内存一致性。
-
对于cache-coherent架构(如大多数现代ARM、x86等),内核通常可以利用硬件提供的cache一致性机制。
-
在非cache-coherent架构上,可能需要额外的软件干预来保证一致性。
-
2. Stream DMA Mapping
Stream DMA mapping 则更关注于高性能的流式数据传输,它主要用于那些不需要严格保证CPU缓存一致性的场景。例如,在连续大块数据传输过程中,尤其是当设备能够自行管理缓存一致性或者数据无需立即由CPU处理时,可以使用stream mapping。
-
特点:
-
-
不强制保证每次DMA操作前后都进行缓存同步,从而减少不必要的开销,提高DMA数据传输效率。
-
对于非缓存一致性的硬件平台,stream mapping可能更加适用,因为它避免了不必要的内存屏障或flush操作。
-
适用于视频流、音频流等实时性要求高、数据量大的传输任务。
-
总结来说,Consistent DMA mapping强调数据的一致性保障,适合于需要与CPU共享数据且保证数据一致性的场合;而Stream DMA mapping则侧重于优化传输速度和性能,适用于对数据一致性要求相对较低但对带宽和延迟敏感的应用场景。
DMA/IOMMU扩展阅读:
-
《存储IO路径》专题:数据魔法师DMA
-
深度剖析:DMA对PCIe数据传输性能的影响
-
存储系统性能优化中IOMMU的作用是什么?
小编每日撰文不易,如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
年度总结|存储随笔2023年度最受欢迎文章榜单TOP15
-
过度加大SSD内部并发何尝不是一种伤害
-
NVMe over CXL如何加速Host与SSD数据传输?
-
FIO测试参数与linux内核IO栈的关联分析
-
为什么QLC NAND才是ZNS SSD最大的赢家?
-
SSD在AI发展中的关键作用:从高速缓存到数据湖
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
SSD数据在写入NAND之前为何要随机化?
-
深度剖析:DMA对PCIe数据传输性能的影响
-
NAND Vpass对读干扰和IO性能有什么影响?
-
HDD与QLC SSD深度对比:功耗与存储密度的终极较量
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
如何通过优化Read-Retry机制降低SSD读延迟?
-
关于硬盘质量大数据分析的思考
-
存储系统性能优化中IOMMU的作用是什么?
-
全景解析SSD IO QoS性能优化
-
NVMe IO数据传输如何选择PRP or SGL?
-
浅析nvme原子写的应用场景
-
多维度深入剖析QLC SSD硬件延迟的来源
-
浅析PCIe链路LTSSM状态机
-
浅析Relaxed Ordering对PCIe系统稳定性的影响
-
实战篇|浅析MPS对PCIe系统稳定性的影响
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!

![[C#]使用纯opencvsharp部署yolov8-onnx图像分类模型](https://img-blog.csdnimg.cn/direct/59cc41476aee453b8193aad6247e2fc7.jpeg)