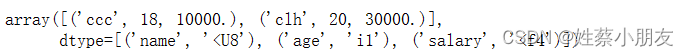目录:
- 一、简介:
- 二、array数组ndarray:
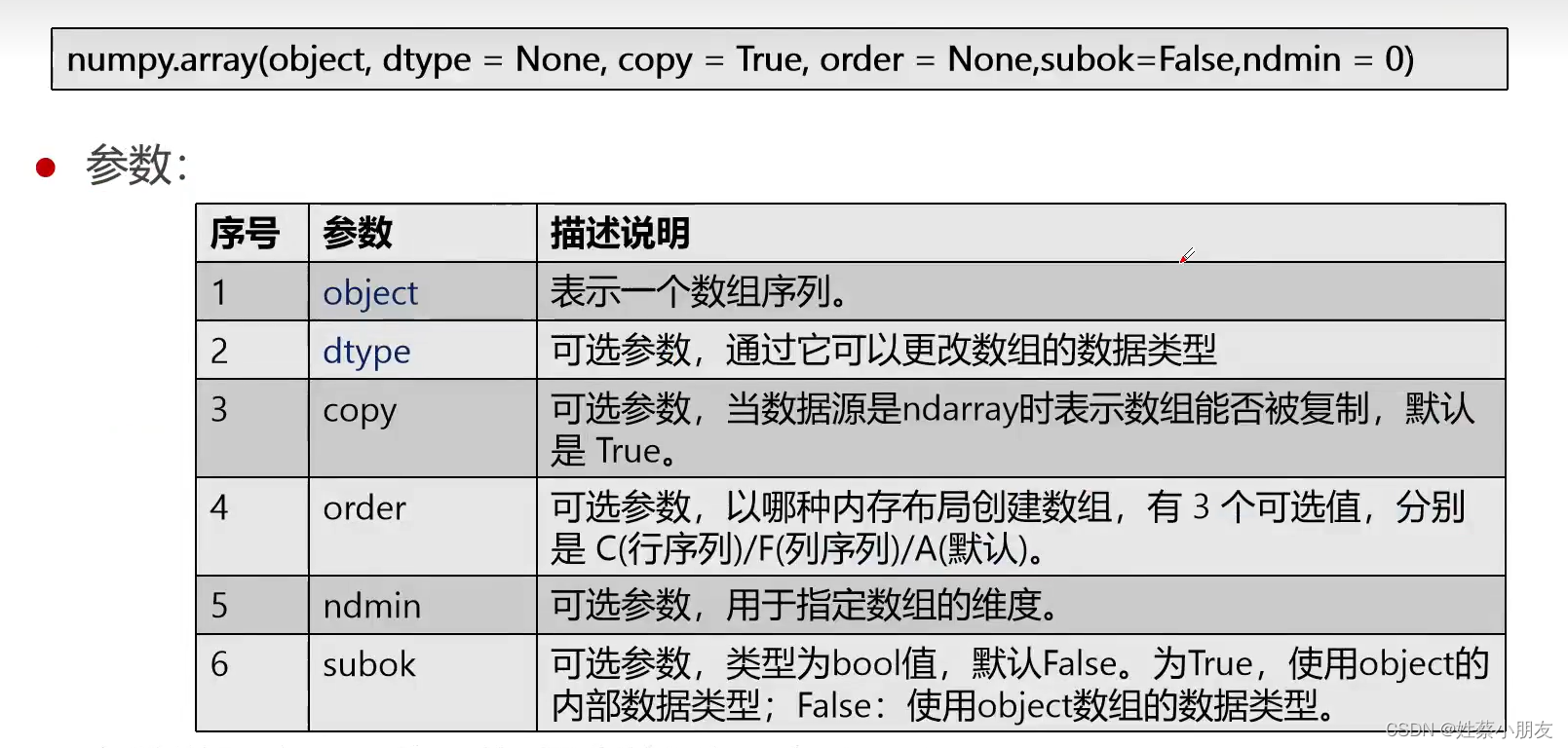
- 1.array( )创建数组:
- 2.数组赋值和引用的区别:
- 3.arange( )创建区间数组:
- 4.linspace( )创建等差数列:
- 5.logspace( )创建等比数列:
- 6.zeros( )创建全0数组:
- 7.ones( )创建全1数组:
- 8.NumPy数组属性:
- (1)shape属性:
- (2)reshape属性:调整数组维度
- 9.一维数组切片、索引操作:
- 10.二维数组切片、索引操作:
- 11.整数数组索引:
- (1)一次性取多个元素,返回一维数组:
- (2)一次性取多个元素,将待返回的一维数组重整成二维数组返回:
- (3)一次性取连续的多行多列元素,返回二维数组:
- (4)取特定行特定列不连续元素,返回二维数组:
- 12.布尔数组索引:
- (1)以数组形式返回数组x>6的元素:
- (2)以数组形式返回数组中奇数的元素:
- (3)根据True|False返回数组中符合要求的元素数组:
- 取行:
- 取列:
- 三、广播机制:
- 四、numpy统计:
- 1.平均值:
- 2.中位数:
- 3.标准差:
- 4.方差:
- 5.最大值:
- 6.最小值:
- 7.加权平均值:
- 五、自定义结构化数据类型:
- *注:数据类型别名:*
- 六、文件操作:
- 1.读取普通文本文件:
- 2.读取csv文件:
- 3.读取不同列表示不同信息文件:
- 4.空数据处理:
- 七、随机数:
- 八、numpy常用函数:
- 1.resize( ):
- 2.unique( ):
- 3.sort( ):
一、简介:
- 是Python 科学计算库,方便对数组、矩阵进行计算,包含大量线性代数、傅里叶变换、随机数等大量函数。
- 直接以数组、矩阵为粒度计算并支撑大量的数学函数,效率高。
- 各种数据科学类库(Scikit-Learn、TensorFlow、Pandas)等的基础库。
二、array数组ndarray:
1.array( )创建数组:
import numpy as np
my_list = [[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]
]
#先将my_list二维数组元素强转为float型,然后是用该数组创建二维ndarray数组
my_ndarray = np.array(my_list,float,ndmin=2)
print(my_ndarray)

2.数组赋值和引用的区别:
#1.引用机制(指针)
my_ndarray_copy = my_ndarray
print('my_ndarray的内存地址:',id(my_ndarray))
print('my_ndarray_copy的内存地址:',id(my_ndarray_copy))#2.拷贝机制
my_ndarray_copy = np.array(my_ndarray)
print('my_ndarray的内存地址:',id(my_ndarray))
print('my_ndarray_copy的内存地址:',id(my_ndarray_copy))

3.arange( )创建区间数组:

a = np.arange(10,20,2,dtype=float)
print(a)

4.linspace( )创建等差数列:
等差数列在线性回归经常用作样本集
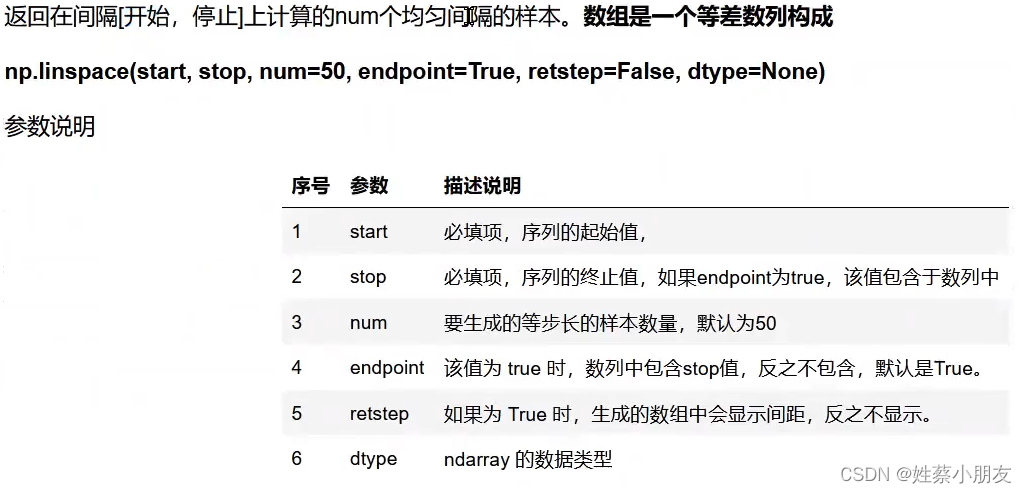
#创建起始值为0,终止值为100,样本数量为11的等差数列数组
b = np.linspace(0,100,11,dtype=int)
print(b)
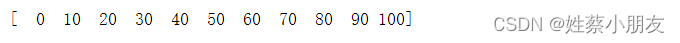
5.logspace( )创建等比数列:

#首先将1-5区间均匀取3个数X(1,3,5),然后创建int型等比数列,元素值为X^base(起始值为1^2,终止值为5^2)
c = np.logspace(1,5,3,base=2,dtype=int)
print(c)

6.zeros( )创建全0数组:

'''
第一个参数:(a)表示a个元素的一维数组(a,b)表示a行b列的二维数组(a,b,c)表示a块,每块b行c列的三维数组
'''
#创建2行2列的全0数组
d = np.zeros((2,2),dtype=int)
print(d)

7.ones( )创建全1数组:
参数同全0
'''
第一个参数:(a)表示a个元素的一维数组(a,b)表示a行b列的二维数组(a,b,c)表示a块,每块b行c列的三维数组
'''
#创建2行2列的全1数组
e = np.ones((2,2),dtype=int)
print(e)

8.NumPy数组属性:
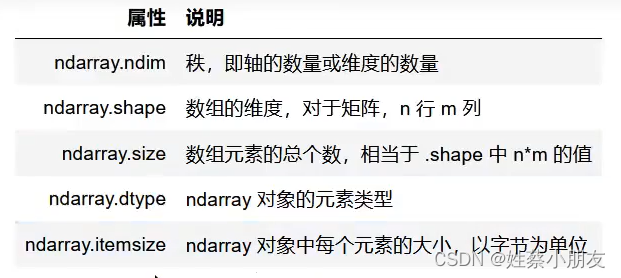
(1)shape属性:
- shape返回值:
- (a)表示a个元素的一维数组
- (a,b)表示a行b列的二维数组
- (a,b,c)表示a块,每块b行c列的三维数组
(2)reshape属性:调整数组维度
返回调整维度后的副本,而不改变原ndarray
f = np.arange(20).reshape(4,5)
print(f)

9.一维数组切片、索引操作:

- 冒号
::解释- [2]将返回与该索引相对应的单个元素
- [2:7]将返回两个索引之间的元素,不包括停止索引
- [2:]表示从该索引开始以后的所有元素都将被提取
- [:7]表示该索引之前的所有元素都将被提取
- [::-1]表示取反,从后往前取所有元素,步长为-1
a1 = np.arange(10)
print(a1)
#切片操作(注意是引用,a1、a2实际上指向同一片内存空间)
a2 = a1[2:7:2]
print(a2)#理解引用机制,并理解索引=数组下标=位序-1,
a2[1]=888
print(a1)
print(a2)

10.二维数组切片、索引操作:
- 冒号
::解释[2]将返回一维数组[2][2]将返回特定元素[2:7]将返回两个索引之间的一维数组集,即返回一个二维数组,不包括停止索引[2:]表示从该索引开始以后的所有一维数组集,即返回一个二维数组都将被提取[:7]表示该索引之前的所有一维数组集,即返回一个二维数组都将被提取[...][1]表示[…]先取所有行即取所有元素,[1]再取所有行的第二行一维数组[2,2]将返回特定元素[...,1]或[:,1]返回第二列元素,组成一个一维数组返回x[...,1:]返回第二列之后的所有列,组成一个二维数组返回
11.整数数组索引:
(1)一次性取多个元素,返回一维数组:
x = np.array([[1,2],[3,4],[5,6]
])
#[0,0,2]是行索引,[0,1,1]是列索引,表示取[0,0]、[0,1]、[2,1]的元素,组成一维数组返回
y = x[[0,0,2],[0,1,1]]
y

(2)一次性取多个元素,将待返回的一维数组重整成二维数组返回:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
#行索引
r = np.array([0,0,0,2])
#列索引
c = np.array([0,1,2,2])
#x[r,c]根据索引获取一维数组,reshape(2,2)将返回的4*1一维数组转为2*2的二维数组
s = x[r,c].reshape(2,2)
s

(3)一次性取连续的多行多列元素,返回二维数组:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
#行取2行3行,列取2列3列
y = x[1:3,1:3]
y

(4)取特定行特定列不连续元素,返回二维数组:
#取1,3行、1,3,4列所有元素
x = np.array([[1,2,3,4],[4,5,6,7],[7,8,9,10]
])
#先取1,3行,:可以换成...
temp = x[[0,2],:]
#再根据上一步结果取1,3,4列,:可以换成...
temp[:,[0,2,3]]

12.布尔数组索引:
- 当返回的结果需要经过布尔运算时,会使用到另一种高级索引方式,即布尔数组索引。
(1)以数组形式返回数组x>6的元素:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
#
x[x>6]

(2)以数组形式返回数组中奇数的元素:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
#将数组中所有奇数置为-1(x[x%2!=0]获取奇数,=-1赋值)
x[x%2!=0] = -1
x

(3)根据True|False返回数组中符合要求的元素数组:
取行:
x = np.array([[1,2,3,4],[4,5,6,7],[7,8,9,10]
])
row = np.array([False,False,True])
print(x[row,...])

取列:
column = np.array([True,False,True,False])
x = np.array([[1,2,3,4],[4,5,6,7],[7,8,9,10]
])
print(x[...,column])

三、广播机制:
- 广播是numpy对不同形状的数组进行数值计算的方式,对数组的算术运算通常在相应的元素上进行。
- (1)若两个数组形状相同,那么两个数组相乘即为数组对应位置元素
相乘。 - (2)若两个数组形状不同,那么两个数组相乘就需要使用广播机制。
- (1)若两个数组形状相同,那么两个数组相乘即为数组对应位置元素
- 广播机制的核心是对形状较小的数组,在横向或纵向的进行一定次数的重复,使其与形状较大的数组具有相同的维度后
相加。
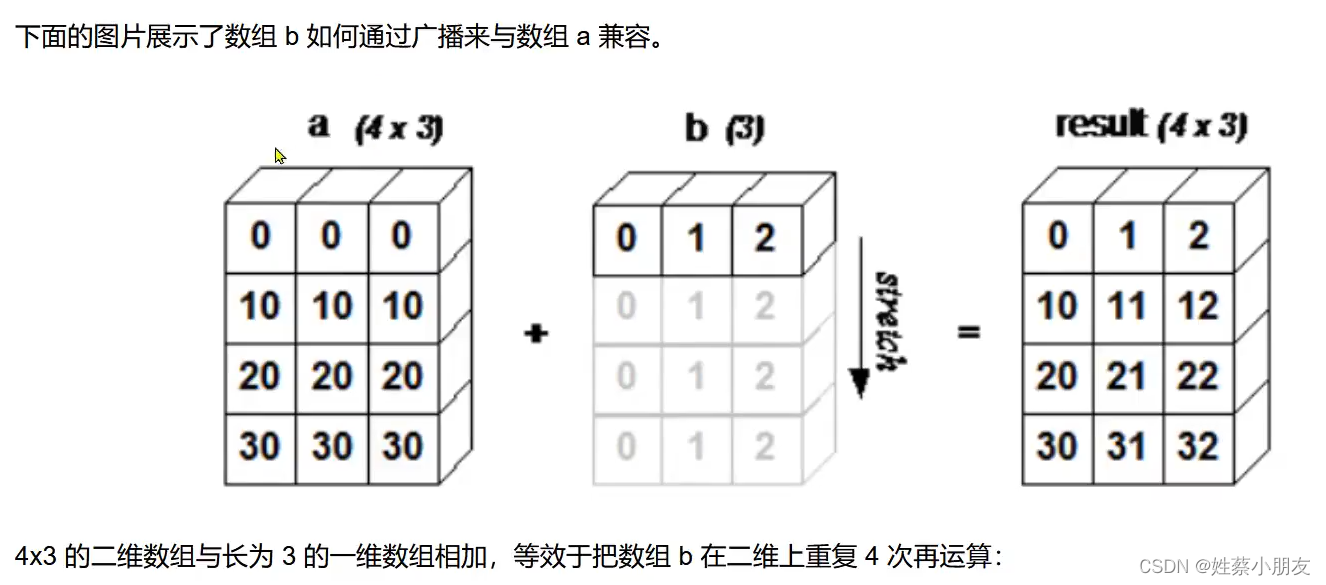
- 广播的规则:
- 输出数组的形状是是输入数组形状的各个维度上的最大值。
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或输入数组的某个维度的长度为1时,这个输入数组能够用来计算,否则不能运算。
- 当输入数组的某个维度的长度为1时,沿着此维度运算时都用此维度上的第一组数组值。
四、numpy统计:
1.平均值:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
#计算所有元素平均值
print(x.mean())
#从上至下计算每列平均值,返回一维数组
print(x.mean(axis=0))
#从左至右计算每行平均值,返回一维数组
print(x.mean(axis=1))

2.中位数:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
np.median(x)

3.标准差:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
np.std(x)

4.方差:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
np.var(x)

5.最大值:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
np.max(x)

6.最小值:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
np.min(x)

7.加权平均值:
x = np.array([[1,2,3],[4,5,6],[7,8,9]
])
np.average(x)

五、自定义结构化数据类型:
#创建结构体
teacher = np.dtype([#(变量名称,变量数据类型->"数据类型别名+所占字节数")("name","U8"),("age","i1"),("salary","f4")
])
#创建数组,数组元素为teacher类型
b = np.array([("clh",20,30000),("ccc",18,10000)],dtype = teacher
)
print("数组b内容为:",b)
print("数组中所有name:",b["name"])

注:数据类型别名:

六、文件操作:

注意:skiprows不忽略注释行和空白行,从文档第一行跳过
1.读取普通文本文件:
- 文本文件一般用空格分隔数据

data = np.loadtxt("data.txt",dtype=np.int32)
2.读取csv文件:
- csv文件是以逗号分隔的文本文件

data = np.loadtxt("data.csv",dtype=np.int32,delimiter=",")
3.读取不同列表示不同信息文件:

#1.定义结构体
user_info = np.dtype([("name","U10"),("age","i1"),("gender","U1"),("height","i2")]
)
#2.用结构体类型接数据,并且使用skiprows跳过第一行不读
data = np.loadtxt("data.txt",dtype=user_info,skiprows=1,encoding="utf-8")
4.空数据处理:
#使用异常机制
def parse_age(age):try:return int(age)except:return 0
#converters调用自定义函数进行空数据处理
data = np.loadtxt("data.csv",delimiter=",",usecols=1,converters={1:parse_age}) 七、随机数:
'''
(a)表示a个元素的一维数组
(a,b)表示a行b列的二维数组
(a,b,c)表示a块,每块b行c列的三维数组
'''#创建[0,1)内给定维度的随机数组,该组元素符合正态分布
np.random.rand(3,3)#返回5*5个[1,5)内的随机整数
np.random.randint(1,5,size=(5,5))八、numpy常用函数:

1.resize( ):
#元素不够时使用原数组数据补齐
a = np.array([1,2,3,4,5,6,7,8,9])
np.resize(a,(4,4))

#元素不够时使用0补齐
a = np.array([1,2,3,4,5,6,7,8,9])
a.resize((4,4),refcheck=False)
a

2.unique( ):
#去重+排序,返回去重后的数组+元素所在原数组的索引+各元素重复次数
a = np.array([2,3,4,5,6,1,2,3])
b,indices,nums = np.unique(a,return_index=True,return_counts=True)
print(b)
print(indices)
print(nums)

3.sort( ):
#结构体
teacher = np.dtype([#(变量名称,变量数据类型)("name","U8"),("age","i1"),("salary","f4")
])
#创建数组,数组元素为teacher类型
b = np.array([("clh",20,30000),("ccc",18,10000)],dtype = teacher
)
#按年龄排序
np.sort(b,order="age")