对基于多源表的结构数据进行商业智能分析,可以帮助决策者从多个不同业务角度对业务行为结果进行观测,进而帮助决策者全面、精确地定位业务问题,实现商业洞察的相关内容。通过商业智能分析产出的分析成果被统称为商业智能报表,简称"BI报表"。根据BI报表的展示形式、使用场景等的不同,BI报表又被称为"XXX驾驶舱"、“XXX仪表盘”、“XXX仪表板”、"XXX大屏"等。日常生活中看到的由交互式数据图表界面构成的报表都是BI报表。
创建一个BI报表需要先后使用ETL、DW、OLAP及数据可视化四个不同阶段的软件技术。其中OLAP技术是进行BI分析最为关键的步骤,在该步骤主要完成两项任务:第一项任务是创建多维数据模型及汇总计算规则;第二项任务是创建针对度量的汇总计算规则。
5.1 多维数据模型
一、
多维数据模型中的维度在分析过程中代表业务角度。多维指的就是多个不同的业务角度。多维数据是用来映射多个不同业务角度的数据信息。多维数据模型是将通过ETL技术提取到DW中的多源数据连接在一起构成的多表连接模型,其主要作用是在DW中的不同数据源间"搭桥",让所有通过"桥梁"连接在一起的数据能够共享彼此的数据信息,从而解决"信息孤岛"问题,为完成多维数据透视分析任务提供完整的数据集合。
多维数据模型又被称为多维数据集或立方体,分析人员通过搭建多维数据模型的方法将多源数据连接为一个完整的数据集合以达到在不同数据间共享彼此数据信息的目的。
搭建多维数据模型的过程称为建模。在数据分析领域中有两类不同的建模工作:一类建模工作是搭建多维数据模型;而另一类建模工作是搭建分析所需要的数学模型。这两类建模工作的建模过程、方法及内容是完全不一样的。
多维数据模型为进行多维数据透视分析提供完整数据信息,有了多维数据模型才能从多角度用数据全面映射业务问题的实际情况。因为企业在经营过程中涉及的任何业务问题都不是孤立出现在某一业务角度下的,所以从不同业务角度对业务问题进行综合分析才有可能找到业务问题产生的全面原因并加以解决。
二、多维数据模型创建方法
创建多维数据模型的过程就是在多个不同数据表间进行连接的过程,而使用多维数据模型的过程,就是在多表连接环境上进行多维数据透视分析(在多个交叉维度下对度量进行汇总计算)的过程。
相邻两表间连接汇总方法:需要使用公共字段在相邻两表间创建连接关系,其连接逻辑与表结构数据间进行横向合并的逻辑非常相似。
影响连接汇总计算结果的要素主要有3个,分别是筛选器的方向、对应关系及汇总角色。其中筛选器的方向和对应关系影响表间的连接逻辑,而连接逻辑又直接影响汇总角色在汇总计算时发生的作用。
筛选器:筛选器的方向决定了维度字段与度量字段的出处。透视分析的本质是维度字段对度量字段进行汇总计算。将用维度字段汇总度量字段的过程称为筛选。用"XX维度字段筛选XX度量字段"或者"XX度量字段被XX维度字段所筛选"的方式进行表述。筛选器的方向可以决定两表连接后哪个表的字段能够作为维度字段对另一个表的度量字段进行筛选。
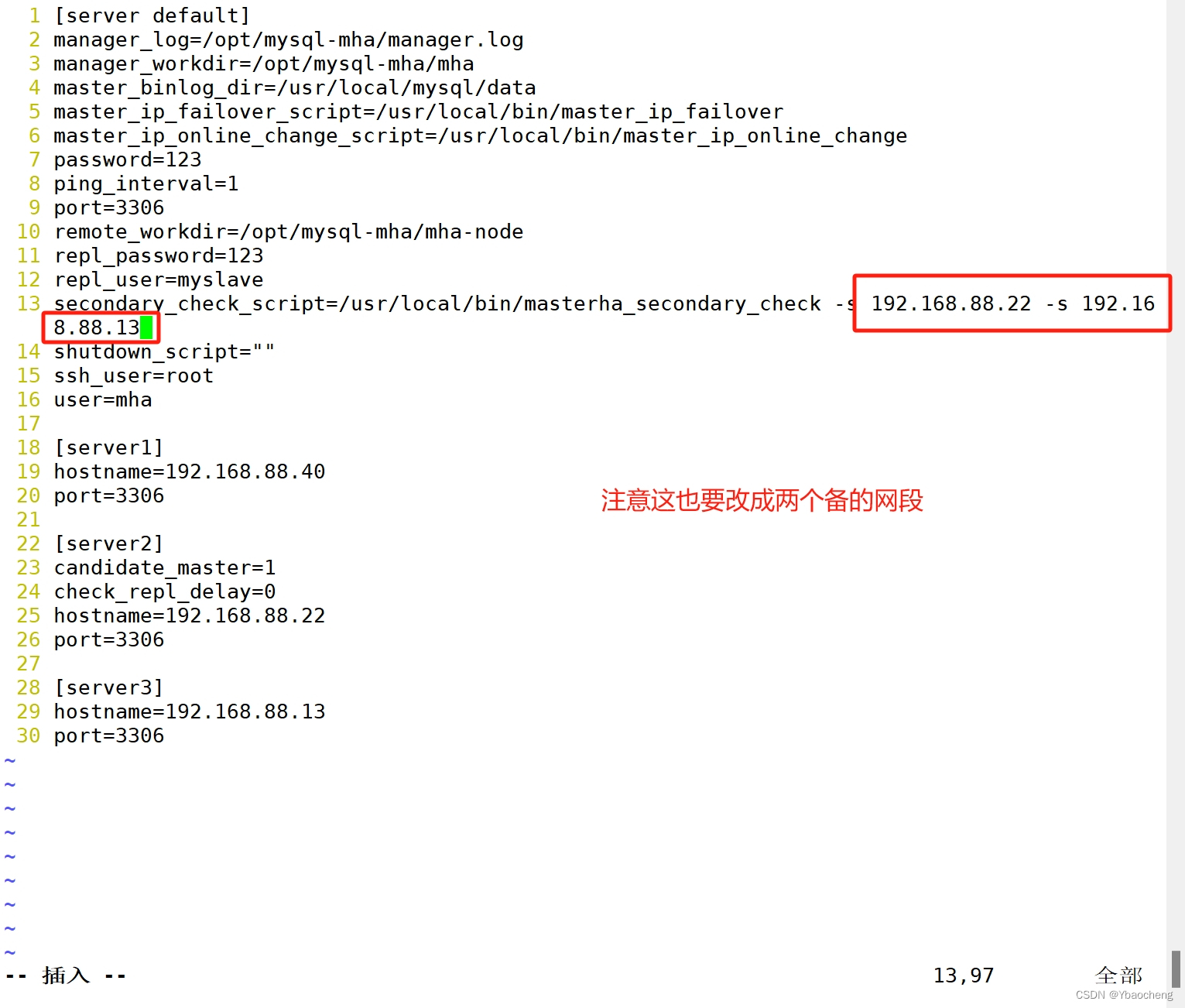
筛选器分为两类:分别是单向筛选器及双向筛选器。连接线中间只有一个箭头的被称为单向筛选器,而连接线中间有两个箭头的被称为双向筛选器。在单向筛选器中箭头指向被筛选的数据表,该表中的字段应作为度量字段被箭头出发一侧的数据表中的字段筛选。箭头出发一侧的数据表是筛选数据表,用来提供维度字段,而箭头指向一侧的数据表是被筛选数据表,用来提供度量字段。(虽然双向筛选器能够实现两表间的互相筛选,但是其中存在的一些逻辑上的问题也会影响透视结果的业务意义)(若是多表出维度字段对一表下的度量字段进行筛选,则会出现汇总计算错误)
连接语句中,左连接时左表是主表,右连接时右表是主表,主表提供查询结果的查询范围。该逻辑在没有连接方向概念的数据模型连接逻辑下并不适用。在数据模型连接逻辑下,哪个表提供度量字段哪个表就是主表,而另一侧的表则为附表。(被箭头指向的表为主表,另一侧为附表)(找不到的情况下,用空值替代)
在一对多的对应关系下,使用单向筛选表进行汇总计算时,应遵循"一表出维度字段是附表,多表出度量字段是主表,一表筛选多表"的规则进行连接汇总计算。
一对一的对应关系可以理解为"主键对主键"的对应关系,所以要形成一对一的对应关系,需要两个表具有相同内容的主键,而这种情况再实际业务场景中几乎是不会出现的。因为主键是表的记录单位,所以表中的所有非主键字段都是为修饰及扩充主键信息而存在的。两个表具有相同内容的主键也就意味着两个表具有相同的记录单位,那么这两个表的其它非主键字段是完全可以统一在一个表中的,没有必要分别放在两个不同表中进行记录。故在数据库的设计环节中基本不会让两个连接表具有相同内容的主键,在实际业务工作中很难遇到主键对主键的连接情况。(虽然主键对主键的连接情况很难遇到,但是在实际工作中会遇到一些主键对非主键形成的物理意义上的一对一的对应情况,即两表中都没有重复值。然而这种一对一双向筛选在实际工作中只是暂时没问题,并不能一直应用下去。因为当前一对一的对应关系并不是由主键对主键形成的,所以非主键字段中的记录内容只是暂时没有重复值,未来大概率会出现重复的记录内容。所以在实际业务中,不能仅凭公共字段中没有重复值就判断为一对一的对应关系,而是要进一步判断只有当两表公共字段都是主键时才能使用一对一的对应关系,如果是主键对非主键的情况,应按照一对多的对应关系进行连接才正确。)。在Power BI工具中,一对一的对应关系默认使用双向选择器。双向选择器可以在两表中进行筛选。
多对多是指非主键连接非主键的情况。在实际业务中虽然会出现,但应尽量避免使用(因为使用多对多的对应关系会造成度量值在汇总时被重复计算的可能)
一表筛选多表:(双向选择器可以实现多表筛选一表,但其计算逻辑往往不符合业务需求,应尽量避免)
三、
表结构连接汇总计算规则称为类型一规则,该规则的计算逻辑是在维度字段汇总度量字段时,先将维度字段下相同的维度项按照合并同类项的方式合并在一起,再按照计算规则的要求将每个不同维度下对应的所有度量值进行汇总计算,最后得到计算结果。
将在多对一的对应关系下使用双向选择器用多表筛选一表的计算逻辑称为类型二规则。该规则的计算逻辑是先对维度字段下的不同维度项进行合并同类项处理,再找出每个维度项下包含的不同的公共字段信息,然后将每个不同公共字段信息作为汇总度量字段的度量值。在类型二规则下,指定的维度字段并不直接对度量字段进行筛选,而是先找出每个不同维度项下包含的不同的公共字段信息,再用这些公共字段信息对度量值字段进行筛选。其总计结果是按照维度计算出来的结果。
对两表间的连接汇总计算逻辑进行总结,应尽量使用一对多的对应关系连接,而一对多的对应关系下进行汇总计算时应尽量遵循"一表出维度,多表出度量,一表筛选多表"的筛选方式进行计算。在一对多的对应关系下会出现下面4种不同情况:
●:双向筛选器、多表筛选一表、按照类型二规则进行汇总计算
X:双向筛选器、一表筛选多表、按照类型一规则进行汇总计算
△:单向筛选器、多表筛选一表、无法正确进行汇总计算
■:单向筛选器、一表筛选多表、按照类型一规则进行汇总计算
双向 单向 维度 值 维度 值 多表 ● X △ ■ 一表 X ● ■ △ ●类型二规则
X类型规则
△无法正确进行汇总计算
■类型一规则
四、跨表筛选(除了两表直接进行连接筛选,还可以在多表环境下进行跨表筛选)
进行跨表筛选的前提条件是筛选路径要通畅,也就是每一段路径中的筛选器中都要有指向被筛选表一侧的箭头才行。若跨表筛选的路径中存在不能被正确筛选的阶段,则跨表筛选后只能得到错误的透视结果。
在筛选路径通畅的前提下,进行跨表筛选,无论完整路径中各表的对应关系如何,都将按照类型二规则进行汇总计算。
五
在多表环境中,在不相邻的两个表间往往可以形成多条不同的筛选路径,两表间包含多条筛选路径的情况称为交叉连接。虽然交叉连接存在多条筛选路径,但真正对汇总结果产生影响的路径只有一条,这边称影响筛选结果的路径为有效路径,而其余路径均不参与筛选计算。(在Power BI中,完全由实线构成的路径称为有效路径,而其他两条包含虚线的路径称为无效路径)
出维度的表称为维度表,出度量的表称为事实表,因为维度字段筛选度量字段,所以维度表筛选事实表。在多对一的对应关系下,我们使用一表对多表进行筛选,所以一表是维度表出维度字段,多表是事实表出度量字段。在多表环境下,维度表与事实表可以构成3种不同的连接模型,分别为星型模型、雪花模型及星座模型。
- 星型模型:一个事实表和多个维度表相连接构成的连接模型
- 雪花模型:维度表和其他维度表连接再与事实表连接后构成的连接模型
- 星座模型:多个事实表与某些维度表连接后构成的连接模型
星座模型用来为事实表丰富维度信息,雪花模型用来在某些特定维度信息上进行更丰富的维度信息拓展,星座模型用共用的维度表将多个不同的事实表连接为一个整体(因为事实表是多表,所以事实表与事实表之间如果直接连接会产生多对多的对应关系。因多对多的连接关系应尽量少用,故事实表与事实表之间一般需要共用的维度表进行中转连接)

5.2 5W2H思维模型
为了解决数据收集问题,采用的经典的思维模型——5W2H思维模型(What、Why、Where、When、Who、How much、How to do)(What代表分析的对象是什么,Why代表为什么分析、Where代表分析的空间维度是什么、When代表时间维度是什么、Who代表分析的参与角色有哪些、How much代表分析的度量是什么、How to do代表该如何做。How to do是通过数据分析最终得出的见解和决策方案,是分析的最终目的。在商业数据的汇总分析中,5个W开头的单词是汇总的维度,而How much是需要观测的度量值。
销售漏洞模型:是科学反映商机状态及销售效率的一种重要的销售管理模型。此模型应用广泛,适用于多种类型的销售体系,尤其适用于关系型销售企业。关系型销售企业就是以销售人员维护客户关系来完成交易的销售形式为基础的企业。销售漏斗模型适用于这些企业中的销售运营管理业务。销售漏斗是将从发现潜在商机开始到最后与客户成交为止的整个销售过程,按照不同的销售进度分为几个不同的销售阶段来进行管理的模型体系。在销售漏斗中每个阶段代表一个已经达成的销售里程碑,在销售漏斗中,销售阶段的数量及设定方法,依据企业的经营方式不同而不同。(从上至下依次为潜在、解除、意向、明确、投入、谈判、成交。商机数量由上至下越来越少,但商机的成功率却由上至下越来越高)要实现的业务目的是让每一个销售阶段的商机数量都尽可能多地顺利过渡到下一个销售阶段。为了实现这个目的,需要及时发现每个商机中的风险,并及时用有效的销售行为规避风险。故销售漏斗分析的本质是企业经营方面的风险分析,直接关系企业的盈亏状况,是企业赖以生存的生命线。
在分析销售类业务问题时常用到的数据主要包括客户维度、产品维度、销售人员维度、销售渠道维度,在销售分析中核心维度是商业维度,以及所有业务通用的时间维度。
首先初步梳理5W2H各自的框架结构:①What(分析的对象,即销售进度管理);②Why(分析的目的,即为了发现并控制销售阶段风险);③Where(分析的空间维度,即销售地点等);④Who(分析的参与角色,即买房和卖方[客户、销售人员和渠道商]);⑤When(分析的时间维度,即围绕商机开展的时间信息);⑥How much(分析的度量,即商机金额、商机数量、商机规模等);⑦How to do(方法,即如何制定有效的销售策略才能减少商业成交风险);
接下来继续从框架概念落实数据信息:①What(销售进度管理,即商机维度,包括商机规模、商机号、商机来源等);②Why(控制销售阶段风险,即商业维度,包括销售阶段、上周销售阶段、赢单率等);③Where(销售地点,即销售大区、销售城市、销售的区域等);④Who(客户、销售人员及渠道商【客户:客户负责人、与客户以往交易情况、客户需求等】、【销售人员:商业发现者、商业管理者、销售人员能力水平、销售人员成本等】、【渠道商:渠道商可提供的相关数据】);⑤When(围绕商业进展的时间信息,即商机创建、预计成交、阶段变化等的时间节点);⑥How much(分析的度量,即商机金额、商机数量、商机规模等);⑦How to do(方法,即如何制定有效的销售策略才能减少商机成交风险)
通过5W2H思维模型梳理出数据线索后,就可以进一步使用ETL功能在多个数据源中将需要的数据信息提取、清洗转换、上传到DW中,再进一步就可以使用OLAP技术创建多维数据模型,计算维度项下的度量值,最后用可视化技术将分析结果展示在BI报表内。
5.3 多维数据透视分析应用案例
无