经常性的报死锁异常,经常性的主从延迟......通过报错信息按图索骥,发现代码是这样的。
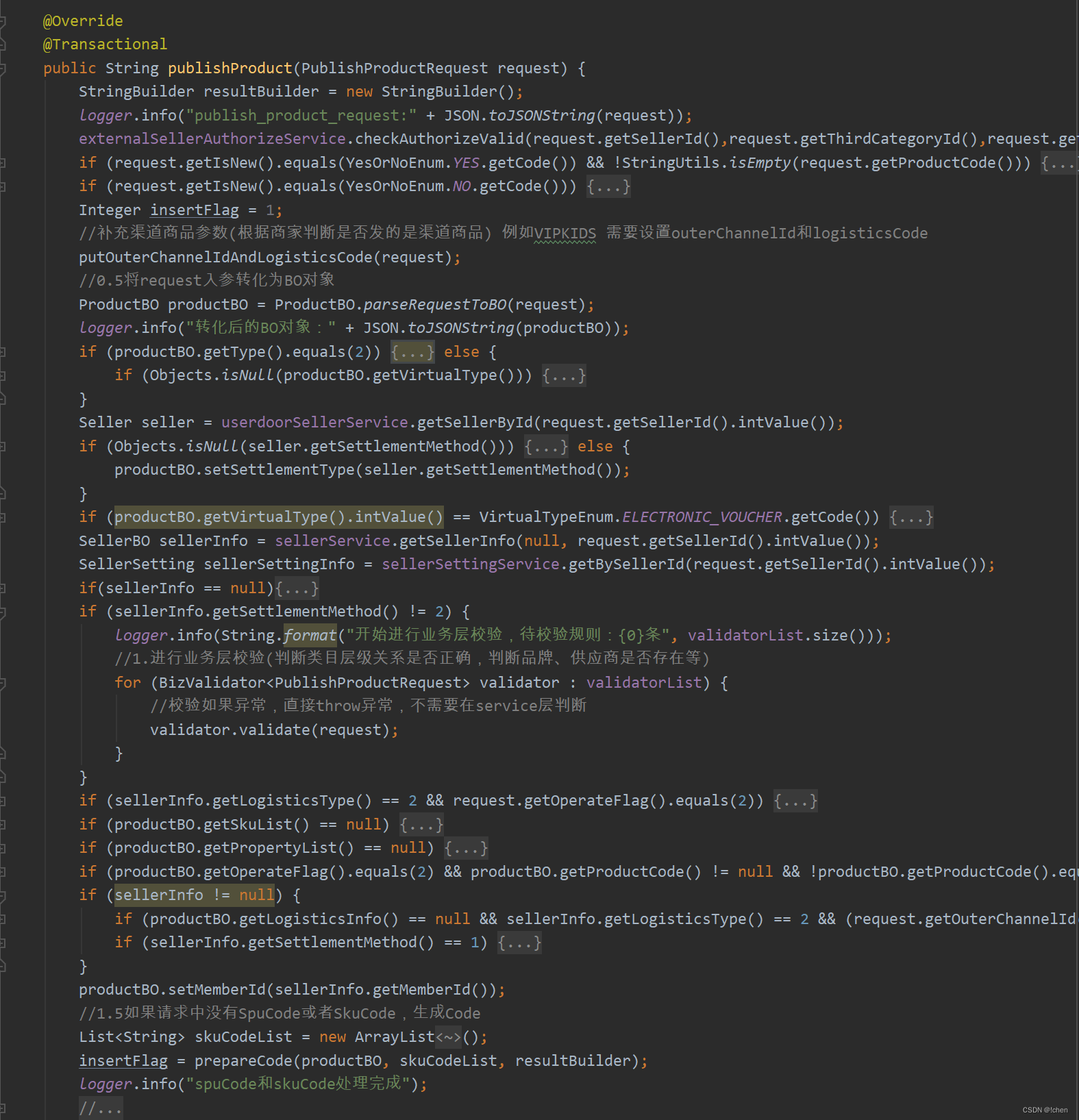
这是一段商品发布的逻辑,我们可以看到参数校验、查询、最终的insert以及update全部揉在一个事务中。遇到批量发布商品的时候就经常出现问题了,数据库主从延迟是肯定少不了的。
开启优化
其实像上述小猫遇到的这种状况我们就称其为大事务,那么我们就大概有这么一个定义。我们将执行时间长,并且操作数据比较多的事务叫做大事务。
大事务产生的原因
在我们日常开发过程中,其实经常会遇到大事务,老猫总结了一下,往往原因其实总结下来有这么几点(当然存在纰漏的地方,也欢迎大家评论区留言补充)
- 一次性操作的数据量确实多,大量的锁竞争,比如批量操作这种行为。
- 事务粒度过大,代码中的 @Transactional使用不当,其他非DB操作比较多,耗时久。比如调用RPC接口,在例如上述小猫遇到的check逻辑甚至都揉在一起等等。
造成的影响
那么大事务造成的影响又是什么呢?
- 从开发者的角度来看的话,部分大事务必定对应的复杂的业务逻辑,代码封装事务拆解不合理,研发侧维护困难,维护成本高。
- 从最终系统以及运维角度来看
- 出现了死锁。
- 造成了主从延迟。
- 大事务消耗更多的磁盘空间,回滚成本高。
- 大事务发生的过程中,由于连接池持续被打开,很容易造成数据库连接池被沾满。
- 接口响应慢导致接口超时,甚至导致服务不可用等等
(欢迎大家补充)
优化方案
大事务既然有这么多坑,那么我们来看一下我们日常开发过程中,应该如何做到尽量规避呢?老猫整理了以下几种优化方法。
- 降低事务颗粒度,大事务拆解小事务
- 编程式事务代替@Transactional。
- 非update以及insert动作外移。
- 大数据量一次性提交尽可能拆解分批处理。
- 拆解原始事务,异步化处理。
降低事务颗粒度
1、我们对@Transactional的事务粒度把控不好,有时候如果使用不当的话事务功能可能会失效,如果经验不足,很难排查,那么我们不如直接使用粗细粒度更好把控的编程式事务。TransactionTemplate。这样的话咱们的优化代码就可以写好才能如下方式。
@Autowired | |
private TransactionTemplate transactionTemplate; | |
public boolean publishProduct(PublishProductRequest request) { | |
externalSellerAuthorizeService.checkAuthorizeValid(request.getSellerId(),request.getThirdCategoryId(),request.getBrandId()); | |
...... | |
transactionTemplate.execute((status) -> { | |
try{ | |
//执行insert | |
productDao.insert(productDO); | |
productDescDao.insert(productDescDO); | |
.... | |
//其他insert以及update操作 | |
}catch (Exception e) { | |
//回滚 | |
status.setRollbackOnly(); | |
return true; | |
} | |
return false; | |
}); | |
return true; | |
} |
非update以及insert动作外移。
原始代码:
@Transactional(rollbackFor=Exception.class) | |
public void save(Req req) { | |
checkParam(req); | |
saveData1(req); | |
updateData2(req); | |
} | |
private void checkParam(Req req){ | |
Data1 data = selectData1(); | |
Data2 data2 = selectData2(); | |
if(data.getSomeThing() != STATUS_YES){ | |
throw new BusinessTimeException(.....); | |
} | |
} |
然后部分小伙伴就觉得外移么,如果不用@Transactional的情况,那直接这样不就行了么。
错误改造案例:
class ServiceAImpl implements ServiceA { | |
@Transactional(rollbackFor=Exception.class) | |
public void save(Req req) { | |
saveData1(req); | |
updateData2(req); | |
} | |
private void checkParam(Req req){ | |
Data1 data = selectData1(); | |
Data2 data2 = selectData2(); | |
if(data.getSomeThing() != STATUS_YES){ | |
throw new BusinessTimeException(.....); | |
} | |
} | |
public void save(Req req){ | |
checkParam(req); | |
doSave(req); | |
} | |
} |
这个例子是非常经典的错误,这种直接方法调用的做法事务不会生效,老猫以前也踩过这样的坑。因为 @Transactional 注解的声明式事务是通过 spring aop 起作用的,
而 spring aop 需要生成代理对象,直接方法调用使用的还是原始对象,所以事务不会生效。那么我们应该如何改造呢?我们看下正确的改造。
正确改造方案1,当然还是利用上面的TransactionTemplate:
@Autowired | |
private TransactionTemplate transactionTemplate; | |
public void save(Req req) { | |
checkParam(req); | |
transactionTemplate.execute((status) -> { | |
try{ | |
saveData1(req); | |
updateData2(req); | |
.... | |
//其他insert以及update操作 | |
}catch (Exception e) { | |
//回滚 | |
status.setRollbackOnly(); | |
return true; | |
} | |
return false; | |
}); | |
} | |
private void checkParam(Req req){ | |
Data1 data = selectData1(); | |
Data2 data2 = selectData2(); | |
if(data.getSomeThing() != STATUS_YES){ | |
throw new BusinessTimeException(.....); | |
} | |
} |
正确改造方案2,把 @Transactional 注解加到新Service方法上,把需要事务执行的代码移到新方法中。
@Servcie | |
public class ServiceA { | |
@Autowired | |
private ServiceB serviceB; | |
private void checkParam(Req req){ | |
Data1 data = selectData1(); | |
Data2 data2 = selectData2(); | |
if(data.getSomeThing() != STATUS_YES){ | |
throw new BusinessTimeException(.....); | |
} | |
} | |
public void save(Req req) { | |
checkParam(req); | |
serviceB.save(req); | |
} | |
} | |
@Servcie | |
public class ServiceB { | |
@Transactional(rollbackFor=Exception.class) | |
public void save(Req req) { | |
saveData1(req); | |
updateData2(req); | |
} | |
} |
正确改造方案3:将ServiceA 再次注入到自身
大数据量一次性提交尽可能拆解分批处理。
我们再来看大数量批量请求的场景,咱们具体来分析一下,假设上游系统存在一个批量导入2w的数据操作。如果我们读取到上游导入的数据,并且直接执行DB一次性执行肯定是不合适的。这种情况就需要我们对其请求的数据量做一个拆解。我们可以采用Lists.partition等等方式将数据拆成多个小的批量然后再进行入库操作处理。
@Servcie | |
public class ServiceA { | |
@Autowired | |
private ServiceB serviceB; | |
private void batchAdd(List<Long> inventorySkuIdList){ | |
List<List<Long>> partition = Lists.partition(inventorySkuIdList, 1000); | |
for (List<Long> idList : partition) { | |
List<InventorySkuDO> inventorySkuDOList = inventorySkuDao.selectByIdList(idList, null); | |
if (CollectionUtils.isNotEmpty(inventorySkuDOList)) { | |
serviceB.doInsertUpdate(inventorySkuDOList); | |
} | |
} | |
} | |
} | |
@Servcie | |
public class ServiceB { | |
@Transactional(rollbackFor=Exception.class) | |
private void doInsertUpdate(List<InventorySkuDO> inventorySkuDOList){ | |
for (InventorySkuDO inventorySkuDO : inventorySkuDOList) { | |
doInsert(inventorySkuDO); | |
doUpdate(inventorySkuDO) | |
} | |
} | |
} |
拆解原始事务,异步化处理。
这种异步化处理的方案其实有两种方式进行异步化操作。尤其是涉及到第三方RPC调用或者HTTP调用的时候,这种方案就更加适合。
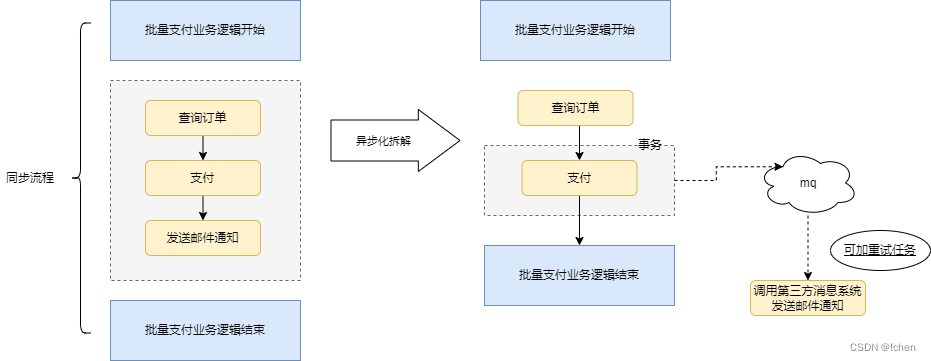
方案一,采用CompletableFuture异步编排特性,当业务流程比较长的时候,我们可以将一个大业务拆解成多个小的任务进行异步化执行。比如咱们有个批量支付的业务逻辑,因为整个流程是同步的,所以大概有了下面这样的流程。
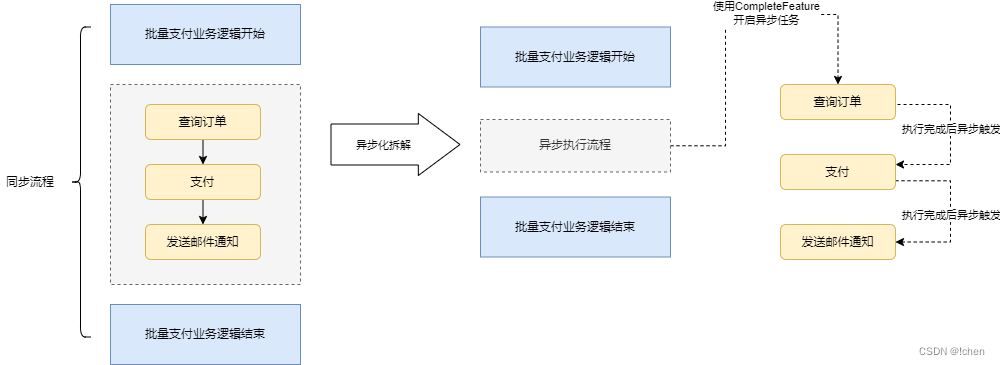
对应转换成代码逻辑的话,大概是这样的:
void doBatchPay() { | |
CompletableFuture<Object> task1 = CompletableFuture.supplyAsync(() -> { | |
return "订单信息"; | |
}); | |
CompletableFuture<Object> task2 = CompletableFuture.supplyAsync(() -> { | |
try { | |
return doPay(); | |
} catch (InterruptedException e) { | |
//log add | |
} | |
}); | |
//task1、task2 执行完执行task3 ,需要感知task1和task2的执行结果 | |
CompletableFuture<Object> future = task1.thenCombineAsync(task2, (t1, t2) -> { | |
return "邮件发送成功"; | |
}); | |
} |
方案二,Mq异步化处理,还是针对上述业务逻辑,我们是否可以将最终的发送邮件的动作剥离出来,最终再去统一执行发送邮件。