Iceberg从入门到精通系列之十九:分区
- 一、认识分区
- 二、Iceberg的分区
- 三、Hive 中的分区
- 四、Hive 分区问题
- 五、Iceberg的隐藏分区
- 六、分区变换
- 七、分区变换
一、认识分区
分区是一种通过在写入时将相似的行分组在一起来加快查询速度的方法。
例如,从日志表中查询日志条目通常会包含一个时间范围,就像针对上午 10 点到 12 点之间的日志的查询一样:
SELECT level, message FROM logs
WHERE event_time BETWEEN '2018-12-01 10:00:00' AND '2018-12-01 12:00:00'
将日志表配置为按 event_time 日期分区会将日志事件分组到具有相同事件日期的文件中。 Iceberg 会跟踪该日期,并使用它来跳过没有有用数据的其他日期的文件。
Iceberg 可以按年、月、日和小时粒度对时间戳进行分区。它还可以使用分类列(如本日志示例中的级别)将行存储在一起并加快查询速度。
二、Iceberg的分区
其他表格式(如 Hive)支持分区,但 Iceberg 支持隐藏分区。
- Iceberg 处理为表中的行生成分区值这一繁琐且容易出错的任务。
- Iceberg 避免自动读取不必要的分区。消费者不需要知道表是如何分区的,也不需要在查询中添加额外的过滤器。
- Iceberg分区布局可以根据需要演变。
三、Hive 中的分区
为了演示差异,请考虑 Hive 如何处理日志表。
在 Hive 中,分区是显式的并显示为一列,因此日志表将有一个名为 event_date 的列。写入时,插入需要为 event_date 列提供数据:
INSERT INTO logs PARTITION (event_date)SELECT level, message, event_time, format_time(event_time, 'YYYY-MM-dd')FROM unstructured_log_source
同样,搜索日志表的查询除了 event_time 过滤器之外还必须具有 event_date 过滤器。
SELECT level, count(1) as count FROM logs
WHERE event_time BETWEEN '2018-12-01 10:00:00' AND '2018-12-01 12:00:00'AND event_date = '2018-12-01'
如果 event_date 过滤器丢失,Hive 将扫描表中的每个文件,因为它不知道 event_time 列与 event_date 列相关。
四、Hive 分区问题
必须为 Hive 指定分区值。在日志示例中,它不知道 event_time 和 event_date 之间的关系。
这会导致几个问题:
- Hive 无法验证分区值 - 由编写者来生成正确的值
- 使用错误的格式(2018-12-01 而不是 20181201)会默默产生错误结果,而不是查询失败
- 使用错误的源列(例如处理时间或时区)也会导致错误的结果,而不是失败
- 由用户决定是否正确编写查询
- 使用错误的格式也会导致无提示的错误结果
- 不了解表的物理布局的用户会获得不必要的缓慢查询 – Hive 无法自动翻译过滤器
- 工作查询与表的分区方案相关联,因此在不破坏查询的情况下无法更改分区配置
五、Iceberg的隐藏分区
Iceberg 通过获取列值并选择性地对其进行转换来生成分区值。 Iceberg 负责将 event_time 转换为 event_date,并跟踪这种关系。
表分区是使用这些关系配置的。日志表将按日期(事件时间)和级别进行分区。
因为 Iceberg 不需要用户维护分区列,所以它可以隐藏分区。每次都会正确生成分区值,并且在可能的情况下始终用于加快查询速度。生产者和消费者甚至看不到 event_date。
最重要的是,查询不再依赖于表的物理布局。通过物理和逻辑的分离,Iceberg 表可以随着数据量的变化而不断演变分区方案。错误配置的表无需进行昂贵的迁移即可修复。
六、分区变换
数据文件存储在带有分区值元组的清单中,这些分区值在扫描中用于过滤掉不能包含与扫描过滤谓词匹配的记录的文件。对于数据文件中存储的所有记录,数据文件的分区值必须相同。 (清单存储来自任何分区的数据文件,只要数据文件的分区规范相同。)
表配置有分区规范,该规范定义如何从记录生成分区值元组。分区规范有一个字段列表,其中包括:
- 表架构中的源列 ID
- 分区字段id,用于标识分区字段,在分区规范中是唯一的。在 v2 表元数据中,它在所有分区规范中都是唯一的。
- 应用于源列以生成分区值的转换
- 分区名称
由 id 选择的源列必须是原始类型,并且不能包含在映射或列表中,但可以嵌套在结构中。
分区规范捕获从表数据到分区值的转换。除了转换数据值之外,这还用于将谓词转换为分区谓词。从表数据上的列谓词派生分区谓词用于将逻辑查询与物理存储分开:分区可以更改,并且始终从列谓词派生出正确的分区过滤器。这简化了查询,因为用户不必同时提供逻辑谓词和分区谓词。
分区变换
| 变换名称 | 描述 | 源类型 | 结果类型 |
|---|---|---|---|
| identity | 源值,未修改 | Any | 源类型 |
| bucket[N] | 哈希值,mod N(见下文) | int, long, decimal, date, time, timestamp, timestamptz, string, uuid, fixed, binary | int |
| truncate[W] | 值被截断为宽度 W(见下文) | int, long, decimal, string | 源类型 |
| year | 提取日期或时间戳年份,即从 1970 年开始的年份 | date, timestamp, timestamptz | int |
| month | 提取日期或时间戳月份,如 1970-01-01 以来的月份 | date, timestamp, timestamptz | int |
| day | 提取日期或时间戳日,如 1970-01-01 以来的天数 | date, timestamp, timestamptz | int |
| hour | 提取时间戳小时,即从 1970-01-01 00:00:00 开始的小时数 | timestamp, timestamptz | int |
| void | 总是产生 null | Any | 源类型或 int |
对于 null 输入值,所有转换都必须返回 null。
void 变换可用于替换现有分区字段中的变换,以便该字段在 v1 表中有效删除。
七、分区变换
Iceberg 表分区可以在现有表中更新,因为查询不直接引用分区值。
当您改进分区规范时,使用早期规范写入的旧数据保持不变。新数据是在新布局中使用新规范写入的。每个分区版本的元数据单独保存。因此,当您开始编写查询时,您会得到分割计划。这是每个分区布局使用为该特定分区布局派生的过滤器单独规划文件的地方。这是一个人为示例的直观表示:
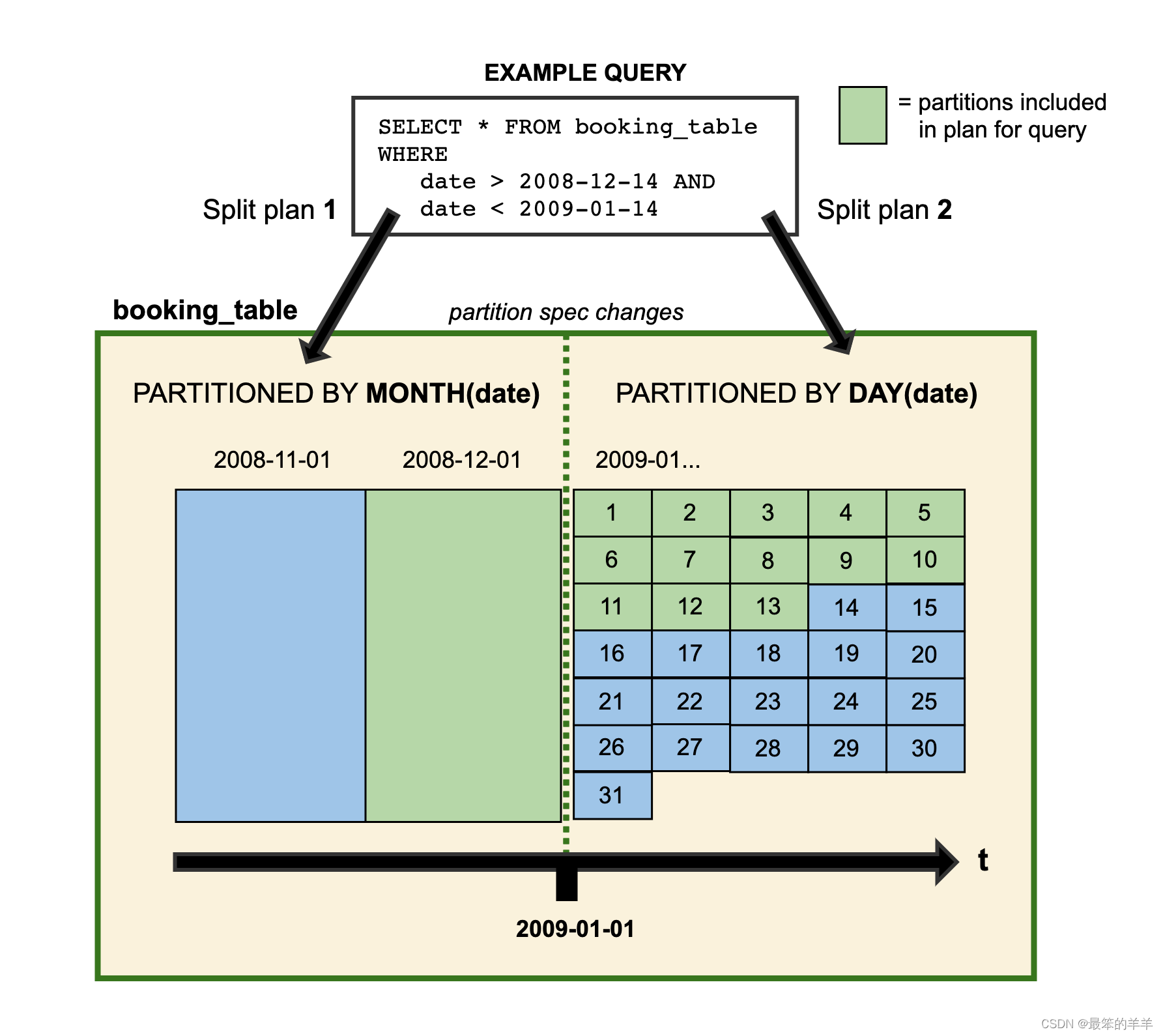
2008 年的数据按月划分。从 2009 年开始,该表进行了更新,数据改为按天分区。两种分区布局都可以在同一个表中共存。
Iceberg 使用隐藏分区,因此您无需为特定分区布局编写查询即可快速运行。相反,您可以编写查询来选择所需的数据,Iceberg 会自动删除不包含匹配数据的文件。
分区演化是元数据操作,不会急切地重写文件。
Iceberg 的 Java 表 API 提供了 updateSpec API 来更新分区规范。例如,以下代码可用于更新分区规范,以添加一个新的分区字段,将 id 列值放入 8 个存储桶中,并删除现有的分区字段类别:
Table sampleTable = ...;
sampleTable.updateSpec().addField(bucket("id", 8)).removeField("category").commit();
Spark 支持通过其 ALTER TABLE SQL 语句更新分区规范。