3D人体姿态估计是指通过计算机视觉和深度学习技术,从图像或视频中推断出人体的三维姿态信息。它是计算机视觉领域的一个重要研究方向,具有广泛的应用潜力,如人机交互、运动分析、虚拟现实、增强现实等。

传统的2D人体姿态估计方法主要关注通过二维图像进行姿态推断,即从图像中提取人体关键点位置信息,然后根据这些关键点的空间关系推断出人体的姿态。然而,由于2D图像投影存在深度信息的缺失和模糊,2D姿态估计往往无法准确捕捉到人体的三维信息。
算法介绍
为了解决这个问题,研究者们开始探索使用深度学习技术进行3D人体姿态估计。深度学习技术能够学习到更高层次的特征表示,从而提高姿态估计的准确性。下面将对3D人体姿态估计的方法和技术进行简述。
- 单视角方法
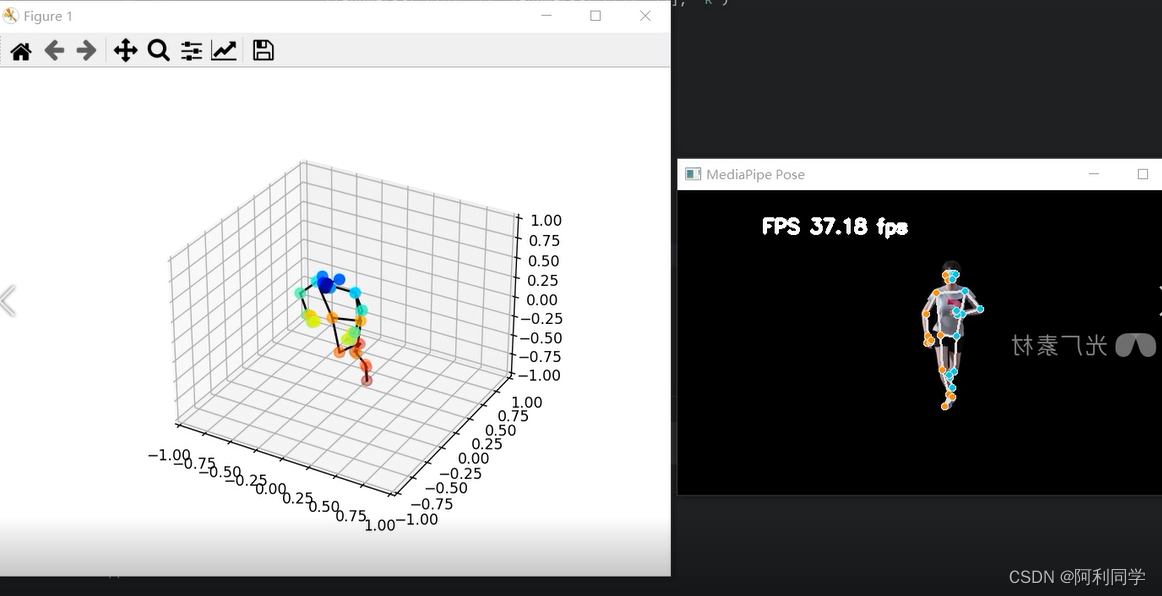
单视角方法是最常见的3D人体姿态估计方法之一。它通过从单个摄像机视角捕捉的图像中推断出人体的三维姿态。这种方法通常分为两个步骤:2D姿态估计和3D重建。
代码获取、作业帮助、论文辅导:qq1309399183
在2D姿态估计阶段,深度学习模型被用于从输入图像中检测和定位人体关键点。这些关键点可以是人体的关节位置或特定身体部位的标记点。通过预测这些关键点的位置,可以得到人体在图像中的二维姿态信息。
然后,在3D重建阶段,使用将二维姿态信息与其他信息(如深度图像、摄像机参数等)结合起来,通过一些几何变换方法,将二维姿态信息转换为三维姿态信息。这些几何变换方法可以是透视投影、三角测量等。最终,通过这些步骤,我们可以得到人体的三维姿态。
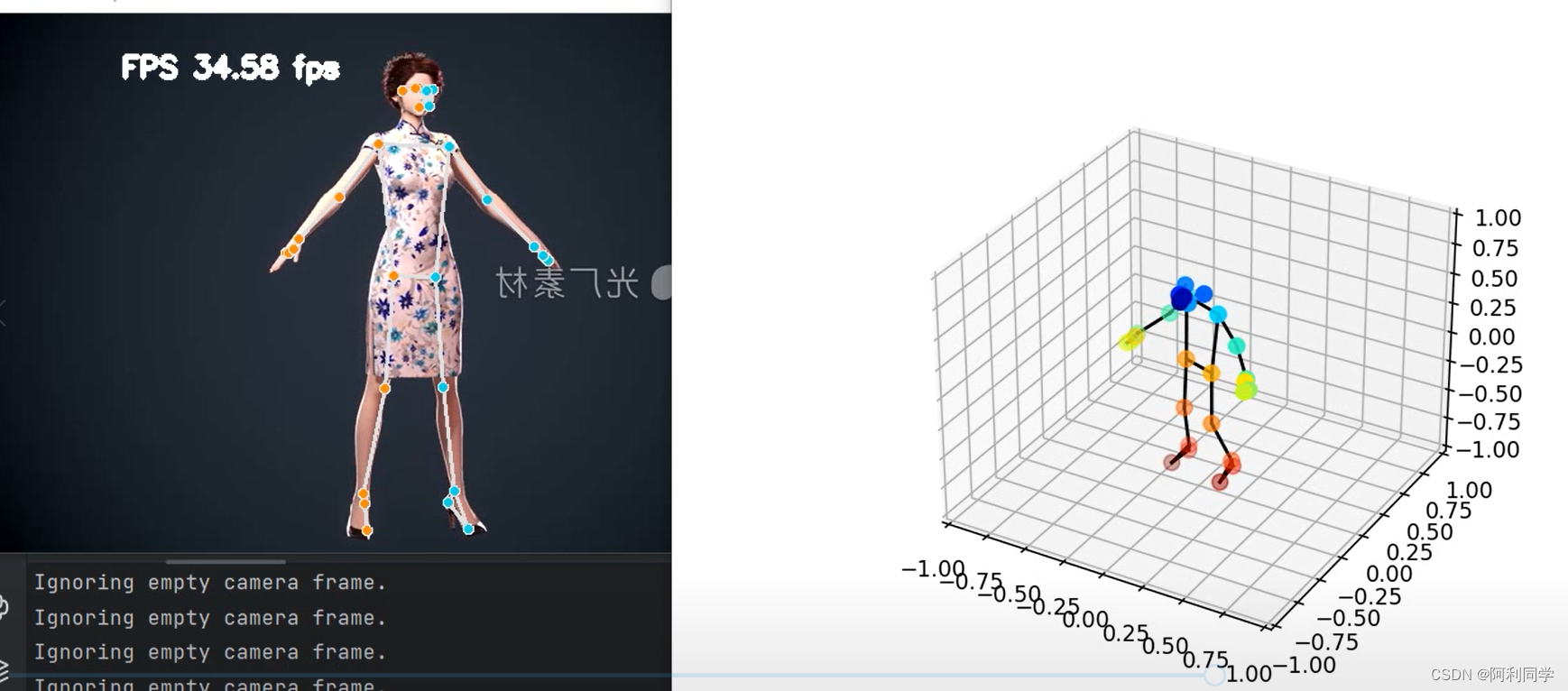
- 多视角方法
多视角方法利用从多个不同视角或摄像机捕捉的图像进行3D人体姿态估计。这种方法可以通过利用多个视角的互补信息来提高姿态估计的准确性。
在多视角方法中,首先通过单视角方法对每个摄像机视角的图像进行2D姿态估计。然后,通过使用多个视角的2D姿态信息,结合摄像机参数和几何约束,将2D姿态信息转换为3D姿态信息。
多视角方法的主要优势在于能够提供更多的观察角度和更多的几何信息,从而提高了姿态估计的准确性和稳定性。但同时,它也增加了系统的复杂性,需要进行多个视角的图像对齐和标定等步骤。
- 基于深度学习的方法
近年来,基于深度学习的方法在3D人体姿态估计领域取得了显著的进展。这些方法利用深度学习模型对大规模数据集进行训练,从而学习到人体姿态的特征表示和模式。
基于深度学习的方法通常采用端到端的训练策略,即将输入图像作为模型的输入,直接输出人体的三维姿态。这种方法可以避免传统方法中的多个阶段处理,并且能够通过大规模数据集的训练来提高姿态估计的准确性。
基于深度学习的方法通常采用卷积神经网络(CNN)或循环神经网络(RNN)等深度学习模型进行姿态估计。这些模型通常使用3D姿态标注数据进行训练,以学习从图像到姿态的映射关系。
- 结合传感器的方法
除了使用图像或视频作为输入,还可以结合其他传感器,如深度摄像机(如Microsoft Kinect)或惯性测量单元(IMU),来提高3D人体姿态估计的准确性和鲁棒性。
模型效果
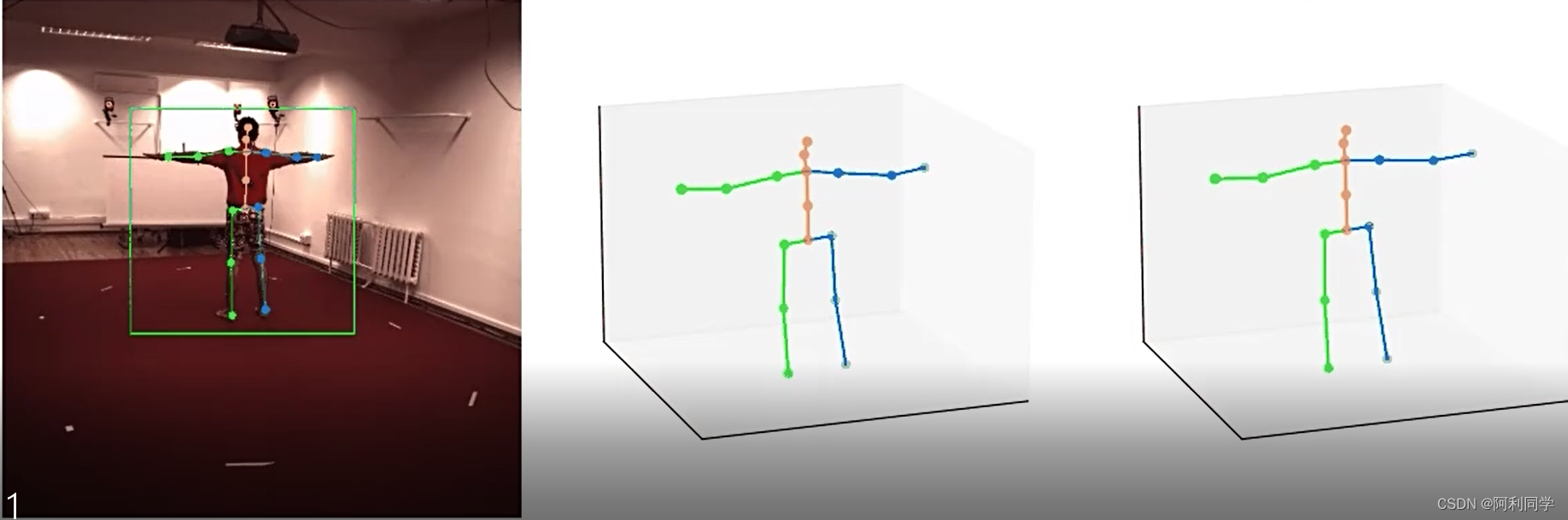
深度摄像机可以提供人体的深度信息,从而帮助更准确地估计三维姿态。IMU可以提供人体的运动信息,从而帮助解决动态姿态估计的问题。
代码介绍
import torch
from torch.utils.data import DataLoader
from torchvision.transforms import Normalizefrom openpose import OpenPoseModel, OpenPoseDataset# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 模型路径和参数
model_path = "path_to_pretrained_model.pth"
input_size = (256, 256)
output_size = (64, 64)
num_joints = 17# 加载模型
model = OpenPoseModel(num_joints=num_joints, num_stages=4, num_blocks=[1, 1, 1, 1]).to(device)
model.load_state_dict(torch.load(model_path))
model.eval()# 数据集路径
dataset_path = "path_to_dataset"# 数据预处理
normalize = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])# 加载数据集
dataset = OpenPoseDataset(dataset_path, input_size, output_size, normalize=normalize)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=4)# 测试模型
total_loss = 0
total_samples = 0with torch.no_grad():for i, (images, targets) in enumerate(dataloader):images = images.to(device)targets = targets.to(device)# 前向传播outputs = model(images)# 计算损失loss = torch.mean((outputs - targets) ** 2)total_loss += loss.item() * images.size(0)total_samples += images.size(0)average_loss = total_loss / total_samplesprint("Average Loss: {:.4f}".format(average_loss))
结合传感器的方法通常需要进行传感器的标定和数据融合等步骤,以将不同传感器的信息相结合。这些方法可以提供更多的信息来源,从而提高姿态估计的准确性和鲁棒性。
总结
代码获取、作业帮助、论文辅导:qq1309399183
- 总结起来,3D人体姿态估计是通过计算机视觉和深度学习技术从图像或视频中推断出人体的三维姿态信息。
- 它可以通过单视角方法、多视角方法、基于深度学习的方法和结合传感器的方法来实现。
- 随着深度学习技术的不断发展和硬件设备的提升,3D人体姿态估计将在很多领域中得到广泛应用,为人机交互、运动分析、虚拟现实等领域带来更多可能性。