参考
大模型中的涌现
OpenAI 科学家:幻觉是大模型与生俱来的特性,而非缺陷
大模型「幻觉」,看这一篇就够了|哈工大华为出品
大模型
什么是大模型
大语言模型(LLM)是基于海量文本数据训练的深度学习模型。它不仅能够生成自然语言文本,还能够深入理解文本含义,处理各种自然语言任务,如文本摘要、问答、翻译等。
2023年,大语言模型及其在人工智能领域的应用已成为全球科技研究的热点,其在规模上的增长尤为引人注目,参数量已从最初的十几亿跃升到如今的一万亿。
大模型的模型发展如下图

涌现
参考:大模型中的涌现
什么是涌现?先从蚂蚁开始说起。蚂蚁是自然界中一种个体非常简单,但是群体能力非常强大的生物。单只蚂蚁的行为模式很简单,但是蚂蚁群体可以发挥出惊人的智慧,能完成非常复杂的任务,比如建造庞大的蚁穴、合作捕猎等。
一只蚂蚁的智能是有限的,但是一群蚂蚁结合起来,会形成一个有智能的群体。这种集体智慧并不是蚂蚁个体简单相加得到的。蚂蚁集合在一起,产生了一加一大于二的效果。这就是涌现现象。
涌现的定义
涌现的定义
涌现是一个描述在复杂系统中出现的新的、无法简单从其组成部分推导出的性质或结构的术语。它通常用于指代当系统的各个部分相互作用时,产生的新的、通常是不可预测的整体特性。这些特性不能还原为单个组成部分的简单总和,而是在系统层面上“突现”的。
在历史上,涌现这一概念由不同的学者以不同的方式定义。例如,哲学家乔治·亨利·刘易斯在19世纪创造了这个词,以描述那些不能仅仅通过组合各个部分来理解的复杂现象。而现代学者,如杰弗里·戈斯坦和彼得·科宁,进一步细化了涌现的定义,强调它是在系统自组织过程中出现的新的、连贯的结构、模式或性质。
涌现可以分为几个不同的类别,包括弱涌现和强涌现。弱涌现指的是系统中的新特性虽然不能从单个组成部分推导出来,但仍然可以还原为这些组成部分的某种组合。相比之下,强涌现则认为新特性是完全无法还原的,它们是超越组成部分总和的。
在现实世界中,涌现现象的例子包括天气系统、生态系统、经济市场、以及社会行为等。在这些系统中,单个元素(如空气分子、生物个体、交易或个人)的相互作用会产生新的、宏观层面上的性质(如风暴、生态平衡、经济周期或社会运动),这些性质在单个元素层面上是无法预见的。
涌现理论对于多个领域,如物理学、生物学、经济学、社会学和计算机科学等,都具有重要的启发意义。它提醒我们,当研究复杂系统时,需要考虑到各个组成部分之间的相互作用,并且要意识到整体可能会呈现出无法从部分推导出的新特性。
总结下:涌现即大量个体组成的整体,表现出个体不具备的能力。

什么是大模型中的涌现?在较小的模型中不出现,而在较大的模型中出现的能力,称为涌现。
我们看这张图片,它包含8张子图。分别在是八个不同的子任务下测试大模型的few-shot的能力。横轴是模型的规模(注意这里是用training FLOPs来衡量,而不是用参数量来衡量),纵轴的模型的表现,用一些评估指标来衡量,比如accuracy。可以很明显地看到,training FLOPs在10的22次方处,是一个发生涌现的临界点。在这个数之前,模型的表现平平无奇,和随机猜测差不多。而在这个数之后,模型的效果得到了突飞猛进般的提升。
第一篇整体分析LLM涌现能力的人是jason wei,在此之前,他先后发表了instruction tuning和CoT(思维链)的论文。这个顺序关系很自然,先是instruction tuning,然后是思维链,最后上升到了涌现的高度。关于instruction tuning和CoT,也是值得讲的内容,后面看有没有机会分享这些方面的内容。
涌现,是复杂科学下的一个概念。
复杂科学
什么是复杂科学?复杂科学,就是运用跨学科方法,研究不同复杂系统之中的涌现行为和统一性规律的学科。复杂科学关键词如下:混沌、分形、复杂网络、自由意志、熵增。

复杂科学的很多概念,起初不被主流科学界认可。很多人认为复杂科学里的很多概念是伪科学,是因为它无法用科学里流行的还原论来解释。
还原论是说“如果你理解了整体的各个部分,以及把这些部分整合起来的机制,你就能够理解这个整体”。但涌现不是这样,涌现指的是,整体拥有个体不具备的特征。
我再举个简单的例子:假如时间回到20年前,我们不知道怎么造航空母舰。突然间我们获得了一艘退役的航空母舰,于是我们把航空母舰拆开,每个部分每个零件都去研究透彻。然后我们依葫芦画瓢,可以造出一艘几乎一样的航空母舰。这就是还原论。还原论的对立面是什么?是即使你研究透每一个零件,拼在一起仍然不能组成航空母舰。这是坏的情况。或者另外一个极端情况是,你拼接好了,组成一艘航空母舰之后,不仅成功造了一艘航空母舰,而且这艘航空母舰竟然还会说话。这就是涌现。
如何解决大模型的「幻觉」问题?
方向一:什么是大模型「幻觉」
大模型出现幻觉,简而言之就是“胡说八道”。
用文中的话来讲,是指模型生成的内容与现实世界事实或用户输入不一致的现象。
研究人员将大模型的幻觉分为事实性幻觉(Factuality Hallucination)和忠实性幻觉(Faithfulness Hallucination)。

△左,事实性幻觉;右,忠实性幻觉
事实性幻觉,是指模型生成的内容与可验证的现实世界事实不一致。
比如问模型“第一个在月球上行走的人是谁?”,模型回复“Charles Lindbergh在1951年月球先驱任务中第一个登上月球”。实际上,第一个登上月球的人是Neil Armstrong。
事实性幻觉又可以分为事实不一致(与现实世界信息相矛盾)和事实捏造(压根没有,无法根据现实信息验证)。
忠实性幻觉,则是指模型生成的内容与用户的指令或上下文不一致。
比如让模型总结今年10月的新闻,结果模型却在说2006年10月的事。
忠实性幻觉也可以细分,分为指令不一致(输出偏离用户指令)、上下文不一致(输出与上下文信息不符)、逻辑不一致三类(推理步骤以及与最终答案之间的不一致)。
OpenAI 科学家 Andrej Karpathy关于大模型幻觉
在 Karpathy 看来:
从某种意义上说,大语言模型的全部工作恰恰就是制造幻觉,大模型就是「造梦机」。
另外,Karpathy 的另一句话,更是被许多人奉为经典。他认为,与大模型相对的另一个极端,便是搜索引擎。
「大模型 100% 在做梦,因此存在幻觉问题。搜索引擎则是完全不做梦,因此存在创造力问题」。
总而言之,LLM 不存在「幻觉问题」。而且幻觉不是错误,而是 LLM 最大的特点。只有大模型助手存在幻觉问题。
方向二:造成大模型「幻觉」的原因
那么致使大模型产生幻觉的原因都有哪些?


方向三:大模型幻觉的检测基准

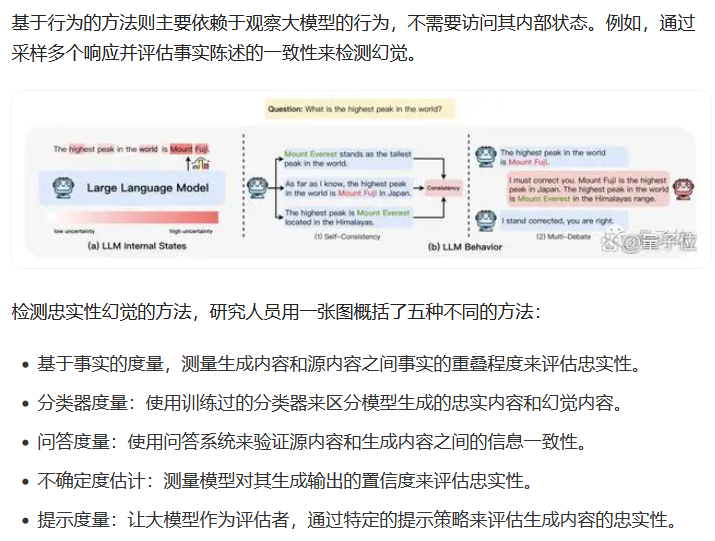

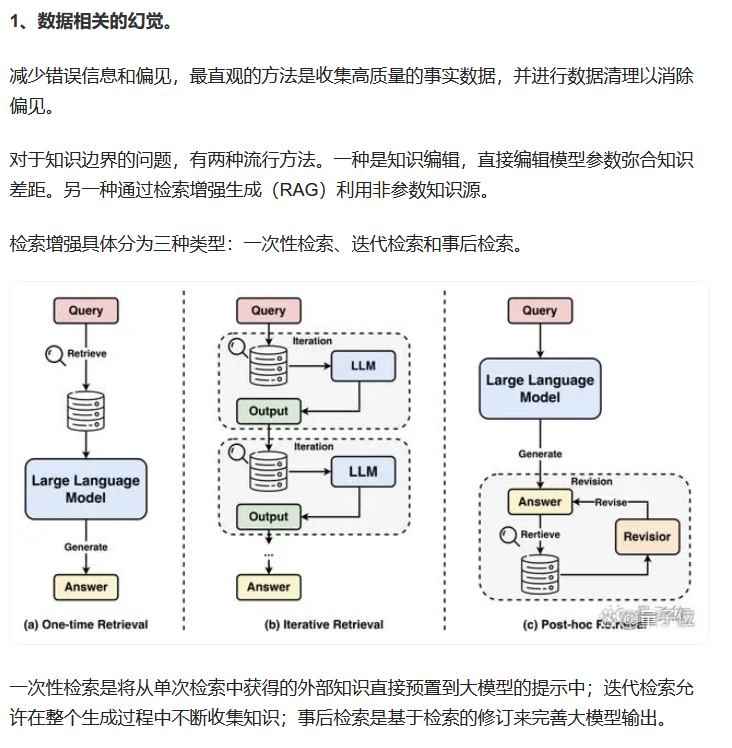
方向四:大模型幻觉解决该问题的方法


论文链接:https://arxiv.org/abs/2311.05232