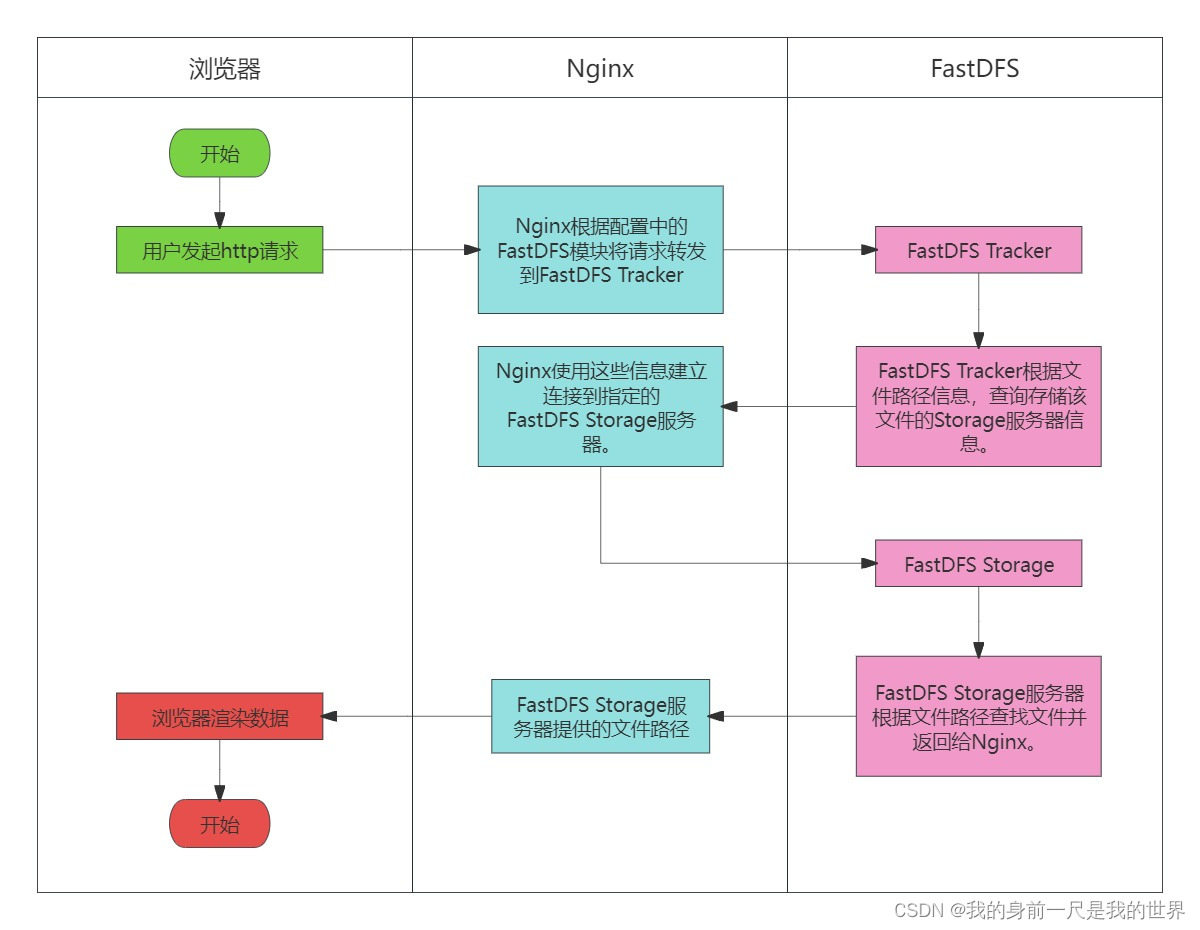
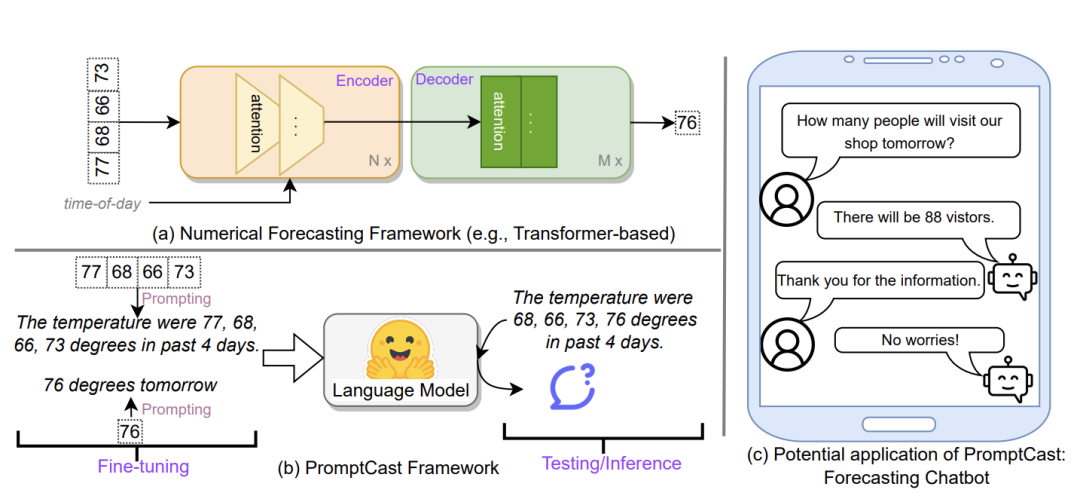
目前时序预测的SOTA模型大多基于Transformer架构,以数值序列为输入,如下图的上半部分所示,通过多重编码融合历史数据信息,预测未来一定窗口内的序列数值。
受到大语言模型提示工程技术的启发,文章提出了一种时序预测新范式,即通过一定的提示词模版将数值输入转化为语句,利用大语言模型进行预测,把时序预测转变成了一个对话任务,如下图的下半部分所示。同时,文章公开了数据集(PISA)用于评估所提出算法的性能。
文章地址:https://arxiv.org/pdf/2210.08964.pdf
代码地址:https://github.com/HaoUNSW/PISA
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
大模型学习资料、数据代码、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

数据集介绍
PISA数据集包含三个实际场景的数据,分别是:天气预报数据、电力负荷预测数据和人类活动预测数据。
-
天气预报数据集来自网站:https://academic.udayton.edu/kissock/http/Weather/default.htm,PISA从中随机选择了110个城市的每日平均温度(以华氏度为单位)。
-
电力负荷数据(ECL)来自网站:https://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014,原始数据包含321个用户每小时的电力消耗数据(以千瓦时为单位),作者剔除了那些记录不完整的用户数据,并从中随机选择了50个记录完整的用户数据。
-
SafeGraph人类活动数据(SG)来自SafeGraph Weekly Patterns3记录的每日访问POI的访客数,随机选择了324个记录完整的POI15个月的访客数。
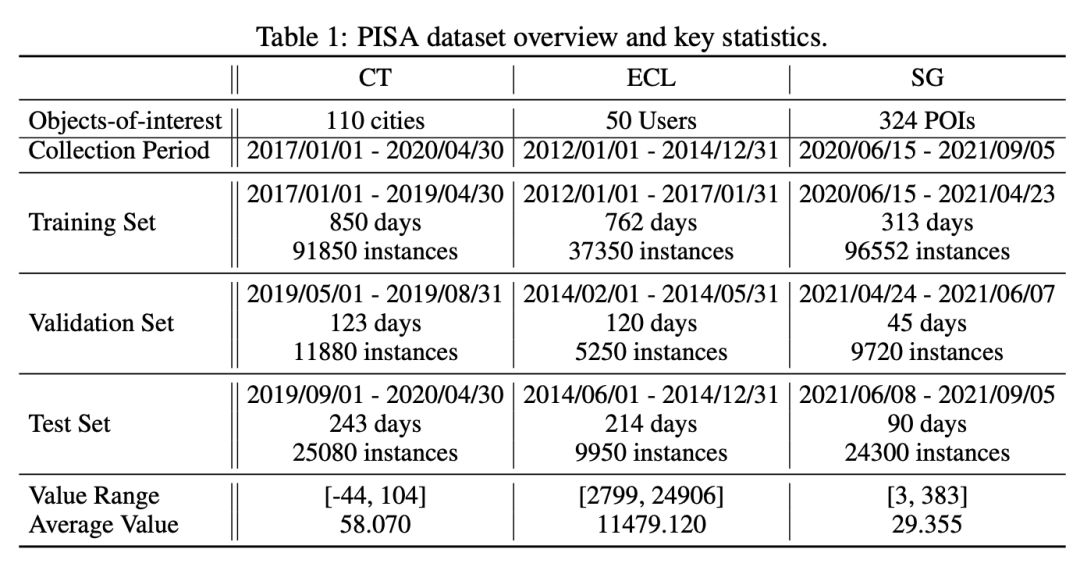
作者依次将上述数据集按照7:1:2的比例,沿时间轴划分成了训练、验证和测试数据集,同时采用滑窗的方式构建样本(基于15个历史样本预测下一个时刻的值)。为了区分数值数据和为语言模型处理的基于语言的数据集,通过上述滑动窗口处理的数值序列称作PISA-numerical,整个数据集包含三十万左右的样本点。作者对所有的数据都进行了脱敏处理,避免信息泄漏。
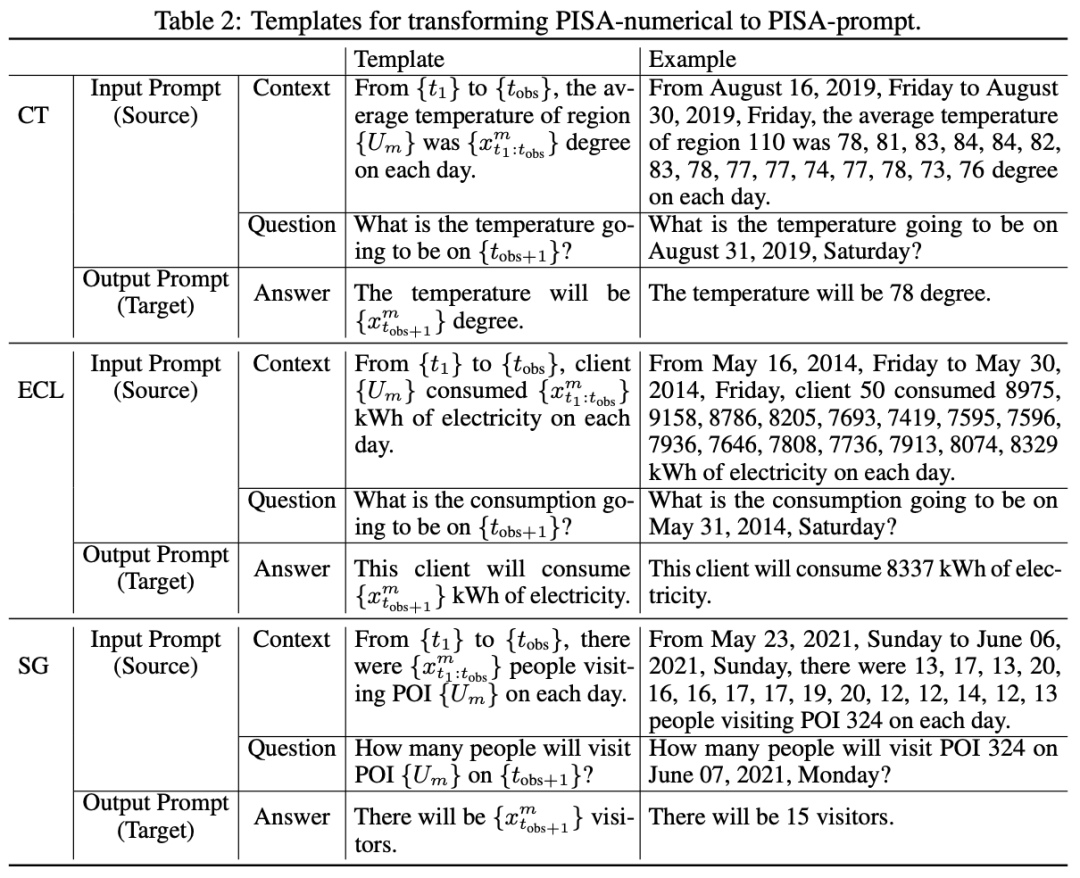
此时构建的PISA-numerical并不能直接送入语言模型中进行预测,文章进一步利用templeta实现data-to-text的转变,具体使用的模版如下,这里就不过多阐述。可以看到通过如下的转变,预测样本转变了一问一答的形式,符合语言模型输入输出的形式。
模型与实验
文章的实验设计围绕如下两个问题展开:
-
RQ1: 能否使用语言模型在PromptCast任务设置下预测时间序列?与传统基于数值的时间序列预测方法相比,基于语言模型的性能如何?
-
RQ2: 使用提示以及语言生成模型进行时间序列预测能否实现更好的泛化能力?
除了使用RMSE和MAE作为评价指标,文章考虑到语言模型的推理过程存在不确定性,无法保证每个测试实例都能能解码出数值引入了缺失率作为一项评估指标,定义为,其中和分别是测试集中的实例总数和能成功解码预测值的实例数,缺失率越小对应更好的性能。
在语言模型部分,文章选取了10个语言模型进行对比验证,包括T5、Bart、BERT、RoBERTa、Electra、Bigbird、ProphetNet、LED、Blenderbot和Pegasus。传统数值预测方法部分,文章选取了3种简单的预测方法:复制昨天(CY)、历史平均(HA)和复制上周(CLW)。基于深度学习的数值预测模型:文章选取了AutoARIMA,LSTM,TCN,vanilia Transformer,Informer、Autoformer,FEDformer。
数值模型和语言模型的结果如下:
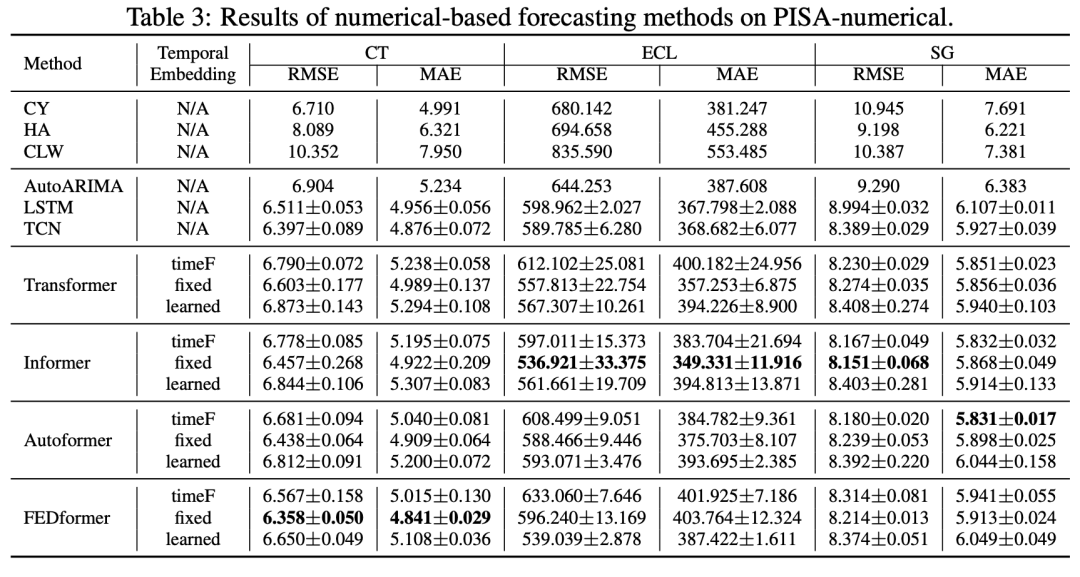 其中只有基于transformer的模型可以采用不同的方式构造temporal embedding(position embedding),这里文章对比了三种不同temporal embedding的效果,其中fixed embedding展现出最好的效果。
其中只有基于transformer的模型可以采用不同的方式构造temporal embedding(position embedding),这里文章对比了三种不同temporal embedding的效果,其中fixed embedding展现出最好的效果。
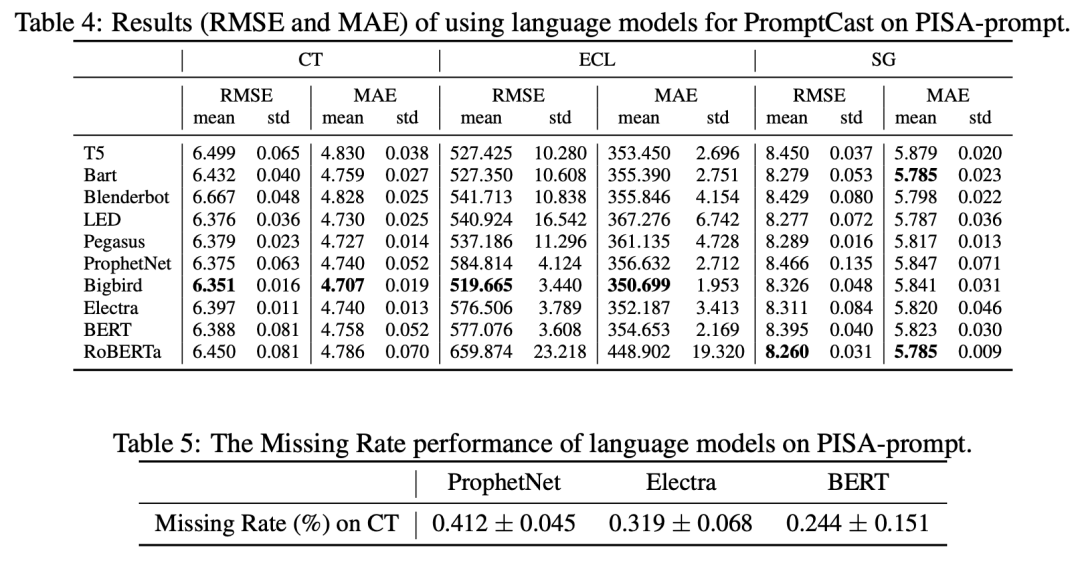
对于所有的语言模型,均使用的是由HuggingFace提供的现成的预训练权重进行初始化。其中,这些预训练权重是用通用英语语料库数据集,如BookCorpus、CC-News和OpenWebText等训练的,这些数据集通常收集的是一般文章,并不包括时间序列的数据,PISA虽是公开数据集,但仅可在线获取csv格式数据,这保证了语言模型预训练过程中没有使用PISA数据集,避免了文本泄漏。在实验中,每个语言模型均使用了PISA中对对应的训练集进行微调。对比不同的语言模型,Bigbird展现出最佳性能。对比数值模型和语言模型,语言模型在CT和ECL子集均展现出更好的性能,在SG上也达到了与数值模型差不多的结果。除了BERT、Electra、Bigbird、ProphetNet,其他语言模型的缺失率均为0,成功解码出包含数值的回复。这部分实验回复了作者提出的第一个问题,即通过promptcast的方式,语言模型是能够进行时间序列预测任务,并且能够达到跟数值预测模型不相上下的结果。
接着作者进一步测试了在零样本(用两个数据集训练或微调,用另一个数据集做测试)和从头开始用PISA数据集训练语言模型两种不同设定下,数值模型和语言模型的对比效果。
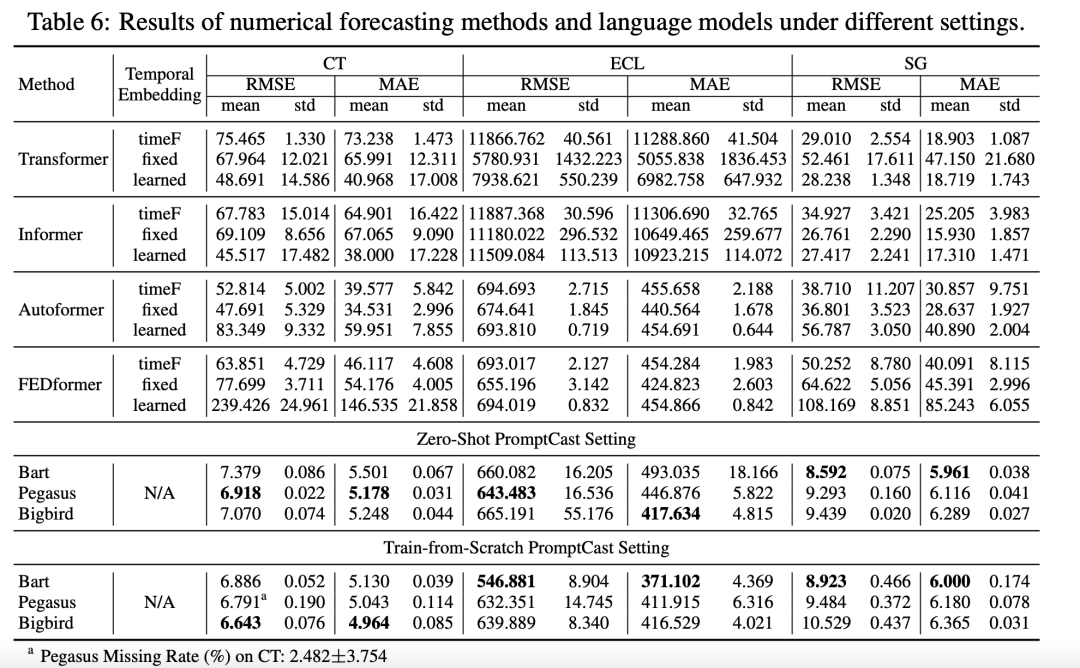
大部分数值模型在零样本设定下表现出较差的性能,相反不论是从头开始训练还是零样本微调,三个语言模型都表现出不错的效果,具有更好的泛化性能。
总结
文章将时序数据转变成文本数据,将时序预测任务转变成对话预测任务,利用语言模型实现了时序数据预测,也通过不同实验验证了语言模型在时序预测任务的有效性和泛化性。同时,文章构建了首个基于提示词的时序预测任务数据集。
为什么语言模型能够进行时序预测,作者认为通过提示词,语言模型可以很好地使用辅助信息,如一天中的时间和场景语义信息,同时更好地理解这些辅助信息与时序数据间的关系,有助于提升预测性能。
同时,作者也希望本文的探索能够为其他研究者提供有关后续研究的启发,例如如何生成适合数值数据的文本提示,固定的模板可能导致偏见。为此,是否可以通过语言模型自动生成对时序数据的描述。