引言
最近在阅读鸣嵩的一篇文章,数据库的下一场革命:S3 延迟已降至原先的 10%,云数据库架构该进化了 收获很多,过去时间也基于对象存储做过一些功能实现,特记录下。关于鸣嵩:
曹伟,花名鸣嵩,原阿里巴巴OLTP和 NoSQL数据库产品总负责人,已经独立创业,成立 杭州云猿生数据有限公司。
曹伟 2011年加入阿里数据库团队,作为核心成员历经双11、RDS等阿里数据库变革历程,主导云数据库 POLARDB和HybridDB产品的自主研制,并在 SIGMOD、VLDB等顶级国际学术会议上发表多篇一作文章,他也是中国计算机学会数据库专委会委员
对象存储
对象存储很多人都很熟悉,耳熟能详的很多产品,Amazon S3、Google Cloud Storage 、 Microsoft Azure Storage、阿里云OSS、腾讯云COS等等,我们会发现只要是云厂商,均会提供对象存储产品。
优点
包括:
- 易于管理,访问简单,通过 RESTful APIs(如HTTP/HTTPS)访问,简单的接口PUT/GET/DELETE;提供多语言的SDK
- 高度可扩展,在任何Region内可读写
- 命名空间扁平:对象存储没有像文件系统那样的层级目录结构,而是使用唯一的标识符来检索对象。当成对象存储的路径也可以类似于文件系统多级目录看待,通过LIST操作列出所有前缀匹配若干“路径”下的所有对象,但是LIST很耗时。
- 成本低,价格便宜,1TB 1个月120元左右。
- 总吞吐高
缺点
- 单个对象读写延迟大
- 性能低:与块存储相比,对象存储的性能可能较低,尤其是对于需要高速随机访问的场景;因为对象存储的实现,LIST操作也可能就是一个随机访问的过程
- 一致性模型:对象存储提供不同的一致性模型,可能影响业务逻辑
RDS
RDS(Relational Database Service)是指关系型数据库服务,它是一种提供在云中托管、管理关系型数据库的服务。RDS 本质上是关系型数据库上云后的产品,典型产品,包括Amazon RDS、Azure SQL Database、阿里云RDS、腾讯云RDS、华为云RDS,我们会发现只要是云厂商,基本也均会提供RDS产品(这句话很熟悉)。
RDS的众多特性这里不展开,其中RDS 通常以云盘(即块存储)作为其核心存储基础设施,在上述文章中,抛出了如下观点:
在技术革新缺席的前提下,云盘在性价比和计费策略方面失去了其竞争优势,我们判断其会从云厂商的主导产品降级为边缘选项。
文章中,认为公有云的关系型数据库,将会从依赖云盘->利用好对象存储,向采用更加云原生的架构的新时代迈进。
云上存储介质
云盘
云盘主要缺点如下:
- 云盘定价高。相比于不到1千元 1TB NVMe SSD,云盘需要更多价格。个人觉得,目前主要收益于硬件发展确实很迅速,笔者最近更换笔记本电脑,加装了几TB的固态硬件,价格确实已经很便宜,机械硬盘已经不再考虑了。
- 云盘弹性不足,仅支持扩容,不支持缩容。比如业务高峰期间,完成扩容;业务高峰过后,无法迅速缩容,进一步加大业务使用成本,无法按量付费。
- 高可用能力成本高。灾难恢复能力局限于单个可用区(AZ)。如果希望实现跨越AZ的高可用,需要多AZ购买。对于分布式数据库而言,成本更高:
- 单个AZ云盘多副本存储,保证单AZ内存储的可用性
- 分布式采用多副本同步(上层通过RAFT等共识算法实现复制),多个AZ场景下数据冗余过多
- 性能不足。云盘使用分布式架构,通过 Erasure coding 机制将数据分割成多个小片段,同时所有IO操作都需要网络,延迟较本地盘高一个数量级。这里感触也是比较多,在云盘很多服务下,有时候经常因为达到云盘本身的IO带宽上限进而影响服务。
云上的本地盘实例存储
和云盘不同,实例存储采用了类似于 SR-IOV 和 SPDK 的高效虚拟化技术。优势在于:
- 实例存储的延迟和带宽都接近物理 SSD 的性能
- 价格便宜,1TB每月不到300元
最大缺点在于:单副本存储,没有多副本高可用机制,如果宿主机故障了,数据永久丢失,因为没多副本。
SR-IOV 和 SPDK 是用于提高虚拟化环境中网络和存储性能的两种不同技术,分别关注 I/O 虚拟化和存储性能优化。
SR-IOV (Single Root I/O Virtualization):
SR-IOV 是一种硬件虚拟化技术,旨在提高虚拟化环境中的网络和 I/O 性能它允许物理设备(如网卡)在多个虚拟机之间进行直接共享,而无需主机 CPU 的干预。关键特点:
-
硬件虚拟化: SR-IOV 允许物理设备在多个虚拟机之间创建虚拟功能,而无需主机的软件层介入。因此虚拟机可以直接地访问物理硬件,从而提高了性能。
-
虚拟机隔离: SR-IOV 提供了一种在虚拟环境中实现硬件 I/O 隔离的方法。每个虚拟机可以被分配到物理设备的一个虚拟功能,而这个虚拟功能可以被单独配置和管理。
-
单根结构: 单根结构指的是整个 SR-IOV 网络设备的管理和配置由单一的根设备进行。这有助于简化配置和管理。
-
性能提升: 相对于传统的软件实现的虚拟网络,SR-IOV 提供了更低的虚拟化开销,从而提高了网络性能。
SPDK (Storage Performance Development Kit):
SPDK 是一个用于构建高性能存储应用程序的开源软件开发工具包。目标是提高存储系统的性能和效率。SPDK 的关键特点:
-
用户态操作: SPDK 在用户态(用户空间)运行,避免了传统的内核态(内核空间)存储堆栈的一些性能限制,从而减少 I/O 操作的延迟。
-
零拷贝: SPDK 鼓励零拷贝操作,通过直接的用户态 I/O 操作来避免数据在用户态和内核态之间的多次复制,从而减少存储系统的处理时间。
-
NVMe 支持: SPDK 适用于支持 NVMe(Non-Volatile Memory Express)设备的高性能存储系统。它提供了针对 NVMe 设备的优化,最大程度地利用其性能潜力。
-
异步 I/O 操作: SPDK 使用异步 I/O 操作,允许应用程序并行处理多个 I/O 请求,提高了系统的并发性。
-
模块化设计: SPDK 的设计模块化,允许开发者选择性地使用或扩展其功能,以适应不同的应用场景。
对象存储对比
云盘、云上本地盘实例存储、对象存储对比:
| 特点 | 云盘 | 云上本地盘实例存储 | 对象存储 |
|---|---|---|---|
| 存储类型 | 块存储 | 虚拟化技术 | 对象存储 |
| 访问方式 | 块设备访问 | 接口访问 | HTTP(S) 访问,通过 API |
| 访问性能 | 高,适合随机读写 | 高,适合随机读写 | 通常较低,适合大规模数据 |
| 成本 | 最高 | 较低 | 最低 |
| 适用场景 | 适用于需要低延迟的应用 | 单个对象读写延迟大,但总吞吐很高 | 适用于大规模数据、归档等 |
| 数据高可用 | 高,适用于关键业务,但成本高 | 低,宿主机挂了数据没了 | 高,通过冗余和分布实现,但成本低 |
| 可伸缩性 | 适用于小规模到大规模,但不具备迅速缩容 | 适用于小规模到大规模, 但不具备迅速缩容 | 高 |
| 吞吐 | 低 | 低 | 高,支持 10Gb 乃至 100Gb 的访问带宽 |
综上比较,对象存储在定价、高可用成本、吞吐等各方面都很有优势,但是单个对象读写延迟较高。在过去基于对象存储开发的项目,笔者也深刻感知到这一点,比如单个对象PUT/GET只有十几M/S,但利用底层对象存储的并行机制结合业务层的异步和并行框架设计,可以跑到上G/s的速度。
而文章中提到
对象存储的缺陷是其延迟比较高,首字节访问延迟可能高达数十毫秒。这一问题部分源于早期对象存储解决方案通常使用 HDD 作为存储媒介,并且在软件层面,I/O 请求的排队处理也会造成一定延迟。然而,高延迟并非对象存储的本质缺陷,而是由于成本考虑和产品定位所做的权衡。
这个也特别有道理,本身一个系统设计最终是各方面的选择和取舍。而 AWS Reinvent 大会上发布的"S3 Express One Zone"服务,将延迟减少至原先的十分之一,实现了毫秒级的响应速度,这样的延迟其实已经和之前印象中对象存储特性很不一致了。当然带来的缺陷是:
- S3 Express One Zone不再支持跨AZ的容灾和可用,数据都在单个AZ内。这个也很好理解,跨AZ的读写,因为网络RT很大,比如北京到深圳 RT有24毫秒左右,跨城的延迟很难去优化到毫秒级,可能在上百毫秒,甚至更高
- 定价贵。价格是 S3 标准版的 7 倍,是云盘 EBS gp3 的 2 倍。个人感觉是留下未来的降价空间,给客户打折~~~
延迟+成本+持久性
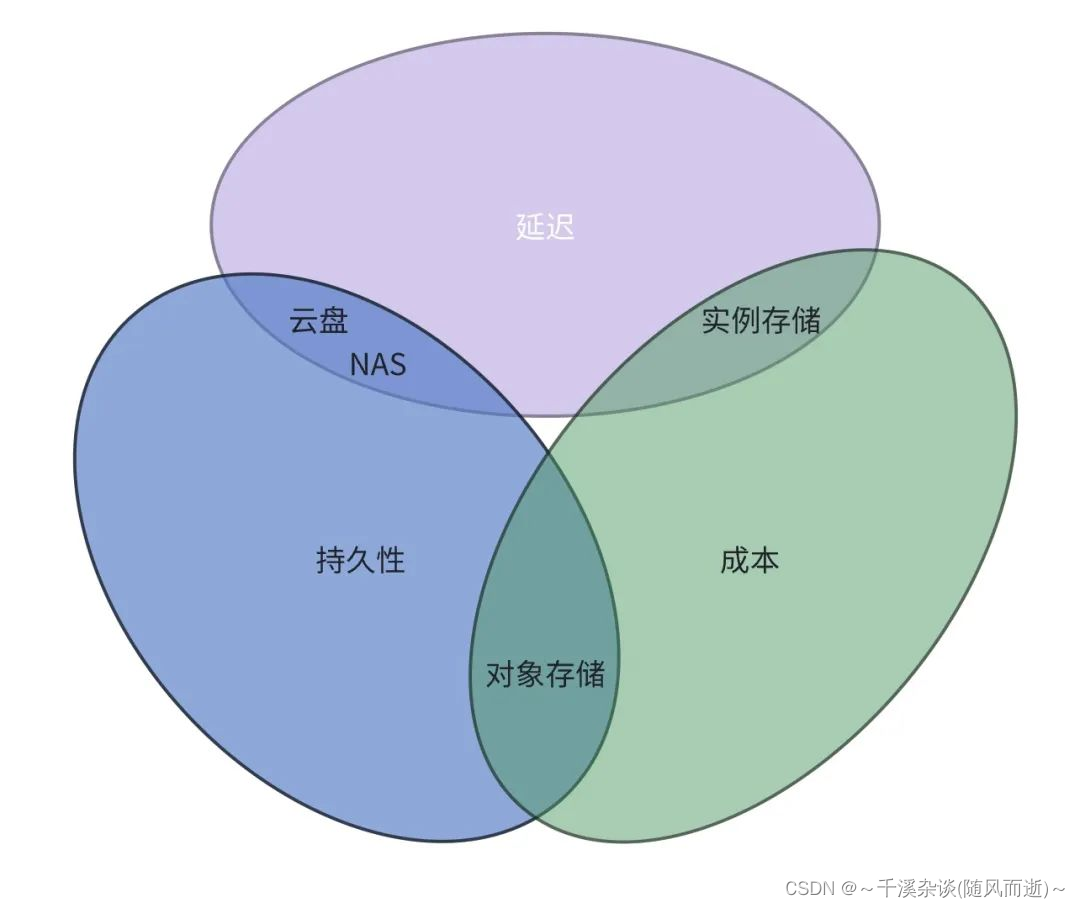
参考数据库的下一场革命:S3 延迟已降至原先的 10%,云数据库架构该进化了 文章中一张图
云盘/NAS:低延迟、持久性好(高可用),但是成本较大
实例存储:低延迟、成本低(单个副本),但是持久性差
对象存储:延迟加大、成本低、持久性好
有点类似之前的文章浅谈CAP+ACID+BASE理论
的CAP,很难有一种云存储产品,在延迟、成本、持久性各方面都达到很好的效果。
目前降本增效是企业广为提的一个概念,如何基于最低的成本的构建考虑的数据库服务?
基于云上的本地盘实例存储
云上的本地盘实例存储低延迟且成本低,但是单副本存储。基于云上的本地盘实例存储,上层通过多副本的机制构建数据库系统,但是问题在于多个云上的本地盘实例存储,可能因为相同的原因的丢失数据, 比如同一批固件BUG的SSD。基于云上的本地盘实例存储,上层采用多副本机制,也未必降低丢失数据的概率。对数据持久性有极高要求的生产环境来说,这种方案并不适用。
延迟和持久分离
通过对象存储保证高持久性、通过云盘/实例存储来保证延迟。具体而言:
- 写操作,有缓存或者聚合,直接写云盘/实例存储等低延迟存储介质,上层通过共识算法多副本同步。
- 云盘/实例存储等的数据,会被后台搬迁到对象存储上,同时云盘等只保留数据即可,这样主要数据在对象存储上,不仅高持久,而且低成本(存储便宜)
- 读操作:构建缓存(比如内存的Cache);对于位于对象存储,可以采用预热、并行读取等技术手段,保证读取的高效性
Serverless
Serverless 是一个很火的概念,Serverless 本质是一种云计算服务模型,其主要理念是使用者无需关心底层的服务器资源和管理,而可以专注于业务逻辑。核心特点是事件驱动、按需自动扩展以及按执行时间计费。而对于Serverless 数据库,提供了低门槛、灵活扩展和缩容、按量付费等重要特性。其中上述特性对于存储的隐含要求在于:
- 需要保证按量付费,需要存储池化,需要用多少,就给云厂商付多少钱,对象存储很匹配这一点。
- 高可用。Serverless 不关心底层的服务器资源和管理,自然也希望本身服务提供高可用的能力。因此Serverless的数据库,需要保证其计算节点池和存储池都在跨 AZ 环境中提供无缝的容灾能力。对象存储也提供了跨AZ的读写能力。
基于对象存储的云数据库
基于上述分析,文章中提出了基于对象存储的云数据库的关键特性:
行列混合存储格式
由单纯的行存储变为行列混合存储,其中这里主要原因目前很多数据库厂商在提HTAP,而列存天然适合于AP数据分析类的业务场景。
关于HTAP(Hybrid Transactional/Analytical Processing)是一种数据库架构,旨在同时支持事务处理(Transactional Processing,OLTP)和分析处理(Analytical Processing,OLAP)。传统上,这两种工作负载分别在不同的系统上执行(比如分析用数据仓库),但 HTAP 将它们集成到同一个系统中,以提供更为综合的数据处理能力。
将行存数据转换为 Pax 格式(行列混合存储格式)存入对象存储好处不仅在适用HTAP,而且可以减少内存开销、降低数据加载时间等
OLTP 与数据湖的深度融合
数据湖(Data Lake)是一种用于存储大量结构化和非结构化数据的架构,旨在为企业提供一个灵活、低成本的数据存储和分析解决方案。数据湖的核心思想是将数据以原始形式保存,并在需要时进行分析、处理和提取价值。关键特点和优势:
- 多样性数据: 数据湖容纳多种类型的数据,包括结构化数据(如关系型数据库中的表格)、半结构化数据(如XML、JSON)以及非结构化数据(如文本文件、图像、音频和视频等)。目前其实多模数据库也支持这么多类型,所以个人理解数据湖从某些方面定义其实和多模数据库类似
- 原始数据存储: 数据湖保存原始数据,不对数据进行预处理或规范化。企业可以存储原始数据,然后根据需要进行多层次的处理和分析。
- 弹性存储: 数据湖通常建立在分布式存储系统上,如HDFS(Hadoop Distributed File System)或云存储服务,以提供弹性和可扩展性。
- 低成本: 数据湖采用相对低成本的存储解决方案
- 分析和处理: 支持多种分析和处理工具,包括SQL查询、数据挖掘、机器学习和大数据处理框架。
- 实时和批处理: 数据湖支持实时和批处理模式
- 安全性: 数据湖通常提供安全性控制,包括对数据的访问权限、加密、身份验证等,以确保敏感数据得到保护。
一种TP和AP系统数据流转的方式,比如数据库->ETL或者CDC能力->数据仓库。
ETL(提取、转换、加载)流程不仅管理负担重,而且实时性较难保证,中间流程过多。
一种新的方式,在数据库中,直接支持将全量数据以行列混合存储格式持久化并写入对象存储,OLTP 数据库可以无缝地将在线数据直接写入数据湖环境,企业可以更快捷、方便使用这些数据
K8s数据库管理
K8S+对象存储+数据库会让管理更简单
总结
最大几点收获如下:
- 不同时代的硬件发展,会导致系统的架构巨大变化,比如早期的机械盘,数据库领域较多采用B+树的设计,SSD更适合LSM tree的设计,而目前硬件迭代很多,在很多新型硬件下,原来系统的设计或者假设就不存在了,比如超大内存。因此我们需要学习和了解新的硬件,然后设计合适的软件架构。软件基于硬件构建。
- 企业客户的一个最大需求在于,如何节约成本同时功能完善、性能齐全,传说的既要也要。一些情况不合理,但是有一些情况是可以通过新的设计来满足的,技术服务于业务需求
- 云盘/对象存储各有优缺点,合适的搭配可以达到更好的效果,有点类似于将军指挥,士兵前线,各司其职的思想。设计是需要权衡的,成本、延迟、持久如何权衡。
- 技术发展很快,比如对象存储的低延迟,S3 Express One Zone在牺牲了跨AZ的容灾,也提供了相当低延迟的读写服务,基于这种特性一定会有新的设计。