前言
PolarDB MySQL
传统的关系型数据库有着悠久的历史,从上世纪60年代开始就已经在航空领域发挥作用。因为其严谨的一致性保证以及通用的关系型数据模型接口,获得了越来越多的应用。2000年以后,随着互联网应用的出现,很多场景下,并不需要传统关系型数据库提供的一致性以及关系型数据模型。由于快速膨胀和变化的业务场景,对**可扩展性(Scalability)以及可靠性(Reliability)**更加需要,而这又正是传统关系型数据库的薄弱之处。此时,新的适合这种业务特点的数据库出现,就是我们常说的NoSQL。但是由于缺乏一致性及事务支持,NoSQL被很多业务场景拒之门外。缺乏统一的高级的数据模型和访问接口,又让业务代码承担了更多的负担。数据库的历史就这样经历了多重否定,又螺旋上升的过程。
PolarDB就是在这种背景下出现的,由阿里巴巴自主研发的下一代关系型分布式云原生数据库。在兼容传统数据库生态的同时,突破了传统单机硬件的限制,为用户提供大容量、高性能、高弹性的数据库服务。
云原生数据库 PolarDB MySQL 版是阿里云完全自主研发的产品,100%兼容 MySQL。产品具有多主多写、多活容灾、HTAP 等特性,交易性能最高可达开源数据库的6倍,分析性能最高可达开源数据库的400倍,TCO 低于自建数据库50%。
PolarDB MySQL 版 Serverless
Serverless数据库能够使得数据库集群资源随客户业务负载动态弹性扩缩,将客户从复杂的业务资源评估和运维工作中解放出来。此处介绍了Serverless的工作原理、核心优势和适用场景。
数据库是现代企业IT系统中非常重要的一部分。在创建数据库时,客户往往需要比较保守地去配置数据库集群的资源,包括CPU、内存、存储以及连接数等多种参数配置,以确保业务能够在波峰和波谷都能平稳运行。在这种情况下,客户购买的集群资源在业务波谷时期会被闲置,导致整体成本偏高;而在业务压力增长阶段,集群资源又应对不足。Serverless数据库可以很好地解决这个问题。它能够使得数据库集群资源随客户业务负载动态弹性扩缩,将客户从复杂的业务资源评估和运维工作中解放出来。
PolarDB MySQL 版 Serverless的工作原理及优势
工作原理
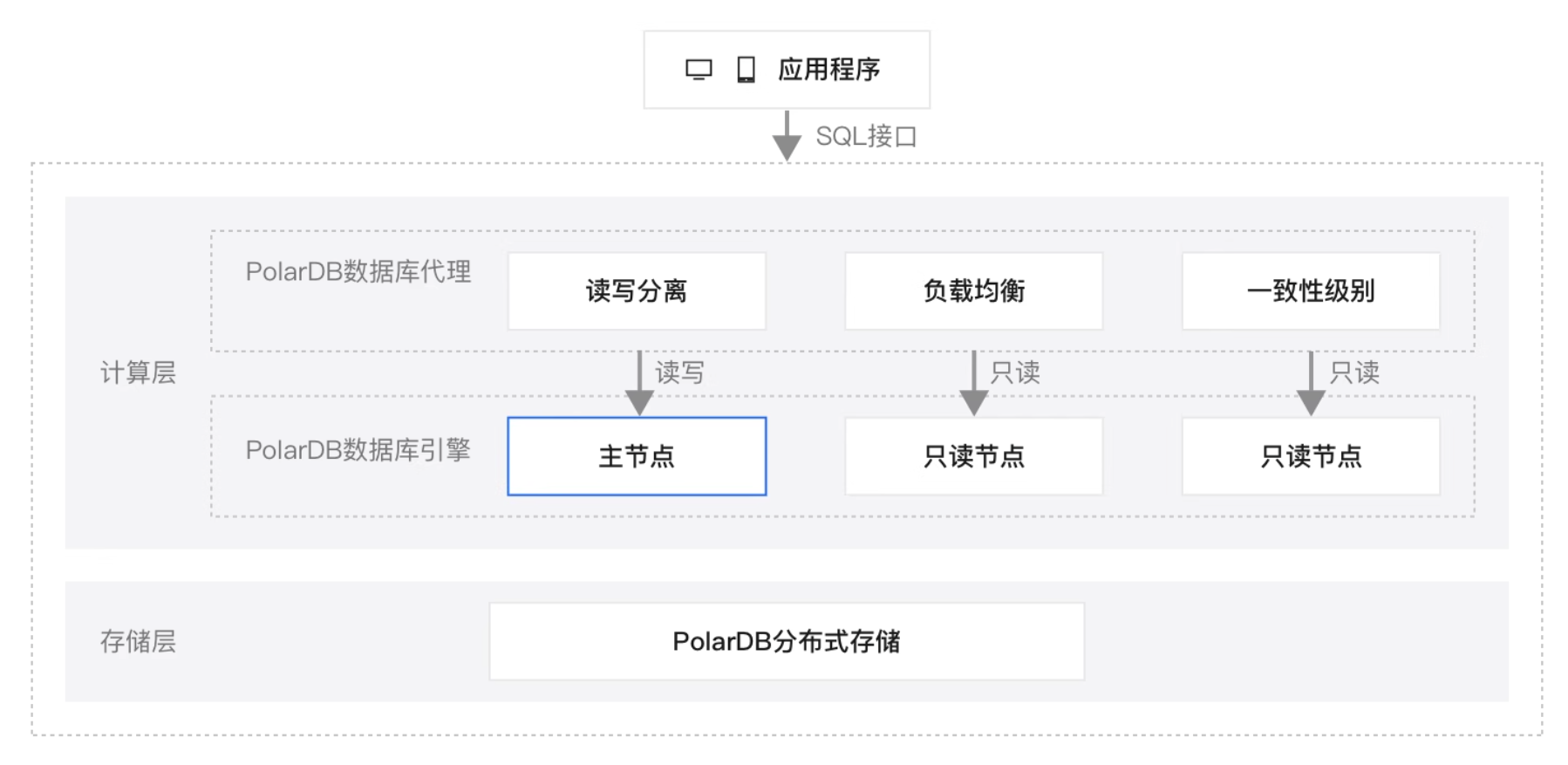
PolarDB MySQL版Serverless提供了CPU、内存、存储、网络资源的实时弹性能力,构建计算与存储分离架构下的PolarDB MySQL版产品新形态。Serverless不仅提供网络资源、命名空间、存储空间的垂直资源隔离能力,还提供计算存储资源按需计费的能力,具有资源用量低、简单易用、弹性灵活和价格低廉等优点,赋能用户面向业务峰谷时对计算、存储能力进行快速且独立的扩缩要求,做到快速响应业务变化的同时,合理优化使用成本,进一步助力企业降本增效。相比弹性扩容,Serverless具有以下优点:
-
打破固定资源付费的模式,做到真正负载与资源动态匹配的按量付费,可节省大量成本。
-
对高吞吐写入场景和高并发业务进行了设计优化,同时提供了弹性扩缩能力,适合业务数据量大、并具有典型的业务访问波峰波谷场景。
-
1秒内即可完成集群资源扩缩,业务完全无感。
Serverless集群

- Serverless集群Proxy
Serverless Proxy为Serverless形态,Proxy资源独立于计算节点弹性扩缩无需用户选择。Serverless Proxy的计量单位是PCU,1个PCU约等于1核2 GB的资源,0.5个PCU约等于0.5核1 GB的资源。
- Serverless集群计算节点扩缩
主节点(RW节点)和只读节点(RO节点)全部为Serverless形态,随业务负载变化而弹性扩缩,并采用单可用区共享分布式存储。
Serverless集群计算节点的计量单位是PCU,1个PCU约等于1核2 GB,0.5个PCU约等于0.5核1 GB的资源。扩缩按照0.5 PCU的增量进行,当前PCU越大,扩缩步长相对越大。
您可以通过PCU指定单节点弹性扩缩的范围,单节点的扩缩范围为1~32 PCU。每当主节点或只读节点扩缩时,节点的PCU会随之增加或减少。系统每秒钟会监测一次计算节点的PCU。
- Serverless集群存储
存储空间采用Serverless方式,购买时无需选择容量,随着数据增长而在线自动扩容,只按实际数据量所占的存储空间大小收费。
核心优势
PolarDB MySQL版Serverless能够根据业务负载,对集群资源进行秒级动态弹降。其核心优势体现在如下几个方面:
-
高可用:多节点的架构保障了Serverless集群的高可用,服务等级协议SLA与普通集群相同,共同保证了Serverless集群的稳定运行。
-
高弹性
-
扩缩范围广:Serverless业内自动扩缩范围最广的云数据库,支持自动横向扩展,单集群支持0~1000核范围内的无感扩缩。
-
秒级扩缩:从容应对业务负载突增,5秒完成探测,1秒完成扩展;同时在业务负载下降时,集群资源阶梯性自动释放。
-
业务无感:扩缩过程业务无影响。
-
数据强一致:支持高性能模式的全局一致性,在集群内实现数据强一致,数据写入后在只读节点上立即可读,性能与弱一致性基本一致。
-
低成本:以计算能力(PCU)定价,真正做到按量付费,帮助客户节省成本。成本下降最高可达80%。
-
免运维:扩缩版本升级、系统部署、扩缩容、报警处理等所有运维工作由阿里云专业团队完成,用户无感知,业务无影响,服务持续可用,真正免运维。
如在业务波动较大的场景下,普通集群和Serverless集群资源使用和规格变化情况如下图:

由上图可以看到,在业务波动较大的场景下:
-
普通集群:在波谷期浪费的资源较多,在高峰期资源不足,业务受损。
-
Serverless集群:
-
由于其规格随业务需求量随时调整,总体浪费的资源很少,提升了资源利用率,降低了资源使用量。
-
在高峰期也能完全满足业务需求,保证业务不受损,提高了系统的稳定性。
-
打破固定资源付费模式,真正做到了负载与资源动态匹配的按量付费模式,可节省大量成本。
-
无需手动变配,提高了运维效率,提升了运维管理人员和研发人员的幸福感。
-
支持自动启停能力。当没有连接时,集群自动暂停,释放计算成本;当请求到来时,集群自动无感启动。
-
对高吞吐写入场景和高并发业务场景进行了设计优化,同时提供了弹性扩缩能力,适合业务数据量大、并具有典型的业务访问波峰波谷场景。
Serverless集群的适用场景
-
开发、测试环境等低频数据库使用场景。
-
中小企业建站服务等SaaS应用场景。
-
个人开发者用户。
-
学校教学、学生实验等教育场景。
-
物联网(IoT)、边缘计算等不确定负载场景。
-
业务有波动或不可预测的用户。
体验极致弹性的PolarDB Serverless确保数据业务持续在线实践
在此实验中,PolarDB for MySQL Serverless实例默认开启严格强一致性集群SCC(Strict Consistency Cluster)服务。SCC功能为PolarDB for MySQL Serverless提供了跨节点无损读扩展的能力。PolarTrans事务系统利用提交时间戳技术CTS和RDMA网络,在内核层面提供集群强一致性读SCC服务,在不损失性能的基础上,保证发往集群任意副本的读请求都可以获得强一致性的结果。
设置Serverless弹性策略
复制下方地址,在Chromium网页浏览器打开新页签,粘贴并访问云数据库PolarDB控制台。
https://polardb.console.aliyun.com/
在集群列表页面,找到您的PolarDB实例,单击实例ID。
在基本信息页面的数据库节点区域中,单击右上角的Serverless配置。
设置Serverless参数如下:

主节点Serverless弹性压测
执行如下命令,初始化相关数据
sysbench /usr/share/sysbench/oltp_read_write.lua
--mysql-host=PolarDB实例的集群私网地址
--mysql-port=3306
--mysql-user=test_user
--mysql-password=Password123
--mysql-db=sbtest
--tables=128
--table-size=1000000
--report-interval=1
--range_selects=1
--db-ps-mode=disable
--rand-type=uniform
--threads=256
--time=12000 prepare
【注释】:
-
sysbench:sysbench是一个多线程的基准测试工具,用于评估系统性能。
-
/usr/share/sysbench/oltp_read_write.lua:这是sysbench提供的一个Lua脚本,用于执行OLTP(联机事务处理)类型的读写测试。
-
–mysql-host:指定PolarDB实例的集群私网地址,表示要连接的MySQL服务器的主机名或IP地址。
-
–mysql-port:指定MySQL服务器的端口号,通常为3306。
-
–mysql-user:指定连接MySQL服务器所使用的用户名。
-
–mysql-db:指定要在MySQL服务器上使用的数据库名称。
-
–tables:指定在测试期间创建的表的数量。
-
–table-size:指定每个表的行数。
-
–report-interval:指定报告输出的时间间隔(以秒为单位)。
-
–range_selects:指定是否进行范围查询操作。
-
–db-ps-mode:指定数据库预处理状态,此处为禁用。
-
–rand-type:指定生成随机数的方式,这里使用均匀分布。
-
–threads:指定并发线程数,即同时执行的任务数量。
-
–time:指定测试运行的总时间(以秒为单位)。
-
prepare:指定执行预备阶段,将在测试之前创建和填充表。
此时可以看到明显的增加。
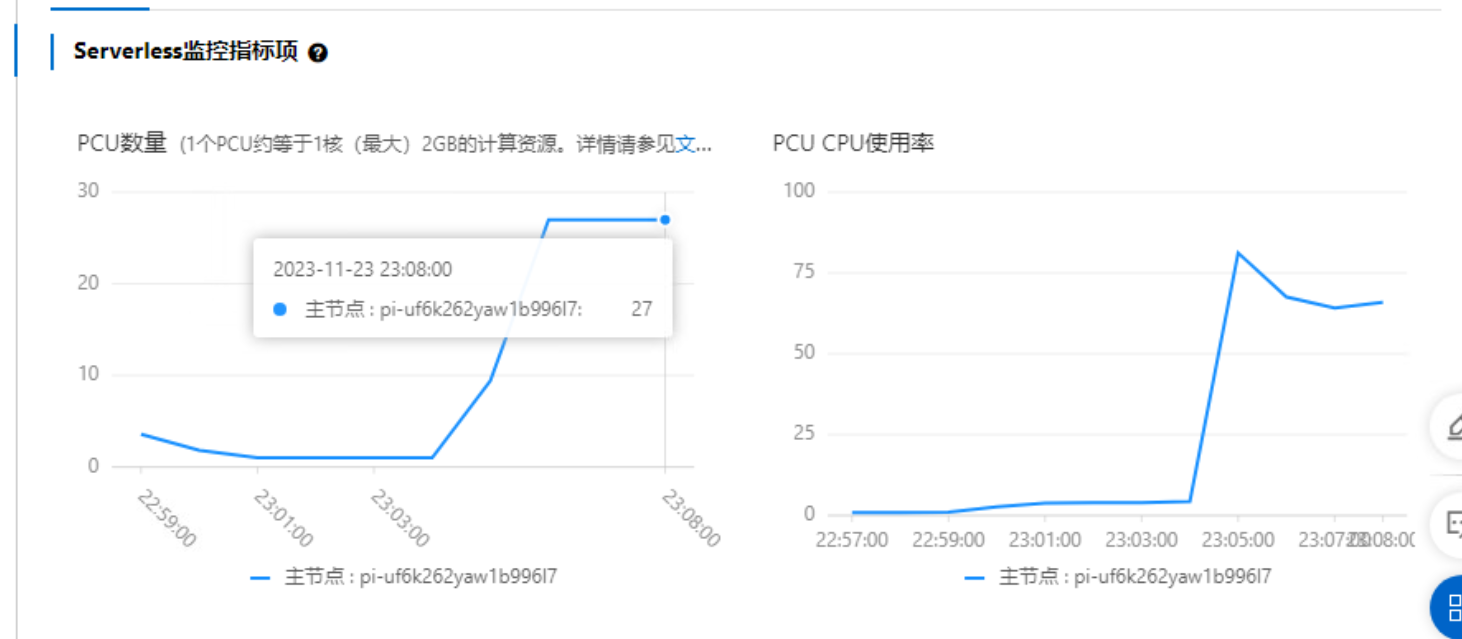
由于初始化数据的负载也会造成Serverless弹升,在执行完毕后等待2-3min,在规格下降到初始状态(1PCU)后,再执行正式的压测命令。
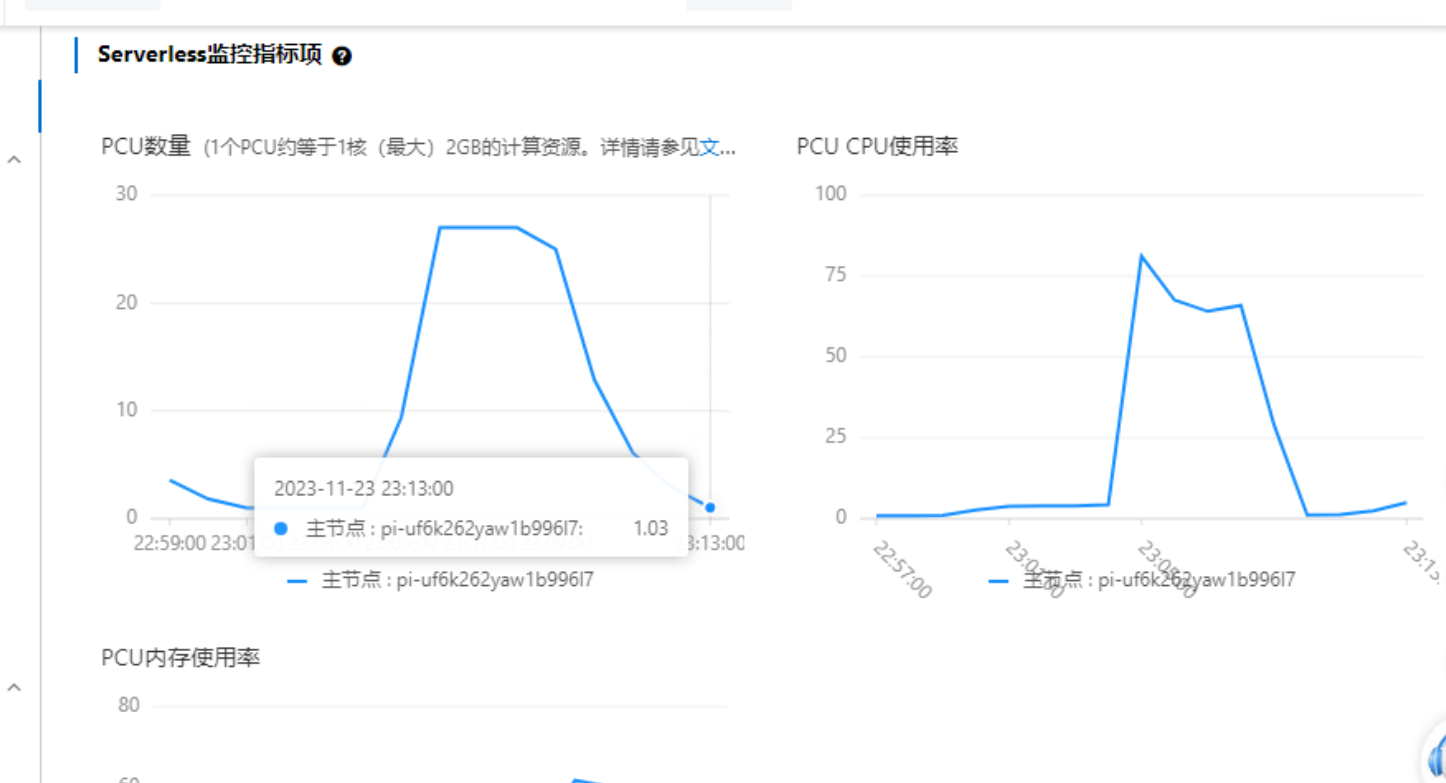
执行如下命令,开始进行256并发读写混合压测。
sysbench /usr/share/sysbench/oltp_read_write.lua
--mysql-host=PolarDB集群私网地址
--mysql-port=3306
--mysql-user=test_user
--mysql-password=Password123
--mysql-db=sbtest
--tables=128
--table-size=1000000
--report-interval=1
--range_selects=1
--db-ps-mode=disable
--rand-type=uniform
--threads=256
--time=12000 run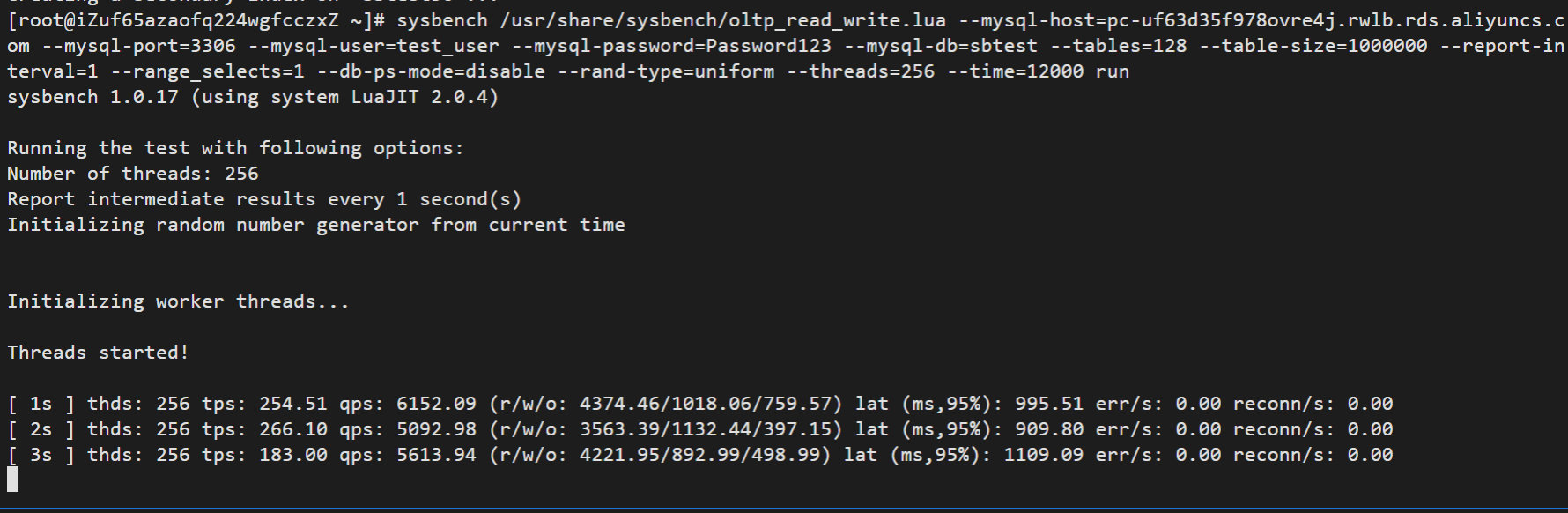
返回如下结果,根据Sysbench输出可以直接观察到,随着时间的推移,在同样的并发数下,tps逐渐上升,延迟(lat)逐渐下降,最终到达一个稳定值,这说明PolarDB的处理能力借助Serverless弹性获得提升。

只读节点Serverless弹性压测
回到刚才的Serverless配置界面。
在设置Serverless配置参数对话框中,将只读节点个数扩展上限从0调整为最大值7,只读节点个数扩展下限保持0不变,单击确定
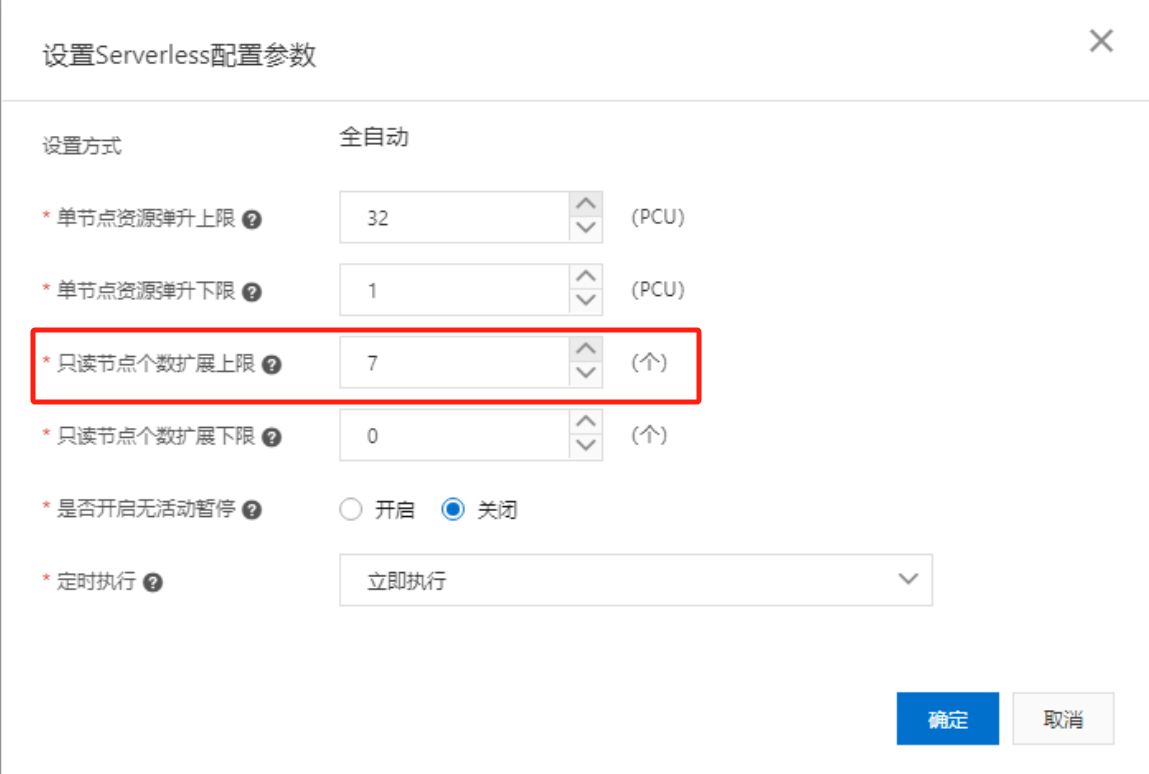
修改完后再执行如下命令,通过访问PolarDB for MySQL Serverless集群私网地址发起256并发读写混合压测请求。
sysbench /usr/share/sysbench/oltp_read_write.lua
--mysql-host=PolarDB集群私网地址
--mysql-port=3306
--mysql-user=test_user
--mysql-password=Password123
--mysql-db=sbtest
--tables=128
--table-size=1000000
--report-interval=1
--range_selects=1
--db-ps-mode=disable
--rand-type=uniform
--threads=256
--time=12000 run
和上一节测试类似,从Sysbench输出可以直接观察到,随着时间的推移,在同样的并发数下,tps逐渐上升,延迟(lat)逐渐下降,最终到达一个稳定值。这说明PolarDB的处理能力借助Serverless弹性获得提升。

初始状态下,在读写混合场景下,读写流量会首先转发到集群唯一节点,即主节点(RW)中。当主节点弹升到最大规格后,Serverless系统会逐个创建只读节点,分摊主节点的读请求,直到只读节点的数量满足当前负载。当只读节点分摊读请求后,主节点负载会降低,触发PCU弹降,为未来支持更多写负载预留了弹升空间。更多具体的信息我们可以从后面的监控中查看。
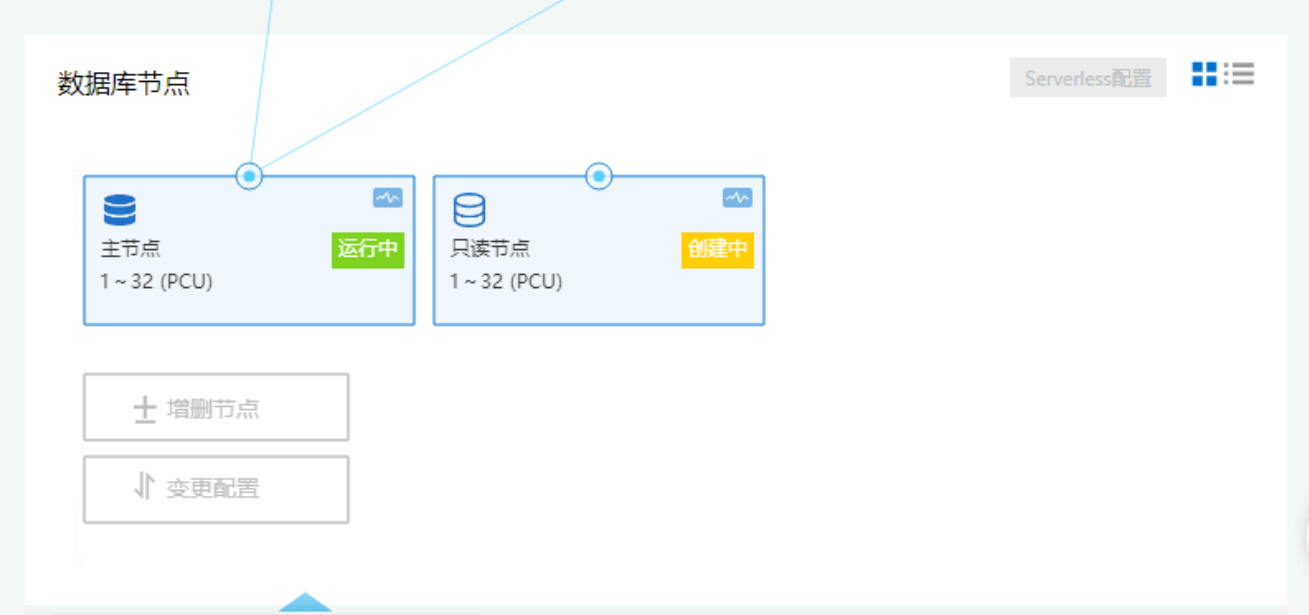
从监控可以看出,PolarDB收到读写混合请求后,主节点会首先迅速弹升到最大的32 PCU,之后监控逐步出现两个只读节点。当只读节点分摊主节点的读请求后,主节点CPU使用率逐步下降,规格最终稳定在22 PCU。
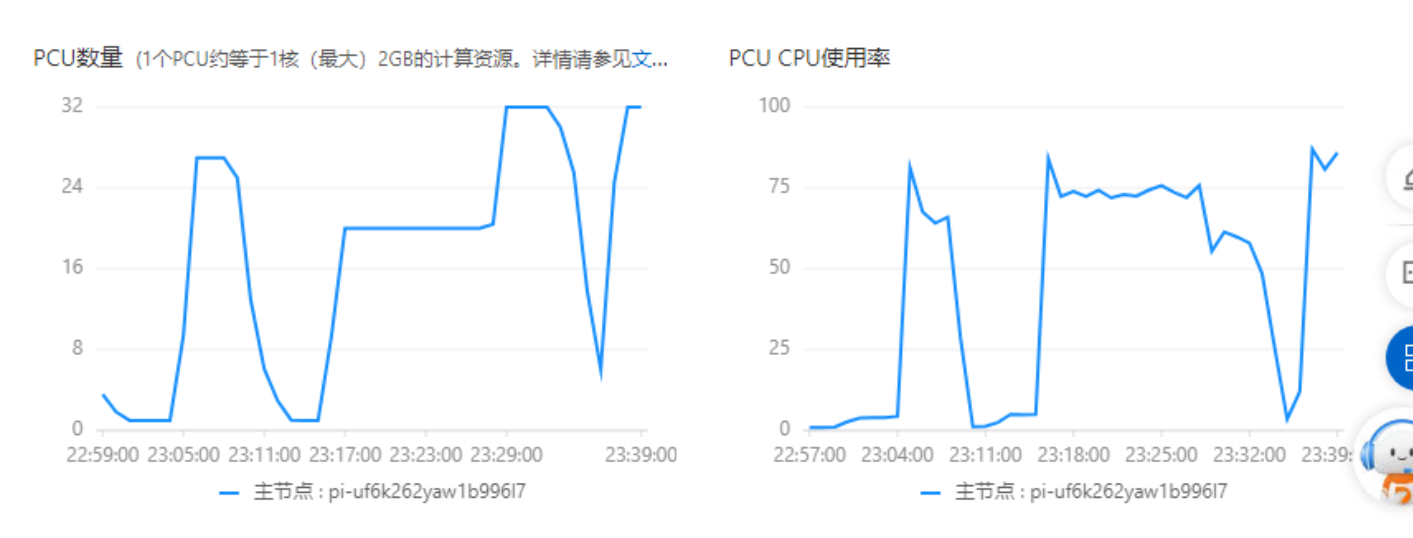
我们可以看到,第一个只读节点创建后,也会立刻弹升到32 PCU。此时系统会尝试继续创建只读节点,分摊读请求。因此当第二个只读节点创建后,第一个只读节点负载降低,规格自动弹降。最终两个只读节点的规格分别稳定在29 PCU和28 PCU(以样例来看,测试的最终数值会略有浮动)。由于目前2个只读节点都没有到最大规格32 PCU,系统判断目前Serverless规格已经满足实际负载,不会再继续增加新的只读节点。
根据该实验之前的配置,PolarDB for MySQL Serverless最多支持扩展出7个只读节点。
只读并发压测
sysbench /usr/share/sysbench/oltp_read_only.lua
--mysql-host=xxx
--mysql-port=3306
--mysql-user=test_user
--mysql-password=Password123
--mysql-db=sbtest
--tables=128
--table-size=1000000
--report-interval=1
--range_selects=1
--db-ps-mode=disable
--rand-type=uniform
--threads=256
--time=12000 run
当数据库接收到新的只读负载后,首先当前的2个只读节点会弹升到最大规格32 PCU,之后Serverless系统会继续创建新的只读节点,直到满足新增只读负载的要求。

自动缩容能力测试
停止压测之后,在监控页上,可以看到PolarDB for MySQL Serverless的计算节点首先会自动缩容,之后新增的只读节点会逐步回收(预计耗时15-20min)。
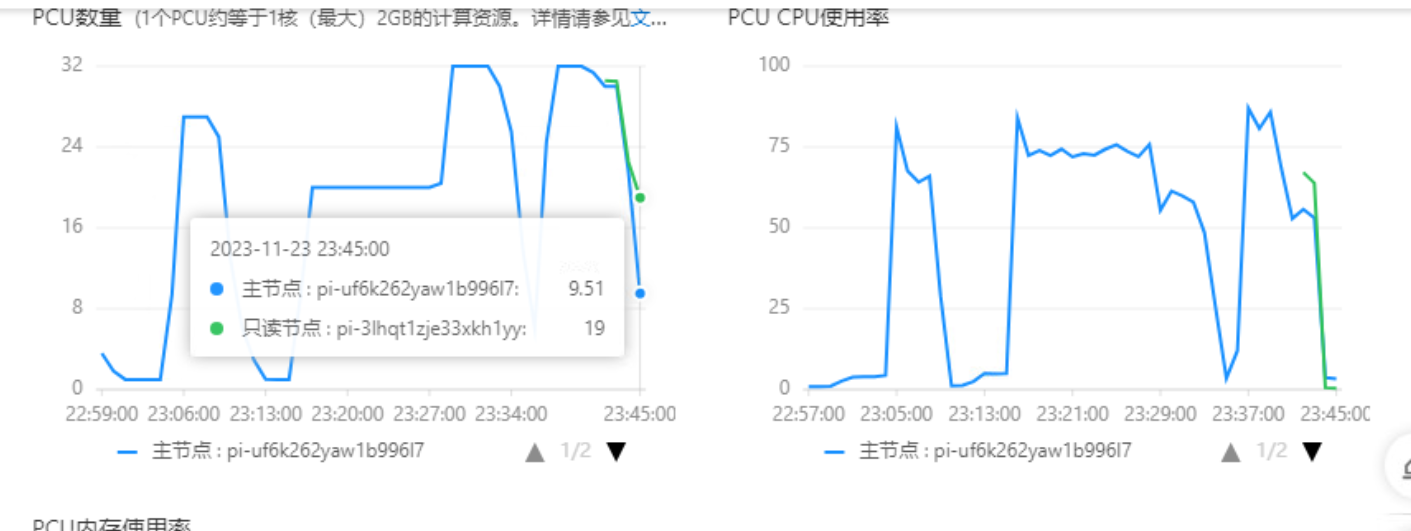
从上面的实验可以看出,PolarDB for MySQL Serverless的节点数量和规格都能够根据负载进行自动伸缩与自动配置。
全局一致性(SCC)测试
高性能全局一致性SCC特性可以为PolarDB for MySQL Serverless提供跨节点无损读扩展的能力,即RO的无损强一致读。传统的Serverless的方案均是基于单机原地升降配实现,其规格受限于单物理机资源。而当RO能借助SCC提供无损强一致读后,针对大部分读多写少业务,我们都可以跨机提供CPU资源,上限远超单物理机限制。
开源的mysqlsct工具用于检验数据库集群的强一致性读能力, 该工具通过跨session的写入+读取+结果对比的方式来测试数据库集群强一致性读的功能和性能。
在设置Serverless配置参数对话框中,将只读节点个数扩展下限从0调整为1,单击确定。
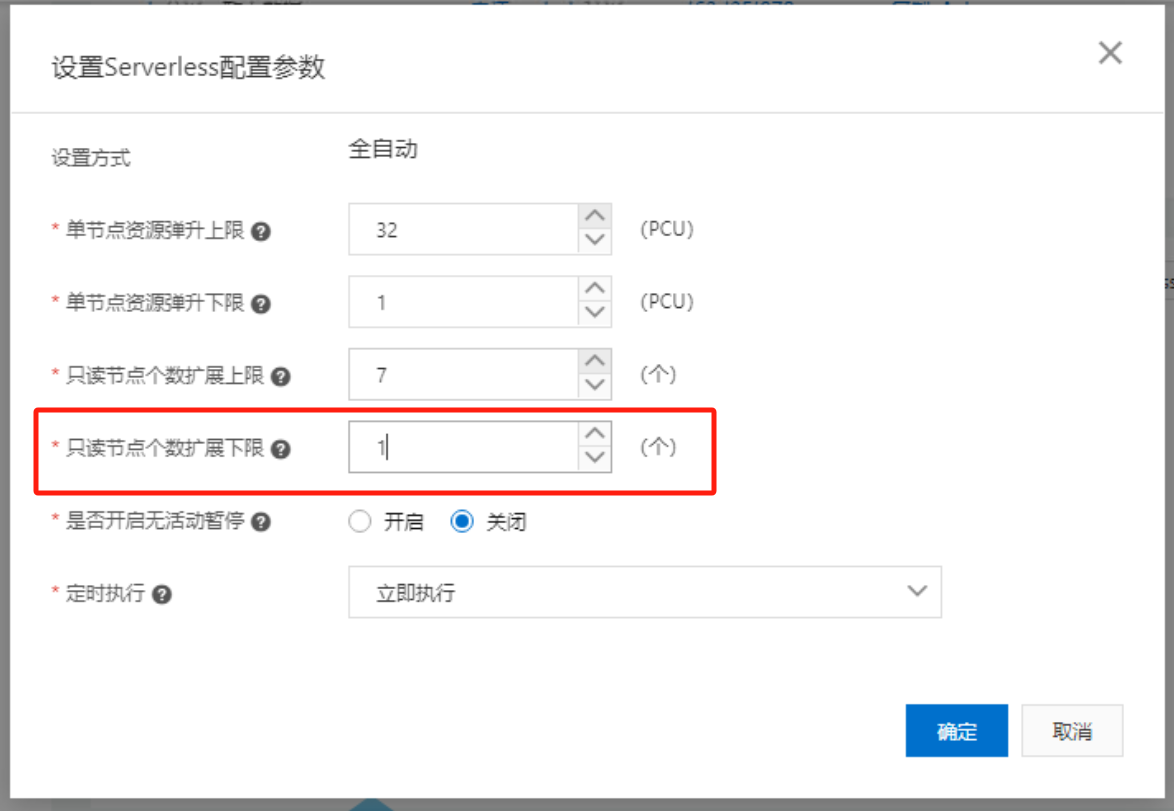
/root/mysqlsct
--host-rw=PolarDB集群私网地址
--host-ro=PolarDB集群私网地址
--port-rw=3306
--port-ro=3306
--user=test_user
--password=Password123
--iterations=100000
--table-cnt=1
--table-size=1000
-f=0
--concurrency=1
--database=sct
--sc-gap-us=0
--report-interval=2
--test-mode=sct
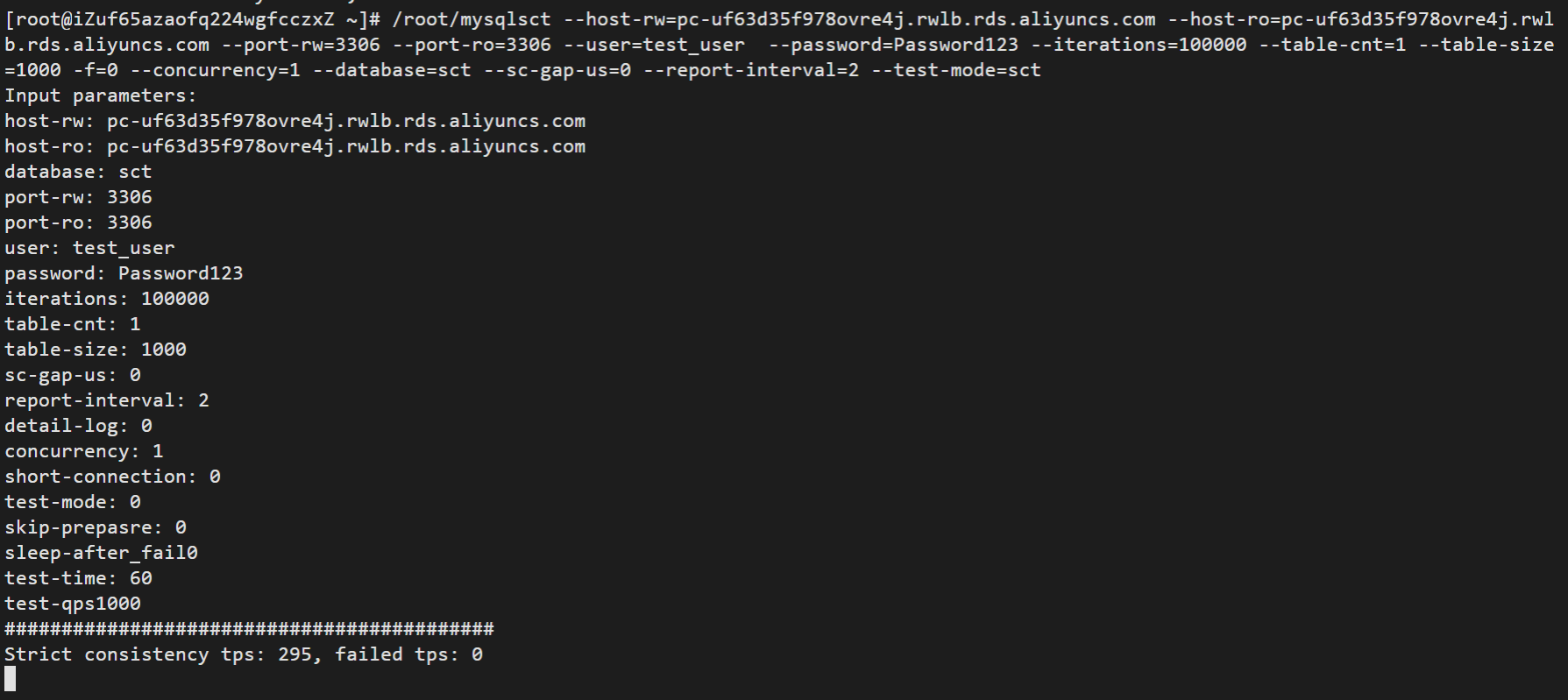
执行后,可以看到一致性检查全部通过,输出的信息类似如下截图:
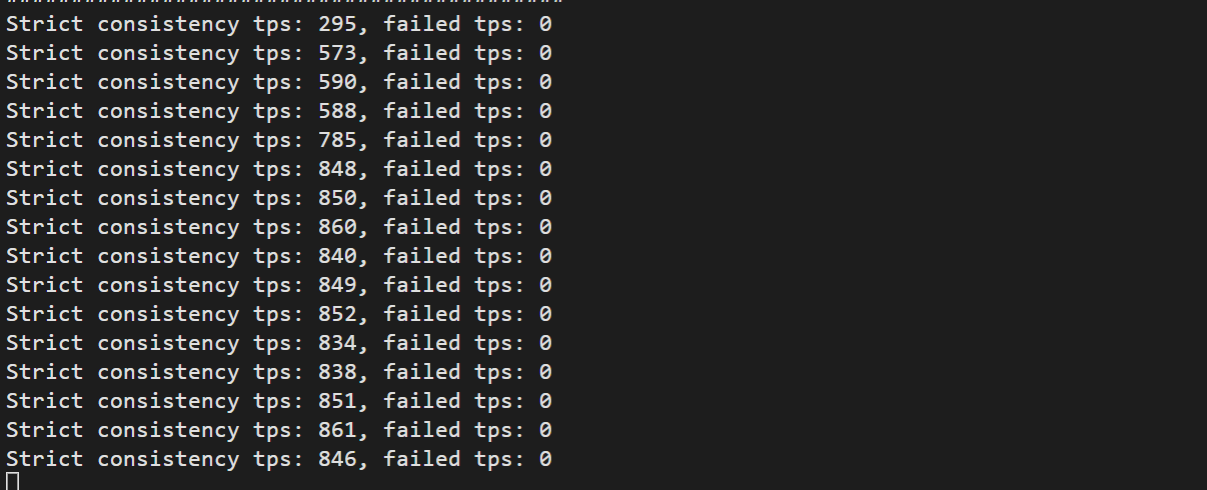
单击页面左上角的修改参数按钮,修改loose_innodb_polar_scc参数为OFF,单击提交修改,单击确定,关闭SCC特性。

重新执行mysqlsct测试命令。
/root/mysqlsct
--host-rw=PolarDB集群私网地址
--host-ro=PolarDB集群私网地址
--port-rw=3306
--port-ro=3306
--user=test_user
--password=Password123
--iterations=100000
--table-cnt=1
--table-size=1000
-f=0
--concurrency=1
--database=sct
--sc-gap-us=0
--report-interval=2
--test-mode=sct
执行后,可以看到一致性检查出现失败。
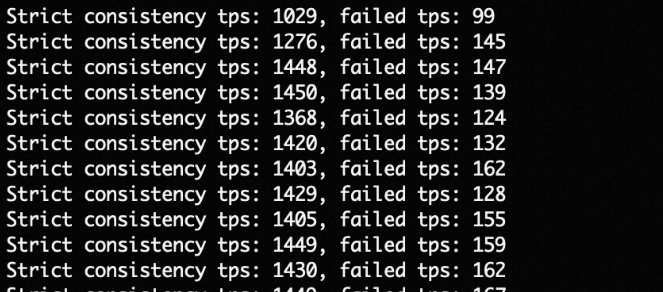
从实验可以看出,PolarDB for MySQL Serverless借助高性能全局一致性SCC特性,提供了跨节点无损读扩展的能力。
使用体验及测评
云原生数据库 PolarDB数据库也是老朋友了,之前也是使用和评测过PostgreSQL版,这次终于也轮到mysql版本了。
对于官方给出的这五点在上述实验中也是可以切身体会到的,其优势是真的一目了然。

这里我也想额外说几点使用PolarDB MySQL版 Serverless的感想:
-
极其灵活:PolarDB MySQL版 Serverless允许根据实际需求自动调整计算资源,避免了手动管理数据库容量和性能的繁琐工作。这种灵活性使得数据库能够适应不断变化的负载需求,为业务运行提供了更大的弹性。
-
成本优化:公司最需要考虑的就是成本,由于Serverless模式下数据库会根据实际负载自动伸缩,因此可以最大程度地避免资源的闲置浪费,从而达到成本优化的效果。对于负载波动较大的业务场景,可以显著降低数据库成本。
-
响应速度:PolarDB MySQL版 Serverless具有快速的资源弹升速度和自动启停功能,在需要时能够快速响应业务负载增加的情况,提供稳定的性能。
PolarDB MySQL版 Serverless确确实实带来了上述好处,不过在使用时我也有一些思考,也算是一些建议吧,这里一并给出:
-
提供更细粒度的资源伸缩选项:目前PolarDB MySQL版 Serverless支持从0核到32核的范围内的纵向扩展,以及从0个到8个节点的范围内的横向扩展。然而,有时候业务需要更小的粒度进行资源调整,因此提供更细粒度的资源伸缩选项将更加灵活和实用。
-
支持更多数据库引擎:目前Serverless版貌似只出了MySQL和PostgreSQL数据库引擎,为了满足不同的应用需求,可以考虑增加对其他数据库引擎的支持,例如SQL Server、Oracle等。
-
改进冷启动性能:PolarDB MySQL版 Serverless在冷启动时可能会有一定的延迟,这对于某些对实时性要求较高的应用可能会产生影响。优化冷启动性能,减少启动时间,将有助于提升用户体验。
-
引入更智能的监控和报警功能:为了帮助用户更好地管理和监控数据库性能,可以考虑引入更智能的监控指标和报警功能,比如结合大模型等采用自然语言来分析判断故障。
时间不早了,这次测评就到此为止吧,也希望PolarDB MySQL 版 Serverless未来可以优化的越来越好!