公众号「架构成长指南」,专注于生产实践、云原生、分布式系统、大数据技术分享
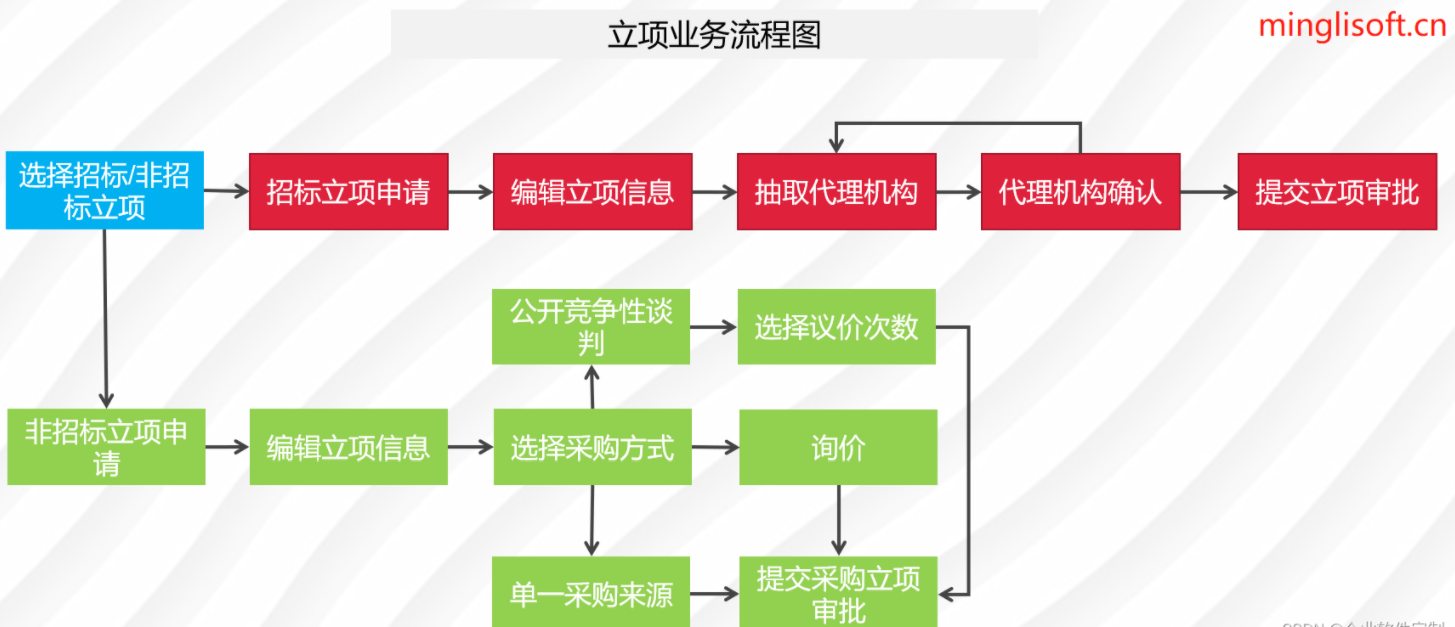
最近一直在搞基于K8S的监控告警平台建设,查找了不少资料,也实验了不少次,目前算是有一定的成果了,分享一下,以下是我们的系统架构

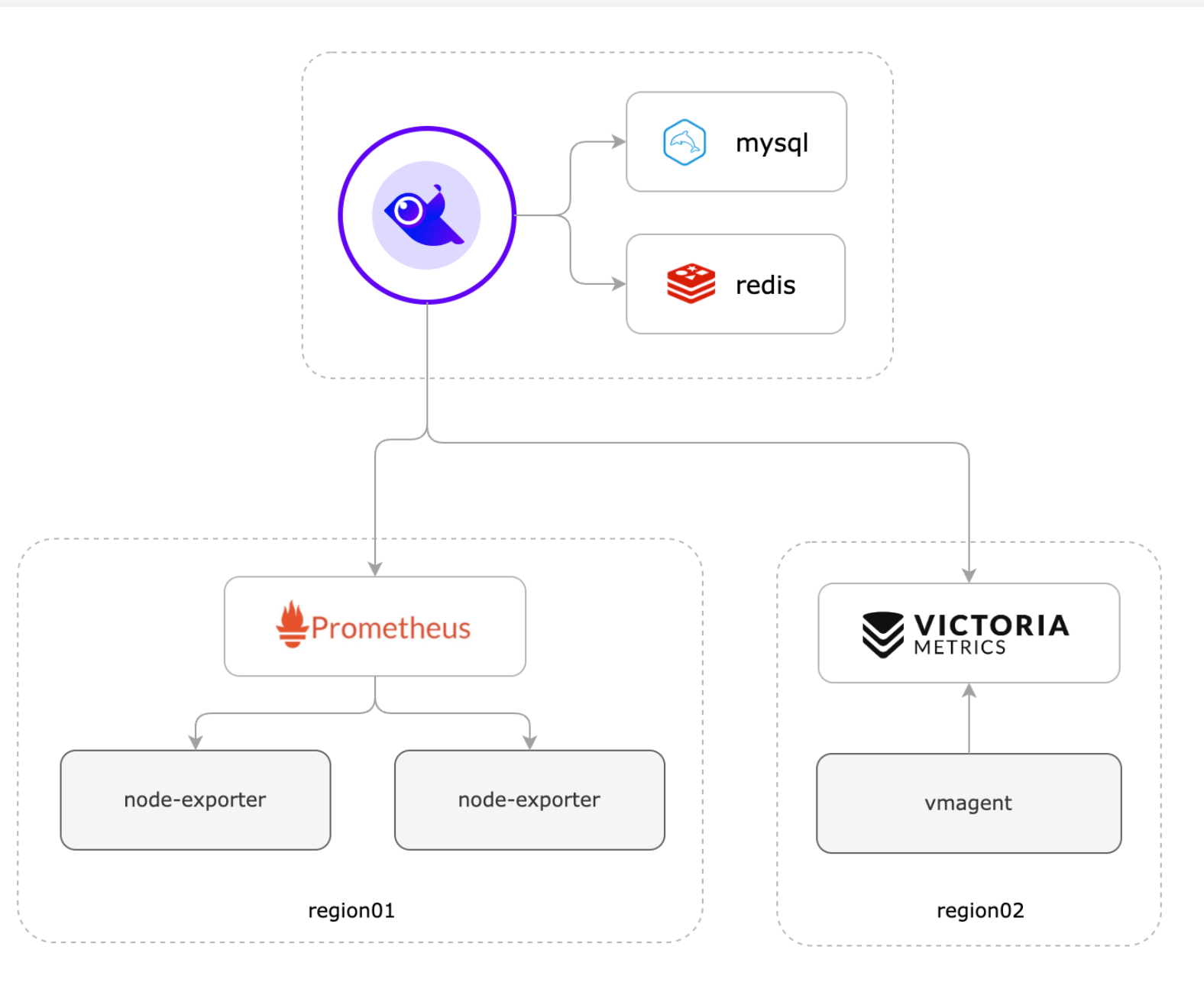
采集端
由于Prometheus的生态过于组件丰富,所以k8s以及Prometheus协议的指标采集这些还是拥抱Prometheus,使用开源的 exporter,虽然现在的exporter 是比较多,但是良莠不齐、有的 Exporter 写的非常棒,有的则并不完善,同时写法各异,每次基础不同的expoter 都要研究一遍配置,心累,所以针对常用的中间件,使用categraf 进行监控,比如 kafka 、Mysql、Redis、Mongo等。
存储端
使用VictoriaMetrics作为的Prometheus长期存储,因为他性能足够强悍,占用资源小,并且完全兼容Prometheus,如果指标小于100w/s,可以采用他的单机版本,并且安装到k8s集群外,这样也避免k8s集群出问题,无从下手
报警配置
由于prometheus的告警配置实在繁琐而且对国内的通讯工具支持度不好,需要第三方实现,所以我们放弃使用 altermanager进行报警,直接采用夜莺进行报警配置,这也是目前业内常用玩法
展现层
由于VictoriaMetrics后兼容 PromQL。我们都可以按照理解的 PromQL 语法来进行查询,所以在 Grafana中配置 Prometheus的数据源时,填入VictoriaMetrics的地址即可
同时这里VictoriaMetrics数据一部分是prometheus 采集的,一部分是categraf,所以针对categraf采集的,需要自行配置报表,因为可能无法与现有 expoter报表兼容,需要微调,不过这种都是一次性的工作

补充
可能有些人有疑问,说VictoriaMetrics兼容Prometheus,可以完全替换掉Prometheus,是的没错,但是我们已经用了Prometheus,目前没有精力去做迁移,等后期有时间逐步过渡到VictoriaMetrics完全替换掉Prometheus