今天,人工智能技术的快速发展和广泛应用已经引起了大众的关注和兴趣,它不仅成为技术发展的核心驱动力,更是推动着社会生活的全方位变革。特别是作为AI重要分支的深度学习,通过不断刷新的表现力已引领并定义了一场科技革命。大型深度学习模型(简称AI大模型)以其强大的表征能力和卓越的性能,在自然语言处理、计算机视觉、推荐系统等领域均取得了突破性的进展。尤其随着AI大模型的广泛应用,无数领域因此受益。
然而,AI大模型的研究和应用是一次复杂且困难的探索。其在训练方法、优化技术、计算资源、数据质量、安全性、伦理性等方面的挑战和难题需要人们去一一应对和破解。以上就是作者编写本书的初衷和目标:希望通过本书能为研究者、工程师、学者、学生等群体提供一份详尽的指南和参考,为读者提供一个理论与实践相结合的全面视角,使他们能够理解并运用AI大模型,同时也希望本书能引领读者探索更多的新问题,从而推动人工智能的持续发展。
AI大模型的训练需要巨大的计算资源和复杂的分布式系统支持。从机器学习到AI大模型的发展历程来看,只有掌握了深度学习的基本概念、经典算法和网络架构,才能更好地理解和应用AI大模型。此外,分布式训练和并行策略在AI大模型训练中起着关键作用,能够有效提升训练效率和模型性能。同时,AI大模型的应用也涉及自然语言处理、计算机视觉等多个领域,为各类读者提供了更广阔的应用空间
一、哪些方法可以提升小目标检测的效果?
-
提高图像分辨率。小目标在边界框中可能只包含几个像素,那么能通过提高图像的分辨率以增加小目标的特征的丰富度。
-
提高模型的输入分辨率。这是一个效果较好的通用方法,但是会带来模型inference速度变慢的问题。
-
平铺图像。

-
数据增强。小目标检测增强包括随机裁剪、随机旋转和镶嵌增强等。
-
自动学习anchor。
-
类别优化。
二、MobileNet系列模型的结构和特点?
MobileNet是一种轻量级的网络结构,主要针对手机等嵌入式设备而设计。MobileNetv1网络结构在VGG的基础上使用depthwise Separable卷积,在保证不损失太大精度的同时,大幅降低模型参数量。
Depthwise separable卷积是由Depthwise卷积和Pointwise卷积构成。
Depthwise卷积(DW)能有效减少参数数量并提升运算速度。但是由于每个特征图只被一个卷积核卷积,因此经过DW输出的特征图只包含输入特征图的全部信息,而且特征之间的信息不能进行交流,导致“信息流通不畅”。Pointwise卷积(PW)实现通道特征信息交流,解决DW卷积导致“信息流通不畅”的问题。
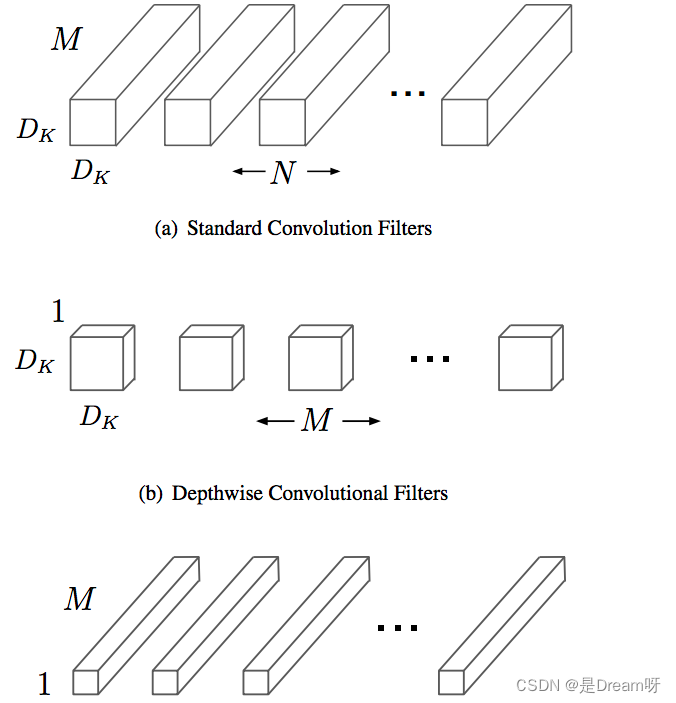
Depthwise Separable卷积和标准卷积的计算量对比:
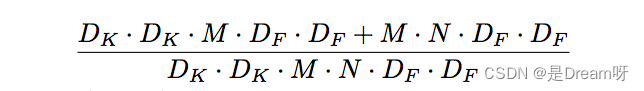
相比标准卷积,Depthwise Separable卷积可以大幅减小计算量。并且随着卷积通道数的增加,效果更加明显。
并且Mobilenetv1使用stride=2的卷积替换池化操作,直接在卷积时利用stride=2完成了下采样,从而节省了卷积后再去用池化操作去进行一次下采样的时间,可以提升运算速度。
MobileNetV2在MobileNetV1的基础上引入了Linear Bottleneck 和 Inverted Residuals。
MobileNetV2使用Linear Bottleneck(线性变换)来代替原本的非线性激活函数,来捕获感兴趣的流形。实验证明,使用Linear Bottleneck可以在小网络中较好地保留有用特征信息。
Inverted Residuals与经典ResNet残差模块的通道间操作正好相反。由于MobileNetV2使用了Linear Bottleneck结构,使其提取的特征维度整体偏低,如果只是使用低维的feature map效果并不会好。如果卷积层都是使用低维的feature map来提取特征的话,那么就没有办法提取到整体的足够多的信息。如果想要提取全面的特征信息的话,我们就需要有高维的feature map来进行补充,从而达到平衡。
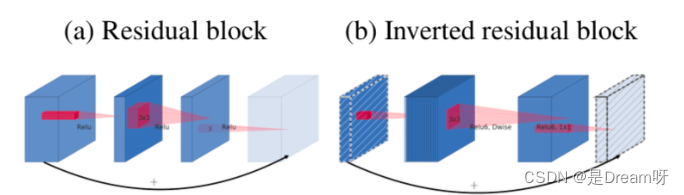
MobileNetV3在整体上有两大创新:
1.互补搜索技术组合:由资源受限的NAS执行模块级搜索;由NetAdapt执行局部搜索,对各个模块确定之后网络层的微调。
2.网络结构改进:进一步减少网络层数,并引入h-swish激活函数。
作者发现swish激活函数能够有效提高网络的精度。然而,swish的计算量太大了。作者提出h-swish(hard version of swish)如下所示:
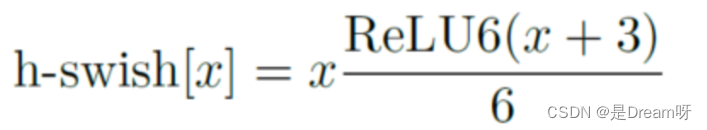
这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。
MobileNetV3模型结构的优化:
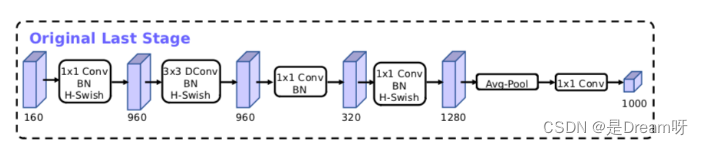
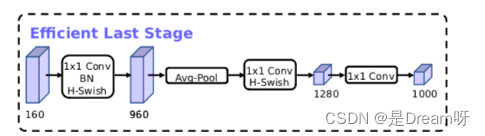
MobileNetV3的论文:《Searching for MobileNetV3》
三、ViT(Vision Transformer)模型的结构和特点?
ViT模型特点:
1.ViT直接将标准的Transformer结构直接用于图像分类,其模型结构中不含CNN。
2.为了满足Transformer输入结构要求,输入端将整个图像拆分成小图像块,然后将这些小图像块的线性嵌入序列输入网络中。在最后的输出端,使用了Class Token形式进行分类预测。
3.Transformer比CNN结构少了一定的平移不变性和局部感知性,在数据量较少的情况下,效果可能不如CNN模型,但是在大规模数据集上预训练过后,再进行迁移学习,可以在特定任务上达到SOTA性能。
ViT的整体模型结构:
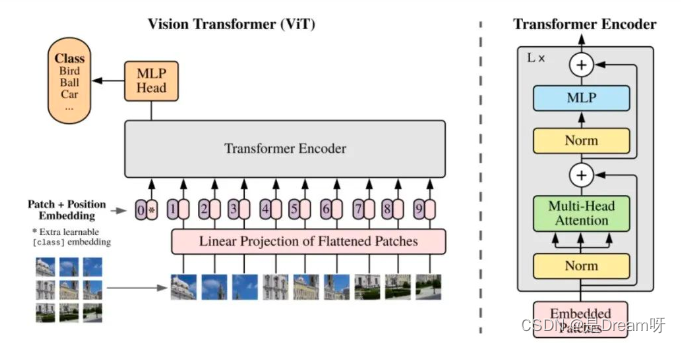
其可以具体分成如下几个部分:
-
图像分块嵌入
-
多头注意力结构
-
多层感知机结构(MLP)
-
使用DropPath,Class Token,Positional Encoding等操作。
四、有哪些经典的轻量型人脸检测模型?
人脸检测相对于通用目标检测来说,算是一个子任务。比起通用目标检测任务动辄检测1000个类别,人脸检测任务主要聚焦于人脸的单类目标检测,使用通用目标检测模型太过奢侈,有点“杀鸡用牛刀”的感觉,并且大量的参数冗余,会影响部署侧的实用性,故针对人脸检测任务,学术界提出了很多轻量型的人脸检测模型,Rocky在这里给大家介绍一些比较有代表性的:
- libfacedetection
- Ultra-Light-Fast-Generic-Face-Detector-1MB
- A-Light-and-Fast-Face-Detector-for-Edge-Devices
- CenterFace
- DBFace
- RetinaFace
- MTCNN
五、LFFD人脸检测模型的结构和特点?
Rocky在实习/校招面试中被多次问到LFFD模型以及面试官想套取LFFD相关算法方案的情况,说明LFFD模型在工业界还是比较有价值的,下面Rocky就带着大家学习一下LFFD模型的知识:
LFFD(A-Light-and-Fast-Face-Detector-for-Edge-Devices)适用于人脸、行人、车辆等单目标检测任务,具有速度快,模型小,效果好的特点。LFFD是Anchor-free的方法,使用感受野替代Anchors,并在主干结构上抽取8路特征图对从小到大的人脸进行检测,检测模块分为类别二分类与边界框回归。
LFFD模型结构
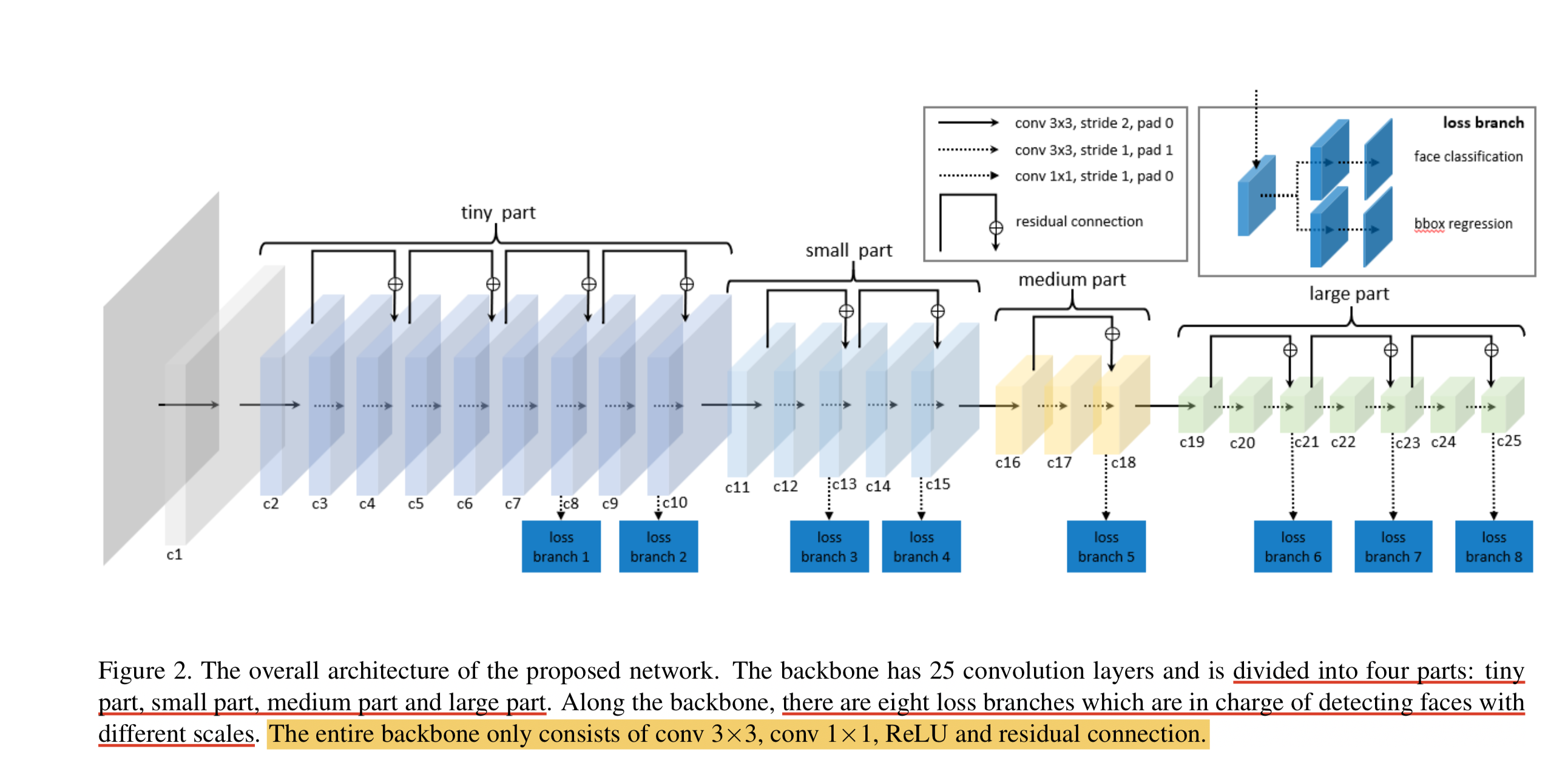
我们可以看到,LFFD模型主要由四部分组成:tiny part、small part、medium part、large part。
模型中并没有采用BN层,因为BN层会减慢17%的推理速度。其主要采用尽可能快的下采样来保持100%的人脸覆盖。
LFFD主要特点:
-
结构简单直接,易于在主流AI端侧设备中进行部署。
-
检测小目标能力突出,在极高分辨率(比如8K或更大)画面,可以检测其间10个像素大小的目标;
LFFD损失函数
LFFD损失函数是由regression loss和classification loss的加权和。
分类损失使用了交叉熵损失。
回归损失使用了L2损失函数。
LFFD论文地址:LFFD: A Light and Fast Face Detector for Edge Devices论文地址
六、GAN的核心思想?
2014年,Ian Goodfellow第一次提出了GAN的概念。Yann LeCun曾经说过:“生成对抗网络及其变种已经成为最近10年以来机器学习领域最为重要的思想之一”。GAN的提出让生成式模型重新站在了深度学习这个浪潮的璀璨舞台上,与判别式模型开始谈笑风生。
GAN由生成器 G G G和判别器 D D D组成。其中,生成器主要负责生成相应的样本数据,输入一般是由高斯分布随机采样得到的噪声 Z Z Z。而判别器的主要职责是区分生成器生成的样本与 g t ( G r o u n d T r u t h ) gt(GroundTruth) gt(GroundTruth)样本,输入一般是 g t gt gt样本与相应的生成样本,我们想要的是对 g t gt gt样本输出的置信度越接近 1 1 1越好,而对生成样本输出的置信度越接近 0 0 0越好。与一般神经网络不同的是,GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的。
在提出GAN的第一篇论文中,生成器被比喻为印假钞票的犯罪分子,判别器则被当作警察。犯罪分子努力让印出的假钞看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。在图像生成任务中也是如此,生成器不断生成尽可能逼真的假图像。判别器则判断图像是 g t gt gt图像,还是生成的图像。二者不断博弈优化,最终生成器生成的图像使得判别器完全无法判别真假。
GAN的对抗思想主要由其目标函数实现。具体公式如下所示:
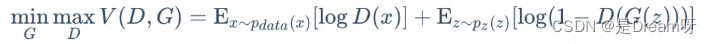
上面这个公式看似复杂,其实不然。跳出细节来看,整个公式的核心逻辑其实就是一个min-max问题,深度学习数学应用的边界扩展到这里,GAN便开始发光了。
接着我们再切入细节。我们可以分两部分开看这个公式,即判别器最小化角度与生成器最大化角度。在判别器角度,我们希望最大化这个目标函数,因为在公示第一部分,其表示 g t gt gt样本 ( x ~ P d a t a ) (x ~Pdata) (x~Pdata)输入判别器后输出的置信度,当然是越接近 1 1 1越好。而公式的第二部分表示生成器输出的生成样本 ( G ( z ) ) (G(z)) (G(z))再输入判别器中进行进行二分类判别,其输出的置信度当然是越接近 0 0 0越好,所以 1 − D ( G ( z ) ) 1 - D(G(z)) 1−D(G(z))越接近 1 1 1越好。
在生成器角度,我们想要最小化判别器目标函数的最大值。判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度,JS散度可以度量分布的相似性,两个分布越接近,JS散度越小(JS散度是在初始GAN论文中被提出,实际应用中会发现有不足的地方,后来的论文陆续提出了很多的新损失函数来进行优化)
- 原始GAN及其训练逻辑
- DCGAN
- CGAN
- WGAN
- LSGAN
- PixPix系列
- CysleGAN
- SRGAN系列
AI大模型推荐
推荐用书:实战AI大模型

实战AI大模型》详细介绍了从基本概念到实践技巧的诸多内容,全方位解读AI大模型,循序渐进、由浅入深。书中配有二维码视频,使读者身临其境,迅速、深入地掌握各种经验和技巧。本书还附带了丰富的额外资源:开源工具和库、数据集和模型案例研究和实际应用、在线交流社区等。读者可以综合利用这些资源,获得更丰富的学习体验,加速自己的学习和成长。
《实战AI大模型》是一本旨在填补人工智能(AI)领域(特别是AI大模型)理论与实践之间鸿沟的实用手册。书中介绍了AI大模型的基础知识和关键技术,如Transformer、BERT、ALBERT、T5、GPT系列、InstructGPT、ChatGPT、GPT 4、PaLM和视觉模型等,并详细解释了这些模型的技术原理、实际应用以及高性能计算(HPC)技术的使用,如并行计算和内存优化。
同时,《实战AI大模型》还提供了实践案例,详细介绍了如何使用Colossal AI训练各种模型。无论是人工智能初学者还是经验丰富的实践者,都能从本书学到实用的知识和技能,从而在迅速发展的AI领域中找到适合自己的方向。
购买链接:https://item.jd.com/14281522.html

为了帮助读者更好地理解和应用AI大模型,本书详细介绍了从基本概念到实践技巧的诸多内容。每章均将重点放在介绍核心概念、关键技术和实战案例上。涵盖了从基本概念到前沿技术的广泛内容,包括神经网络、Transformer模型、BERT模型、GPT系列模型等。书中详细介绍了各个模型的原理、训练方法和应用场景,并探讨了解决AI大模型训练中的挑战和优化方法。此外,书中还讨论了分布式系统、并行策略和内存优化等关键技术,以及计算机视觉和自然语言处理等领域中Transformer模型的应用。总体而言,本书提供了一个全面的视角,帮助读者深入了解AI大模型和分布式训练在深度学习领域的重要性和应用前景。
本书内容安排如下。
第1章介绍了AI大模型的兴起、挑战和训练难点,以及神经网络的发展历程和深度学习框架的入门指南。
第2章介绍了分布式AI系统和大规模分布式训练平台的关键技术,以及梯度累积、梯度剪裁以及大批量优化器的应用。
第3章介绍了数据并行和张量并行在分布式环境下处理大规模数据和张量数据的方法,以及混合并行策略对分布式训练效果的提升。
第4章介绍了Transformer模型的结构和自注意力机制的实现,探讨了自然语言处理中的常见任务和Transformer模型在文本处理中的应用。
第5章介绍了BERT模型的架构和预训练任务,以及利用参数共享和句子顺序预测来优化模型性能和减少内存使用的方法。
第6章介绍了T5模型的架构、预训练方法和关键技术,预训练任务的统一视角以及结合不同预训练范式的混合去噪器的应用。
第7章介绍了GPT系列模型的起源、训练方法和关键技术,以及GPT2和GPT3模型的核心思想、模型性能和效果评估。
第8章介绍了能与互联网和人类交互的ChatGPT和InstructGPT模型,以及ChatGPT模型的应用和GPT4模型的特点与应用。
第9章介绍了稀疏门控混合专家模型和基于MoE的Switch Transformer模型,以及PaLM模型的结构、训练策略和效果评估。
第10章介绍了ViT模型在计算机视觉中的应用和性能,以及图像分类、目标检测和图像生成等任务中Transformer的应用前景。
无论是BERT、GPT,还是PaLM,每种模型都是人工智能技术演进的结晶,背后包含了深厚的理论基础和实践经验。这正是本书选择对每种模型进行单独讨论的原因,以确保对每种模型的深度和广度都有充分覆盖。对于训练这些模型所需的技术,本书也进行了全面介绍:从高性能计算(HPC)到并行处理,从大规模优化方法到内存优化,每一种技术都是精心挑选并进行过深入研究的,它们是AI大模型训练的基石,也是构建高性能AI系统的关键。
然而,掌握理论知识只是理解大模型的起点。AI的实际应用需要解决AI大模型训练的一系列挑战,如计算资源的管理、训练效率的优化等。这就引出了书中特别强调的一部分内容——Colossal AI。
通过使用Colossal AI,本书提供了一系列实战内容,包括如何一步步地训练BERT、GPT 3、PaLM、ViT及会话系统。这些实战内容不仅介绍了模型训练的具体步骤,还深入解析了Colossal AI的关键技术和优势,帮助读者理解如何利用这个强大的工具来提升他们的研究和
工作。最后,本书设计了一系列实战训练,目的是将理论转化为实践。这样的设计也符合编程学习中“实践出真知”的经验,只有真正动手实际操作,才能真正理解和掌握这些复杂的AI大模型背后的原理。
本书面向对深度学习和人工智能领域感兴趣的读者。无论是学生、研究人员还是从业者,都可以从书中获得有价值的知识和见解。对于初学者,本书提供了深度学习和AI大模型的基础概念和算法,帮助他们建立必要的知识框架;对于有一定经验的读者,本书深入探讨了大模型和分布式训练的关键技术和挑战,使他们能够深入了解最新的研究进展和实践应用。
本书提供了丰富的资源,以帮助读者更好地理解和应用所学知识。书中的内容经过了作者的精心编排和整理,具有系统性和连贯性,读者可以从中获得清晰的知识结构和学习路径。同时,书中也提供了大量的代码示例和实践案例,读者可以通过实际操作来巩固所学的概念和
技术。此外,书中还提供了进一步学习的参考文献,帮助读者深入研究感兴趣的主题。除此以外,本书还附带了丰富的额外资源,旨在进一步吸引读者在书籍知识之外继续自己的探索学习。这些资源包括:
开源工具和库:书中介绍了许多常用的开源深度学习工具和库,读者可以获得这些工具的详细说明、用法和示例代码,从而更方便地应用于实际项目中。
数据集和模型下载:书中涵盖了多个领域的数据集和预训练模型,读者可以通过书中提供的链接或附带的访问代码,轻松获取这些资源,节省了大量的数据收集和模型训练时间。
案例研究和实际应用:书中详细介绍了一些成功的深度学习案例和实际应用,包括自然语言处理、计算机视觉、语音识别等领域,读者可以通过这些案例了解主流的技术趋势和行业应用。
在线交流社区:读者可以通过作者提供的ColossalAI在线交流社区与其他读者和专家进行交流和讨论。这个社区提供了问题解答、经验分享和学习资源推荐等功能,为读者提供了一个互动和合作的平台。
这里还要感谢所有对本书创作和出版做出贡献的人和机构。感谢所有为本书做出贡献的人员,他们付出了大量的心血和努力,为本书添加了丰富、详尽的核心知识资源,帮助读者深入了解AI大模型的各个方面。他们分别是(排名不分先后,按照拼音首字母排序):卞正达、曹绮桐、韩佳桐、巩超宇、李永彬、刘勇、柳泓鑫、娄宇轩、路广阳、马千里、申琛惠、许凯、杨天吉、张耿、张懿麒、赵望博、赵轩磊、郑奘巍、郑子安和朱子瑞。
感谢所有提供代码、数据集和模型的研究者和机构,这些宝贵资源使读者能够更好地理解和运用AI大模型技术。此外,还要感谢那些为本书提供反馈和建议的审读人,他们的意见和建议对于书稿的改进和完善起到了重要作用。最后,感谢所有支持和购买本书的读者,这份支持和信任使得这本书能够帮助更多人深入学习和应用AI大模型。
希望本书能够为广大读者提供有价值的知识和资源,推动AI大模型的发展和应用。
由于水平有限,书中不足之处在所难免,欢迎读者批评指正。