文章目录
- 1.RDD双值类型算子
- 1.1 intersection
- 1.2 union
- 1.3 subtract
- 1.4 zip
1.RDD双值类型算子
RDD双Value算子就是对两个RDD进行操作或行动,生成一个新的RDD。
1.1 intersection
对源 RDD 和参数 RDD 求交集后返回一个新的 RDD
函数定义:
def intersection(other: RDD[T]): RDD[T]
//建立与Spark框架的连接val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件val sparkRdd = new SparkContext(rdd) //读取配置文件val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))val data2: RDD[Int] = sparkRdd.makeRDD(List(3, 4, 5, 6))val dataRdd = data1.intersection(data2)dataRdd.collect().foreach(println)sparkRdd.stop(); //关闭连接
运行结果:

1.2 union
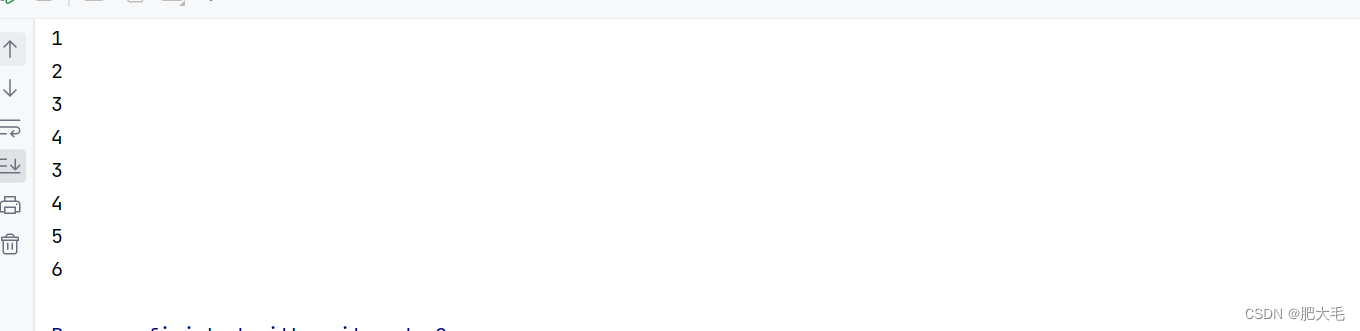
对源 RDD 和参数 RDD 求并集后返回一个新的 RDD
函数定义:
def union(other: RDD[T]): RDD[T]
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))val data2: RDD[Int] = sparkRdd.makeRDD(List(3, 4, 5, 6))val dataRdd = data1.union(data2)dataRdd.collect().foreach(println)
1.3 subtract
以一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来。求差集
函数定义:
def subtract(other: RDD[T]): RDD[T]
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))val data2: RDD[Int] = sparkRdd.makeRDD(List(3, 4, 5, 6))val dataRdd = data1.subtract(data2)dataRdd.collect().foreach(println)

1.4 zip
将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的 Key 为第 1 个 RDD中的元素,Value 为第 2 个 RDD 中的相同位置的元素。
函数定义:
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
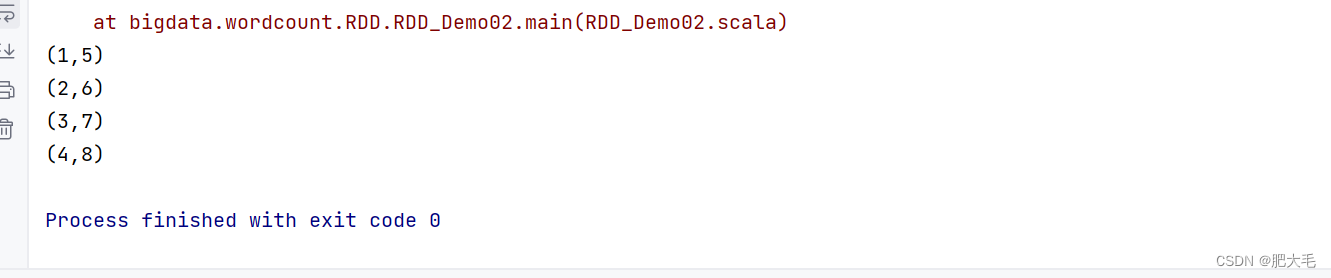
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))val data2: RDD[Int] = sparkRdd.makeRDD(List(5,6,7,8))val dataRdd = data1.zip(data2)dataRdd.collect().foreach(println)
注意:如果两个RDD类型不一样,则会报错
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))val data2: RDD[Int] = sparkRdd.makeRDD(List("hello", "scala", "hello", "Java"))val dataRdd = data1.zip(data2)dataRdd.collect().foreach(println)




![P1067 [NOIP2009 普及组] 多项式输出————C++](https://img-blog.csdnimg.cn/direct/8986bdce9f9746ffa9b500205f0e89b0.png)