大模型的参数量和显存占用估算
现在业界的大语言模型都是基于transformer模型的,模型结构主要有两大类:encoder-decoder(代表模型是T5)和decoder-only,具体的,decoder-only结构又可以分为Causal LM(代表模型是GPT系列)和Prefix LM(代表模型是GLM)。针对decoder-only框架,估算其参数量和显存占用。
参数量约为,其中l指transformer层数,h指隐藏层维度。
训练显存占用约为20*参数量,单位B。20=2+4+2+4+4+4,前两个数字是权重,接着两个是梯度,最后两个是优化器状态大小。每个可训练模型参数都会对应1个梯度,并对应2个优化器状态。在混合精度训练中,会使用float16的模型参数进行前向传递和后向传递,计算得到float16的梯度;在优化器更新模型参数时,会使用float32的优化器状态、float32的梯度、float32的模型参数来更新模型参数。
推理显存占用约为2*参数量,单位B。如果使用KV cache来加速推理过程,KV cache也需要占用显存,约为,b是batch,l是transformer层数,h指隐藏层维度,s是输入序列长度,n是输出序列长度,4=2*2,k和v的cache,每个cache fp16存储,占用2B。
计算量FLOPs约为
计算量和参数量的关系,近似认为,在一次前向传递中,对于每个token,每个模型参数,需要进行2次浮点数运算,即一次乘法法运算和一次加法运算。一次训练迭代包含了前向传递和后向传递,后向传递的计算量是前向传递的2倍。因此,一次训练迭代中,对于每个token,每个模型参数,需要进行6次浮点数运算。
训练时间估计参考下面的公式,8是因为激活重计算技术来减少中间激活显存需要进行一次额外的前向传递,即4*2次浮点数运算。

中间激活的显存占用大小约为,其中b是batch,s是序列长度,a是注意力头数,l是transformer层数,h指隐藏层维度。在训练过程中中,模型参数(或梯度)占用的显存大小只与模型参数量和参数数据类型有关,与输入数据的大小是没有关系的。优化器状态占用的显存大小也是一样,与优化器类型有关,与模型参数量有关,但与输入数据的大小无关。而中间激活值与输入数据的大小(批次大小 和序列长度是成正相关的,随着批次大小和序列长度的增大,中间激活占用的显存会同步增大。
参考资料:分析transformer模型的参数量、计算量、中间激活、KV cache
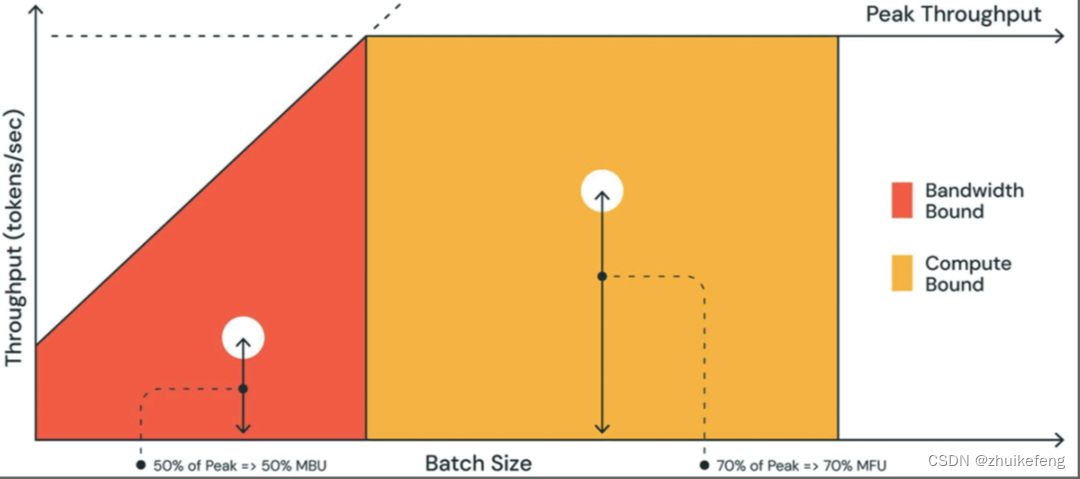
MBU和MFU
MBU(模型带宽利用率) = 实际内存带宽 / 峰值内存带宽,其中实际内存带宽为(模型参数大小+KV缓存大小) / 每token生成时延。如70亿参数的16位精度的模型(大小为14GB),每token时延为14ms,则实际内存带宽为1TB/s,如果峰值内存带宽为2TB/s,则MBU=50%。
MFU(模型FLOPs利用率)是实际计算量/理论算力。
两者的关系见下图。红色区域表示batch很小时主要是带宽瓶颈,橙色区域表示batch很大时主要是计算瓶颈。现实情况下,对于小batch(红色区域白点),观察到的性能低于最大吞吐量,降低程度可通过MBU来度量。对于大batch(黄色区域白点),系统受计算限制,实际所占的吞吐量以MFU衡量。
参考资料:A guide to LLM inference and performance
语言大模型推理性能工程:最佳实践