本篇笔记分享R语言绘制直方图的方法,通过多种展示风格对数据进行可视化,主要用到ggplot、ggpubr等包。
什么是直方图?
直方图(Histogram),又称质量分布图,是一种统计报告图,由一系列高度不等的柱子表示数据分布的情况。

主要展示数据的分布情况,诸如众数、中位数的大致位置、数据是否存在缺口或者异常值。
直方图和柱形图的区别?

-
柱形图横轴表示类别:横轴固定
-
直方图横轴表示组距:横轴可变
-
直方图的表示的数据通常是连续排列,而柱状图则是分开排列,直方图能展示分布趋势。
R语言绘制直方图方法
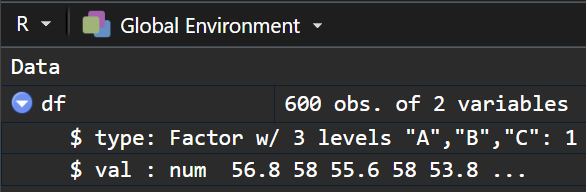
先创建一个随机数据用于绘图,该数据表格的第一列是“type”样品分类信息,包含A、B、C三个种类,第二列是随机数字,一共包含600行,将其看做600个样品的某指标数据。
set.seed(666)
df = data.frame(type = factor(rep(c("A", "B","C"), each=200)),val = c(rnorm(200, 56), rnorm(200, 58),rnorm(200, 52)))
创建的随机数据如下所示,在实际的作图过程中,只需整理成类似这种格式即可。
为了直观的展示测试数据的分布,先做个散点图试试:
ggplot(df)+geom_point(aes(type,val,color=type),position = "jitter")
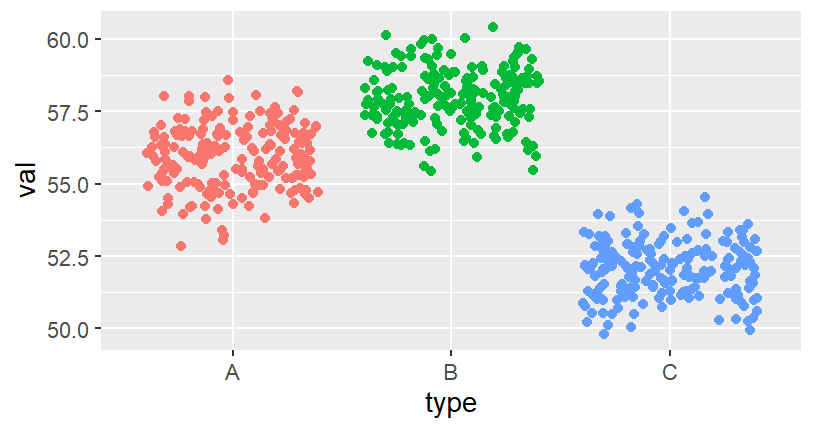
明显可以看出C组的均值52左右最低,B组均值58左右最高,组内整体随机分布。
Base R 基础版直方图
hist(df$val, breaks = 16, #切分多少个条col = "#51cf66",freq = F,xlab = "Value",main = "Hist Plot")
# 添加拟合曲线
lines(density(df$val),col= "#fd7e14",lwd=2)
# 添加下方密度条
rug(jitter(df$val))

这是最基础的直方图,没有展示分组信息,仅对所有的数据统计,可以看出在52和58处有峰值,说明分布频率很高,横轴上有一些条形码一样的黑色竖线,表示样品的分布情况,黑色线越密集,代表此处的值越多。
ggplot2 升级版直方图
library(ggplot2)
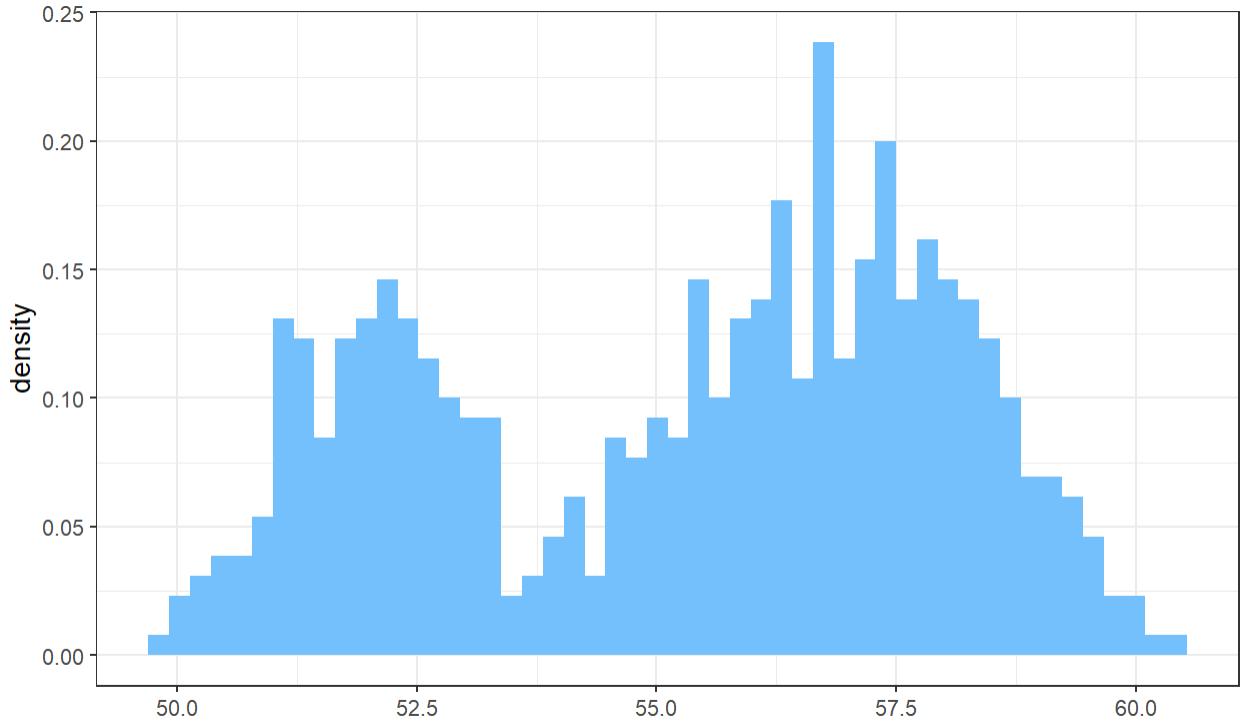
ggplot(df,aes(val,..density..)) +geom_histogram(bins = 50, fill="#74c0fc") +xlab("Insertion Size (bp)") +theme_bw()
通过上述代码,可以用ggplot绘制一张简单的直方图,gfill参数后面可以修改颜色,bins参数可以修改条子的数量。
bins参数很重要,它关系到直方图的形状,以下举个例子,分别画两张直方图,左图p1是bins等于10的时候,组距比较宽。右图p2是bins等于50的情况,组距变窄,同时一些隐藏的细节趋势展示的更加清楚。
p1 <- ggplot(diamonds, aes(carat)) +geom_histogram(aes(carat,fill=cut),bins = 10)+xlim(0,3)+theme_bw()
p2 <- ggplot(diamonds, aes(carat)) +geom_histogram(aes(carat,fill=cut),bins = 50)+xlim(0,3)+theme_bw()
library(patchwork)
p1+p2

由上图可知,不同的分组数量bins影响了信息的传递,在实际过程中若想模糊细节展示整体,则将bins设置的小一些。
多组分面直方图
假如有多个分组或者水平因素,想要看不同分组的直方图,则借助分面功能实现。例如在本文中A、B、C三个分组的直方图,通过下面的代码绘图:
ggplot(df,aes(val,..density..)) +geom_histogram(aes(fill=type),bins = 30,color="#ffffff") +facet_wrap(~type, scales = 'free_x') +xlab("Insertion Size (bp)") +theme_bw()

这样就可以将不同类型分开绘制,观察每个组内样品的指标数据分布趋势,可以发现三个组都是呈正态分布。
ggpubr 尊享版直方图
gghistogram函数提供了一个便捷绘制好看直方图的方法,只需简单的几行代码,就能生成漂亮的直方图。
library(ggpubr)
gghistogram(df, x = "val",fill = "#3bc9db", # 设置填充色add = "mean", # 添加均值线rug = TRUE # 添加轴须线
)
先画一张基础的直方图,fill参数可以修改颜色,add参数可以添加辅助线,比如这里就添加了一条均值竖线,rug是绘制横轴的条形码须线。

但是,上图中把三个组的样品数据混在一起统计,下面将其分开用不同颜色表示:
gghistogram(df,x="val",add="mean",rug = TRUE,color = "type",fill = "type",palette = c("#0fb9b1","#f7b731","#8854d0"),bins = 50,add_density = FALSE,xlab = "公众号:生信分析笔记")
如果想在图中对直方图添加拟合曲线展示密度信息,只需将add_density改为TURE即可。

堆叠形式直方图
接下来,再分享两种堆叠形式的直方图,用途是比较不同分组的数据。首先重新修改一下随机生成的测试数据,注意A组的样品数减少到100,B组样品数增加到300,以下是新的数据框:
df = data.frame(type = factor(rep(c("A", "B","C"), each=200)),val = c(rnorm(100, 56), rnorm(300, 58),rnorm(200, 57)))
画一张普通的直方图看看效果:
ggplot(df)+geom_histogram(aes(val,fill=type),bins = 20)+scale_fill_brewer()+theme_bw()

整体趋势比较明显,均值都在57附近,只不过不同组的数据个数不一样,正如所料,整体的趋势都呈正态分布。
再添加亿点点细节:
ggplot(df,aes(val,fill=type))+geom_histogram(bins = 40,color="black",alpha=0.8)+scale_fill_manual(values = c("A"="#a3cd5b","B"="#f7b731","C"="#0fb9b1"),labels=c("A"="Type A","B"="Type B","C"="Type C"))+geom_vline(xintercept = 57,lty="dashed")+theme_bw()+theme(panel.border = element_blank(),panel.grid = element_blank(),axis.line = element_line(),legend.position = c(0.9,0.8),legend.background = element_rect(fill = "transparent"),legend.title = element_blank())

上面这张图展示了不同种类样品的数据分布规律,这种分布是柱形堆叠格式“stack”,现在将其转换成密度曲线图,你能看出下面这张图的区别吗?
ggplot(df,aes(val,fill=type))+geom_density(alpha=0.5,position = "stack")+scale_fill_manual(values = c("#a3cd5b","#f7b731","#0fb9b1"))
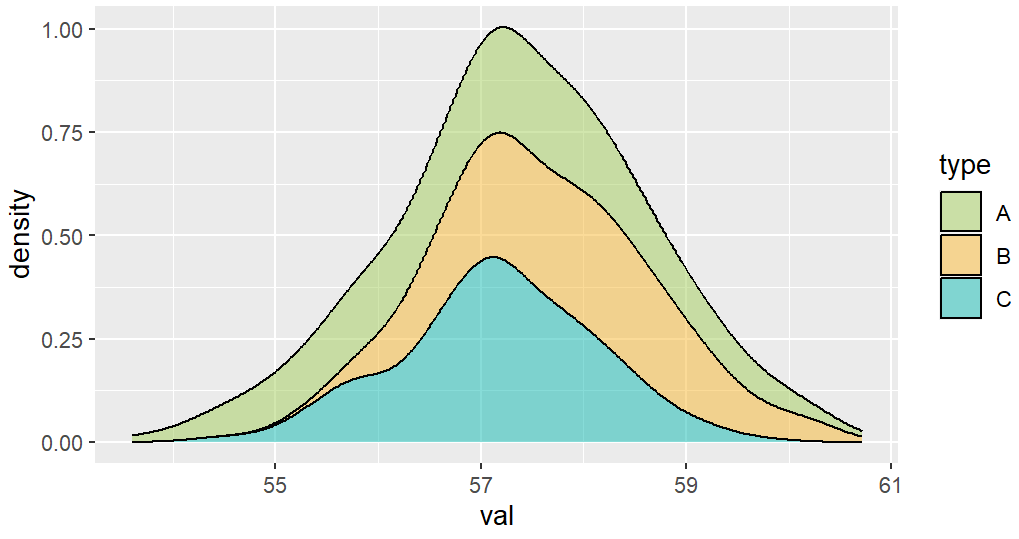
是不是感觉似曾相识,直方图和密度曲线的规律是一样的,因为它们都是用同样的数据做出的图,呈现出相同的变化趋势。
还有一种位置展示方式“identity”,它不会将不同分组的值堆叠累加到一起,而是都从Y等于0为起始位置,只需修改上方代码中的“stack”为“identity”,即可看出效果区别。
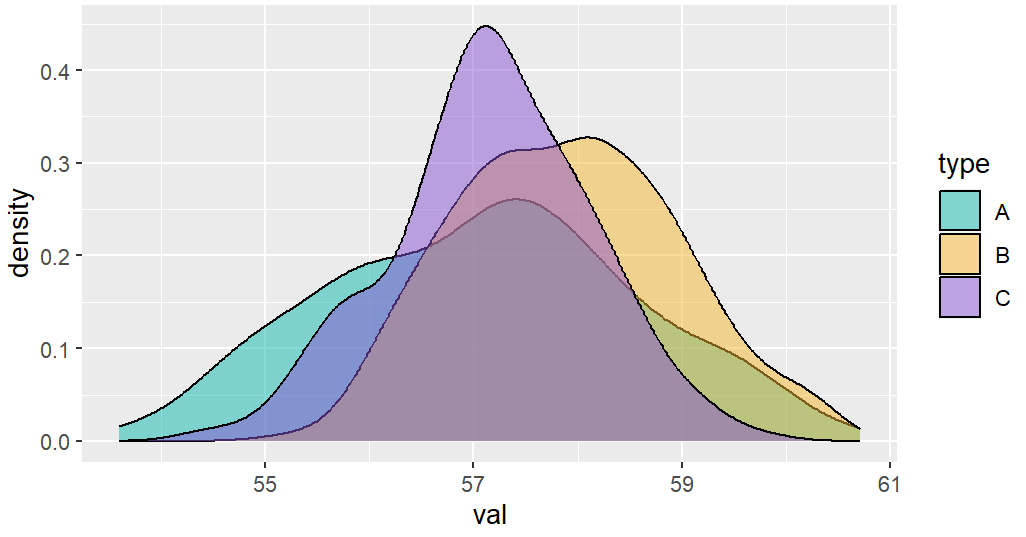
不知道你有没有发现,这个图就是小提琴图的一半,因为这个密度曲线实际上反映了数据的分布,而小提琴图的宽窄也反应数据的分布,因此二者本质一样。
ggplot(df)+geom_violin(aes(x=type,y=val,fill=type))+scale_fill_manual(values = c("#0fb9b1","#f7b731","#8854d0"))+theme_bw()
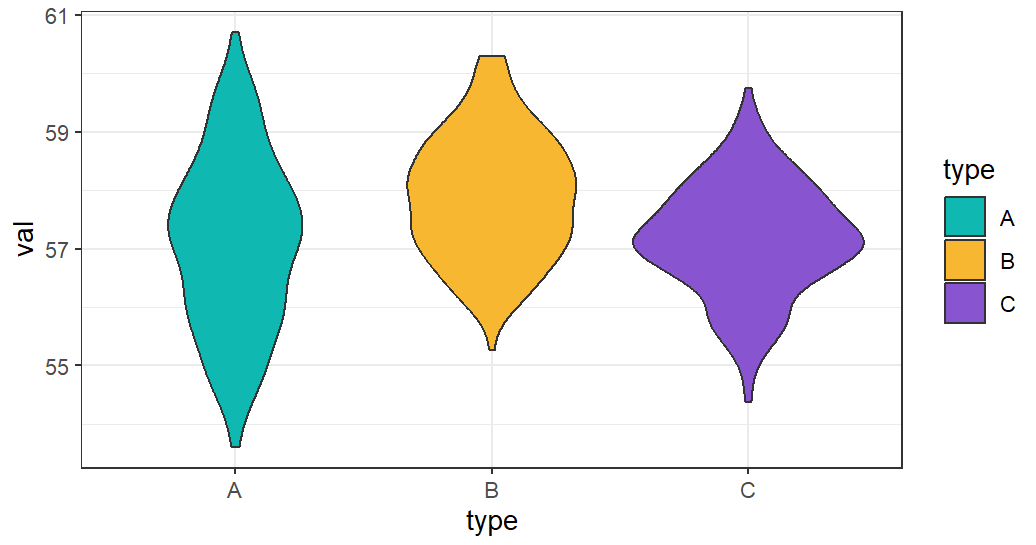
对比一下,就能看出小提琴图、直方图、密度图存在互通之处,比如Type C类型的数据分布比较集中,因此小提琴图中紫色的中间部分凸出明显,而且上面密度曲线的紫色也区域中间也明显凸起。
翻转直方图
有时候还想比较两组之间的分布趋势差异,那么将两个直方图按横轴翻转放置,展示效果更佳。
ggplot(df,aes(val,fill=type))+geom_histogram(data = filter(df,type=="B"),aes(y=..count..),bins = 40,color="#ffffff")+geom_histogram(data = filter(df,type=="C"),aes(y=..count..*(-1)),bins = 40,color="#ffffff")+scale_fill_manual(values = c("#0fb9b1","#8854d0"))+labs(x='Value',y='Frequency')+theme_bw()+theme(legend.position = c(0.1,0.3))
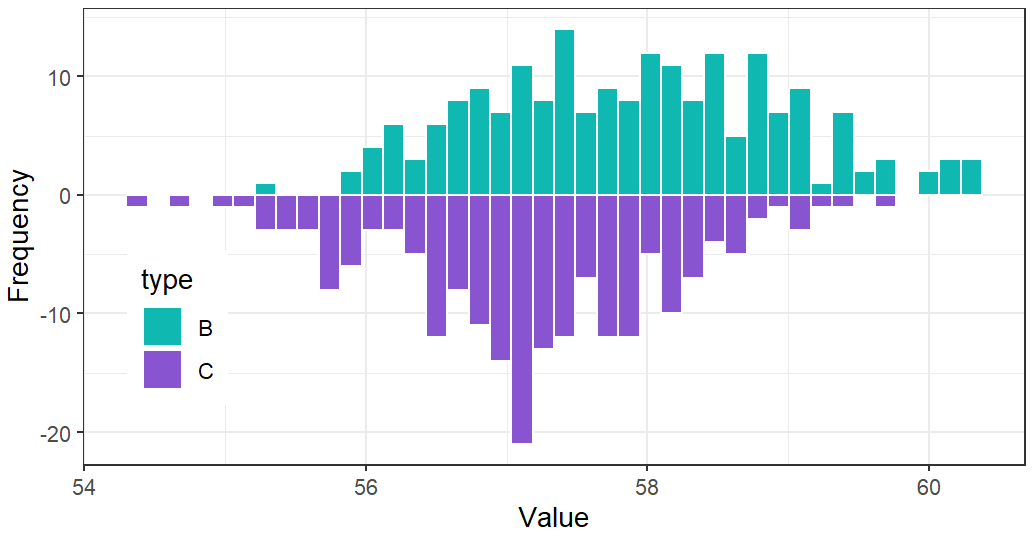
此时可以看出,C组紫色的分布明显更集中一些,该图信息直观明了。本次直方图分享到这里完毕,感谢您的阅读,建议收藏转发,有备无患,万一之后需要用到这个绘图方法,换一下数据就可以。
本文由mdnice多平台发布
![[AutoSar]基础部分 RTE 05 Port的实例化和初始化](https://img-blog.csdnimg.cn/direct/bd03a146e3c74accaf19538dcb1261ef.png)