1、R 语言赋值使用的是左箭头 <- 符号。
2、变量名可以 . 号开头,但是要注意 . 号开头后面不能跟着数字。
3、定义函数:使用 function 关键字,形式:
function_name <- function(arg_1, arg_2, ...) {# 函数体# 执行的代码块return(output)
}
4、数据类型
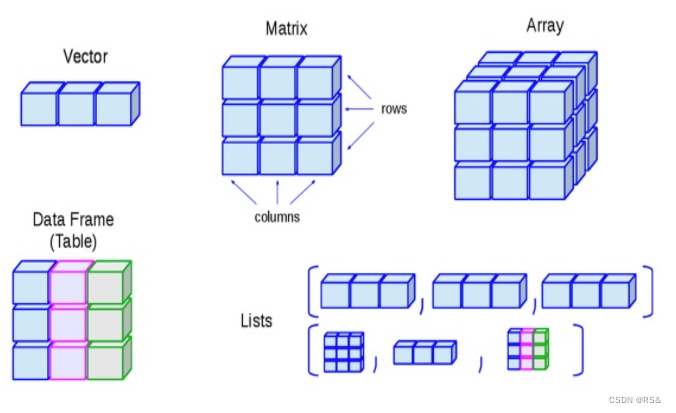
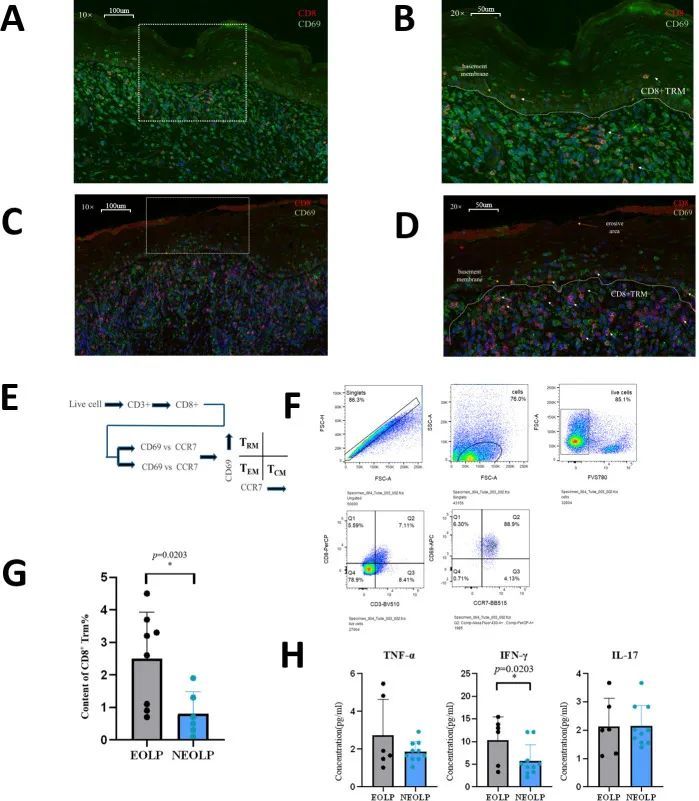
图片来源:https://www.runoob.com/r/r-data-types.html
5、常用函数、包
- c() 是一个创造向量的函数。
- na.omit是一个函数,用于从数据框或向量中删除包含缺失值(NA)的观测行或元素。它返回一个新的数据框或向量,其中不包含任何包含缺失值的行或元素。【na.omit函数会删除包含缺失值的整行,而不是单独删除缺失值】
- as.numeric:用于将数据转换为数值型(numeric)的格式。它可以将字符型、逻辑型、因子型等其他数据类型转换为数值型。【当将非数值型的非数字字符转换为数值型时,R会将其转换为NA】
# 将字符型转换为数值型
x <- "123"
y <- as.numeric(x)
print(y) # 输出: 123# 将逻辑型转换为数值型
a <- TRUE
b <- FALSE
c <- as.numeric(a)
d <- as.numeric(b)
print(c) # 输出: 1
print(d) # 输出: 0# 将因子型转换为数值型
f <- factor(c("1", "2", "3"))
g <- as.numeric(f)
print(g) # 输出: 1 2 3- na.rm = TRUE,表示在计算函数操作时要移除缺失值(NA)。"na.rm"是"remove NA"的缩写。当将na.rm参数设置为TRUE时,函数将忽略包含缺失值的数据,并且只对非缺失值进行计算。
- 创建数据库,类似python-dataframe:data.frame(x=x, y=y) 是 R 语言中创建数据框(data frame)的语法。数据框是 R 中最常用的数据结构之一,类似于表格,可以存储不同类型的数据(如数值、字符、逻辑值等)。
x <- c(1, 2, 3, 4, 5)
y <- c("A", "B", "C", "D", "E")df <- data.frame(x = x, y = y)#两列数据,x,y- library(hydroGOF)是一个R语言的包,它提供了一些评估水文模型准确性的函数和工具。
hydroGOF包的作用包括以下几个方面:
模型评估:hydroGOF包提供了一系列函数,用于评估水文模型的准确性。这些函数可以计算模型的各种统计指标,比如均方根误差(RMSE)、平均绝对误差(MAE)、相关系数(R^2)等。通过这些指标,可以评估模型的拟合程度和预测能力。
绘制图表:hydroGOF包还包括了一些函数,用于绘制模型评估相关的图表。比如,可以绘制观测值与模型预测值的散点图,或者绘制观测值与模型残差的散点图。这些图表可以帮助我们更直观地理解模型的准确性和误差分布情况。
重采样:hydroGOF包中的一些函数还提供了重采样的功能,用于评估模型的稳定性和不确定性。通过对观测数据进行重采样,并与模型进行对比,可以得到模型预测的不确定性范围。
- GAM(Generalized Additive Models)模型,翻译为广义加性模型。是一种统计模型,用于建立响应变量与预测变量之间的非线性关系。与传统的线性回归模型不同,GAM允许预测变量与响应变量之间的关系是非线性的,并且可以通过添加平滑函数来描述这种非线性关系。
init_gam <- gam(y~s(x,k=k,bs="cr"))
#在这个语句中,"y"是因变量,"x"是自变量。#"s(x, k=k, bs='cr')"是一个GAM模型中的平滑项(smoothing term)。它使用了一个自变量"x"的样条函数来表示与因变量"y"的关系。在这里,"s"代表平滑项,"x"是要平滑的自变量,"k"是平滑项的度数(可以根据需要进行调整),"bs"参数指定了使用的基函数类型,"cr"表示使用的是样条函数的B样条(cubic regression spline)。#因此,这个语句的意思是用GAM拟合一个因变量"y"与自变量"x"之间的非线性关系,并将结果存储在"init_gam"变量中。
学习资料来源:
R语言菜鸟教程:https://www.runoob.com/r/