一.Pandas简介
1、基本介绍
-
Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
-
Pandas和Spark SQL中很多功能都类似,甚至使用方法都是相同的
-
Pandas适用场景
-
Pandas用于处理单机数据
-
可以在数据ETL、查询分析、报表输出等环节使用
-
2.数据结构
Python中的Pandas的DataFrame数据结构:
DataFrame:表示一个二维表对象,就是表示整个表
字段,列,索引;Series表示一行或者一列

二.Spark SQL函数定义
1.窗口函数
分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])
分析函数大致可以分为以下三类:
1- 聚合函数:sum() count() avg() max() min()
2- row_number() rank() dense_rank() ntile()
3- first_value() last_value() lead() lag()
2.SQL函数分类
SQL函数,主要分为以下三大类:
①UDF函数:用户自定义函数
特点:一对一,输入一个得到一个
例如:split() substr()
②UDAF函数:用户自定义聚合函数
特点:多对一,输入多个得到一个
例如:sum()
③UDTF函数:用户自定义表数据生成函数
特点:一对多,输入一个得到多个
例如:explode()
在SQL中提供的所有的内置函数,都是属于以上三类中某一类函数
思考:有这么多的内置函数,为啥还需要自定义函数呢?
为了扩充函数功能。在实际使用中,并不能保证所有的操作函数都已经提前的内置好了。很多基于业务处理的功能,其实并没有提供对应的函数,提供的函数更多是以公共功能函数。此时需要进行自定义,来扩充新的功能函数
1- SparkSQL原生的时候,Python只能开发UDF函数
2- SparkSQL借助其他第三方组件,Python可以开发UDF,UDAF函数
在Spark SQL中,针对Python语言,对于自定义函数,原生支持的并不是特别好。目前原生仅支持自定义UDF函数,而无法自定义UDAF函数和UDTF函数。
在1.6版本后,Java 和scala语言支持自定义UDAF函数,但Python并不支持。
Spark SQL原生存在的问题:大量的序列化和反序列
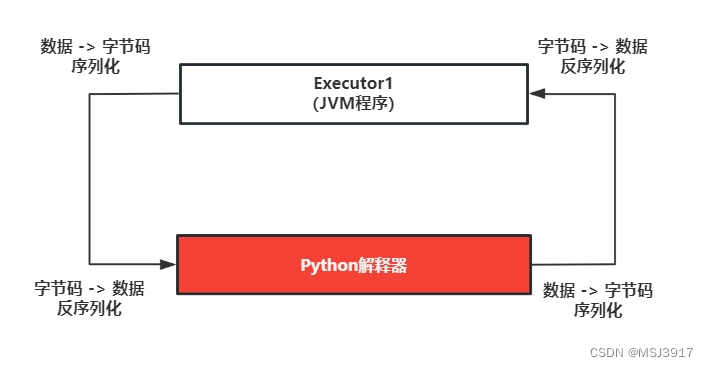
虽然Python支持自定义UDF函数,但是其效率并不是特别的高效。因为在使用的时候,传递一行处理一行,返回一行的方式。这样会带来非常大的序列化的开销的问题,导致原生UDF函数效率不好
早期解决方案: 基于Java/Scala来编写自定义UDF函数,然后基于python调用即可
目前主要的解决方案: 引入Arrow框架,可以基于内存来完成数据传输工作,可以大大的降低了序列化的开销,提供传输的效率,解决原生的问题。同时还可以基于pandas的自定义函数,利用pandas的函数优势完成各种处理操作
3.Spark原生自定义UDF函数
自定义函数流程:
第一步:在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可
第二步:将Python函数注册到Spark SQL中
注册方式一:udf对象 = sparkSession.udf.register(参数1,参数2,参数3)
参数1:[UDF函数名称],此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范
参数2:[自定义的Python函数],表示将哪个Python的函数注册为Spark SQL的函数
参数3:[UDF函数的返回值类型],用于表示当前这个Python的函数返回的类型
udf对象:返回值对象,是一个UDF对象,可以在DSL中使用
说明:如果通过方式一来注册函数,[可以用在SQL和DSL]
注册方式二:udf对象 =F.udf(参数1,参数2)
参数1:Python函数的名称,表示将那个Python的函数注册为Spark SQL的函数
参数2:返回值的类型,用于表示当前这个Python的函数返回的类型
udf对象:返回值对象,是一个UDF对象,可以在DSL中使用.
说明: 如果通过方式二来注册函数,【仅能用在DSL中】
注册方式三: 语法糖写法 @F.udf(returnType=返回值类型) 放置到对应Python的函数上面
说明: 实际是方式二的扩展。如果通过方式三来注册函数,【仅能用在DSL中】
第三步: 在Spark SQL的 DSL/ SQL 中进行使用即可
4.Pandas的UDF函数
4.1 Apache Arrow框架基本介绍
Apache Arrow是Apache旗下的一款顶级的项目。是一个跨平台的在内存中以列式存储的数据层,它的设计目标就是作为一个跨平台的数据层,来加快大数据分析项目的运行效率
Pandas 与 Spark SQL 进行交互的时候,建立在Apache Arrow上,带来低开销 高性能的UDF函数
Arrow并不会自动使用,在某些情况下,需要配置 以及在代码中需要进行小的更改才可以使用
4.2 基于Arrow完成Pandas DataFrame和Spark DataFrame互转
使用场景:
1- Spark的DataFrame -> Pandas的DataFrame:当大数据处理到后期的时候,可能数据量会越来越少,这样可以考虑使用单机版的Pandas来做后续数据的分析
2- Pandas的DataFrame -> Spark的DataFrame:当数据量达到单机无法高效处理的时候,或者需要和其他大数据框架集成的时候,可以转成Spark中的DataFrame
总结:
Pandas的DataFrame -> Spark的DataFrame: spark.createDataFrame(data=pandas_df)
Spark的DataFrame -> Pandas的DataFrame: init_df.toPandas()
4.3 基于Pandas完成UDF函数
基于Pandas的UDF函数来转换为Spark SQL的UDF函数进行使用。底层是基于Arrow框架来完成数据传输,允许向量化(可以充分利用计算机CPU性能)操作。
Pandas的UDF函数其实本质上就是Python的函数,只不过函数的传入数据类型为Pandas的类型
基于Pandas的UDF可以使用自定义UDF函数和自定义UDAF函数
第一步: 在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可
第二步: 将Python函数包装成Spark SQL的函数
注册方式一: udf对象 = spark.udf.register(参数1, 参数2)
参数1: UDF函数名称。此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范
参数2: Python函数的名称。表示将哪个Python的函数注册为Spark SQL的函数
使用: udf对象只能在DSL中使用。参数1指定的名称只能在SQL中使用
注意: 如果编写的是UDAF函数,那么注册方式一需要配合注册方式三,一起使用
注册方式二: udf对象 = F.pandas_udf(参数1, 参数2)
参数1: 自定义的Python函数。表示将哪个Python的函数注册为Spark SQL的函数
参数2: UDF函数的返回值类型。用于表示当前这个Python的函数返回的类型对应到Spark SQL的数据类型
udf对象: 返回值对象,是一个UDF对象。仅能用在DSL中使用
注册方式三: 语法糖写法 @F.pandas_udf(returnType=返回值Spark SQL的数据类型) 放置到对应Python的函数上面
说明: 实际是方式一的扩展。仅能用在DSL中使用
第三步: 在Spark SQL的 DSL/ SQL 中进行使用即可
三.Spark on Hive
1.集成原理
HiveServer2的主要作用: 接收SQL语句,进行语法检查;解析SQL语句;优化;将SQL转变成MapReduce程序,提交到Yarn集群上运行
SparkSQL与Hive集成,实际上是替换掉HiveServer2。是SparkSQL中的HiveServer2替换掉了Hive中的HiveServer2。
集成以后优点如下:
1- 对于SparkSQL来说,可以避免在代码中编写schema信息。直接向MetaStore请求元数据信息
2- 对于SparkSQL来说,多个人可以共用同一套元数据信息,避免每个人对数据理解不同造成代码功能兼容性问题
3- 对于Hive来说,底层执行引擎由之前的MapReduce变成了Spark Core,能够提升运行效率
4- 对于使用者/程序员来说,SparkSQL与Hive集成,对于上层使用者来说,是完全透明的。
2.在代码中集成Hive
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1- 创建SparkSession对象"""spark.sql.warehouse.dir:告诉Spark数据存储在什么地方。默认使用本地磁盘进行存储。推荐使用HDFShive.metastore.uris:告诉Spark元数据信息去什么地方找MetaStoreenableHiveSupport():开启SparkSQL和Hive的集成"""spark = SparkSession.builder\.config("spark.sql.warehouse.dir","hdfs://node1:8020/user/hive/warehouse")\.config("hive.metastore.uris","thrift://node1.itcast.cn:9083")\.appName('sparksql_hive')\.master('local[*]')\.enableHiveSupport()\.getOrCreate()# 2- 数据输入# 3- 数据处理# 4- 数据输出spark.sql("show databases").show()spark.sql("""select *from day07.studentwhere id>=2""").show()# 5- 释放资源spark.stop()总结:
spark.sql.warehouse.dir: 告知Spark,数据表存放的地方。推荐使用HDFS进行存储。如果不配置,默认使用本地磁盘存储。
hive.metastore.uris: 告知Spark,MetaStore元数据管理服务的连接信息
enableHiveSupport() : 开启Spark和Hive的集成