AI 浪潮席卷 CES 2024,英伟达股价创历史新高!二季度量产国内特供 H20 芯片

https://mp.weixin.qq.com/s/3E0xD4VhP0PMSXjPbJPb-A
本周一,NVIDIA 在 CES 开幕前举行的重磅演讲中,重点介绍了生成式 AI 模型及其在创造逼真角色方面的作用,同时推出了一款新的 GPU,专为游戏玩家和内容创作者设计。英伟达股价当天涨 6.43% 收 522.53 美元/股,市值达到 1.29 万亿美元,创历史新高。NVIDIA 还推出了 GeForce RTX 40 SUPER 系列 GPU,包括 RTX 4080 SUPER、RTX 4070 Ti SUPER 和 RTX 4070 SUPER,均具备强大的游戏和生成式 AI 性能。GeForce RTX 4080 SUPER 支持 4K 全景光线追踪游戏,其性能在某些方面超过了 GeForce RTX 3080 Ti。
首个无师自通、泛化使用各种家具家电的具身三维图文大模型系统

https://mp.weixin.qq.com/s/9Zs8bPhcqm4tZV4uITIhAA
只需给它观看示范视频,加上10个小时的训练,Figure-01 就能学会使用咖啡机,放咖啡胶囊到按下启动键,一气呵成。但是想要让机器人无师自通,第一次见到各式各样的家具家电,就能在没有示范视频的情况下熟练使用。这是个难以解决的问题,不仅需要机器人拥有强大的视觉感知、决策规划能力,更需要精确的操纵技能。现在,一个三维具身图文大模型系统为以上难题提供了新思路。该系统将基于三维视觉的精准几何感知模型与擅长规划的二维图文大模型结合了起来,无需样本数据,即可解决与家具家电有关的复杂长程任务。这项研究由斯坦福大学的 Leonidas Guibas 教授、北京大学的王鹤教授团队,与智源人工智能研究院合作完成。
成功率提高四倍,东大、浙师大提出材料合成通用框架,整合 AI、高通量实验和化学先验知识

https://mp.weixin.qq.com/s/MIKoO35L7JAxL3UWNT6UmA
在过去几年中,数据驱动的机器学习 (ML) 技术已成为设计和发现先进材料的强大工具。然而,由于需要考虑前体、实验条件和反应物的可用性,材料合成通常比性质和结构预测复杂得多,并且很少有计算预测能在实验中实现。为了解决这些挑战,来自东南大学和浙江师范大学的研究团队,提出了一个集成高通量实验、化学先验知识以及子群发现(subgroup discovery)和支持向量机等机器学习技术的通用框架来指导材料的实验合成,能够揭示隐藏在高通量实验中的结构-性质关系,并从广阔的化学空间中快速筛选出具有高合成可行性的材料。通过应用所提来解决二维银/铋(AgBi)有机-无机杂化钙钛矿的挑战性和后续合成问题,将合成可行性的成功率相对于传统方法提高了四倍。该研究为利用来自典型实验室、可用实验资源有限的小数据集解决多维化学加速问题提供了一条实用途径。
百川智能发布大模型Baichuan-NPC 只需简单文字描述就能构建游戏角色

https://www.chinastarmarket.cn/detail/1565745
百川智能发布角色大模型Baichuan-NPC,并推出了“角色创建平台+搜索增强知识库”的定制化方案。通过这一方案,游戏厂商不用编写任何代码,只需通过简单的文字描述,便可以快速构建角色,实现角色定制。
Getty 和 NVIDIA 推出旗下iStock 图库平台的 AI 图像生成工具

https://www.maginative.com/article/getty-and-nvidia-launch-generative-ai-by-istock/
Getty lmages 与 NVIDIA 进一步合作为旗下图库平台iStock 推出AI 文本到图像生成功能,售价 14.99 美元.用户可以进行 100 次生成,每次提供四张不同的图像。生成的图片可以用于商业用途,并提供最高 10000 美元的法律版权保护。
对标GPTs但没有创建门槛,应用层的AI Agent玩家终于来了

https://mp.weixin.qq.com/s/alBxn0zVkJazGG2-4BiXUw
2024 开年伊始,大厂便开始卷 AI Agent 了。 过去一年,人工智能行业的风向标不断发生变化,最开始备受关注的是如雨后春笋般涌现的大语言模型及 AIGC 应用,接着又出现很多基于大语言模型打造的 AI 辅助应用(如微软 Copilot)。如今 AI Agent 成为激烈角逐点,是 AIGC 下一阶段的关键。 纵被百般看好,但不难发现 AI Agent 大都是开发者、极客和企业用户在玩,需要一定的专业知识,限制了在应用层面收获大量用户。这就要求厂商在推出 AI Agent 时,考虑如何将创建和使用门槛打下来。如果能在已有产品上直接创建,那当然更好。1 月 9 日,在钉钉 2024 年度产品发布会 - 我的超级助理活动上,用户数量已达 7 亿的国民级办公软件钉钉发布了全新 7.5 版本,并推出有机会对标 GPTs 的智能化产品 ——AI 助理,让每个人、每家企业定制个性化、专属超级助理。
英伟达将与米哈游、腾讯、网易等游戏公司合作AI数字人业务

https://www.chinastarmarket.cn/detail/1565657
在美国CES 2024展会上,英伟达发布了系列新品,其中的NVIDIA ACE 微服务首次亮相,这是一个使用生成式AI制作虚拟数字人的技术平台,目前与ACE的合作者包括米哈游、网易游戏、掌趣科技、腾讯游戏、育碧等企业。
奋战一年,LangChain首个稳定版本终于发布,LangGraph把智能体构建为图
https://mp.weixin.qq.com/s/EOYTMs_ucGdr5P7_lABl_A
不知不觉,LangChain 已经问世一年了。作为一个开源框架,LangChain 提供了构建基于大模型的 AI 应用所需的模块和工具,大大降低了 AI 应用开发的门槛,使得任何人都可以基于 GPT-4 等大模型构建自己的创意应用。在过去的一年中,LangChain 自身也一直在进化。刚刚,LangChain 官方宣布,他们的首个稳定版本 ——LangChain v0.1.0 问世了。
NVIDIA 与 Deepcell 合作,加速生成式 AI 在单细胞研究中的应用

https://mp.weixin.qq.com/s/PUS67TZPf44K13iFUZICuQ
1 月 8 日,AI 驱动的单细胞分析领域的先驱 Deepcell,宣布与 NVIDIA 达成一项研究合作,加速生命科学领域先进计算机视觉解决方案的开发和采用。Deepcell 已经使用 NVIDIA A4000 和 NVIDIA AI 技术,将把 NVIDIA AI 融入其单细胞分析技术中,与 NVIDIA 合作共同开发细胞生物学中生成 AI 和多模式应用的新用途。此次联合合作旨在增进对细胞形态的理解,并最终加速 AI 驱动的细胞分析在细胞生物学和转化研究中的广泛应用,包括癌症、干细胞和细胞治疗。
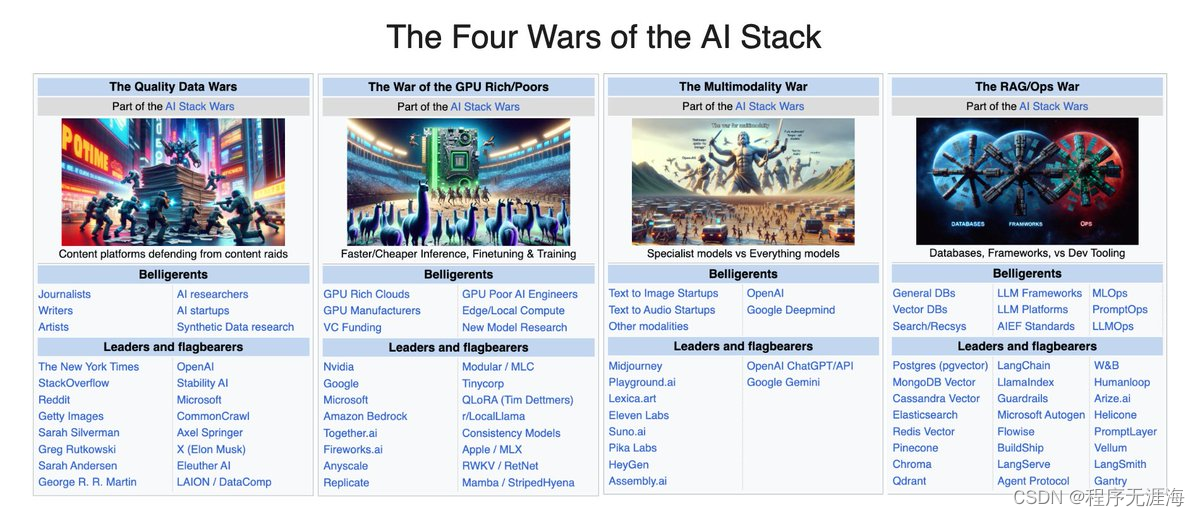
Shawn Wang:AI 栈的四场战争,审视 2023 年所有关键商业战场
https://x.com/swyx/status/1744467383090372743?s=20
🆕《AI 栈的四场战争》
https://latent.space/p/dec-2023
我们 2023 年 12 月的回顾还包括一个框架,用于审视 2023 年所有关键商业战场:
在数据方面:
OpenAI 宣布与 Axel Springer 合作(参见其与 AP 的交易及其数据合作伙伴计划),《纽约时报》就关闭所有 GPT 向 OpenAI 提起诉讼,苹果现在为与出版商的数据合同提供 5000 万美元。与此同时,无论是在 NeurIPS 还是 Deepmind,对合成数据的兴趣无可否认地在上升。
在 GPU/推理方面:
Mixtral 输出令牌每百万个的价格从大约 2 美元迅速降至 0.27 美元(具体细节见下文),@AnyscaleCompute 与其他推理提供商之间的新的基准测试争议。新型模型架构(Mamba、RWKV)的研究,以及将计算从 Nvidia 转移(@Modular、tinycorp、Apple MLX)使现有 GPU 资源发挥更大效用。
在多模态方面:
Midjourney 软启动 v6、一个网络用户界面,并且现在据报每年收入超过 2 亿美元,@AssemblyAI 为“构建 AI 模型的 Stripe”筹集了 5000 万美元 C 轮融资,@Replicate(历史上以稳定扩散为中心)为服务 AI 工程师筹集了 4000 万美元 B 轮融资,@suno_ai_(即将上线的嘉宾!)结束潜伏并重返猴子 - 这些都是稳定的点解决方案改进,而 OpenAI 和谷歌继续开发与所有这些同时竞争的神模型。
在 RAG/Ops 方面:
关于是否需要向量数据库的辩论,以及权力用户采用新的向量数据库(如 turbopuffer);@LangChainAI(现在版本为 0.1,有 TED 演讲和 AI 状态调查)与 @llama_index(现在具有分步代理执行)之间的辩论;以及持续的 LLMOps 开发(@HumanLoop 的新 .prompt 文件,Openlayer)与基于框架的工具(如 LangSmith)和新方法(如 @withmartian(宣布其 900 万美元种子轮融资))的辩论。
吴恩达详细解释前一天发表的对纽约时报诉讼OpenAI案的看法:任何公司未经许可大规模复制他人版权内容是不可接受的,但仍然认为将内容训练和内容大规模呈现用户联系较弱

https://x.com/AndrewYNg/status/1744433663969022090?s=20
我在上一条推文中有些话表达得不够准确,让我详细阐述/澄清一下。
我认为任何公司未经许可或没有可行的合理使用理由,就大规模复制他人版权内容是不可接受的。我应该更明确地说出这一点。
并且…我仍然认为,将某人的内容用于训练 LLM,以及让 LLM 将该内容大规模地呈现给用户之间的联系,比从《纽约时报》的诉讼中所想象的要弱。LLM 可能仅使用预训练的权重(没有 RAG)来重复文本,但我相信这种情况非常罕见,仅在特定的提示下出现(实际上普通用户几乎不会使用)。
当我尝试复制诉讼中看起来“最糟糕”的版权侵犯示例——例如用户尝试使用 ChatGPT 绕过付费墙,或获取 Wirecutter(《纽约时报》的资产)的结果时,我最终触发了 GPT-4 的网络浏览功能。(见附图中的两个示例。)这就是为什么我说我怀疑 RAG 在《纽约时报》诉讼中使用的示例中起了作用。
具体来说,GPT-4 的一个酷炫功能是它可以浏览网络下载额外信息以生成响应。例如,可以提示它进行网络搜索,或有时甚至下载特定文章。尽管 GPT-4 显然愿意下载并几乎逐字显示一篇文章这一点并不好,但值得赞扬的是 OpenAI 似乎已经关闭了这个漏洞。
我相信诉讼中对这些示例的强调让人们认为直接导致这些《纽约时报》文本被重复的是 LLM 对《纽约时报》文本的训练。但如果涉及 RAG,那么这些重复示例的根本原因不是 LLM 接受了《纽约时报》文本的训练——这就是为什么我说我发现诉讼中问题的呈现方式混乱。
同样真实的是,《纽约时报》表明,通过特定方式提示,你可以让 GPT-4 重复《纽约时报》的文本。(我也应该在上一条推文中说这一点。)通常使用的提示似乎涉及提供文章的大部分内容,然后让 LLM 完成它。
尽管 LLM 这样做并不好,但我怀疑几乎没有人会这样使用 LLM。这就是为什么我说,鉴于这种方式产生的文本重复如此罕见,我质疑这实际上对《纽约时报》造成了多大的伤害。我也不确定这是否仅适用于已被转载、在互联网上随处可见的文章(因此该文章在 LLM 训练集中出现了无数次)。此外,看起来 ChatGPT 的新版本已经关闭了这个漏洞。
Niels Rogge分享‘训练和部署开源大型语言模型’演讲录音:在家创建一个 100% 私有的 ChatGPT 的所有步骤
https://x.com/NielsRogge/status/1744351291839521016?s=20
我将我最近关于“训练和部署开源大型语言模型(LLMs)”的演讲录音放到了 @YouTube 上。
内容涉及在家创建一个 100% 私有的 ChatGPT 的所有步骤:监督式微调(SFT)、基于人类偏好的微调,以及使用 vLLM 或 TGI 进行服务。
https://youtube.com/watch?v=Ma4clS-IdhA&ab_channel=NielsRogge
不需要Token的大语言模型可以生成更准确格式的中国古典诗歌

链接:http://arxiv.org/abs/2401.03512v1
微调的大型语言模型(如ChatGPT和Qwen-chat)可以根据人类的指示生成中国古典诗歌。LLM在内容上表现出色,但通常在格式上存在缺陷,每行字符有时过多或不足。由于大多数SOTA LLMs基于token,我们认为格式不准确是由于“token planning”任务的难度,这意味着LLM需要准确知道每个token中包含多少字符,并根据该知识进行长度控制规划。在本文中,我们首先通过展示现有的基于token的大型语言模型在token-character关系上的有限知识来确认我们的假设。我们使用一个拼写测试探索程序,并发现Qwen-chat在近15%的中文拼写测试中失败。然后,我们展示了如何将基于token的模型轻松改造为不需要token的模型(针对中文),从而可以在很大程度上解决格式准确性问题。我们的改造过程从词汇表中删除了长token,只保留了字符级或字节级的token。作为我们的贡献的一部分,我们发布了基于Qwen-chat-7B的经过token-free调整的模型,它可以生成类似LLMs(如故事改写)的复杂指令的中国古典诗歌,并且在格式方面表现出色。在测试集上,我们的token-free模型的格式准确性达到了0.96,而基于token的模型仅为0.84,GPT-4仅为0.38。
CRUXEval:代码推理、理解和执行的基准测试

链接:http://arxiv.org/abs/2401.03065v1
我们介绍了CRUXEval(Code Reasoning, Understanding, and eXecution Evaluation),这是一个包含800个Python函数(3-13行代码)的基准。每个函数都带有一个输入输出对,导致两个自然的任务:输入预测和输出预测。首先,我们提出了一个通用的方法来生成我们的执行基准,可以用来创建未来的变体。其次,我们对我们的基准评估了二十个代码模型,并发现在HumanEval上得分较高的许多最近模型在我们的基准上没有显示出同样的改进。第三,我们表明简单的CoT和微调方案可以提高我们的基准性能,但离解决问题还有很大差距。最佳设置,GPT-4和CoT一起使用,分别在输入预测和输出预测上达到了75%和81%的通过率。相比之下,Code Llama 34B在输入预测和输出预测上的通过率分别为50%和46%,突出了开源模型和闭源模型之间的差距。由于没有任何模型接近CRUXEval的高分,我们提供了关于GPT-4在简单程序上一致失败的示例,以便观察其代码推理能力和改进的方向。
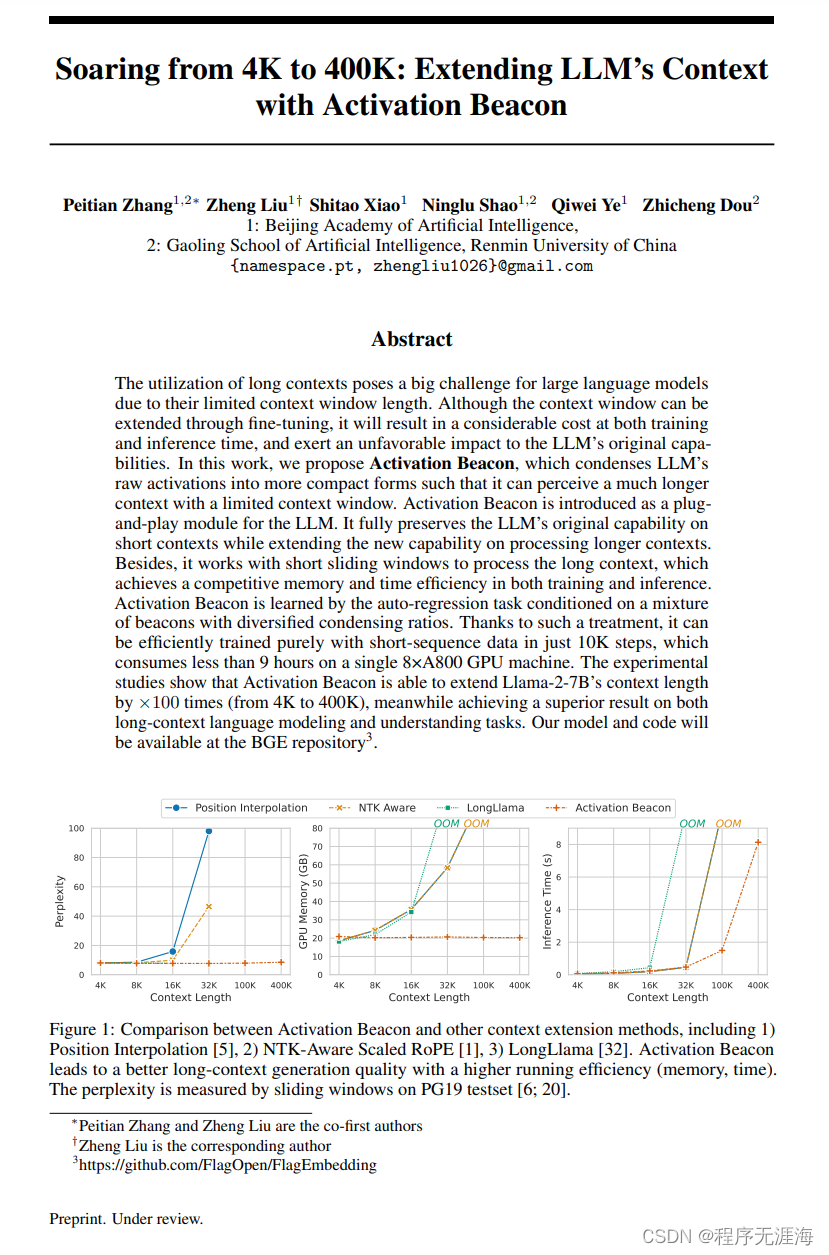
从4K到400K:通过激活信标扩展LLM的上下文
链接:http://arxiv.org/abs/2401.03462v1
长文本上下文的利用对于大型语言模型是一个巨大的挑战,因为它们的上下文窗口长度有限。尽管可以通过微调来扩展上下文窗口,但这会导致训练和推理时间上的相当大的成本,并对LLM的原始能力产生不利影响。在本文中,我们提出了Activation Beacon,它将LLM的原始激活状态压缩为更紧凑的形式,从而可以在有限的上下文窗口内感知更长的上下文。Activation Beacon被引入作为LLM的即插即用模块。它在处理短上下文时完全保留了LLM的原始能力,同时扩展了处理更长上下文的新能力。此外,它使用短窗口滑动处理长上下文,在训练和推理中都实现了竞争性的内存和时间效率。Activation Beacon通过受多样化压缩比例混合信标条件化的自回归任务进行学习。多亏了这样的处理方式,它可以仅使用短序列数据在仅10K步内高效训练,仅在单个8xA800 GPU机器上消耗不到9个小时。实验研究表明,Activation Beacon可以将Llama-2-7B的上下文长度扩展100倍(从4K扩展到400K),同时在长上下文生成和理解任务上取得优异结果。我们的模型和代码将在BGE存储库中提供。
Agent AI:勘探多模态交互的前沿

链接:http://arxiv.org/abs/2401.03568v1
多模态人工智能系统可能会成为我们日常生活中无处不在的存在。提高这些系统互动性的一种有前景的方法是将它们作为智能体嵌入到物理和虚拟环境中。目前,系统利用现有的基础模型作为创建智能体的基本构建模块。在这种环境中嵌入智能体有助于模型处理和解释视觉和语境数据的能力,这对于创建更复杂和上下文感知的人工智能系统至关重要。例如,一个能够感知用户行为、人类行为、环境对象、音频表达和场景集体情感的系统可以用来通知和引导给定环境中的智能体响应。为了加快基于智能体的多模态智能研究,我们将“Agent AI”定义为一类可以感知视觉刺激、语言输入和其他与环境相关的数据,并且能够通过无数智能体产生有意义的行为的交互系统。特别是,我们探索旨在通过整合外部知识、多感官输入和人类反馈来改进基于下一个具体行动预测的智能体系统。我们认为,通过在有基础的环境中开发智能体AI系统,还可以减轻大型基础模型产生幻觉和生成环境不正确输出的倾向。智能体AI这一新兴领域涵盖了多模态交互的更广泛的具体和主体性方面。除了在物理世界中行动和互动的智能体,我们设想一个未来,人们可以轻松创建任何虚拟现实或模拟场景,并与嵌入在虚拟环境中的智能体进行互动。
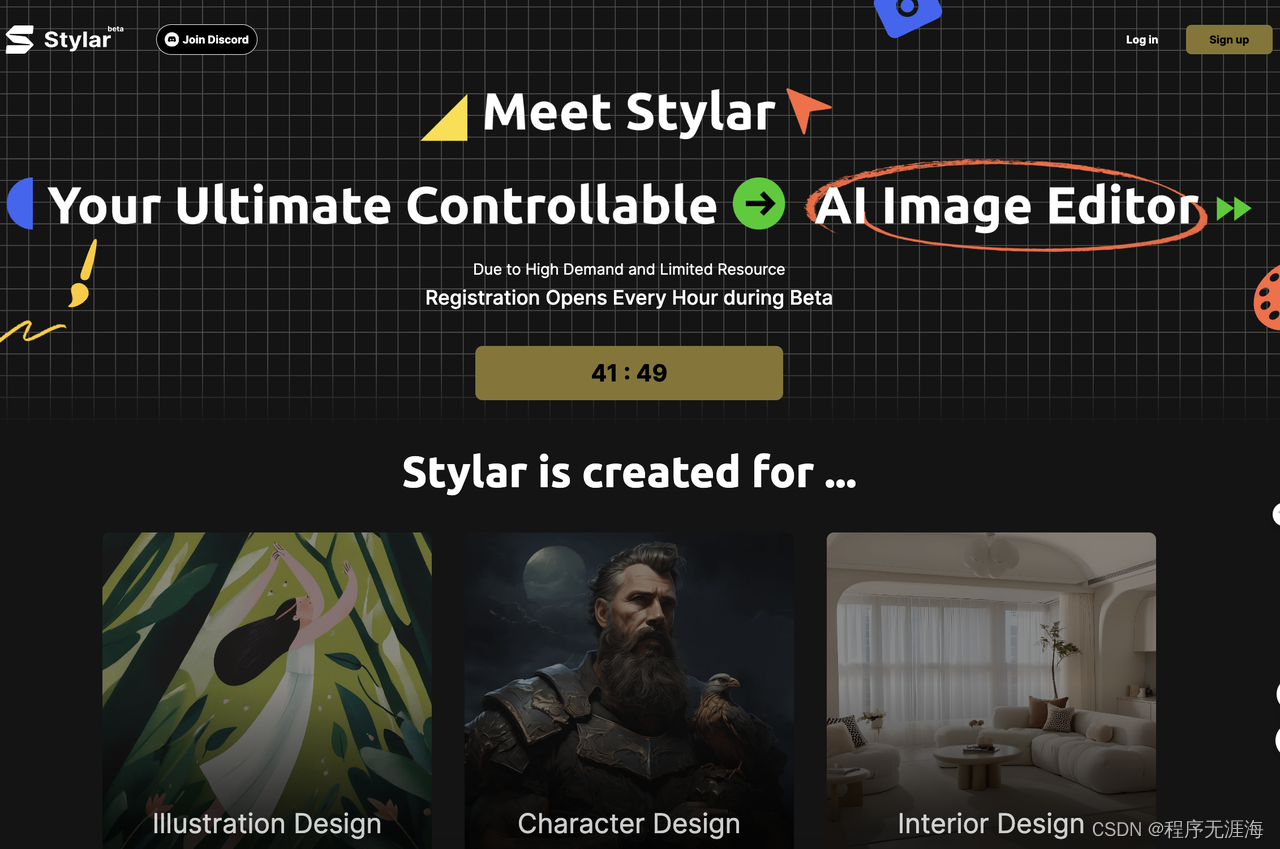
Stylar
https://www.stylar.ai/
Stylar.ai是一款AI图像生成工具,希望提供更高的视觉控制、设计灵活性和个性化的创作体验。用户可以使用Stylar.ai创建自定义图像,实现精确的布局和风格化,无需编码或复杂的设计软件。这个工具适用于设计师、插画家、艺术家和营销人员,为他们提供了创造独特图像的能力。
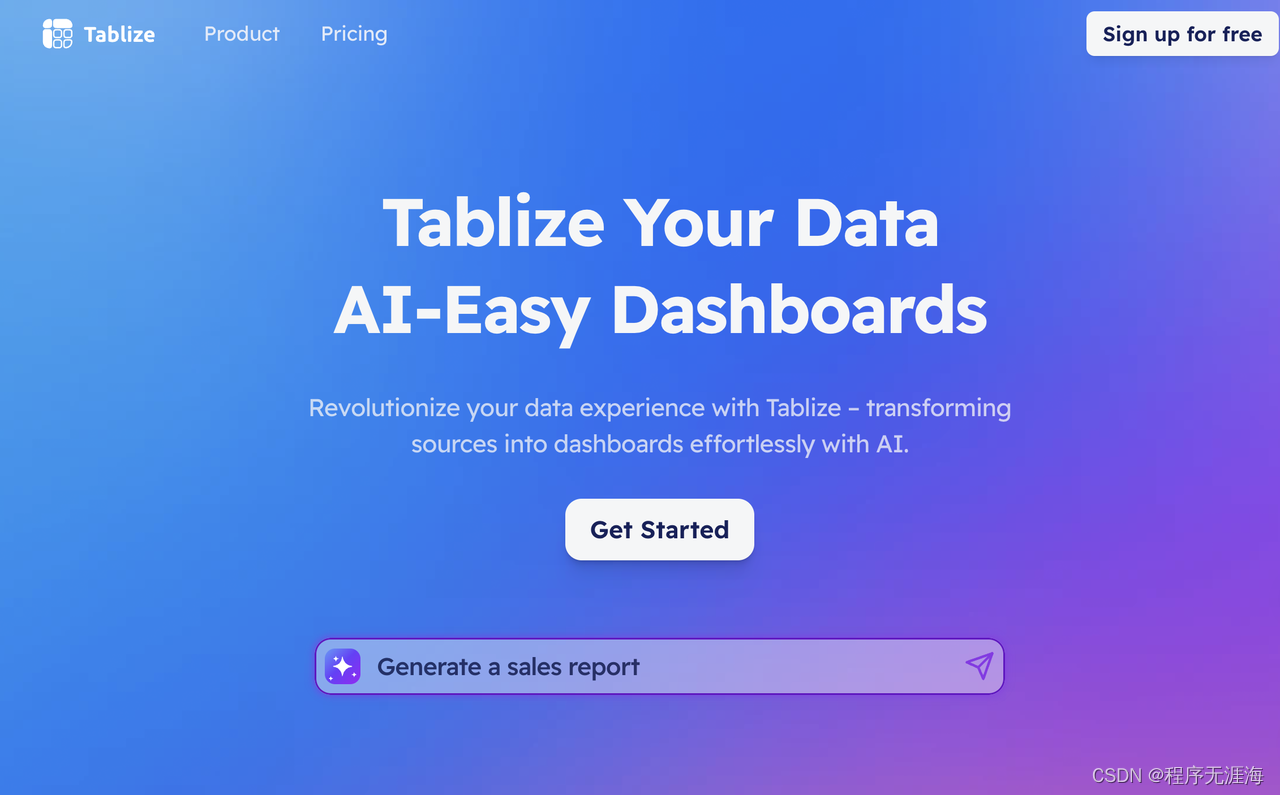
Tablize
https://tablize.com/
Tablize是一个数据管理和可视化工具,利用强大的AI功能,帮助用户将各种数据源转化为具有深度洞察力的仪表板。无论是数据工作者、需要定期处理数据的人,还是仪表板创建者,Tablize都能满足需求。它具有集成多个数据源、使用简单命令创建仪表板、AI驱动的仪表板生成、实时数据处理等酷炫功能,可视化和管理数据变得更加智能和高效。
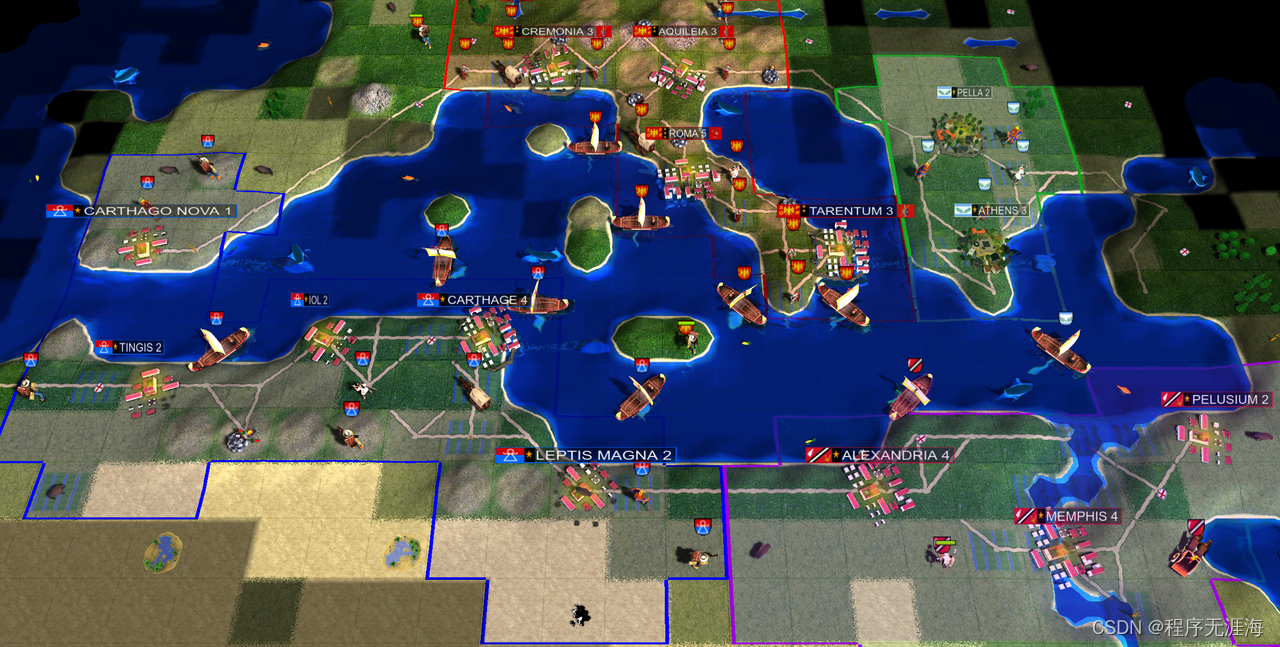
CivRealm
https://civrealm.github.io/civrealm/
CivRealm 是基于 Freeciv 的开源策略游戏 Freeciv-web 的交互式环境中的AI Agent。在 CivRealm 中,为两种典型的代理类型提供了接口:在 Gymnasium API 的基础下的强化学习代理,以及由语言模型提供支持的基于语言的代理。同时,还提供了一套用于培训和评估座席的工具,以及一组用于两种座席类型的基线。希望 CivRealm 可以作为一个测试平台,用于开发和评估能够在复杂环境中学习和推理的智能体。
generative_ai_with_langchain

https://github.com/benman1/generative_ai_with_langchain
使用 Python、ChatGPT 和其他模型构建大型语言模型 (LLM) 应用程序。这是关于使用LangChain的生成式AI的书的配套存储库。大家可以借助材料进行学习。
论文分享:ToRA A Tool-Integrated Reasoning Agent for Mathematical Problem Solving
https://zhuanlan.zhihu.com/p/676860626
本文介绍了清华大学和微软团队在ICLR24提交的论文,探讨了如何通过微调大型语言模型LLaMA来提升其解决数学问题的能力。研究提出了ToRA,一个集成工具的推理代理,它结合了自然语言推理和代码执行的优势。通过两阶段微调,首先构建了一个16K数据集进行基础模型微调,然后通过输出空间重塑来增加解决方案的多样性。实验表明,这种方法显著提升了模型解决数学问题的能力,接近了ChatGPT和GPT4的水平。ToRA展示了在数学问题解决领域的潜力。
AI芯片战局逆转!英伟达欲被放弃,BAT和字节转头拥抱国产?
https://zhuanlan.zhihu.com/p/676606441
中国科技公司,如百度、阿里巴巴、腾讯和字节跳动,因美国对中国显卡的禁售政策,开始减少对英伟达芯片的订单,转而支持国内芯片制造商或自研芯片。这一转变部分是由于美国监管政策的不确定性,以及中国企业为未来减少对英伟达产品的依赖而调整战略。同时,英伟达显卡性能的下降也使得国产芯片更具吸引力。尽管如此,中国企业在短期内仍面临挑战,因为英伟达的CUDA计算平台和软硬件生态仍是AI开发人员的首选。华为和阿里巴巴等公司正在积极开发国产芯片,以期在未来几年内减少对英伟达的依赖。
![数据库设计规范[掌握好规范,设计出的表一般不会差]](https://img-blog.csdnimg.cn/img_convert/248997fba2e6d63d3d902dce39051959.jpeg)