自从 LLaMA 被提出以来,开源大型语言模型(LLM)的快速发展就引起了广泛研究关注,随后的一些研究就主要集中于训练固定大小和高质量的模型,但这往往忽略了对 LLM 缩放规律的深入探索。
开源 LLM 的缩放研究可以促使 LLM 提高性能和拓展应用领域,对于推进自然语言处理和人工智能领域具有重要作用。在缩放规律的指导下,为了解决目前 LLM 缩放领域中存在的不明确性,由 DeepSeek 的 AI 团队发布了全新开源模型 LLMDeepSeek LLM。此外,作者还在这个基础模型上进行了监督微调(SFT)和直接偏好优化(DPO),从而创建了 DeepSeek Chat 模型。
在性能方面,DeepSeek LLM 67B 在代码、数学和推理任务中均超越了 LLaMA-2 70B,而 DeepSeek LLM 67B Chat 在开放性评估中更是超越了 GPT-3.5。这一系列的表现为开源 LLM 的未来发展奠定了一定基础。
论文题目:
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
论文链接:
https://arxiv.org/abs/2401.02954
与作为人工通用智能(AGI)新标杆的 LLaMa 相比,本文提出的 DeepSeek LLM:
-
数据集规模:DeepSeek LLM 使用了一个包含 2 万亿字符的双语数据集进行预训练,这比 LLaMA 的数据集更大。
-
模型性能:DeepSeek LLM 在多个基准测试中表现优于 LLaMA,特别是在代码、数学和推理方面。
-
模型架构:虽然 DeepSeek LLM 在微观设计上主要遵循 LLaMA ,但在宏观设计上有所不同。DeepSeek LLM 7B 是一个 30 层网络,而 DeepSeek LLM 67B 有 95 层。这些层数调整在保持与其他开源模型参数一致性的同时优化了模型的训练和推理。
-
可缩放研究:DeepSeek LLM 对模型和数据尺度的可缩放性进行了深入研究,并成功地揭示了最优模型/数据缩放分配策略,从而预测了大规模模型的性能。
-
安全性评估:DeepSeek LLM 67B 表现优秀,能够在实践中提供无害化的回复。
预训练
-
数据:为了在确保模型在预训练阶段能够充分学习并获得高质量的语言知识,在构建数据集过程中,采取了去重、过滤和混合三个基本阶段的方法,来增强数据集的丰富性和多样性。为了提高计算效率,作者还描述了分词器的实现方式,采用了基于 tokenizers 库的字节级字节对编码(BBPE)算法,使用了预分词化和设置了适当的词汇表大小。
-
架构:主要借鉴了 LLaMA 的 Pre-Norm 结构,其中包括 RMSNorm 函数,使用 SwiGLU 作为前馈层的激活函数,中间层维度为 ,此外还引入了 Rotary Embedding 用于位置编码。为了优化推理成本,67B 模型没采用传统的 Multi-Head Attention(MHA),而是用了 GroupedQuery Attention(GQA)。
-
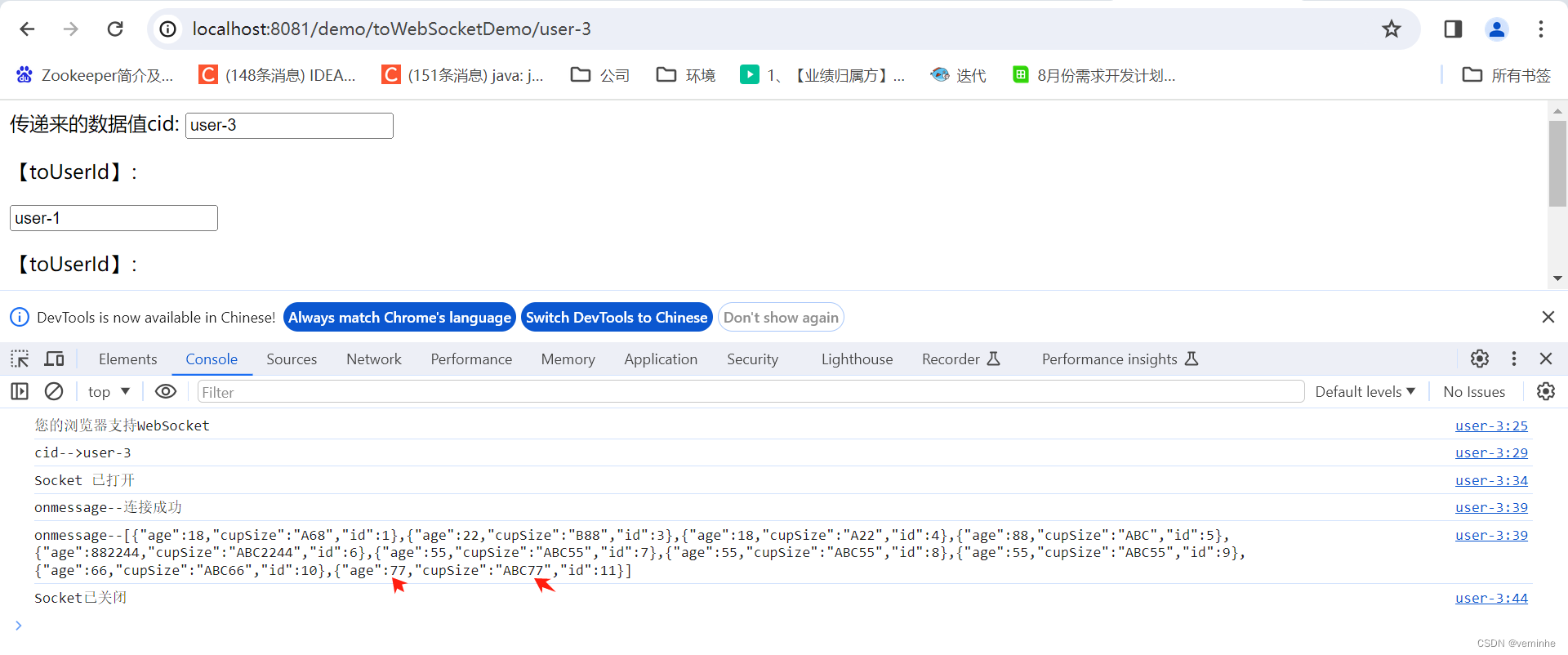
超参数:通过我们的实验证明,使用多步学习率调度程序的最终性能与余弦调度程序基本一致,如图 1(a) 所示,作者还在图 1(b) 中演示了调整多步学习率调度程序不同阶段比例,可以略微提升性能。
▲图1 使用不同学习率调度程序或调度程序不同参数的训练损失曲线
缩放规律及影响
作者通过大量实验,探讨了模型和数据大小与计算预算之间的关系。研究发现,随着计算预算的增加,模型性能可以通过增加模型规模和数据规模来预测性地提高。但是,不同数据集对缩放法则有显著影响,高质量的数据可以推动更大模型的训练。
超参数的缩放规律
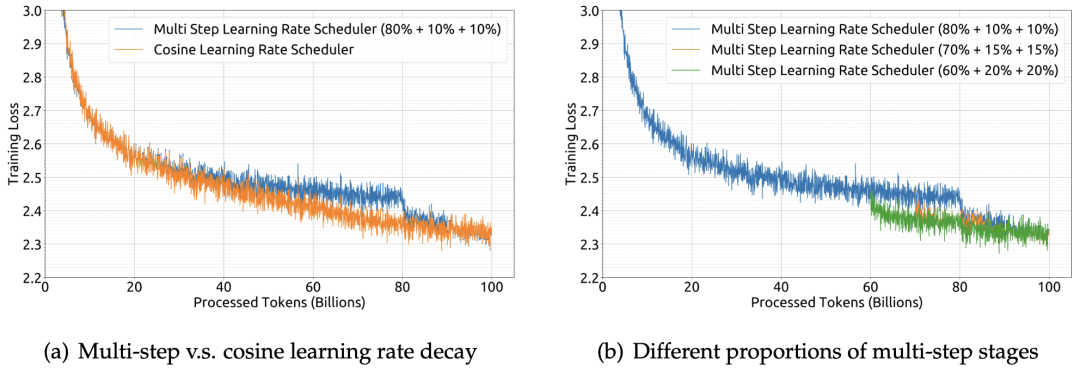
在这部分,作者研究了 batch size 和学习率的缩放律,并找到了它们随模型大小的变化趋势。图 2 的实验展示了 batch size 和学习率与计算预算之间的关系,为确定最佳超参数提供了经验框架。
▲图2 训练损失关于 batch size 和学习率的变化
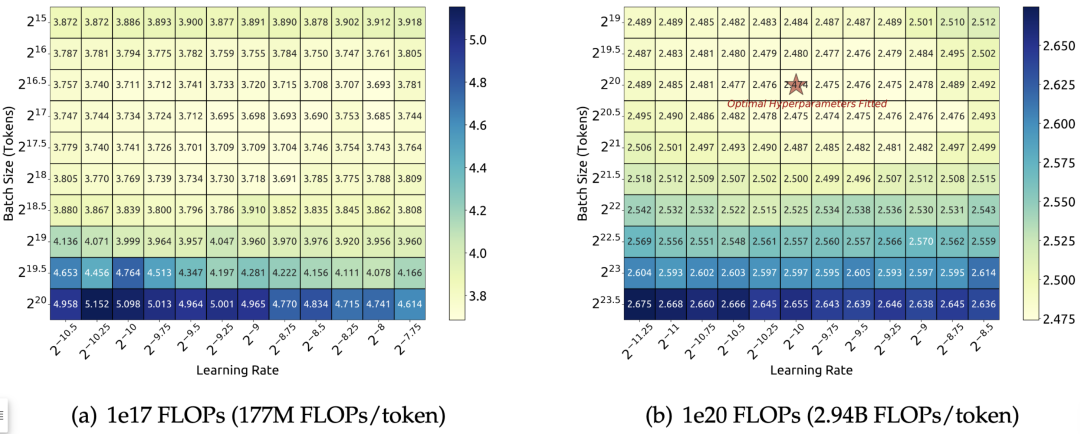
如图 3 所示,经验证实,batch size 随计算预算的增加而增加,而学习率则随计算预算的增加而减小。作者指出,他们的研究结果与一些早期研究中提到的观点不一致。这些研究可能认为最佳 batch size 仅与泛化误差𝐿有关。然而,本文的发现似乎暗示了更为复杂的关系,可能受到模型规模和数据分配的影响。作者将在未来工作中进一步研究以了解如何进行超参数和训练动态选择。
▲图3 batch size 和学习率的缩放曲线
估算最优的模型和数据缩放
表 1 的结果表明,数据质量会影响最优模型/数据缩放分配策略。数据质量越高,增加的计算预算应更多地分配给模型缩放。作者使用了三个不同的数据集来研究缩放定律,发现最优模型/数据缩放分配策略与数据质量一致。数据质量提高时,模型缩放指数逐渐增加,而数据缩放指数减小,这表明增加的计算预算应更多地分配给模型而不是数据。
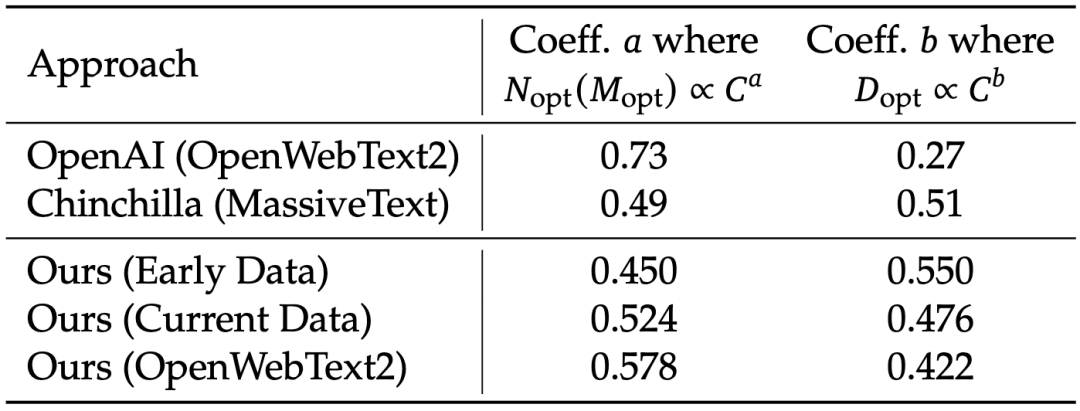
▲表1 模型缩放和数据缩放的系数随训练数据分布而变化
对齐
对齐流程主要包括两个阶段:监督微调(SFT)和直接偏好优化(DPO)。
监督微调
在微调阶段,作者对 7B 模型进行了 4 个 epoch 的微调,而由于观察到 67B 模型存在较为严重的过拟合问题,对 67B 模型仅进行了 2 个 epoch 的微调。
作者还评估了微调过程中聊天模型的重复率。根据实验结果所示,随着数学 SFT 数据量的增加,重复率往往上升。这可以归因于数学 SFT 数据中偶尔包含相似的推理模式。
直接偏好优化(DPO)
此外,作者还采用了直接偏好优化算法(DPO)以进一步增强模型的能力,这是对齐大语言模型的一种简单而有效的方法。为了构建 DPO 训练的偏好数据,模型根据有益和无害两个方面进行了训练。
实验结果显示,DPO 在增强模型的开放性生成能力方面很成功,同时在标准基准测试中几乎没有差异。
实验评估
实验表明,尽管 DeepSeek 模型是在 2 万亿字符的双语语料库上预训练的,但在英语语言理解基准上表现与 token 数差不多但侧重于英语的 LLaMA-2 模型相当。实验结果显示,在相同数据集上训练的 7B 和 67B 模型之间,模型缩放对某些任务(如 GSM8K 和 BBH)的性能提升效果明显。然而,随着数学数据比例的增加,小型和大型模型之间的性能差异可能会减小。
在表 2 中,DeepSeek 67B 相对于 LLaMA-2 70B 的优势大于 DeepSeek 7B 相对于 LLaMA-2 7B 的优势,突显了语言冲突对较小模型的更大影响。此外,LLaMA-2 在某些中文任务上表现出色,这表明某些基本能力如数学推理可以在语言之间有效地迁移。然而,对于涉及中文成语使用的任务,DeepSeek LLM 相较于 LLaMA-2 表现更出色,特别是在预训练期间涉及大量中文 token 的情况下。
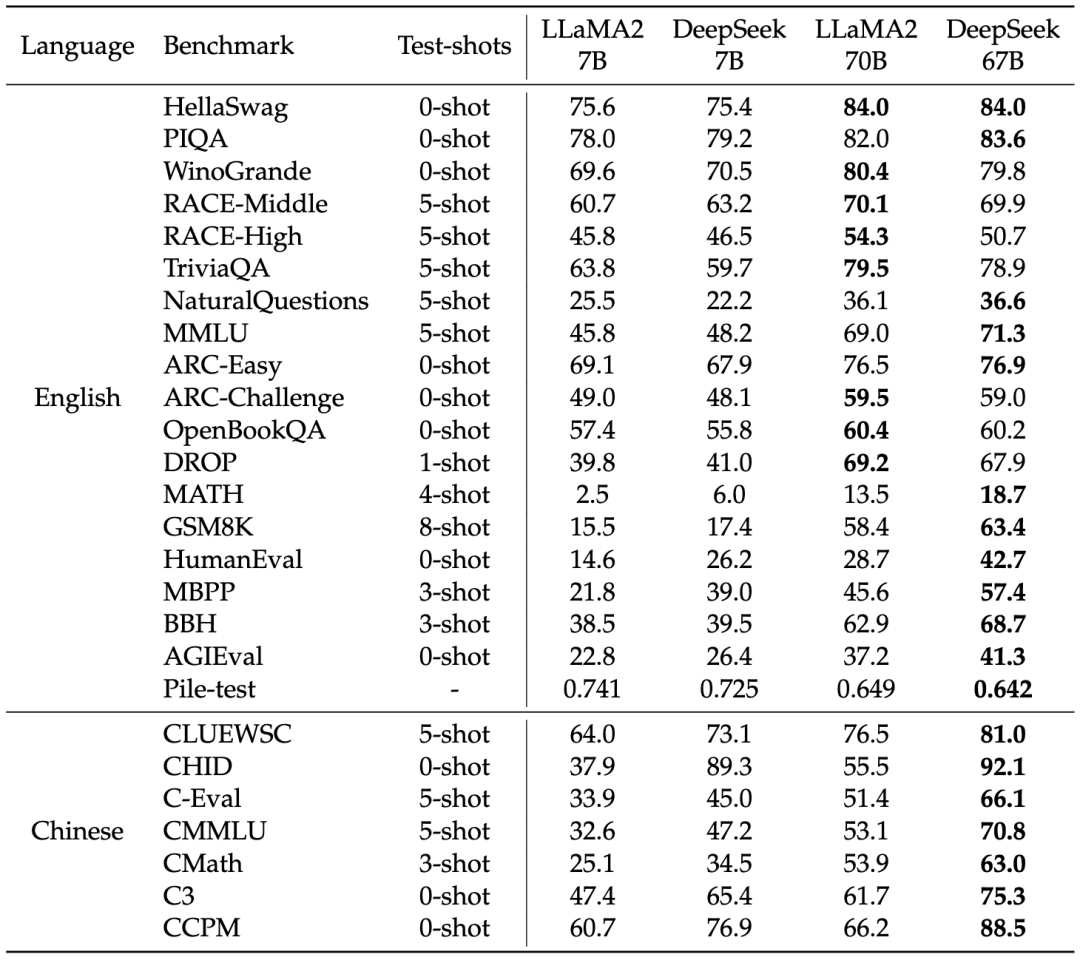
▲表2 主要实验结果
聊天模型
如表格 3 所示,微调后的 DeepSeek 聊天模型在大多数任务上取得了整体改进,表现出对多样性任务的适应能力。
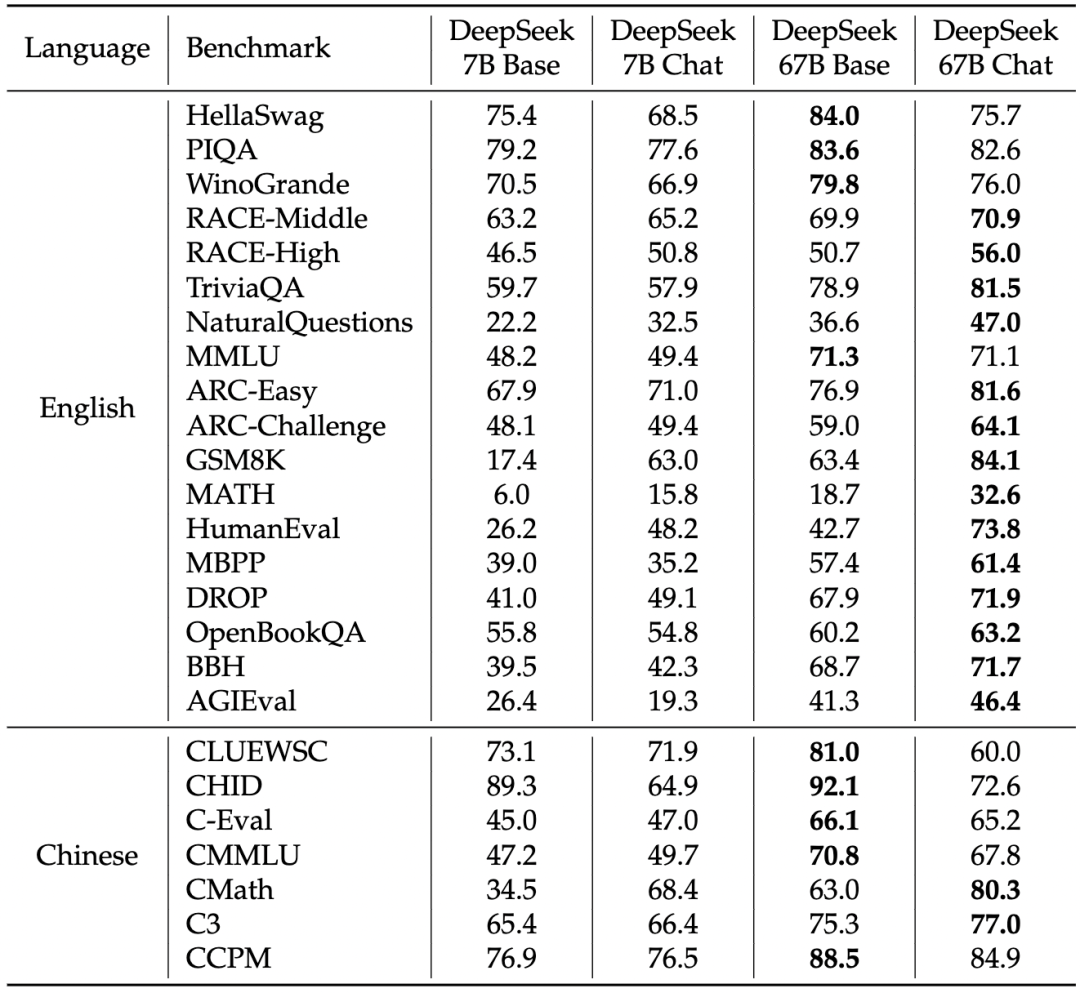
▲表3 基础模型和聊天模型之间的比较
-
知识相关任务:在与知识相关的任务(如 TriviaQA、MMLU、C-Eval)中,基础模型和聊天模型之间存在一些波动。作者指出,这种波动不一定意味着在 SFT(聊天模型监督微调)后获取或失去了知识,而是强调 SFT 的价值在于实现聊天模型在零样本设置中的性能与基础模型在少样本设置中相当,这与真实场景一致。
-
推理任务:由于 SFT 实例采用了 CoT 格式,聊天模型在推理任务中表现出些许改进。作者认为 SFT 阶段并未学到推理能力,而是学到了正确的推理路径格式。
-
性能下降任务:一些任务在微调后持续表现出性能下降,特别是涉及填空或句子完成的任务(如 HellaSwag)。可能纯语言模型更适合处理这类任务。
-
数学和编程任务:在数学和编程任务中,微调后的模型表现出显著的改进,例如 HumanEval 和 GSM8K 的提升了 20 多分。这可能是由于 SFT 阶段学到了编程和数学方面的额外知识,尤其是在代码完成和代数问题方面。作者指出,未来工作可能需要在预训练阶段引入更多样化的数据以全面理解数学和编程任务。
开放性评估
中文开放性评估
实验结果显示,DeepSeek 67B Chat 模型在基本的中文语言任务中位于所有模型的第一梯队,甚至在中文基础语言能力方面超过了最新版本的 GPT-4。在高级中文推理任务中,本文的模型得分明显高于其他中文 LLM,在更复杂的中文逻辑推理和数学计算中有着卓越性能。
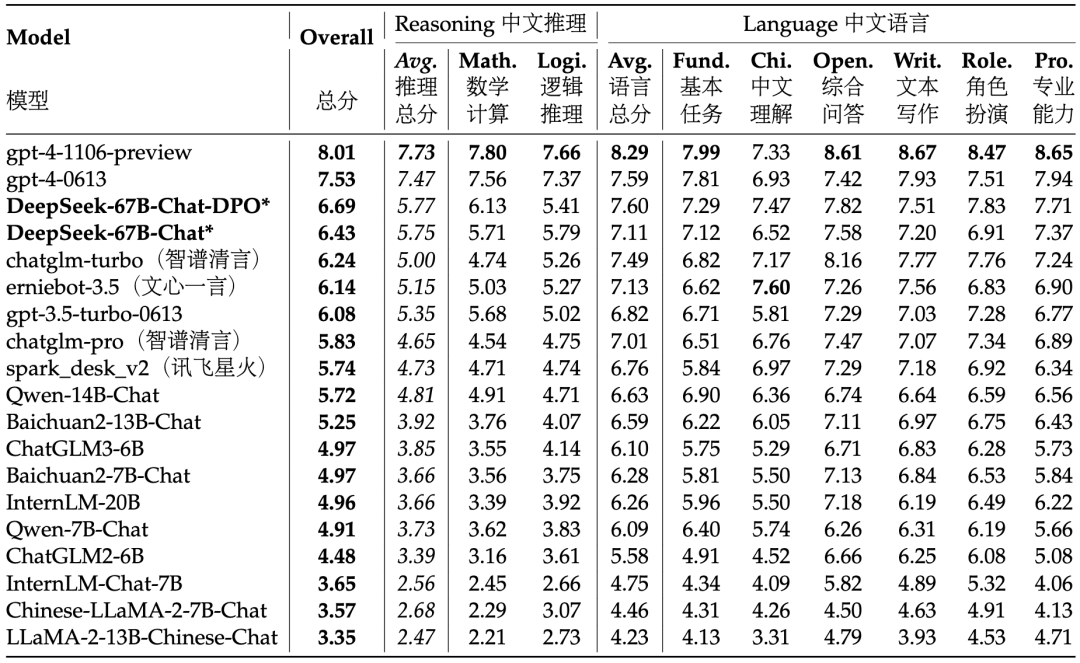
▲表4 AlignBench 排行榜
英文开放性评估
DeepSeek LLM 67B Chat 在性能上超过了 LLaMA-2-Chat 70B 等其他开源模型,与 GPT-3.5-turbo 相媲美。此外,经过 DPO 阶段后,DeepSeek LLM 67B Chat 的平均分进一步提升,仅次于 GPT-4。这表明 DeepSeek LLM 在多轮开放性生成方面具有强大能力。

▲表5 MT-Bench 评估
保留集评估
保留集是模型在训练阶段未曾接触到的数据集,用于评估模型在面对新领域和未见过的样本时的泛化能力。作者采用了多个基准任务和指标,包括对话、数学、编程、语言理解等方面的测试。这些任务涵盖了模型需要在实际应用中面对的各种场景和挑战。DeepSeek 在各个阶段的保留集评估中都展现出卓越的性能,验证了其在处理未知任务和领域时的强大能力。
安全性评估
DeepSeek 67B Chat 模型在安全性评估方面表现良好,其安全性得分高于 ChatGPT 和 GPT-4。在不同的安全测试类别中,该模型的表现也相对出色。然而,模型在某些任务上的表现可能受到数据集的局限性影响。例如,初始版本的中文数据可能在某些中文特定主题上表现不佳。此外,由于模型主要基于中英文数据集,对其他语言的熟练程度可能相对较低,需要在实际应用中审慎对待。
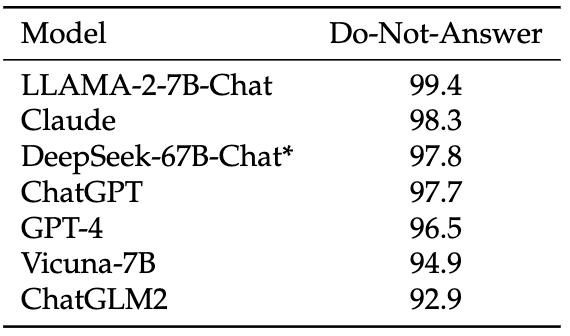
▲表6 Do-Not-Answer 得分
进一步讨论
分阶段微调
小型模型在数学和代码数据集上需要更长时间的微调,但这将损害模型的对话能力。为了解决这个问题,作者进行了分阶段微调:
-
第一阶段使用所有可用数据进行微调;
-
第二阶段专注于使用对话数据进行微调。
表 7 的结果表明,第二阶段不会损害模型在编程和数学方面的熟练程度,同时降低了重复行为并增强了指令跟随的能力。

▲表7 两阶段微调结果
多选题
多选题要求模型不仅具有相应的知识,还要理解选项的含义。在对齐阶段,作者测试了添加 2000 万个中文多项选择问题并获得了如表 8 所示的性能。为防止数据污染,作者对 C-Eval 验证集和 CMMLU 测试集进行了去重。

▲表8 添加多项选择问题数据的影响
额外添加的多项选择问题不仅对中文多项选择基准有益,还有助于改善英文基准,这表明模型解决多选题的能力已经得到了增强。然而,用户在对话交互中可能不会认为模型变得更加智能,因为这些交互是生成回复而非解决多项选择问题。
在预训练中的指令数据
作者探讨了在预训练的后期阶段引入指令数据对基础模型性能的影响。他们在预训练的最后 10% 阶段整合了包含多项选择题在内的 500 万条指令数据,结果观察到基础 LLM 模型的性能改进。然而,最终结果几乎与在 SFT 阶段添加相同数据时获得的结果相同。因此,尽管这种方法增强了基础模型在基准测试中的性能,但其整体与在预训练过程中不引入这些指令数据相当。
系统提示
这里探讨了系统提示对模型性能的影响。他们采用 LLaMA-2 的系统提示,并稍微修改成为他们的系统提示,明确要求模型以有益、尊重、诚实的方式回答问题,同时禁止包含有害内容。
如表 9 所示,作者观察到一个有趣的现象,即在引入系统提示时,7B LLM 的性能略微下降。然而,当使用 67B LLM 时,添加提示导致结果显著改善。他们解释这种差异的原因是更大的模型能更好理解系统提示背后的预期含义,使它们能够更有效地遵循指令并生成更出色的回复。相反,较小的模型难以充分理解系统提示,训练和测试之间的不一致可能对它们的性能产生负面影响。
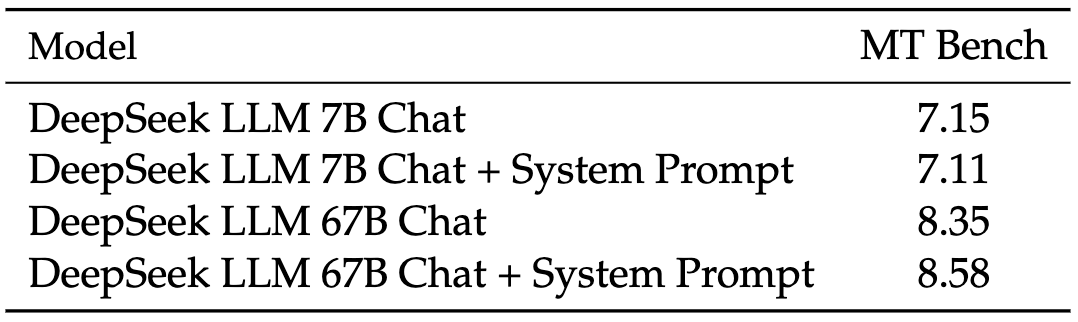
▲表9 添加系统提示的影响
总结
作者在本文中提出了 DeepSeek LLM,并详细解释了超参数选择、缩放规律以及进行的各种微调尝试,校准了以前工作中的缩放规律,提出了一种新的最优模型/数据缩放分配策略。通过缩放规律的指导,我们使用最佳超参数进行预训练,并进行了更为全面的评估。
然而,DeepSeek Chat 仍然存在一些已知限制:如在预训练后缺乏知识更新、生成非事实信息以及在某些中文特定主题上性能不佳。此外,模型在其他语言上的熟练程度仍然相对脆弱,需要谨慎对待。
目前,该团队正在为即将推出的 DeepSeek LLM 版本构建更大、更完善的数据集,希望能在下一版本中改进推理、中文知识、数学和编程能力。作者的这一系列努力,也体现了他们要在推动 NLP 和 AIG 领域的创新和提升模型性能方面长期努力的承诺。



![[Kubernetes]7. K8s包管理工具Helm、使用Helm部署mongodb集群(主从数据库集群)](https://img-blog.csdnimg.cn/direct/7acd61edb2c84e39b0c68682399d3ef1.png)